个人之前做过15445的2023spring版本,这次回炉时重新做了15445的2024fall版本,在进行实验3时,需要实现一个之前2023spring任务中没有给出的算子--external merge sort。如果待排序的数据量不大,那么很显然可以全部先读入bufferpool,再对数据进行常见的排序算法,比如快排或者归并,但是当数据多到塞不下内存,那么我们此时只可以借助磁盘的空间进行排序,所以被称为外部排序。当然我们可以拓展一下,比如说其他算子在数据量很多,内存装载不下时,会有什么表现,比如聚合算子和join算子。
2-way sorting
假设待排序的数据在磁盘上面占N个页面,数据库的bufferpool只开了B个页面,此时使用2路外排的思路是:先将磁盘中的各个页面读入bufferpool,每次读取B个页面,需要读取N/B轮,读取完之后对各个页面内的数据进行排序,之后刷新回磁盘,注意这里不是作为脏页覆盖之前的数据,此时只是作为外部排序的临时文件刷盘,因为不能覆盖之前的数据,现在磁盘中的N个临时页面全部有序了。
之后在2路外排的过程中,我们需要在缓冲区中开辟三个页面大小的操作页面,将磁盘中有序的page1和page2读入内存,然后将merge结果放入缓冲区中的page3,由于存储结果的只有一个页,所以我们肯定要merge两轮,每当page3满了之后就再次刷新到磁盘,然后继续前面page1和page2的merge操作,等到再次填满page3时,就重复之前的刷盘步骤,具体过程如下:
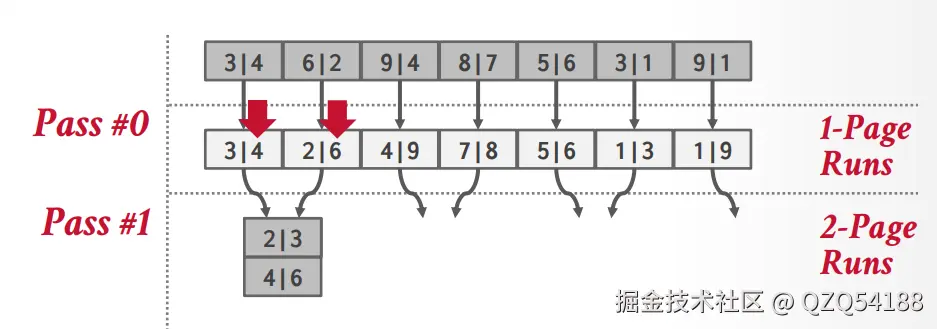
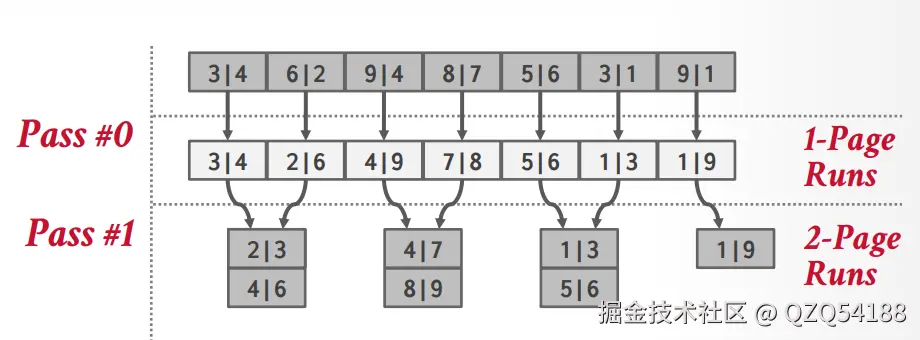
