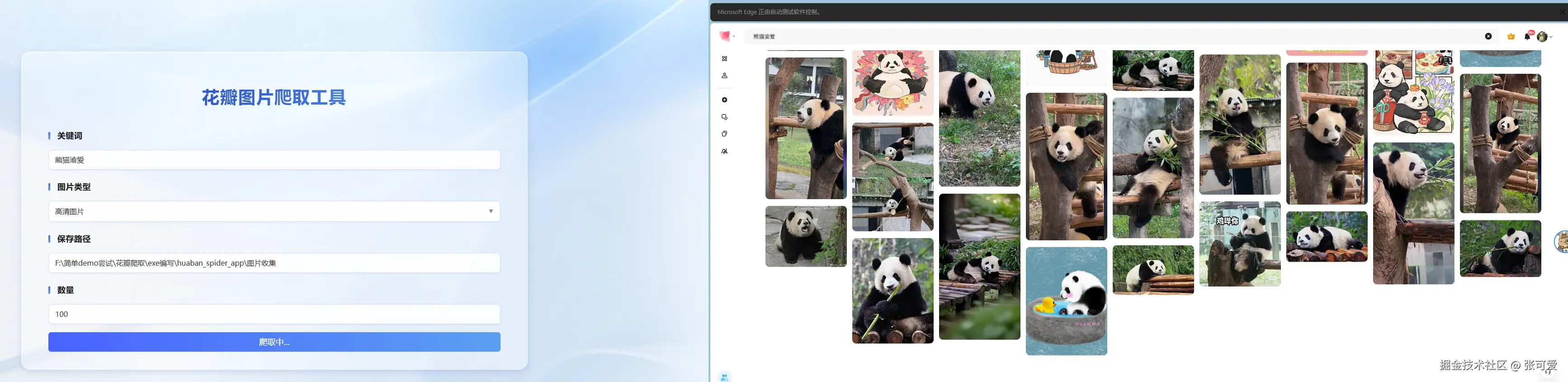
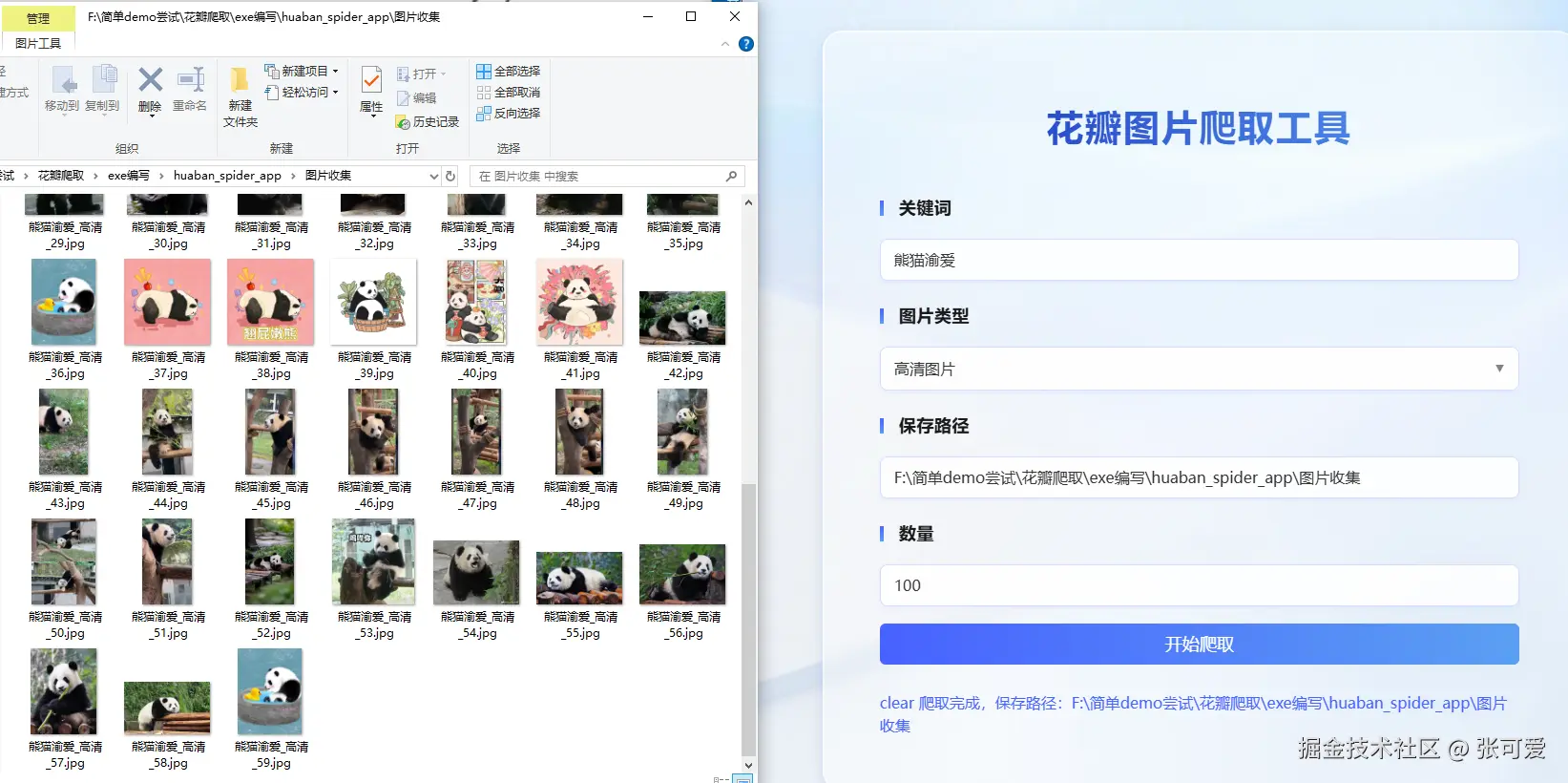
哈喽,小可爱们!辣条爬取花瓣网图片工具来啦~ 这个工具能帮你轻松地抓取花瓣网上的高清图片,用 Vue3 来实现前端界面,Flask 来实现后端。来根辣条叭~~
✨ 技术栈
- 前端: Vue3, Vite, Element-Plus
- 后端: Flask (Python)
- 爬虫: Selenium + requests
- 打包工具: PyInstaller, PyWebView
- 开发环境: Windows 10/11
🌼 效果展示
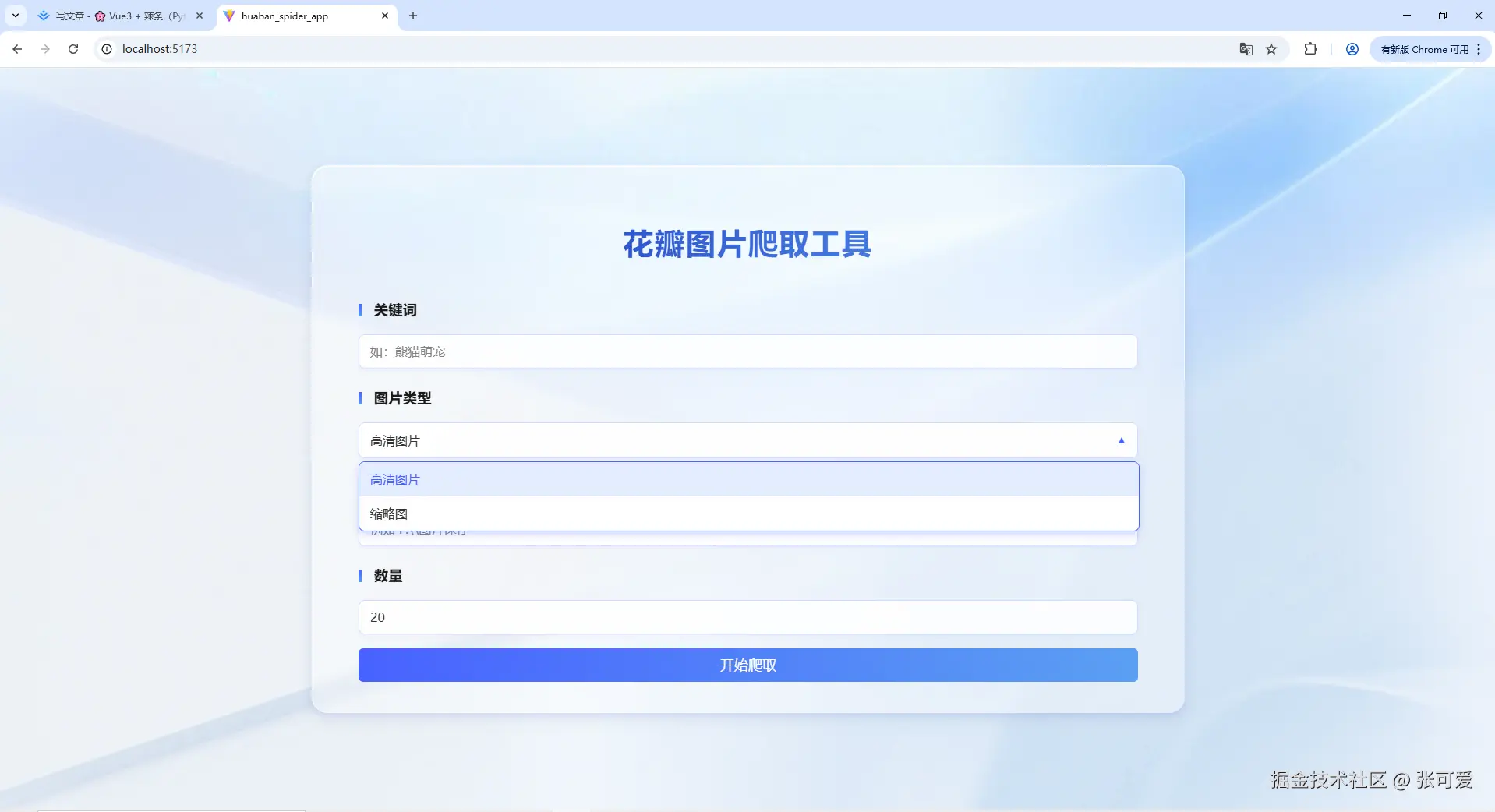
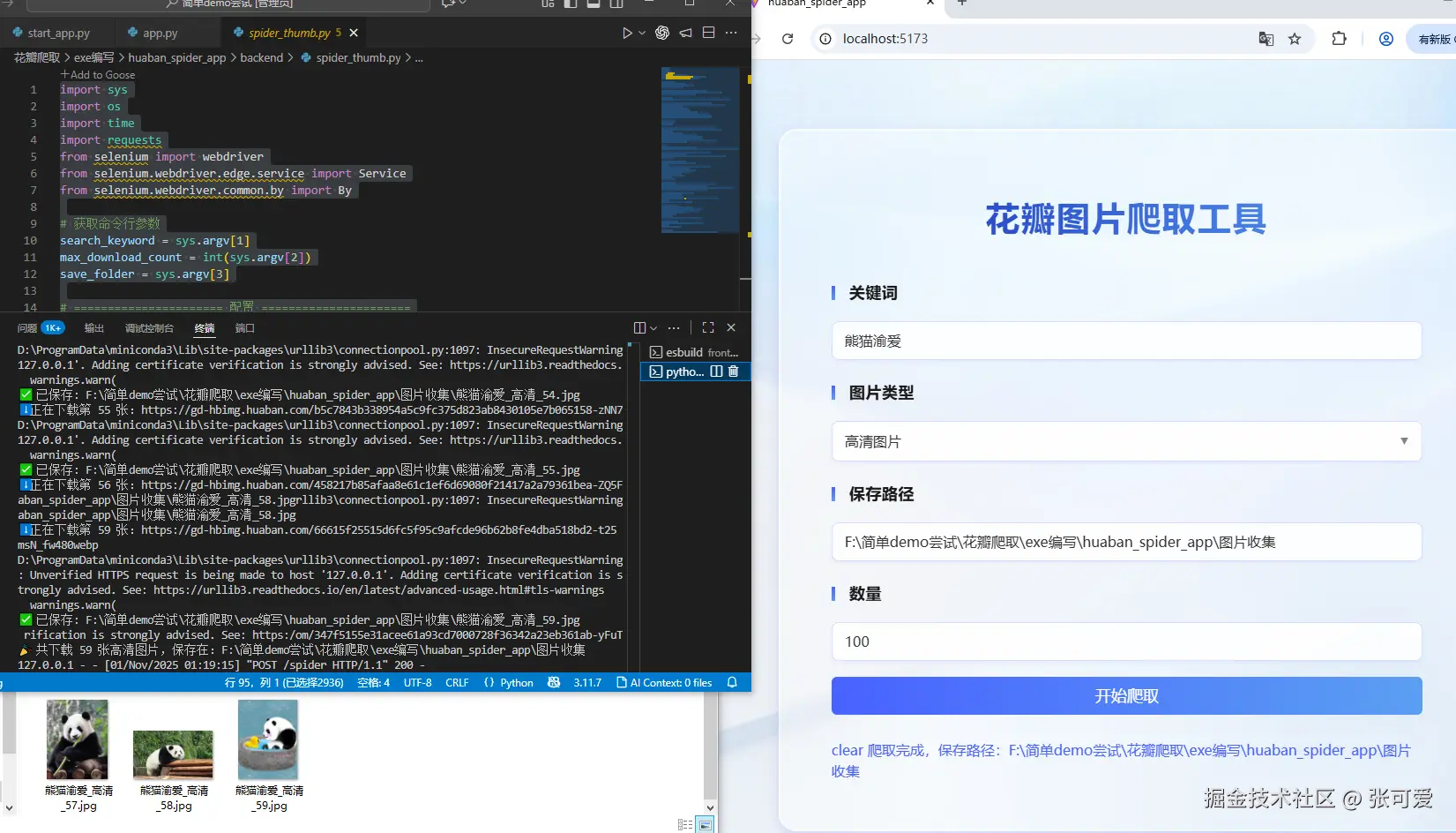
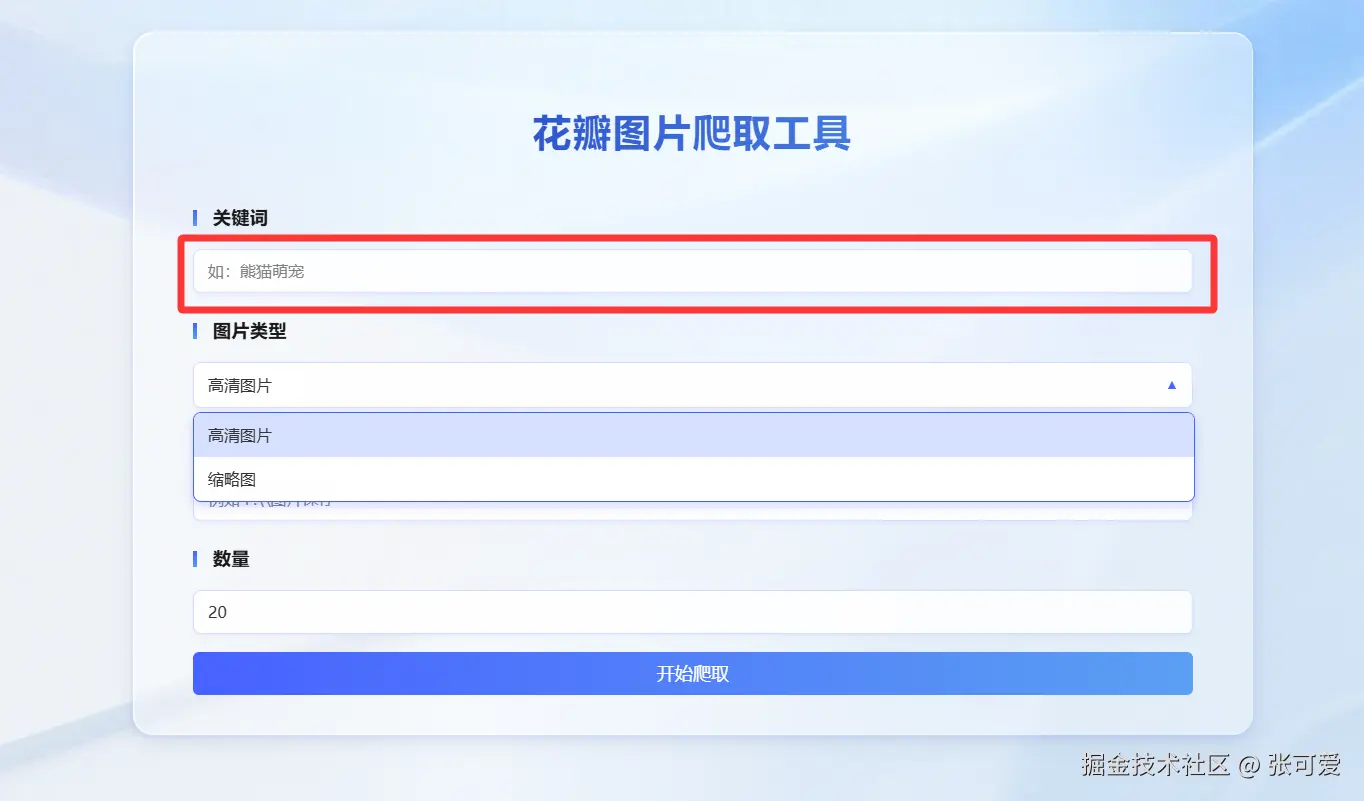
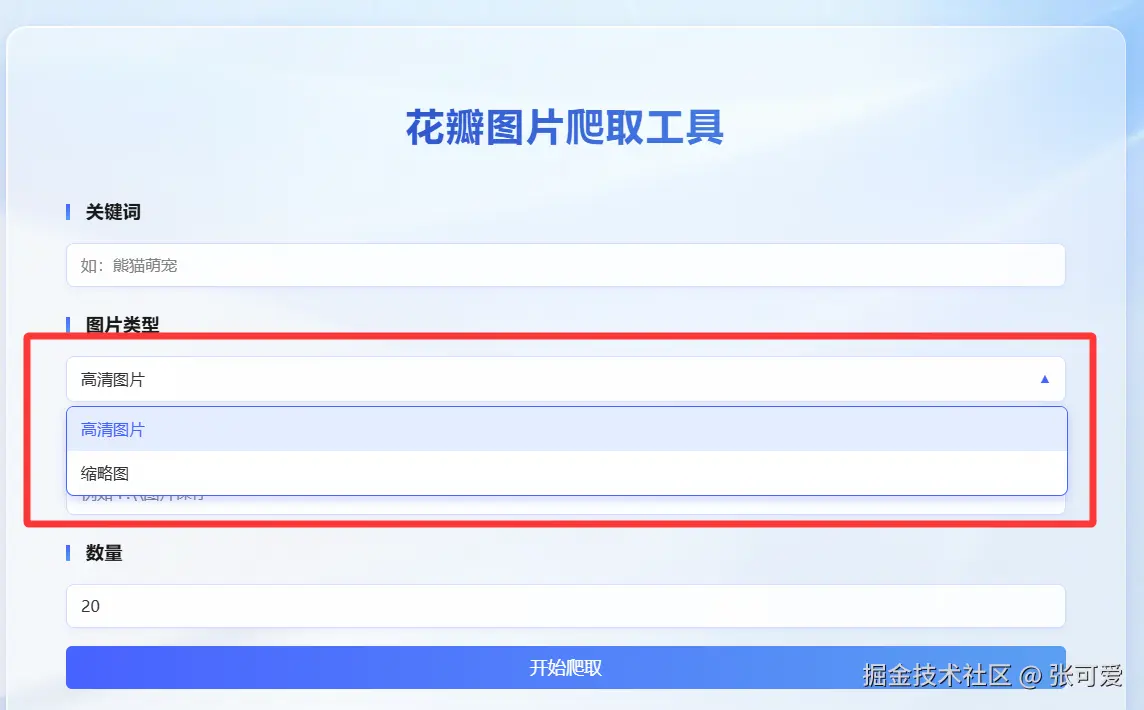
首先,使用 Vue3 打造了界面,用户只需要输入关键词,选择爬取缩略图/高清图片,点击开始爬取即可。构建工具使用的是Vite 。
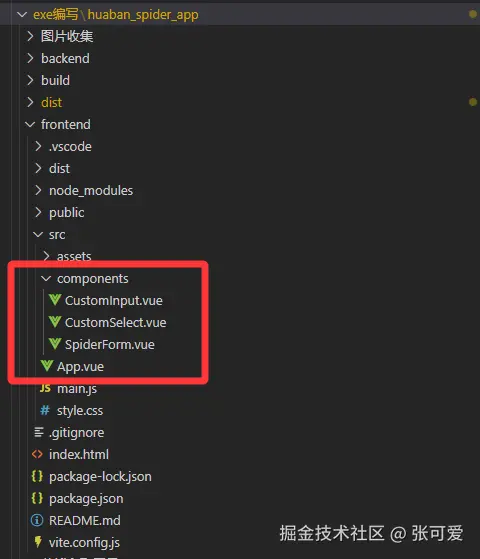
目录结构
csharp
|-- frontend/ # 前端代码
| |-- dist/ # 编译后的静态文件
| |-- public/ # 静态资源
| |-- src/ # Vue 组件和逻辑
|-- backend/ # 后端(Python Flask)
|-- start_app.py # 启动文件主要功能
- 搜索框:输入关键词,搜索花瓣网的高清图片。
- 显示图片:以卡片形式展示搜索结果的图片。
- 下载按钮:支持用户选择图片进行下载。
CustomInput.vue
CustomInput.vue实现了一个自定义的输入框组件
xml
<template>
<div class="custom-input">
<input
:type="type"
v-model="inputValue"
:placeholder="placeholder"
@focus="isFocused = true"
@blur="isFocused = false"
/>
</div>
</template>
<script setup>
import { ref, watch } from "vue"
const props = defineProps({
modelValue: [String, Number],
placeholder: String,
type: {
type: String,
default: "text",
},
})
const emit = defineEmits(["update:modelValue"])
const inputValue = ref(props.modelValue || "")
const isFocused = ref(false)
watch(inputValue, (val) => emit("update:modelValue", val))
watch(() => props.modelValue, (val) => (inputValue.value = val))
