本文从原理到实践系统地分享了如何高效使用AI编程工具。
- 涵盖其底层机制(如Token计算、工具调用、Codebase 索引与 Merkle Tree)
- 提升对话质量的方法(如规则设置、渐进式开发)
- 实际应用场景(如代码检索、绘图生成、问题排查)
- 并推荐了结合AI的编码最佳实践,包括文档、注释、命名规范和安全合规
旨在帮助不同经验水平的开发者真正把AI工具用好。
引言
在使用 AI 编程的过程中,我知道大家偶尔会有如下感受或者疑问:
- 一口气生成整个需求代码,然后打补丁快?还是边写代码边提问快?
- AI 的能力边界在哪?什么场景下适合使用?什么场景下适合手搓?
- AI 只能帮我写代码吗?能不能探索下新场景?
从原理讲起,了解 AI 编程工具的能力和边界
Token 计算机制
原理
我们知道不同 model 都有不同大小的上下文,上下文越大的模型自然能接受更大的提问信息,那么在 cursor 中我们的任意一次聊天,大致会产生如下的 token 计算:
- 初始 Token 组成:初始输入 = SystemPrompt +用户问题 + Rules + 对话历史
- 用户问题 : 我们输入的文字 + 主动添加的上下文(图片、项目目录、文件)
- Rules:project rule + user rule + memories
- 工具调用后的 Token 累积:cursor 接收用户信息后开始调用 tools 获取更为详细的信息,并为问题回答做准备
总 Token = 初始输入 + 所有工具调用结果
举个例子
用户粘贴了一段代码,以及一张相关图片,询问"这个函数有什么问题?",然后 AI 需要调用工具来分析代码。
- 初始Token组成
SystemPrompt
css
你是一个专业的代码审查助手,能够分析代码问题并提供改进建议...
注意:Cursor调用大模型的完整的提示词在"2.5 调用LLM的Prompt"部分,感兴趣的同学可以自行观看。UserPrompt
bash
用户输入文字: "这个函数有什么问题?"
主动添加的上下文:
- 图片: [相关图片]
- 用户附加文件: [Line12-22]somemodule/src/main/java/com/xxx/xxx/service/ExampleService.java
- 项目目录: /Users/KuBo/IdeaProjects/someproject/
- 当前文件: somemodule/src/main/java/com/xxx/xxx/service/ExampleService.javaRules
makefile
projectrule: 多模块Maven项目,使用Java 8,包名统一为com.xxx.xxx.*...
userrule: 始终使用中文回复,不要使用行尾注释,单行不超过120字符...
memories: [相关的项目记忆和上下文信息]对话历史
makefile
用户: 你好,我想了解一下这个项目的结构
AI: 这是一个多模块的Maven项目,主要包含以下模块...- 工具调用后的Token累积
工具调用1: 读取文件内容
ini
工具调用: read_file
参数: target_file = "somemodule/src/main/java/com/xxx/xxx/service/ExampleService.java"
结果: [返回完整的Java文件内容,约2000个token]工具调用2: 代码搜索
ini
工具调用: codebase_search
参数: query = "Java方法异常处理最佳实践"
结果: [返回相关的代码示例和最佳实践,约1500个token]工具调用3: 语法检查
ini
工具调用: read_lints
参数: paths = ["somemodule/src/main/java/com/xxx/xxx/service/ExampleService.java"]
结果: [返回linter错误信息,约300个token]最终Token计算
初始输入 = SystemPrompt(500) + 用户问题(200) + Rules(800) + 对话历史(300) = 1800 tokens
工具调用结果 = 文件内容(2000) + 搜索结果(1500) + 语法检查(300) = 3800 tokens
总Token = 1800 + 3800 = 5600 tokens
工具调用(Function Call)
搜索
用于搜索代码库和网络以查找相关信息的工具。

编辑
用于对文件和代码库进行特定编辑的工具。

运行
Chat 可以与您的终端进行交互。

MCP
聊天功能可以使用配置的 MCP 服务器与外部服务进行交互,例如数据库或第三方 API。

Browser
Cursor 新版本对浏览器功能做了升级,原生新增了 Brower Automation 工具,不需要再手动配置相关MCP。它可以直接操作浏览器,对于前端自动化有一定的帮助,下面是官方演示。
代码库检索
为何要了解
Cursor 代码库工具的检索和构建,都是经过 Codebase Indexing 流程实现的,它其实就是在对整个代码仓库做 RAG,即:将你的代码转换为可搜索的向量。
了解这一部分将有助于:
- 提示词的编写:如何提问,编写什么样的 prompt,才能让模型准确地找到它需要的代码?