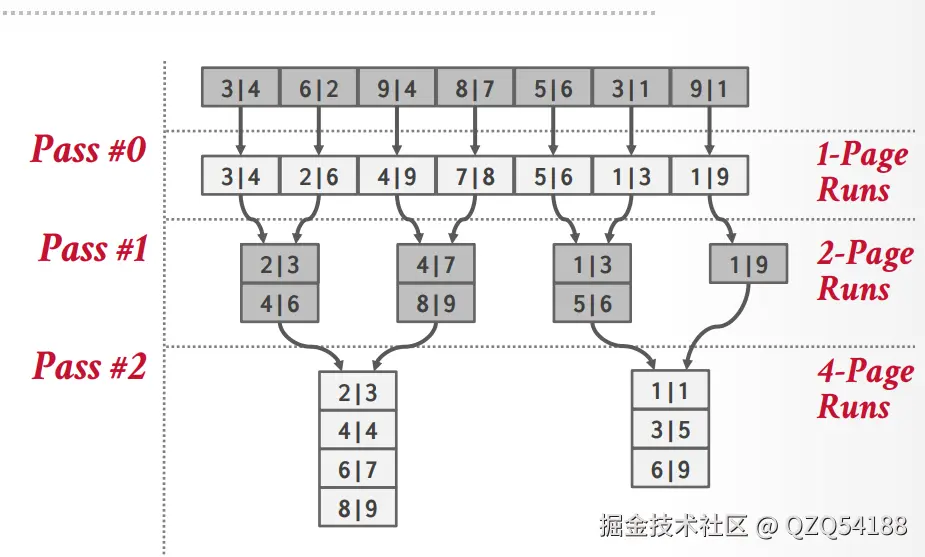
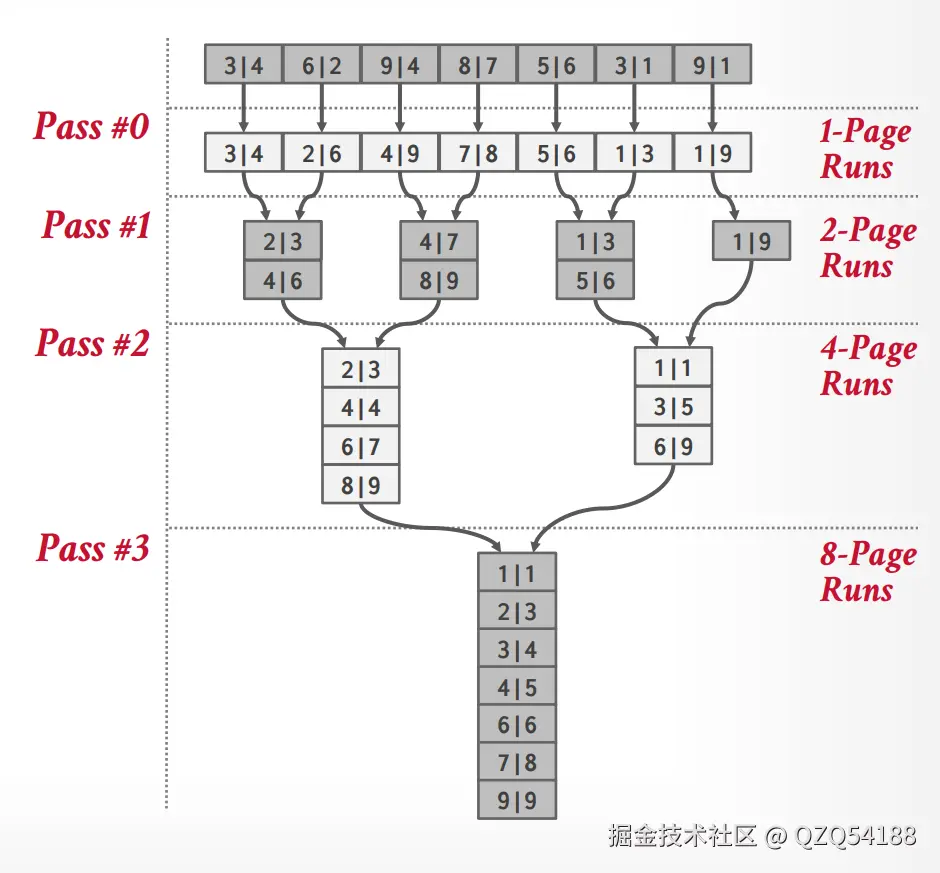
排序完之后,磁盘中的临时文件就是整体有序的状态了,可以逐个page读取。上面是15445课程ppt中的示例,还可以参考如下链接中的示例:Example of Two-way Sorting,Example of multiway Sorting。
multiway Sorting
在上述2路外排中,算法在于磁盘io,如果 worker(执行线程)必须等待磁盘 I/O 完成,就无法有效利用更多的缓冲区。如果没有异步 I/O 或多线程 pipeline,worker就只可以等待输入页准备好,等待输出页刷盘,继续下一轮,所以我们可以尝试从异步io和多线程pipeline方向进行优化。
在同步模型中,cpu会等待磁盘读取数据,磁盘会等待cpu把当前page给merge完,二者在相互等待,我们可以让二者的操作并行重叠来优化。当 CPU 在处理当前页时,磁盘 I/O 已经在后台预取下一页或异步写出旧页,这样当cpu把当前page给merge完之后,下一个需要的page已经读取到了内存中,不需要额外等待。同样的可以使用异步写,当输出缓冲页写满时,不要阻塞等待磁盘写完,让它异步刷新,CPU 立刻切换到处理下一页的比较与合并。
我们还可以使用多线程pipeline优化,此时就是多路外部排序,为了减少归并的轮数,我们不再只合并 2 个 run,而是同时合并k 个 run,示例可以参考上述链接。
下面给出我在实验中所写的外部归并排序算子:
C++
/**
* Page to hold the intermediate data for external merge sort.