</script>
<style scoped>
.custom-input {
position: relative;
width: 100%;
}
/* ✅ 输入框样式(与下拉框 CustomSelect 完全对齐) */
.custom-input input {
width: 100%;
height: 44px; /* ✅ 与下拉框高度一致 */
padding: 0 14px;
font-size: 16px;
line-height: 44px;
color: #333;
border-radius: 8px;
border: 1.5px solid #d6dcff;
background: rgba(255, 255, 255, 0.9);
box-shadow: 0 2px 4px rgba(72, 98, 255, 0.08);
outline: none;
transition: all 0.25s ease;
font-family: "Microsoft YaHei", sans-serif;
font-weight: 400; /* ✅ 与下拉框内文字粗细一致 */
box-sizing: border-box;
}
/* ✅ 去掉数字输入框的上下箭头 (Chrome / Edge) */
.custom-input input::-webkit-outer-spin-button,
.custom-input input::-webkit-inner-spin-button {
-webkit-appearance: none;
}
/* ✅ 去掉 Firefox 的数字输入箭头 */
.custom-input input[type="number"] {
-moz-appearance: textfield;
}
/* ✅ 聚焦状态 */
.custom-input input:focus {
border-color: #4862ff;
box-shadow: 0 0 6px rgba(72, 98, 255, 0.4);
background: rgba(255, 255, 255, 0.95);
}
/* ✅ placeholder 灰色 */
.custom-input input::placeholder {
color: #818281;
font-weight: 400;
}
</style>CustomSelect.vue
CustomSelect.vue实现了一个下拉选择框组件
xml
<template>
<div class="custom-select" @click="toggleSelect">
<div class="selected">
<!-- 如果没有选中任何选项,显示 '请选择图片类型' -->
{{ selectedLabel || '请选择图片类型' }}
<span class="arrow" :class="{ open: isOpen }">▼</span>
</div>
<ul v-show="isOpen" class="options">
<li
v-for="opt in options"
:key="opt.value"