- 代码规范:在编码时,什么样的代码风格是"模型友好"的?
工作原理
在用户导入项目时,Cursor 会启动一个 Codebase Indexing 流程,它的进度可以在 Preference - Cursor Settings - Indexing & Docs 中看到。
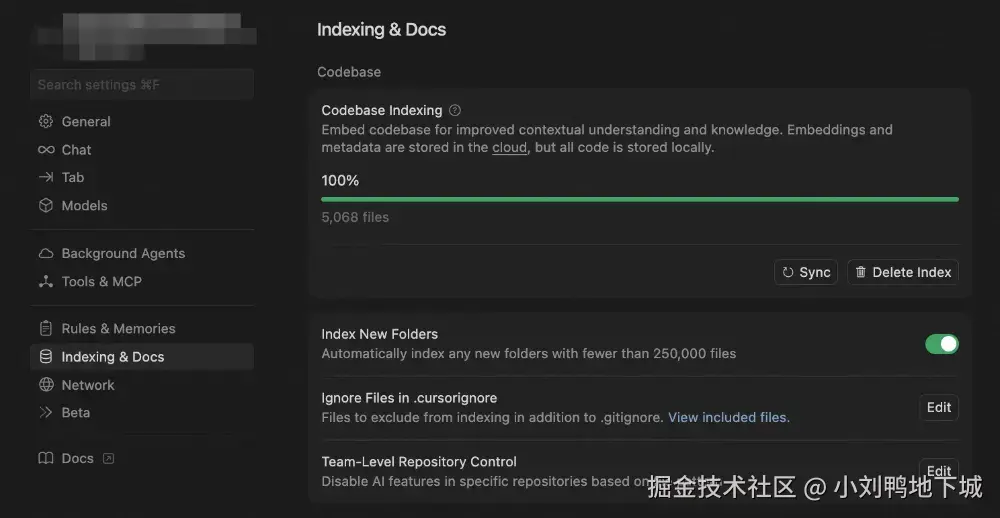
更多细节
索引构建
项目初始化阶段、增量同步机制、服务器端处理
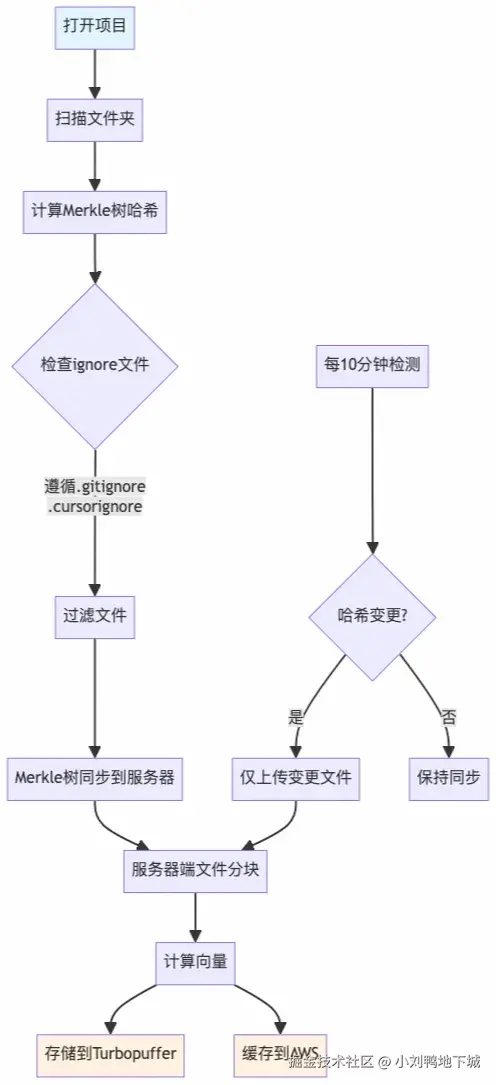
用户查询流程
查询向量化、相似度搜索、代码片段获取、AI答案生成
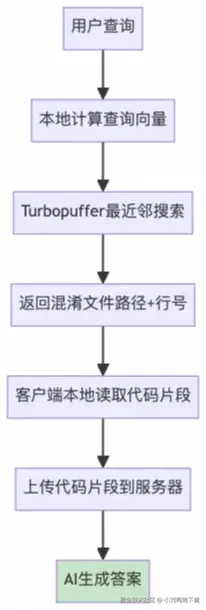
Merkle Tree 增量块验证
Cursor 的代码库检索是使用RAG实现的,在召回信息完整的同时做到了极致的检索速度,体验下来要比Claude Code 快很多。
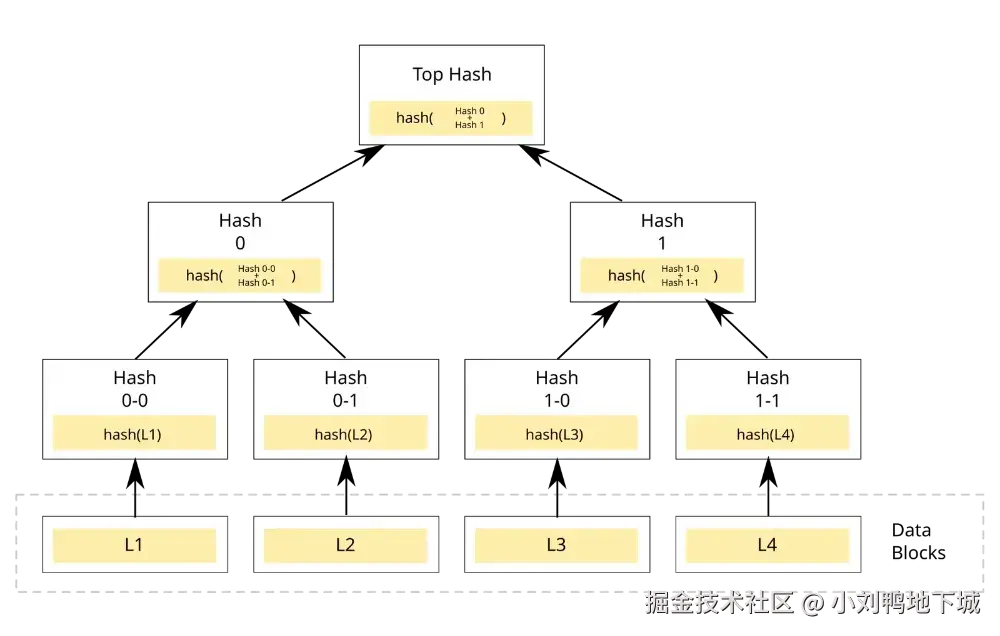
对于"增量导入"的部分,我们介绍下 Cursor 实际使用的一种数据结构------默克尔树。实际上我们常用的版本控制工具Git的底层用的也是这种数据结构。
Cursor 调用 LLM 的 Prompt
在原理方面,这里提供了AI Coding工具调用大预言模型所使用的prompt。可以看到,它其实跟我们平时写代码调用模型是很相似的,但是在工具调用、上下文获取上都有针对Coding领域非常细节的定制化。
Claude Code CLI 工具基础原理
国内如何用上CLI工具
如何使用百炼提供的 Qwen3 Coder 模型,得到几乎满血的 CLI 工具体验
Claude Code、CodeX 等常用 CLI 工具都支持供应商替换
bash
npm install -g @anthropic-ai/claude-code
claude
json
# .claude.json
"env": {
"ANTHROPIC_API_KEY": "",
"ANTHROPIC_BASE_URL": "https://dashscope.aliyuncs.com/apps/anthropic"
},
"hasCompletedOnboarding": trueClaude Code 内部 Prompt
与 Cursor 类似,Claude Code 也有自己的一套模型调用提示词,准确来说,这是一套完整的上下文工程。这里面有用户环境、用户问题、系统提示词、工作过程管理(自动生成并按顺序执行TODO)等部分。
最佳实践
提升对话质量:合理利用上下文窗口
由于AI模型的上下文窗口存在容量限制,我们需要在有限空间内最大化信息价值。
- 进行清晰的问题描述