*
* Only fixed-length data will be supported in Fall 2024.
*/
class SortPage {
public:
/**
* TODO: Define and implement the methods for reading data from and writing data to the sort
* page. Feel free to add other helper methods.
*/
// Delete all constructor / destructor to ensure memory safety
SortPage() = delete;
SortPage(const SortPage &other) = delete;
void Init(int size, int max_size, int tuple_size) {
size_ = size;
max_size_ = max_size;
tuple_size_ = tuple_size;
}
auto Size() const -> int { return size_; }
auto MaxSize() const -> int { return max_size_; }
auto IsFull() const -> bool { return size_ == max_size_; }
void Clear() { size_ = 0; }
auto InsertTuple(const Tuple &tuple) -> void {
int offset = size_ * tuple_size_;
tuple.SerializeTo(data_ + offset);
size_++;
}
auto GetTuple(int index) const -> Tuple {
int offset = index * tuple_size_;
Tuple res{};
res.DeserializeFrom(data_ + offset);
return res;
}
private:
/**
* TODO: Define the private members. You may want to have some necessary metadata for
* the sort page before the start of the actual data.
*/
int max_size_;
int size_;
int tuple_size_;
char data_[];
};这个SortPage结构体是在内存中实际存储磁盘的介质,我们首先初始化一个Tuple的大小,这样就可以确定一个页内可以存储多少个Tuple。注意这个tuple_size的大小是一个定值,所以我们目前只可以对定长Tuple实现外部归并排序。data_里面存储了实际的元组数据,前面三个字段是一个SortPage的固定头部。
之后是MergeSortRun结构体,这个结构体就体现了上图中n-pageRuns的流程:
C++
class MergeSortRun {
public:
MergeSortRun() = default;
MergeSortRun(std::vector<page_id_t> pages, BufferPoolManager *bpm) : pages_(std::move(pages)), bpm_(bpm) {}
auto GetPageCount() -> size_t { return pages_.size(); }
auto GetPages() -> std::vector<page_id_t> { return pages_; }
/** Iterator for iterating on the sorted tuples in one run. */
class Iterator {
friend class MergeSortRun;
public:
Iterator() = default;
/**
* Advance the iterator to the next tuple. If the current sort page is exhausted, move to the
* next sort page.
*
* TODO: Implement this method.
*/
auto operator++() -> Iterator & {
// ReadPageGuard guard = run_->bpm_->ReadPage(run_->pages_[page_index_]);
// auto page = guard.As<SortPage>();
auto page = page_guard_.As<SortPage>();
tuple_index_++;
if (tuple_index_ < page->Size()) {
return *this;
}
++page_index_;
tuple_index_ = 0;
if (page_index_ < static_cast<int>(run_->pages_.size())) {
page_guard_ = run_->bpm_->ReadPage(run_->pages_[page_index_]);
}
return *this;
}
/**
* Dereference the iterator to get the current tuple in the sorted run that the iterator is
* pointing to.