:class="{ active: opt.value === modelValue }"
@click.stop="selectOption(opt)"
>
{{ opt.label }}
</li>
</ul>
</div>
</template>
<script setup>
import { ref, computed, onMounted, onBeforeUnmount } from "vue"
const props = defineProps({
modelValue: String,
options: Array,
})
const emit = defineEmits(["update:modelValue"])
const isOpen = ref(false)
// 切换下拉框状态
const toggleSelect = () => {
isOpen.value = !isOpen.value
}
// 选择选项
const selectOption = (opt) => {
emit("update:modelValue", opt.value)
isOpen.value = false
}
// 计算当前选中的 label,如果没有选中则返回空字符串
const selectedLabel = computed(() => {
const found = props.options.find((o) => o.value === props.modelValue)
return found ? found.label : "" // 如果没有选择,返回空字符串
})
// 点击页面空白处关闭菜单
const handleClickOutside = (event) => {
const selectEl = document.querySelector(".custom-select")
if (selectEl && !selectEl.contains(event.target)) {
isOpen.value = false
}
}
onMounted(() => {
document.addEventListener("click", handleClickOutside)
})
onBeforeUnmount(() => {
document.removeEventListener("click", handleClickOutside)
})
</script>
<style scoped>
.custom-select {
position: relative;
width: 100%;
font-size: 16px;
cursor: pointer;
}
/* 外层选中框样式 */
.selected {
background: rgba(255, 255, 255, 0.9);
border: 1.5px solid #d6dcff;
border-radius: 8px;
padding: 10px 14px;
color: #333; /* ✅ 改这里:选中后文字颜色为深灰,与输入框一致 */
transition: all 0.25s ease;
display: flex;
justify-content: space-between;
align-items: center;