在上面的原理部分,我们介绍了模型是如何进行代码库理解的。因此,在描述问题时,我们最好能给出具体的功能、文件名、方法名、代码块,让模型能够通过语义检索等方式,用较短的路径找到代码,避免在检索这部分混杂太多弱相关内容,干扰上下文。
- 把控上下文长度
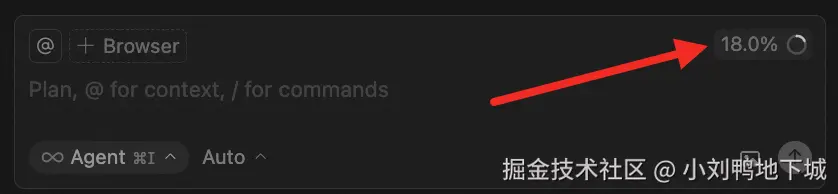
现在不少工具都支持上下文占用量展示,比如这里的18.0%表示之前的对话占用的上下文窗口比例。超出这个比例之后,工具会对历史内容进行压缩,保证对话的正常进行。
但被压缩后的信息会缺失细节,所以建议大家在处理复杂问题时,采用上下文窗口大的模型/模式,尽量避免压缩。
- 尽可能地使用 Revert 和新开对话
省上下文是一方面,维持上下文的简洁对模型回答质量提升也是有帮助的。因此,如果你的新问题跟历史对话关系不大,就最好新开一个对话。
在多轮对话中,如果有一个步骤出错,最好的方式也是会退到之前出错的版本,,基于现状重新调整 prompt 和更新上下文;而不是通过对话继续修改。否则可能导致上下文中存在过多无效内容。
这里回滚在IDE类型的工具里操作很方便,点一下"Revert"按钮即可。不过如果使用的是 Claude Code 等 CLI 类型的工具,回滚起来就没有这么方便,可以考虑在中间步骤多进行 commit。
- 给出多元化的信息
我们不只可以粘代码、图片进去,还可以让模型参考网页、Git历史、当前打开的文件等,这些 IDE 类的工具支持的比较好,因为是在IDE环境里面,而CLI在终端中,限制就要多一些(但更灵活)。
关于 Rule
其实这就是一种可复用的上下文。比如,我在整个开发过程中,提炼出了很多共性规则(不要写太多注释、不要动不动就生成测试文件),就可以把它们沉淀为Rule,让模型在每次的对话中自动复用。其核心主要是通过复用的思想来节约精力。
Cursor 中的 Rule
- Project Rule
跟项目绑定的Rule,它的本质是在 .git 的同级目录下维护一个 .cursor 的目录,在这里面存放自定义的规则文本,然后在每次会话时根据你的设置,决定要不要把这些内容贴到上下文中。可以通过 /Generate Cursor Rules 命令来自动生成。
- User Rule
跟用户绑定的全局设置,它与项目维度的规则类似,只不过生效范围是全局,它的对应规则文件在用户的根目录下面。需要注意的是,这个规则的更新不是实时生效的,可能要等10分钟左右,推测这里也用到了RAG,离线进行索引构建。
Claude Code / CodeX 中的 Rule
项目维度规则,在CLI工具中统一被整合进了使用/init指令生成的Markdown文件中,被存放在项目根目录中。Claude 生成的文件为 CLAUDE.md,CodeX 生成的文件为 AGENT.md。
