Spring原理编码学习
文章学习:Spring Bean生命周期源码篇
前言
Spring框架作为Java生态系统中最重要的框架之一,其IoC(Inversion of Control,控制反转)容器是整个框架的核心。本文将通过分析一个完整的Spring IoC容器实现,深入探讨Spring的核心机制,包括单例Bean生命周期、循环依赖解决方案、三级缓存机制等关键技术。
Bean的创建的生命周期
类-》推断构造方法-》根据构造方法创建普通对象-》依赖注入(@Autowired等进行属性注入)-》初始化前(@PostConstruct)->初始化(InitializingBean)-》初始化后(AOP)-》代理对象(没有开启AOP就会把普通对象放入单例池)-》放入单例池-》Bean对象
依赖注入
在Spring容器中创建了一个普通对象后,如果这个对象有类似于@Autowired注解的属性,如何给这个属性赋值呢?这里利用的是反射的机制,在创建完一个普通对象后,利用反射机制看有没有@Autowird注解的属性,如果依赖注入的bean为单例,首先从单例池中寻找,找到就赋值注入,找不到就创建然后注入属性,如果这个bean为多例,就会直接new 一个对象出来然后赋值。这个具体可以看下面的模拟代码进行深入理解。
推断构造方法
在Spring容器中使用构造方法创建对象的时候默认采用无参构造方法。在Spring容器中创建对象是通过反射根据构造方法进行创建的,至于具体根据哪个构造方法进行创建对象,内容如下:
1.只有一个构造方法,那么实例化就只能使用这个构造方法了。有参的话(前提是根据参数类型或者名字可以找到唯一的bean。
2.有多个构造方法,不管构造方法参数是一个还是多个,那么Spring会去找默认的无参的构造方法,找不到则报错。
3.多个构造方法,并且开发者指定了想使用的构造方法,那么就用这个构造方法
通过@Autowired注解,@Autowired注解可以写在构造方法上,所以哪个构造方法上写了@Autowired注解,表示开发者想使用哪个构造方法。通过@Autowired注解的方式,需要Spring通过byType+byName的方式去找到符合条件的bean作为构造方法的参数值,当然找不到是要报错的。通过byType找如果只有一个就使用该Bean对象,如果有多个再根据名字去找,Spring容器在寻找过程中是根据参数名作为名字去寻找的,找不到则报错。这个类似于@Autowired注解,一开始根据类型去寻找,如果有多个,再根据属性名去找对应的是该名字的Bean对象。
@PostConstruct
如果想要在对象初始化之前执行该对象中的一些方法,可以在该对象方法上加上@PostConstruct注解。在Spring容器中初始化之前执行有该注解的方法。
初始化
Spring容器中对于对象的初始化可以通过继承 InitializingBean 接口重写 afterPropertiesSet() 方法,在此方法里面执行自己的初始化的业务逻辑
Spring IoC容器整体架构
核心组件概览
Spring IoC容器的核心实现类MyApplicationContext承担了容器的所有核心职责:
java
public class MyApplicationContext implements ApplicationContext {
// 配置类,指定组件扫描路径
private final Class<?> configClass;
// Bean定义注册表
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<>();
// 三级缓存机制(解决循环依赖的核心)
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16); // 三级缓存
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16); // 二级缓存
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256); // 一级缓存
// 创建状态跟踪
private final Set<String> singletonsCurrentlyInCreation =
Collections.newSetFromMap(new ConcurrentHashMap<>(16));
// Bean后处理器链
private final List<BeanPostProcessor> beanPostProcessorList = new ArrayList<>();
}容器启动流程
容器的启动遵循严格的三阶段流程:
java
public MyApplicationContext(Class<?> configClass) {
this.configClass = configClass;
// 第一阶段:扫描Bean定义,构建Bean定义注册表
scanBeanDefinition(configClass);
// 第二阶段:注册Bean后处理器,为Bean生命周期提供扩展点
registerBeanPostProcessors();
// 第三阶段:预实例化所有单例Bean,完成容器初始化
preInstantiateSingletons();
}这种设计确保了:
- 依赖关系完整性:在创建Bean之前,所有Bean定义都已注册
- 扩展点就绪:BeanPostProcessor在Bean创建前就已准备好
- 错误提前发现:配置问题在容器启动时就能被发现
Bean定义扫描与注册
扫描机制实现
Bean定义扫描是容器初始化的第一步,通过递归扫描指定包路径下的所有类文件:
java
private void scanBeanDefinition(Class<?> configClass) {
if (!configClass.isAnnotationPresent(ComponentScan.class)) {
return;
}
ComponentScan componentScanAnnotation = configClass.getAnnotation(ComponentScan.class);
String scanPath = componentScanAnnotation.value();
if (scanPath.isEmpty()) {
// 如果没有指定扫描路径,使用配置类所在的包
scanPath = configClass.getPackage().getName();
}
scanPackage(scanPath);
}类文件处理策略
对于扫描到的每个类文件,容器会进行严格的过滤:
java
private void processClassFile(String className, ClassLoader classLoader) {
try {
Class<?> clazz = classLoader.loadClass(className);
// 跳过接口、抽象类、注解和枚举
if (clazz.isInterface() || clazz.isAnnotation() || clazz.isEnum() ||
Modifier.isAbstract(clazz.getModifiers())) {
return;