box-shadow: 0 2px 4px rgba(72, 98, 255, 0.08);
backdrop-filter: blur(4px);
}
/* 悬停或展开时 */
.selected:hover,
.custom-select.open .selected {
border-color: #4862ff;
box-shadow: 0 0 6px rgba(72, 98, 255, 0.4);
background: rgba(255, 255, 255, 0.95);
}
/* 箭头状态 */
.arrow {
font-size: 12px;
transition: transform 0.2s ease, color 0.25s ease;
color: #818281;
}
.custom-select:hover .arrow,
.arrow.open {
color: #4862ff;
}
.arrow.open {
transform: rotate(180deg);
}
/* 下拉菜单 */
.options {
position: absolute;
width: 100%;
background: rgba(255, 255, 255, 0.95);
border: 1px solid #4862ff;
border-radius: 8px;
margin-top: 4px;
list-style: none;
padding: 0;
box-shadow: 0 4px 10px rgba(72, 98, 255, 0.25);
z-index: 999;
backdrop-filter: blur(8px);
overflow: hidden;
animation: fadeIn 0.15s ease;
}
/* 下拉项 */
.options li {
padding: 10px 14px;
color: #333; /* ✅ 下拉项默认深灰色 */
transition: all 0.2s ease;
font-weight: 400;
}
/* 悬停项(浅蓝背景 + 蓝字) */
.options li:hover {
background-color: #e5edff;
color: #4862ff;
}
/* ✅ 当前选中项 */
.active {
background-color: #d6e0ff;
color: #1a31bc;
}
@keyframes fadeIn {
from {
opacity: 0;
transform: translateY(-6px);
}
to {
opacity: 1;
transform: translateY(0);
}
}
</style>SpiderForm.vue
SpiderForm.vue实现了一个带背景图的爬虫工具界面,包含关键词、图片类型、保存路径和数量输入框的表单
xml
<template>
<div class="page-wrapper" :style="{ backgroundImage: `url(${bg})` }">
<div class="spider-form">
<h2>花瓣图片爬取工具</h2>
<!-- ✅ 每个 label 前都有竖条 -->
<label>关键词</label>