在对话中,这些文件会被完整的贴进上下文,因此如果你有自己的定制化需求,也可以加在这里面。比如我就加上了"永远使用中文"这一条。

生成这些项目规则,本身也是通过Prompt+工具调用进行的,本质上是工具自动帮你贴了一大串Prompt进去。这里使用CodeX的提示词进行举例。
采用渐进式开发,而不是大需求一口气梭哈
根据实践经验,不推荐输出完方案后让 AI 一口气基于方案完成需求(非常小的需求除外),需求越大代码质量越烂。我的使用方式是,跟 AI 进行结对编程,讨论具体的方案是什么,这个场景下的最佳实践是什么,拆解需求后,人工控制每一个块的代码生成。生成之后,可以咨询一下代码实现是否优雅,是否有重构空间,根据需要进行修改。
总结来说,有这些好处:
- 因为上下文窗口有限,任务粒度越小,AI 完成度越高
- 分步骤代码量便于做 Code Review
讲讲应用
上面说的都是一些准则类的经验,下面将结合具体场景,看一下如何把这些规则落地。以及帮助大家了解一下,除了纯粹的写代码,AI 还可以帮我们做什么。
快速熟悉项目 & 自然语言检索代码
arduino
讲解一下这个项目的每个module都是用来做什么的,并且给出包依赖关系图。
我希望实现一个「什么什么」功能,需要修改的部分包括「这里」和「那里」,我的代码放在哪个包/目录下比较合适?仔细分析项目结构,并给出你的理由。
我在找「某个某个」功能的实现,请帮我在仓库里搜寻,并给出它的核心具体代码位置和片段,并附上简洁的说明。PlantUML / Mermaid 文本绘图生成
这里是打算让AI帮忙画一下某个功能的前后端交互流程图,先是把接口请求顺序在浏览器里进行了截图:
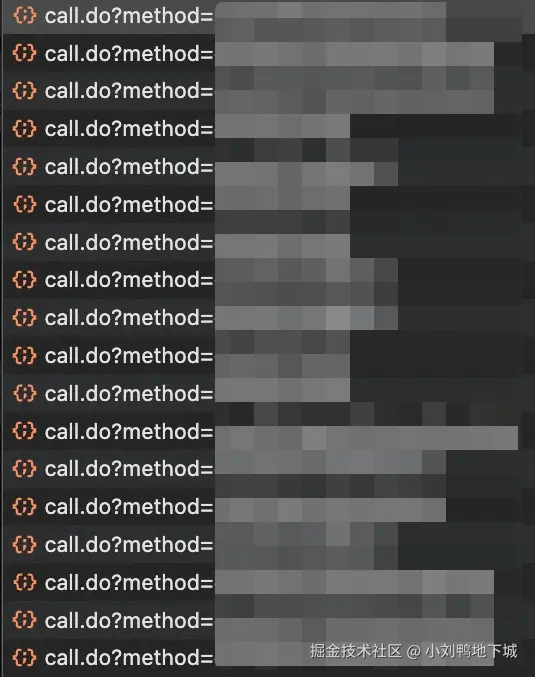
然后把我的需求+我的判断(比如图里有一些接口实际上和这个需求并不相关)一起告诉AI:
AI在进行了一长串分析之后,也是给出了比较准确的流程图。
问题排查
这里是用真实遇到的一个问题举例子,这张图片是执行流程图的展示,当时遇到的问题是这个流程的产出结果出现了问题,大致定位到是图里的左侧节点有问题:
由于对这个仓库并不熟悉,于是暂时交给AI帮忙翻代码排查:
最后人工验证了一下,给出的问题分析和解决方案确实非常详细且准确。在对于项目不熟悉的情况下,这是一种快速进行检索和排查的有效手段。
补充网页信息到上下文
Web 是相对来说比较容易忽视,但是又非常好用的工具,可以通过@Web的进行添加,也可以直接粘链接进去。需要注意的是,需要进行权限认证的网页(如内网)无法直接被读取。
这里直接粘贴链接进去,让大模型帮忙总结文章内容,也可以基于它直接对任意网页进行问答。
推荐 Coding 方式
这里主要是一些实践性的探索,目前尚未进行推广,原因是还没有找到一种提升大、好维护、可移植的工具,团队同学的偏好也各不相同。当然,在这方面,团队内部已经有很多探索,目前在积极进行投入和尝试。