}
// 检查是否有@Component注解
if (clazz.isAnnotationPresent(Component.class)) {
registerBeanDefinition(clazz);
}
} catch (Exception e) {
// 异常处理逻辑
}
}Bean定义注册
Bean定义的注册过程包括名称解析、冲突检测和作用域设置:
java
private void registerBeanDefinition(Class<?> clazz) {
Component componentAnnotation = clazz.getAnnotation(Component.class);
String beanName = componentAnnotation.value();
// 生成默认的beanName(类名首字母小写)
if (beanName.isEmpty()) {
beanName = Introspector.decapitalize(clazz.getSimpleName());
}
// 检查beanName冲突
if (beanDefinitionMap.containsKey(beanName)) {
throw new RuntimeException("Bean name '" + beanName + "' is already in use");
}
// 创建并注册BeanDefinition
BeanDefinition beanDefinition = createBeanDefinition(clazz);
beanDefinitionMap.put(beanName, beanDefinition);
}单例Bean生命周期详解
完整生命周期流程
Spring单例Bean的生命周期是一个复杂而精密的过程,涉及多个阶段:
java
private Object createBean(String beanName, BeanDefinition beanDefinition) {
// 第一步:创建前准备工作
beforeCreation(beanName, beanDefinition);
try {
// 第二步:实例化 - 创建Bean的原始实例
Object bean = createBeanInstance(beanName, beanDefinition);
// 第三步:三级缓存处理 - 为解决循环依赖做准备
if (beanDefinition.isSingleton()) {
this.singletonFactories.put(beanName, () -> {
Object exposedObject = bean;
// 应用SmartInstantiationAwareBeanPostProcessor
for (BeanPostProcessor processor : beanPostProcessorList) {
if (processor instanceof SmartInstantiationAwareBeanPostProcessor) {
exposedObject = ((SmartInstantiationAwareBeanPostProcessor) processor)
.getEarlyBeanReference(exposedObject, beanName);
}
}
return exposedObject;
});
this.earlySingletonObjects.remove(beanName);
}
Object exposedObject = bean;
// 第四步:属性填充 - 依赖注入
populateBean(beanName, beanDefinition, bean);
// 第五步:初始化 - 执行各种初始化回调
exposedObject = initializeBean(beanName, beanDefinition, exposedObject);
// 第六步:循环依赖处理 - 检查是否发生了循环依赖
if (beanDefinition.isSingleton()) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
exposedObject = earlySingletonReference;
}
}
return exposedObject;
} finally {
// 第七步:创建后清理工作
afterCreation(beanName, beanDefinition);
}
}Bean实例化
实例化阶段通过反射创建Bean的原始实例:
java
private Object createBeanInstance(String beanName, BeanDefinition beanDefinition) {
Class<?> clazz = beanDefinition.getType();
try {
Constructor<?> constructor = clazz.getDeclaredConstructor();
return constructor.newInstance();
} catch (Exception e) {
throw new RuntimeException("Failed to instantiate bean: " + beanName, e);
}
}Bean初始化
初始化阶段是Bean生命周期中最复杂的部分,包含多个子阶段:
java
private Object initializeBean(String beanName, BeanDefinition beanDefinition, Object bean) {
// 第一步:Aware接口回调
invokeAwareMethods(beanName, bean);
// 第二步:初始化前处理
Object wrappedBean = applyBeanPostProcessorsBeforeInitialization(bean, beanName);
// 第三步:执行初始化方法
invokeInitMethods(beanName, wrappedBean, beanDefinition);
// 第四步:初始化后处理(AOP代理创建)
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
return wrappedBean;
}循环依赖问题与解决方案
被 Spring 管理的对象叫做 Bean 。Bean的生成步骤如下:
Spring 扫描 class 得到 BeanDefinition;
根据得到的 BeanDefinition 去生成 bean;
首先根据 class 推断构造方法;
根据推断出来的构造方法,反射,得到一个对象(暂时叫做原始对象);
填充原始对象中的属性(依赖注入);
如果原始对象中的某个方法被 AOP 了,那么则需要根据原始对象生成一个代理对象;
把最终生成的代理对象放入单例池(源码中叫做 singletonObjects)中,下次 getBean 时就直接从单例池拿即可;
我们可以发现,在得到一个原始对象后,Spring 需要给对象中的属性进行依赖注入,那么这个注入过程是怎样的?
