前段时间,我又干了一件"手痒"的事。
事情的起因是这样的------有天晚上我在调试 Spring AI 的项目,想着要不要把 ONNX 模型也集成进来试试看。结果,这一试不得了,直接让我熬到凌晨两点,还边调边惊呼:"卧槽,这也太丝滑了吧!"
所以今天,小米就来和大家聊聊:
SpringAI 如何使用 ONNX 向量模型(Embedding Model) ,以及在实际开发中,怎么配置、踩坑、解决异常。
如果你之前没接触过 ONNX,也没关系,我保证这篇文章看完,你不仅能懂,还能自己上手撸个 demo!
什么是 ONNX 向量模型?
先从 ONNX 说起。
ONNX,全称 Open Neural Network Exchange,是微软和 Facebook 一起推出的一个开放标准。它的目的,就是让各种 AI 框架之间能"互通"模型。
简单来说,TensorFlow 的模型、PyTorch 的模型、MXNet 的模型......都能转成 ONNX 格式,然后你可以在不同框架、不同语言、不同硬件上运行。
就像一场语言大会,ONNX 是那个万能的翻译官。那"向量模型"呢?
在 Spring AI 的语境下,ONNX 向量模型主要用于文本嵌入(Text Embedding) 。也就是把一段文字转化成数字向量(通常几百或上千维),供后续做语义搜索、相似度计算、知识检索等任务。
SpringAI 在 2024 年版本中开始支持 ONNX Embedding Model,这意味着:
- 你可以在 本地运行嵌入模型,
- 不依赖 OpenAI 或云端 API,
- 完全离线使用,速度快,还省钱。
是不是很香?我当时拿来测试了一个中文文本相似度任务,效果非常不错,延迟甚至比在线模型低好几倍。
先决条件:动手前你要准备啥?
在动手之前,咱得先把环境铺好。这里是小米踩坑后的完整 checklist:
1. 安装依赖
Spring AI 对 ONNX 的支持依赖 onnxruntime 库。你需要在系统中安装:
pip install onnxruntime
如果你在 Java 项目中使用 Spring Boot + Spring AI,则需要在 pom.xml 中引入:

2. 模型文件
你需要一个 ONNX 格式的向量模型,比如:
- all-MiniLM-L6-v2.onnx
- bge-small-zh-v1.5.onnx(中文强推)
放在资源目录下即可,例如:
src/main/resources/models/bge-small-zh-v1.5.onnx
3. Spring Boot 环境
推荐使用:
- JDK 17+
- Spring Boot 3.3+
- Spring AI 最新版(建议 1.0.0+)
自动配置:Spring AI 已帮你准备好一切
这也是我最喜欢 Spring AI 的地方------傻瓜式自动配置。
你只要在 application.yml 里轻轻一写,Spring AI 就能自动识别并加载 ONNX 模型。例如:

启动应用时,Spring 会自动注册一个 OnnxEmbeddingModel Bean。
然后在你的业务代码中,你就可以直接注入使用啦:

就这么简单。没有密钥、没有 API 调用、没有延迟。本地模型,几乎 0 成本运行。
Embedding 属性
我们再系统化一点,来看一下 Spring AI 中 ONNX 向量模型的关键属性配置:
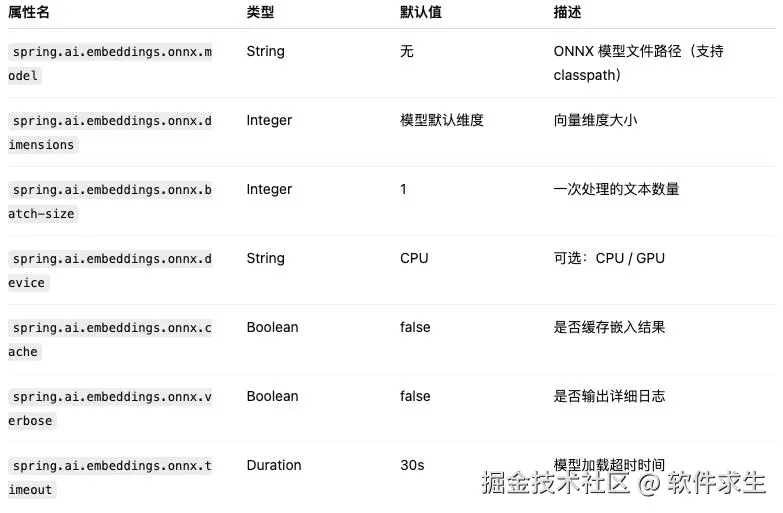
注意:
如果你使用 GPU(如 CUDA 环境),把 device 改为 GPU 可以显著提升速度。
错误与特殊情况
开发中最怕的是什么?当然是------"启动没错,一用就爆"。
下面是小米在调试 ONNX 向量模型时踩到的几个典型坑,顺便帮大家总结成表:

