目录:
-
- [零、上下文缓存(Context Cache)简介](#零、上下文缓存(Context Cache)简介)
- [一、核心概念:隐式缓存 vs 显式缓存](#一、核心概念:隐式缓存 vs 显式缓存)
- 二、隐式缓存:自动触发的实现方式
-
- [1. 触发条件](#1. 触发条件)
- [2. 代码对接示例(OpenAI兼容API)](#2. 代码对接示例(OpenAI兼容API))
- [3. 隐式缓存的效果验证](#3. 隐式缓存的效果验证)
- [4. 举例分析](#4. 举例分析)
- 三、显式缓存:手动指定缓存Key
-
- [1. 触发条件](#1. 触发条件)
- [2. 代码对接示例(显式指定缓存Key)](#2. 代码对接示例(显式指定缓存Key))
- [3. 显式缓存的高级用法](#3. 显式缓存的高级用法)
- [4. 举例分析](#4. 举例分析)
- 四、缓存效果查看与验证
- 五、缓存机制的监控与优化
-
- [1. 关键监控指标(从响应中获取)](#1. 关键监控指标(从响应中获取))
- [2. 优化建议](#2. 优化建议)
- 六、与阿里云原生SDK的对比
零、上下文缓存(Context Cache)简介
调用大模型时,不同推理请求可能出现输入内容的重叠(例如多轮对话或对同一本书的多次提问)。上下文缓存(Context Cache)技术可以缓存这些请求的公共前缀,减少推理时的重复计算。这能提升响应速度,并在不影响回复效果的前提下降低您的使用成本。
为满足不同场景的需求,上下文缓存提供两种工作模式,可以根据对便捷性、确定性及成本的需求进行选择:
- 隐式缓存:此为自动模式,无需额外配置,且无法关闭,适合追求便捷的通用场景。系统会自动识别请求内容的公共前缀并进行缓存,但缓存命中率不确定。
- 显式缓存:需要主动开启的缓存模式。需要主动为指定内容创建缓存,以在有效期(5分钟)内实现确定性命中。
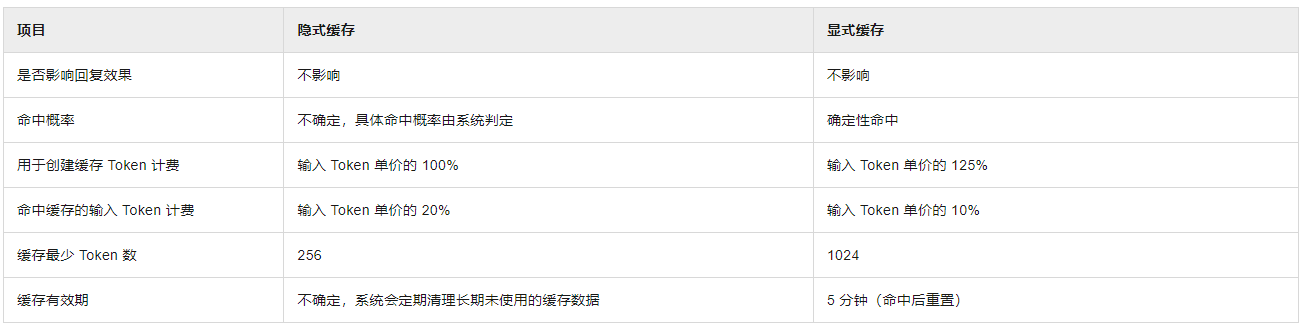
隐式缓存与显式缓存互斥,单个请求只能应用其中一种模式。
一、核心概念:隐式缓存 vs 显式缓存
阿里云大模型服务的缓存机制本质是对重复的输入内容(如prompt中的固定指令、历史对话)进行缓存,避免重复计算,降低token消耗和响应延迟。两者的核心区别:
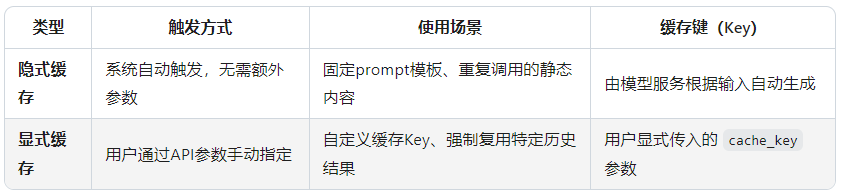
二、隐式缓存:自动触发的实现方式
1. 触发条件
- 适用模型:阿里云通义千问等支持缓存的大模型(需确认模型版本是否支持,如 qwen-plus、qwen-max 等)。
- 输入特征:当连续多次调用中,prompt包含重复的固定内容(如系统指令、模板化问题),系统会自动识别并缓存这部分内容。
- 限制:Batch 批量调用模式不支持隐式缓存(文档明确说明:"OpenAI兼容Batch方式调用无法享受缓存折扣")。
2. 代码对接示例(OpenAI兼容API)
阿里云大模型服务提供 OpenAI兼容接口,因此可直接使用OpenAI SDK调用,隐式缓存完全由服务端自动处理,无需额外代码。
python
import openai
# 配置阿里云API endpoint和密钥
openai.api_base = "https://dashscope.aliyuncs.com/compatible-mode/v1"