比如上文说的 A 类,A 类中存在一个 B 类的 b 属性,所以,当 A 类生成了一个原始对象之后,就会去给 b 属性去赋值,此时就会根据 b 属性的类型和属性名去 BeanFactory 中去获取 B 类所对应的单例bean。
- 如果此时 BeanFactory 中存在 B 对应的 Bean,那么直接拿来赋值给 b 属性;
- 如果此时 BeanFactory 中不存在 B 对应的 Bean,则需要生成一个 B 对应的 Bean,然后赋值给 b属性。
问题就出现在「第二种」情况,如果此时 B 类在 BeanFactory 中还没有生成对应的 Bean,那么就需要去生成,就会经过 B 的 Bean 的生命周期。
那么在创建 B 类的 Bean 的过程中,如果 B 类中存在一个 A 类的 a 属性,那么在创建 B 的 Bean 的过程中就需要 A 类对应的 Bean,但是,触发 B 类 Bean 的创建的条件是 A 类 Bean 在创建过程中的依赖注入,所以这里就出现了循环依赖:
A Bean创建-->依赖了 B 属性-->触发 B Bean创建--->B 依赖了 A 属性--->需要 A Bean(但A Bean还在创建过程中)
从而导致 A Bean 创建不出来,B Bean 也创建不出来。
这里就用到三级缓存了,这里设置两个类Aservice,Bservice。Aservice中有Bservice属性的注入,Bservice中有Aservice属性的注入。那么三级缓存是如何解决问题的呢?这里先对三级缓存进行简单的描述。
「singletonObjects」 :缓存某个 beanName 对应的经过了完整生命周期的bean也就是我们的单例池;
「earlySingletonObjects」 :缓存提前拿原始对象进行了 AOP 之后得到的代理对象,原始对象还没有进行属性注入和后续的 BeanPostProcesso r等生命周期;
「singletonFactories」:缓存的是一个 ObjectFactory ,主要用来去生成原始对象进行了 AOP之后得到的「代理对象」,在每个 Bean 的生成过程中,都会提前暴露一个工厂,这个工厂可能用到,也可能用不到,如果没有出现循环依赖依赖本 bean,那么这个工厂无用,本 bean 按照自己的生命周期执行,执行完后直接把本 bean 放入 singletonObjects 中即可,如果出现了循环依赖依赖了本 bean,则另外那个 bean 执行 ObjectFactory 提交得到一个 AOP 之后的代理对象(如果有 AOP 的话,如果无需 AOP ,则直接得到一个原始对象)
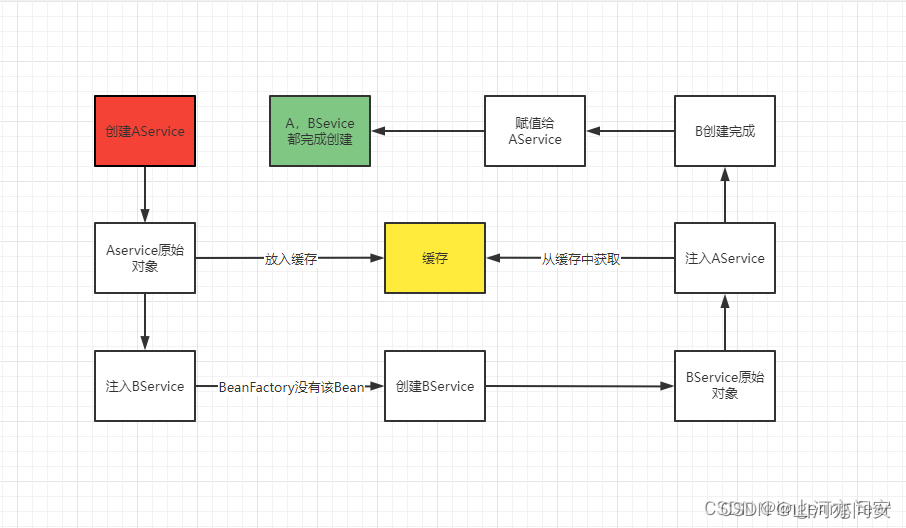
Aservice 在Spring容器创建过程中,在实例化后把Aservice普通对象放在缓存中,然后进行Bservice属性的依赖注入,首先从单例池中寻找Bservice,如果找到就会赋值,找不到就会创建Bservice,在进行Aservice注入的时候从单例池寻找,找不到然后从缓存中寻找进行属性的注入。此时循环依赖问题得以解决。因为在整个过程中AService都是单例的 , 所以即使从缓存中拿到的AService的原始对象也没有关系 , 因为在后续的Bean生命周期中 ,AService在堆内存中没有发生变化。这种情况当Aservice对象没有AOP的时候这种情况是没有问题的,如果Aservice类有AOP,从上文可知那么单例池中的该对象是代理对象,而我们在Bservice中依赖注入的Aservice是普通对象,这显而易见就有问题了。
所以就需要二级缓存了,在Bservice进行Aservice属性注入的时候,要进行提前AOP,而上面的缓存就相当于三级缓存存储原始对象,出现循环依赖后从二级缓存earlySingletonObjects中获取如果获取不到对应的对象,然后就会从三级缓存中获取原始对象,如果是AOP就生成代理对象,不是就是普通对象然后放在二级缓存中,此时这个对象还不能放入单例池中,为什么呢?假如这里是个代理对象,代理对象的Target原始对象还没有完成生命周期属性还没有完全注入完成,如果在这里放入单例池,在多线程环境下在这时从单例池中获取这个bean对象就会发生不可预期的错误。当Bservice Bean对象创建完成后然后在Aservice中填充完所有属性后,就可以从二级缓存中获取该对象然后放到单例池中了。
循环依赖的本质
循环依赖是指两个或多个Bean之间存在相互依赖关系,形成一个闭环。最常见的情况是:
java
@Component
public class UserService {
@Autowired
private OrderService orderService; // UserService依赖OrderService
}
@Component