*
* TODO: Implement this method.
*/
auto operator*() -> Tuple {
auto page = page_guard_.As<SortPage>();
return page->GetTuple(tuple_index_);
}
/**
* Checks whether two iterators are pointing to the same tuple in the same sorted run.
*
* TODO: Implement this method.
*/
auto operator==(const Iterator &other) const -> bool {
return run_ == other.run_ && page_index_ == other.page_index_ && tuple_index_ == other.tuple_index_;
}
/**
* Checks whether two iterators are pointing to different tuples in a sorted run or iterating
* on different sorted runs.
*
* TODO: Implement this method.
*/
auto operator!=(const Iterator &other) const -> bool { return !(*this == other); }
private:
explicit Iterator(const MergeSortRun *run, size_t page_index, size_t tuple_index)
: run_(run), page_index_(page_index), tuple_index_(tuple_index) {
if (page_index_ < static_cast<int>(run_->pages_.size())) {
page_guard_ = run_->bpm_->ReadPage(run_->pages_[page_index_]);
}
}
/** The sorted run that the iterator is iterating on. */
[[maybe_unused]] const MergeSortRun *run_;
/**
* TODO: Add your own private members here. You may want something to record your current
* position in the sorted run. Also feel free to add additional constructors to initialize
* your private members.
*/
int page_index_; // 目前遍历run的页数组下标,标识遍历哪一个页
int tuple_index_; // 当前页内元组下标
ReadPageGuard page_guard_{}; // 避免对迭代器进行操作时重复fetch读页面
};
/**
* Get an iterator pointing to the beginning of the sorted run, i.e. the first tuple.
*
* TODO: Implement this method.
*/
auto Begin() -> Iterator { return Iterator{this, 0, 0}; }
/**
* Get an iterator pointing to the end of the sorted run, i.e. the position after the last tuple.
*
* TODO: Implement this method.
*/
auto End() -> Iterator { return Iterator{this, pages_.size(), 0}; }
private:
/** The page IDs of the sort pages that store the sorted tuples. */
std::vector<page_id_t> pages_;
/**
* The buffer pool manager used to read sort pages. The buffer pool manager is responsible for
* deleting the sort pages when they are no longer needed.
*/
[[maybe_unused]] BufferPoolManager *bpm_;
};按照上面图中的流程,一开始所有的page都是一个run,之后每轮两两run进行merge,最后变成一个run,这个run的pages数组中就存储了所有已经排序好的数所在pageid,可以配套上面的图解来理解代码。
C++
// Pass 0
Tuple child_tuple;
RID child_rid;
int tuple_size = static_cast<int>(sizeof(int32_t) + child_executor_->GetOutputSchema().GetInlinedStorageSize());
int max_size = (BUSTUB_PAGE_SIZE - SORT_PAGE_HEADER_SIZE) / tuple_size;
std::vector<SortEntry> entries;
entries.reserve(max_size);
auto bpm = GetExecutorContext()->GetBufferPoolManager();
while (child_executor_->Next(&child_tuple, &child_rid)) {
entries.emplace_back(GenerateSortKey(child_tuple, plan_->GetOrderBy(), child_executor_->GetOutputSchema()),
std::move(child_tuple));
if (static_cast<int>(entries.size()) >= max_size) {
std::sort(entries.begin(), entries.end(), cmp_);
page_id_t page_id = bpm->NewPage();
WritePageGuard page_guard = bpm->WritePage(page_id);
auto page = page_guard.AsMut<SortPage>();
page->Init(0, max_size, tuple_size);
for (const auto &entry : entries) {
page->InsertTuple(entry.second);
}
runs_.emplace_back(std::vector<page_id_t>{page_id}, bpm);
entries.clear();
bpm->FlushPage(page_id);
}
}
if (!entries.empty()) {
std::sort(entries.begin(), entries.end(), cmp_);
page_id_t page_id = bpm->NewPage();
WritePageGuard page_guard = bpm->WritePage(page_id);
auto page = page_guard.AsMut<SortPage>();
page->Init(0, max_size, tuple_size);
for (const auto &entry : entries) {
page->InsertTuple(entry.second);
}
runs_.emplace_back(std::vector<page_id_t>{page_id}, bpm);
entries.clear();
bpm->FlushPage(page_id);
}
// Pass 1..2..3.....