这些坑我全踩过一遍。现在每次看到别人问同样的问题,我都忍不住发出老父亲式微笑:"哈哈,这我熟。"
手动配置(高级玩法)
当然啦,Spring 的自动配置虽然方便,但有时我们也希望能更灵活地控制加载逻辑。比如你想:
- 动态选择不同的 ONNX 模型;
- 结合业务逻辑切换中英文模型;
- 手动管理模型生命周期。
这时候,你可以选择手动配置 Bean。示例代码如下:
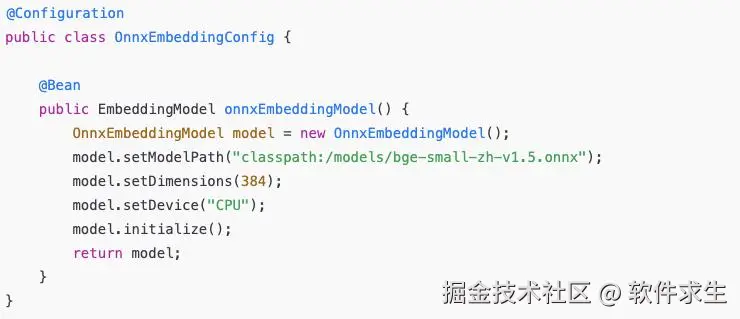
然后在业务代码中一样使用:

这种方式适合中大型项目,特别是当你需要支持多语言、多模型切换的时候。
小米的实测心得
我拿 bge-small-zh-v1.5.onnx 模型在本地做了几组实验。
- 文本长度: 20~200 字不等
- 平均嵌入耗时: 0.02 秒
- 模型加载时间: 约 1.5 秒(首次)
- 相似度检索准确率: 与 OpenAI text-embedding-3-small 接近
更爽的是:离线部署、无 token 限制、无网络延迟。尤其是那种知识库问答类项目,本地 embedding 真是"自由呼吸"的感觉。
总结:ONNX,让 Spring AI 更"自由"
现在回过头看,Spring AI + ONNX 的组合,真的是让我眼前一亮。
以前我们要用 OpenAI API 做嵌入,每次都得担心:
- token 消耗太多;
- 请求超时;
- 模型限速;
- 数据要不要脱敏上传。
但现在,有了 ONNX,
- 模型本地化、
- 性能可控、
- 成本几乎为零。
这才是真正属于开发者的自由。
END
结尾,我想引用一句我很喜欢的话:
"工具的意义,不在于替代人,而在于让人有更多的可能性。"
ONNX 就是这样的存在。它让我们不再受限于厂商,让 Spring AI 更开放、更独立。
希望你看完这篇文章后,也能像我一样,在某个深夜,用自己的模型,跑出属于你的"向量世界"。
互动时间
你用过哪些本地 embedding 模型?有没有踩过类似的坑?欢迎在评论区和小米一起唠嗑~
我是小米,一个喜欢分享技术的31岁程序员。如果你喜欢我的文章,欢迎关注我的微信公众号"软件求生",获取更多技术干货!