public class OrderService {
@Autowired
private UserService userService; // OrderService依赖UserService
}循环依赖的挑战
如果没有特殊处理机制,循环依赖会导致:
- 无限递归:A创建时需要B,B创建时需要A,形成死循环
- 栈溢出:递归调用最终导致StackOverflowError
- Bean无法完成初始化:两个Bean都在等待对方完成创建
Spring的解决策略
Spring通过三级缓存机制巧妙地解决了循环依赖问题:
- 提前暴露:Bean实例化后立即暴露,即使还未完成初始化
- 延迟注入:通过ObjectFactory延迟创建依赖对象
- 缓存管理:使用三级缓存管理不同状态的Bean实例
三级缓存机制深度剖析
三级缓存的设计理念
Spring的三级缓存是解决循环依赖的核心机制,每一级缓存都有其特定的职责:
java
// 一级缓存:完成品单例对象池
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 二级缓存:早期单例对象缓存
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
// 三级缓存:单例工厂缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);缓存的职责分工
一级缓存(singletonObjects)
- 存储内容:完全初始化完成的Bean实例
- 生命周期:Bean完全初始化后存入 → 容器销毁时清理
- 作用:提供完整Bean的快速访问,这是最终的Bean存储容器
二级缓存(earlySingletonObjects)
- 存储内容:早期Bean引用(可能是原始对象或代理对象)
- 生命周期:循环依赖发生时创建 → Bean完全初始化后移除
- 作用:避免重复调用ObjectFactory,确保循环依赖中注入的是同一个对象
三级缓存(singletonFactories)
- 存储内容:ObjectFactory对象工厂
- 生命周期:Bean实例化后存入 → 依赖注入完成后移除
- 作用:延迟创建Bean引用,支持AOP代理的动态创建
缓存查找机制
三级缓存的查找遵循严格的优先级顺序:
java
private Object getSingleton(String beanName, boolean allowEarlyReference) {
// 第一步:尝试从一级缓存获取完全初始化的Bean
Object singletonObject = this.singletonObjects.get(beanName);
// 如果一级缓存没有,且Bean正在创建中(可能存在循环依赖)
if (singletonObject == null && this.singletonsCurrentlyInCreation.contains(beanName)) {
synchronized (this.singletonObjects) {
// 第二步:尝试从二级缓存获取早期Bean引用
singletonObject = this.earlySingletonObjects.get(beanName);
// 如果二级缓存也没有,且允许创建早期引用
if (singletonObject == null && allowEarlyReference) {
// 第三步:尝试从三级缓存获取Bean工厂
ObjectFactory<?> objectFactory = this.singletonFactories.get(beanName);
if (objectFactory != null) {
// 通过工厂创建早期Bean引用
singletonObject = objectFactory.getObject();
// 将早期引用放入二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
// 从三级缓存中移除工厂
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}循环依赖解决流程实例
让我们通过一个具体的例子来理解三级缓存如何解决循环依赖:
场景设置
java
@Component
public class ServiceA {
@Autowired
private ServiceB serviceB;
}
@Component
public class ServiceB {
@Autowired
private ServiceA serviceA;
}详细解决流程
第一步:ServiceA开始创建
java
// 1. 标记ServiceA为正在创建状态
singletonsCurrentlyInCreation.add("serviceA");