<CustomInput v-model="keyword" placeholder="如:熊猫萌宠" />
<label>图片类型</label>
<CustomSelect v-model="type" :options="options" />
<label>保存路径</label>
<CustomInput v-model="savePath" placeholder="例如 F:\\图片保存" />
<label>数量</label>
<CustomInput v-model.number="count" type="number" placeholder="30" />
<button @click="startSpider" :disabled="loading">
{{ loading ? "爬取中..." : "开始爬取" }}
</button>
<!-- ✅ 动态显示不同颜色 -->
<p v-if="result" :class="statusClass">{{ result }}</p>
</div>
</div>
</template>
<script setup>
import { ref } from "vue"
import axios from "axios"
import bg from "@/assets/bg.jpg"
import CustomSelect from "@/components/CustomSelect.vue"
import CustomInput from "@/components/CustomInput.vue"
const statusClass = ref("") // ✅ 新增这一行!
const keyword = ref("")
const type = ref("clear")
const savePath = ref("")
const count = ref(20)
const loading = ref(false)
const result = ref("")
// ✅ 修改点1:仍然请求开发环境后端
const options = [
{ value: "clear", label: "高清图片" },
{ value: "thumb", label: "缩略图" },
]
const startSpider = async () => {
loading.value = true
result.value = ""
statusClass.value = "" // ✅ 重置状态
try {
const res = await axios.post("http://127.0.0.1:5000/spider", {
keyword: keyword.value,
type: type.value,
save_path: savePath.value,
count: count.value,
})
// ✅ 如果后端返回包含"错误"或"❌"
if (res.data.msg.includes("错误") || res.data.msg.includes("❌") || res.data.msg.includes("不完整")) {
statusClass.value = "msg-error" // ⬅️ 必加!