openai.api_key = "你的阿里云API密钥" # 从阿里云控制台获取
# 重复调用相同的系统指令(隐式缓存会自动触发)
for i in range(3):
response = openai.ChatCompletion.create(
model="qwen-plus", # 支持缓存的模型
messages=[
{"role": "system", "content": "你是阿里云开发的一款超大规模语言模型,叫通义千问。"}, # 固定系统指令(会被缓存)
{"role": "user", "content": f"第{i+1}次提问:介绍一下你自己"} # 变化的用户输入(不缓存)
],
temperature=0.7
)
# 解析响应中的缓存使用情况(文档截图中的 cached_tokens 字段)
usage = response["usage"]
print(f"总tokens: {usage['total_tokens']}, "
f"缓存命中tokens: {usage['prompt_tokens_details']['cached_tokens']}")3. 隐式缓存的效果验证
- 首次调用:cached_tokens=0(无缓存,全量计算)。
- 第二次调用:cached_tokens=N(N为系统指令的token数,如文档示例中的 2048),此时 prompt_tokens =变化的用户输入token数 + 0(缓存复用系统指令),总token成本降低。
4. 举例分析

其实隐式缓存使用场景是缓存开场白这个固定部分。
三、显式缓存:手动指定缓存Key
1. 触发条件
- 适用场景:需要强制复用特定结果(如固定问答对、重复查询相同知识库内容),或希望自定义缓存粒度。
- 核心参数:通过 cache_control 字段手动控制缓存策略(阿里云扩展参数,需通过 extra_body 传入)。
2. 代码对接示例(显式指定缓存Key)
阿里云OpenAI兼容接口需通过 extra_body 传递扩展参数,显式缓存的关键参数:
- cache_control: 缓存控制对象
- cache_key: 自定义缓存键(字符串,相同Key会复用缓存结果)
- cache_age: 缓存有效期(秒,如 3600 表示1小时内复用)
python
import openai
openai.api_base = "https://dashscope.aliyuncs.com/compatible-mode/v1"
openai.api_key = "你的阿里云API密钥"
# 显式缓存:手动指定 cache_key 和有效期
response = openai.ChatCompletion.create(
model="qwen-plus",
messages=[
{"role": "user", "content": "什么是云计算?用100字解释"}
],
# 阿里云扩展参数:显式缓存配置
extra_body={
"cache_control": {
"cache_key": "cloud_computing_explanation", # 自定义缓存Key
"cache_age": 3600 # 缓存1小时
}
}
)
# 解析缓存结果
usage = response["usage"]
print(f"缓存命中tokens: {usage['prompt_tokens_details']['cached_tokens']}")