while (runs_.size() > 1) {
std::vector<MergeSortRun> new_runs;
for (size_t i = 0; i < runs_.size(); i += 2) {
if (i == runs_.size() - 1) {
new_runs.emplace_back(std::move(runs_[i]));
continue;
}
auto it_a = runs_[i].Begin();
auto it_b = runs_[i + 1].Begin();
std::vector<SortEntry> entries;
std::vector<page_id_t> pages;
page_id_t page_id = bpm->NewPage();
WritePageGuard page_guard = bpm->WritePage(page_id);
auto page = page_guard.AsMut<SortPage>();
page->Init(0, max_size, tuple_size);
while (it_a != runs_[i].End() && it_b != runs_[i + 1].End()) {
SortEntry entry_a = {GenerateSortKey(*it_a, plan_->GetOrderBy(), child_executor_->GetOutputSchema()), *it_a};
SortEntry entry_b = {GenerateSortKey(*it_b, plan_->GetOrderBy(), child_executor_->GetOutputSchema()), *it_b};
if (cmp_(entry_a, entry_b)) {
page->InsertTuple(entry_a.second);
++it_a;
} else {
page->InsertTuple(entry_b.second);
++it_b;
}
if (page->Size() == page->MaxSize()) {
pages.emplace_back(page_id);
bpm->FlushPage(page_id);
page_id = bpm->NewPage();
page_guard = std::move(bpm->WritePage(page_id));
page = page_guard.AsMut<SortPage>();
page->Init(0, max_size, tuple_size);
}
}
while (it_a != runs_[i].End()) {
if (page->Size() == page->MaxSize()) {
pages.emplace_back(page_id);
bpm->FlushPage(page_id);
page_id = bpm->NewPage();
page_guard = std::move(bpm->WritePage(page_id));
page = page_guard.AsMut<SortPage>();
page->Init(0, max_size, tuple_size);
}
page->InsertTuple(*it_a);
++it_a;
}
while (it_b != runs_[i + 1].End()) {
if (page->Size() == page->MaxSize()) {
pages.emplace_back(page_id);
bpm->FlushPage(page_id);
page_id = bpm->NewPage();
page_guard = std::move(bpm->WritePage(page_id));
page = page_guard.AsMut<SortPage>();
page->Init(0, max_size, tuple_size);
}
page->InsertTuple(*it_b);
++it_b;
}
if (page->Size() > 0) {
pages.emplace_back(page_id);
bpm->FlushPage(page_id);
}
for (auto pid : runs_[i].GetPages()) {
bpm->DeletePage(pid);
}
for (auto pid : runs_[i + 1].GetPages()) {
bpm->DeletePage(pid);
}
new_runs.emplace_back(pages, bpm);
}
runs_ = std::move(new_runs);
}
if (!runs_.empty()) {
it_ = runs_[0].Begin();
}external aggregation
和外部排序一样,当聚合操作处理超出bufferpool容量的大量数据时,系统不得不借助磁盘完成中间分组与聚合的情况。在使用聚合时,我们通常使用hash函数,将Groupby字段的值作为key,聚合函数类似Sum这种作为value,但是数据量太大,内存容纳不下这个哈希表,只可以借助磁盘。
假设我们的bufferpool里面有B个可用的page,那我们就使用一个page不断接收表的数据,其他B-1个page都用来作为哈希表聚合的输出。外部聚合时要按分组键的哈希值将数据划分为若干分区,每个分区单独写入一个磁盘临时文件,也就是前面的B-1个page。这样写入磁盘再重复处理之后就可用处理完表中所有数据,但是此时哈希表不在内存中,而在磁盘中,所以我们需要从磁盘读取分区文件,在内存中重新构建出哈希表,对分区内的数据执行普通哈希聚合,因为第一轮哈希之后一个分区内会有不同的key。我们把硬盘中一个个哈希桶中的数据以页为单位往内存里读,读进去之后做第二次哈希,第二次哈希就可以彻底去重并且把阶段1中哈希碰撞的值区分出来,我们把第二次哈希的结果放到最终的哈希表里。