} else {
statusClass.value = "msg-success"
}
result.value = res.data.msg
} catch (e) {
result.value = "请求失败,请检查后端是否启动"
statusClass.value = "msg-error" // ⬅️ catch 里也要加!
}
loading.value = false
}
</script>
<style scoped>
html,
body {
width: 100%;
height: 100%;
margin: 0;
padding: 0;
overflow: hidden;
}
.page-wrapper {
position: fixed;
top: 0;
left: 0;
width: 100vw;
height: 100vh;
background-repeat: no-repeat;
background-position: center center;
background-size: cover;
display: flex;
justify-content: center;
align-items: center;
}
/* ✅ 修改点2:优化表单卡片外观 */
.spider-form {
width: 70vw;
font-size: 18px;
max-width: 1000px;
min-width: 300px;
padding: 40px 60px;
border-radius: 20px;
background: rgba(255, 255, 255, 0.4);
backdrop-filter: blur(6px);
color: #181818;
display: flex;
flex-direction: column;
gap: 18px;
text-align: left;
font-weight: 400;
border: #fff;
position: relative;
overflow: hidden;
/* ✅ 柔和立体阴影 */
box-shadow: 0 4px 10px rgba(72, 98, 255, 0.15),
0 8px 25px rgba(0, 0, 0, 0.04);
}
/* ✅ 修改点3:为每个 label 加上蓝色竖条 */
.spider-form label {
position: relative;
display: flex;
align-items: center;
gap: 16px;
/* 竖条与文字间距 */
font-weight: 600;
color: #1a1a1a;
letter-spacing: 0.5px;
margin-top: 6px;
}
/* ✅ 蓝色竖条渐变特效 */
.spider-form label::before {
content: "";
display: inline-block;
width: 4px;
height: 16px;
background: linear-gradient(180deg, #4862ff 0%, #5b9ff3 100%);
}
/* ✅ 输入框字体保持轻盈 */
.spider-form input {
font-weight: 400;
}
/* ✅ 白色渐变描边特效 */
.spider-form::before {
content: "";
position: absolute;
inset: 0;
border-radius: 20px;
padding: 1.5px;
background: linear-gradient(145deg, rgba(255, 255, 255, 0.8), rgba(255, 255, 255, 0.2));
-webkit-mask:
linear-gradient(#fff 0 0) content-box,
linear-gradient(#fff 0 0);
-webkit-mask-composite: xor;
mask-composite: exclude;
pointer-events: none;
}
/* ✅ 标题样式 */
.spider-form h2 {
font-size: 38px;
font-weight: bold;
text-align: center;
background: linear-gradient(90deg, #1a31bc 0%, #5b9ff3 100%);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
letter-spacing: 2px;
margin-bottom: 20px;
}
/* ✅ 按钮样式(保持一致) */
button {
background: linear-gradient(90deg, #4862ff, #5b9ff3);
color: white;
border: none;
padding: 10px;
border-radius: 6px;
cursor: pointer;
font-size: 18px;
transition: background 0.3s ease;
}
button:hover {
background: linear-gradient(90deg, #3952e2, #487ffb);
}
.spider-form p {
font-weight: 500;
font-size: 16px;
margin-top: 10px;
}
:deep(.msg-success) {
color: #4862ff !important;
}
:deep(.msg-error) {
color: #e74c3c !important;
}
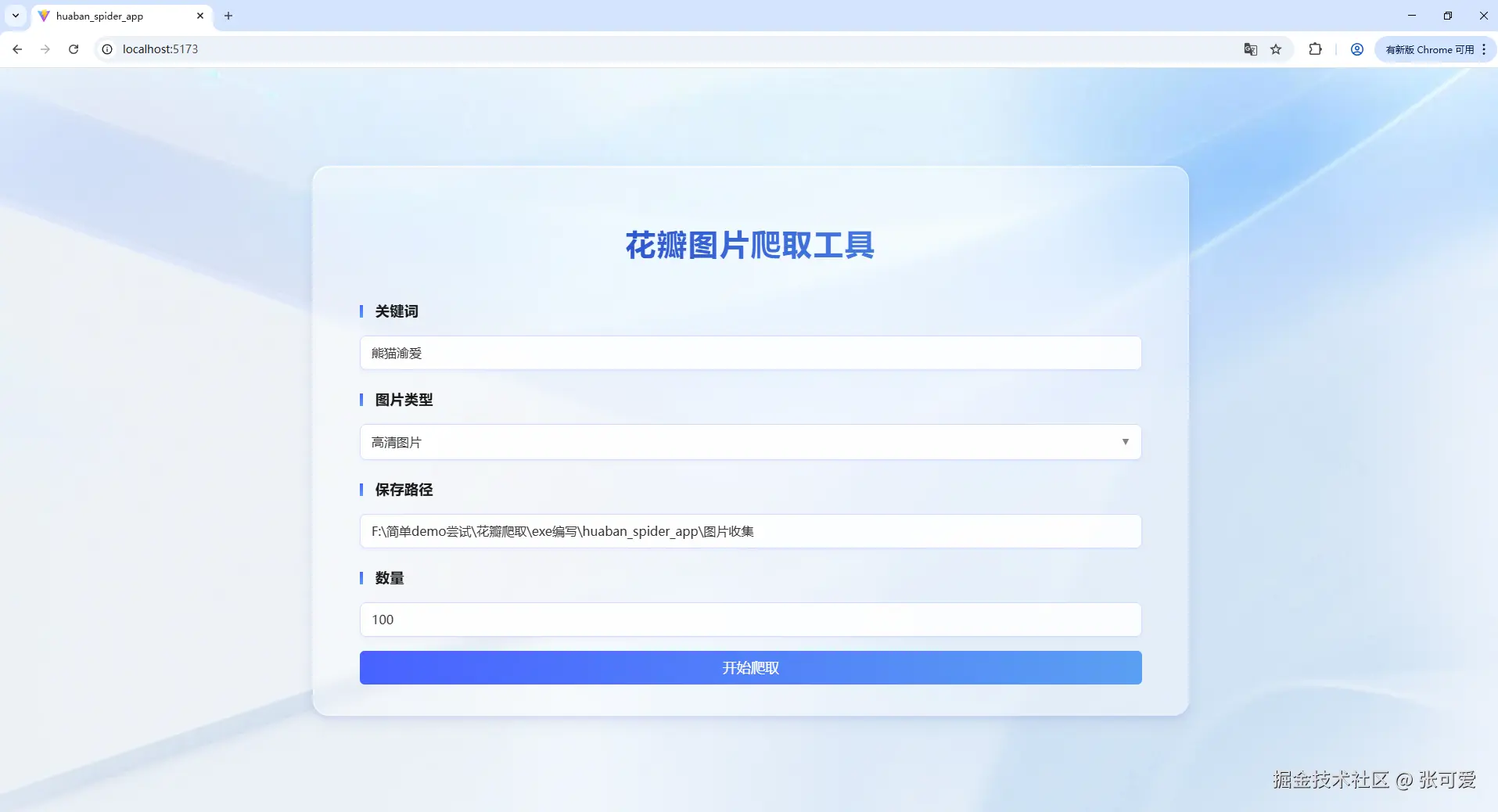
</style>🍀 后端部分:Flask + 爬虫实现图片抓取
后端使用 Flask 搭建 RESTful API,爬取花瓣网上的图片。爬虫部分使用 Selenium 控制浏览器加载页面,requests 用来下载图片。
app.py
app.py实现了一个 Flask 后端接口,用于处理爬虫请求并执行相应的爬取任务,支持根据不同类型(高清或缩略图)进行选择。通过 subprocess 调用 Python 脚本来执行爬取操作,并返回爬取结果或错误信息。
kotlin
from flask import Flask, request, jsonify
from flask_cors import CORS
import subprocess
import os
app = Flask(__name__)
CORS(app) # ✅ 开启跨域支持
@app.route("/spider", methods=["POST"])