rule 的制定和优化
最基本应该包含你当前项目的技术栈使用,以及对应依赖版本;除此之外应该包含编码明确要求的规范。

注:使用一套统一的rule,需要统一使用cursor,可能不符合个人习惯。但是在使用其它 AI 编程工具时,维护一个项目规则文档,并在对话时手动添加至上下文,可以达到一样的效果。
文档
根目录下,存放以下内容
README.md
仓库门面,包含:简介、核心特性、快速开始、其它重要文件的说明和索引
CHANGELOG.md
需要发版的仓库可以考虑添加
- 新增功能
- bug修复
- breaking changes(破坏性变更)
- 注意事项等
ARCHITECTURE.md
架构复杂且需要多人协作的仓库可以考虑添加
- 整体架构
- 模块划分
- 核心逻辑流程图
/docs 目录
目的:让团队成员快速理解项目、高效协作
内容:兼顾实用性、准确性、易维护性
- 错误码体系、错误码格式、
- 错误码分类、
- 详细场景、
- 异常处理指南、
- 可重试/不可重试、
- 异常抛出原则、
- 日志打印要求、
- 常见异常案例、
- 常用工具类
注:需根据项目内容修改,以上仅为个人推荐
注释和命名
- 方法、参数等注释,尽量保证语义清晰、内容完整;
- 可以考虑添加调用方的使用场景;
- 适当添加行内注释,明确每个分支的场景和期望处理方式;
- 命名需要清晰,无歧义;
- AI 生成量 > 80%的文件,建议使用 @author AI Assistant,注明是AI生成,便于维护和统计。
安全合规问题
需要根据公司规定,合规使用。
推广方式
在团队内部创建了一个代码仓库,作一下示例,主要维护这些内容
范围确定
- 核心代码库梳理
- 区分给人看的文档(详细)和给LLM看(核心内容)的文档
Docs 资产
- 内容指定:markdown文档内容by project定制
- 生产:初始化文档,暂定为各应用owner
Project Rule
- 内容指定:rule内容by project定制,产出为markdown;放在仓库中
- 生产:初始化project rule的md文档,暂定为各应用owner
User Rule
- 内容指定:产出通用部分,如团队规约,保证内容简洁;不放在仓库中
- 同步方式:(暂定)统一维护在一个新增仓库中,各应用中可以使用脚本进行一键同步到本地
参考文献
- 《Cursor 实战万字经验分享,与 AI 编码的深度思考》:www.cnblogs.com/echolun/p/1...
- 《Claude Code(及 cursor) 内部工作原理窥探》:www.superlinear.academy/c/share-you...