print(f"回答内容: {response['choices'][0]['message']['content']}")3. 显式缓存的高级用法
- 强制刷新缓存:若需更新缓存内容,可修改 cache_key 或设置 cache_age=0。
- 复用历史结果:相同 cache_key 的调用会直接返回缓存结果,无需模型重新计算,响应速度接近0延迟。
4. 举例分析
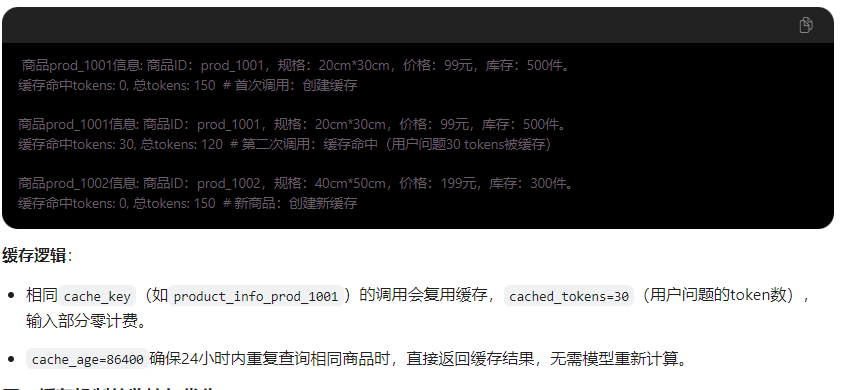
四、缓存效果查看与验证
根据文档截图,缓存命中的 tokens 数会在响应的 usage.prompt_tokens_details.cached_tokens 字段中体现,示例响应结构:
python
{
"choices": [
{
"message": {
"role": "assistant",
"content": "我是阿里云开发的一款超大规模语言模型,叫通义千问。"
},
"finish_reason": "stop",
"index": 0
}
],
"usage": {
"prompt_tokens": 3819,
"completion_tokens": 104,
"total_tokens": 3923,
"prompt_tokens_details": {
"cached_tokens": 2048 // 此处为命中的缓存tokens数
}
}
}- 关键指标:cached_tokens > 0 表示缓存生效,prompt_tokens = 实际输入tokens +
cached_tokens,但计费时 cached_tokens 部分可能享受折扣(具体以阿里云定价为准)。
总结:
-
隐式缓存:零代码成本,适合固定模板场景,全自动触发,推荐作为默认方案。
-
显式缓存:通过 cache_key 手动控制,适合自定义缓存粒度,推荐用于高频重复查询。
-
核心价值:减少重复计算,降低token消耗(文档示例中单次缓存命中2048 tokens),同时提升响应速度。
实际对接时,建议优先通过OpenAI兼容接口开发,利用阿里云提供的缓存机制优化成本和性能。
五、缓存机制的监控与优化
1. 关键监控指标(从响应中获取)
-
usage.prompt_tokens_details.cached_tokens:缓存命中的token数(越高越好,0表示未命中)。
-
usage.total_tokens:总消耗token数(结合cached_tokens计算成本优化比例)。
-
响应时间:通过代码记录time.time()对比缓存前后延迟。
2. 优化建议
- 最大化隐式缓存:将固定不变的内容(如系统指令、模板化开场白)放在messages的前面,确保阿里云能识别并缓存。
- 合理设置显式缓存有效期:高频更新的内容(如库存)设短缓存(如10分钟),静态内容(如商品规格)设长缓存(如1天)。
- 避免缓存动态内容:用户ID、时间戳等变化参数不要放入缓存Key或prompt(如get_product_info(user_id, product_id)中,仅用product_id作为缓存Key)。
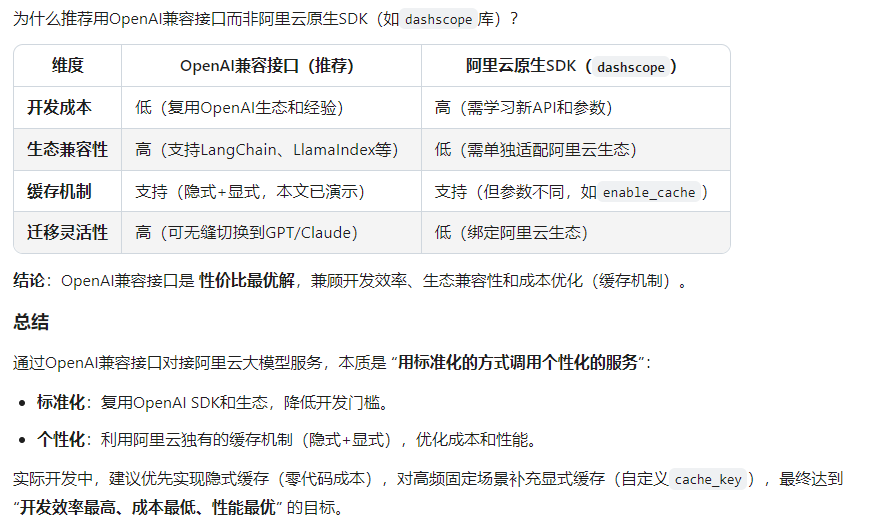
六、与阿里云原生SDK的对比
为什么推荐用OpenAI兼容接口而非阿里云原生SDK(如dashscope库)?