def spider():
data = request.json
keyword = data.get("keyword")
spider_type = data.get("type") # clear / thumb
save_path = data.get("save_path")
count = str(data.get("count", 30))
if not keyword or not save_path:
return jsonify({
"msg": "参数不完整",
"status": "error"
})
py_file = "spider_clear.py" if spider_type == "clear" else "spider_thumb.py"
try:
subprocess.run(
["python", py_file, keyword, count, save_path],
cwd=os.path.dirname(__file__),
check=True
)
return jsonify({
"msg": f"{spider_type} 爬取完成,保存路径:{save_path}",
"status": "success"
})
except Exception as e:
return jsonify({
"msg": f"爬取出错:{e}",
"status": "error"
})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)spider_clear.py
spider_clear.py通过 Selenium 打开花瓣网,模拟滚动加载并提取图片链接,根据用户提供的关键词、图片类型、保存路径和数量,下载相应数量的图片。若直接下载失败,代码会尝试通过 API 获取图片的真实链接并下载。
python
import sys
import os
import time
import requests
import random
import re
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
# ====================== 🧠 命令行参数 ======================
search_keyword = sys.argv[1]
max_download_count = int(sys.argv[2])
save_folder = sys.argv[3]
# ====================== 🧱 基础配置 ======================
driver_path = r'F:\简单demo尝试\花瓣爬取\清晰图片爬取\msedgedriver.exe'
os.makedirs(save_folder, exist_ok=True)
url = f'https://huaban.com/search?q={search_keyword}&sort=created_at&type=pin'
# ====================== 🧩 Edge 设置 ======================
user_data_dir = r'C:\Users\Admin\AppData\Local\Microsoft\Edge\User Data'
profile_name = 'Default'
service = Service(driver_path)
options = webdriver.EdgeOptions()
options.add_argument("--start-maximized")
options.add_argument(f"user-data-dir={user_data_dir}")
options.add_argument(f"profile-directory={profile_name}")
options.add_argument('--ignore-certificate-errors')
driver = webdriver.Edge(service=service, options=options)
# ====================== 🚀 打开网页 ======================
driver.get(url)
time.sleep(5)
# ====================== 🍪 提取 Cookies ======================
session = requests.Session()
for cookie in driver.get_cookies():
session.cookies.set(cookie["name"], cookie["value"])
# ====================== ⬇️ 滚动加载 ======================
scroll_times = 0
while scroll_times < 20 and len(driver.find_elements(By.CSS_SELECTOR, "img.hb-image")) < max_download_count:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(random.uniform(1.5, 2.5))
scroll_times += 1
print(f"⬇️ 第 {scroll_times} 次滚动,当前检测图片数:{len(driver.find_elements(By.CSS_SELECTOR, 'img.hb-image'))}")
# ====================== 🖼️ 提取图片及 pin_id ======================
img_infos = []
img_elements = driver.find_elements(By.CSS_SELECTOR, "a[href*='/pins/'] > img.hb-image")
for i in range(len(img_elements)):
try:
img = driver.find_elements(By.CSS_SELECTOR, "a[href*='/pins/'] > img.hb-image")[i]
src = img.get_attribute("src") or ""
srcset = img.get_attribute("srcset") or ""
link = srcset.split()[0] if srcset else src
# 提取上层 a 标签中的 pin_id
parent = img.find_element(By.XPATH, "..")
pin_url = parent.get_attribute("href")
pin_id = re.search(r'/pins/(\d+)', pin_url).group(1) if pin_url else None
if link and pin_id and "hb_logo" not in link and "huaban.com" in link:
img_infos.append({"src": link, "pin_id": pin_id})
except Exception as e:
print(f"⚠️ 图片 {i+1} 失效,跳过({e.__class__.__name__})")
continue
print(f"🖼️ 共获取 {len(img_infos)} 张图片链接,准备下载(最多 {max_download_count} 张)")
# ====================== 🌐 请求头池 ======================
ua_list = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/125 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 Safari/605.1.15",
"Mozilla/5.0 (X11; Linux x86_64) Gecko/20100101 Firefox/126.0",
]
# ====================== 📦 下载函数 ======================
def try_download_v2(img_info, path):
"""下载图片:先直接下,不行就通过 API 修复"""
url = img_info["src"]
pin_id = img_info["pin_id"]
try:
headers = {
"User-Agent": random.choice(ua_list),
"Referer": "https://huaban.com/"
}
r = session.get(url, headers=headers, timeout=10, verify=False)
# ✅ 正常成功
if r.status_code == 200 and len(r.content) > 5000:
with open(path, "wb") as f:
f.write(r.content)
return True
# ❌ 如果 404,则调用 API 修复
print(f"🚨 状态码 {r.status_code},尝试 API 修复 pin={pin_id}")
api_url = f"https://huaban.com/api/pins/{pin_id}?fields=pin:PIN_DETAIL"
resp = session.get(api_url, headers=headers, timeout=10, verify=False)
if resp.status_code == 200:
data = resp.json()
file_info = data.get("pin", {}).get("file", {})
if "bucket" in file_info and "key" in file_info:
real_url = f"https://{file_info['bucket']}.huaban.com/{file_info['key']}"
print(f"🔄 新地址: {real_url}")
r2 = session.get(real_url, headers=headers, timeout=10, verify=False)
if r2.status_code == 200 and len(r2.content) > 5000:
with open(path, "wb") as f:
f.write(r2.content)
return True
except Exception as e:
print(f"❌ 异常: {e}")
return False
# ====================== 🚀 下载流程 ======================
downloaded = 0
for idx, img_info in enumerate(img_infos[:max_download_count]):
ext = ".webp" if ".webp" in img_info["src"] else ".jpg"
save_path = os.path.join(save_folder, f"{search_keyword}_高清_{idx + 1}{ext}")
print(f"⬇️ 正在下载第 {idx + 1} 张:{img_info['src']}")
success = try_download_v2(img_info, save_path)
if success:
print(f"✅ 已保存: {save_path}")
downloaded += 1
else:
print(f"❌ 下载失败: {img_info['src']}")
driver.quit()
print(f"🎉 共下载 {downloaded} 张高清图片,保存在:{save_folder}")spider_thumb.py
spider_thumb.py通过 Selenium 自动化浏览器,打开花瓣网搜索页面,获取缩略图链接,并尝试下载。若下载失败,代码会通过修改图片链接中的参数进行重试,直到成功或超出最大下载数量。
python
import sys
import os
import time
import requests
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.common.by import By
# 获取命令行参数
search_keyword = sys.argv[1]
max_download_count = int(sys.argv[2])
save_folder = sys.argv[3]
# ====================== 配置 ======================
driver_path = r'F:\简单demo尝试\花瓣爬取\缩略图爬取\msedgedriver.exe'
os.makedirs(save_folder, exist_ok=True)
# 花瓣搜索URL
url = f'https://huaban.com/search?q={search_keyword}&sort=created_at&type=pin'
# ====================== Edge 配置 ======================
user_data_dir = r'C:\Users\Admin\AppData\Local\Microsoft\Edge\User Data'
profile_name = 'Default'
service = Service(driver_path)
options = webdriver.EdgeOptions()
options.add_argument("--start-maximized")
options.add_argument(f"user-data-dir={user_data_dir}")
options.add_argument(f"profile-directory={profile_name}")
driver = webdriver.Edge(service=service, options=options)
# 打开花瓣搜索页
driver.get(url)
time.sleep(5)
# ====================== 提取缩略图链接 ======================
img_elements = driver.find_elements(By.CSS_SELECTOR, "img.hb-image")
img_urls = []
for img in img_elements:
src = img.get_attribute("src") or ""
srcset = img.get_attribute("srcset") or ""
link = srcset.split()[0] if srcset else src
if link and "hb_logo" not in link and "huaban.com" in link:
img_urls.append(link)
# 去重
img_urls = list(dict.fromkeys(img_urls))
print(f"🖼️ 共获取 {len(img_urls)} 张缩略图链接,准备下载(最多 {max_download_count} 张)")
# ====================== 下载图片 ======================
session = requests.Session()
headers = {"User-Agent": "Mozilla/5.0", "Referer": "https://huaban.com/"}
downloaded = 0
def try_download(url, path):
"""尝试下载指定URL,返回是否成功"""
try:
r = session.get(url, headers=headers, timeout=8)
if r.status_code == 200:
with open(path, "wb") as f:
f.write(r.content)
return True
except Exception as e:
pass
return False
# 开始下载缩略图
for idx, base_url in enumerate(img_urls[:max_download_count]):
ext = ".webp" if ".webp" in base_url else ".jpg"
save_path = os.path.join(save_folder, f"{search_keyword}_缩略_{idx + 1}{ext}")
print(f"⬇️ 正在下载第 {idx + 1} 张:{base_url}")
# 获取候选链接列表,只保留 _fw658
candidate_urls = []
if "_fw" in base_url:
candidate_urls = [re.sub(r"_fw\d+", "_fw658", base_url)]
else:
candidate_urls = [base_url]
success = False
for candidate in candidate_urls:
if try_download(candidate, save_path):
print(f"✅ 已保存: {save_path}")
success = True
break
else:
print(f"⚠️ 尝试失败:{candidate}")
if not success:
print(f"❌ 全部缩略下载失败:{base_url}")
else:
downloaded += 1
driver.quit()
print(f"🎉 共下载 {downloaded} 张缩略图,保存在:{save_folder}")🦋 运行后效果展示