// 2. 实例化ServiceA(调用构造函数)
ServiceA serviceA = new ServiceA(); // serviceB字段还是null
// 3. 将ServiceA的ObjectFactory放入三级缓存
singletonFactories.put("serviceA", () -> {
// 这里可能会应用AOP代理
return serviceA; // 或者返回serviceA的代理对象
});第二步:ServiceA进行属性注入,需要ServiceB
java
// 4. 开始注入serviceB字段
// 5. 调用getBean("serviceB"),ServiceB开始创建第三步:ServiceB开始创建
java
// 6. 标记ServiceB为正在创建状态
singletonsCurrentlyInCreation.add("serviceB");
// 7. 实例化ServiceB
ServiceB serviceB = new ServiceB(); // serviceA字段还是null
// 8. 将ServiceB的ObjectFactory放入三级缓存
singletonFactories.put("serviceB", () -> serviceB);第四步:ServiceB进行属性注入,需要ServiceA(循环依赖发生)
java
// 9. 开始注入serviceA字段
// 10. 调用getBean("serviceA")
// 11. 发现serviceA正在创建中,触发三级缓存查找
// 12. 一级缓存没有serviceA(还未完全初始化)
// 13. 二级缓存没有serviceA(还未创建早期引用)
// 14. 三级缓存有serviceA的ObjectFactory
// 15. 调用ObjectFactory.getObject()创建早期引用
Object earlyServiceA = singletonFactories.get("serviceA").getObject();
// 16. 将早期引用放入二级缓存
earlySingletonObjects.put("serviceA", earlyServiceA);
// 17. 从三级缓存移除ObjectFactory
singletonFactories.remove("serviceA");
// 18. 将早期的ServiceA引用注入到ServiceB中
serviceB.serviceA = earlyServiceA;第五步:ServiceB完成创建
java
// 19. ServiceB完成初始化(Aware回调、BeanPostProcessor等)
// 20. 将完整的ServiceB放入一级缓存
singletonObjects.put("serviceB", serviceB);
// 21. 清理ServiceB的创建状态
singletonsCurrentlyInCreation.remove("serviceB");第六步:ServiceA完成创建
java
// 22. ServiceB创建完成,继续ServiceA的属性注入
serviceA.serviceB = serviceB;
// 23. ServiceA完成初始化
// 24. 检查是否存在早期引用
Object earlyReference = earlySingletonObjects.get("serviceA");
if (earlyReference != null) {
// 使用早期引用作为最终结果,确保对象一致性
finalServiceA = earlyReference;
}
// 25. 将完整的ServiceA放入一级缓存
singletonObjects.put("serviceA", finalServiceA);
// 26. 清理二级缓存和创建状态
earlySingletonObjects.remove("serviceA");
singletonsCurrentlyInCreation.remove("serviceA");依赖注入实现原理
注入机制概述
Spring的依赖注入通过反射机制实现,支持字段注入、构造器注入和setter方法注入。在我们的实现中,主要展示了字段注入:
java
private void populateBean(String beanName, BeanDefinition beanDefinition, Object bean)
throws IllegalAccessException {
Class<?> clazz = beanDefinition.getType();
// 遍历所有声明的字段,查找需要注入的依赖
for (Field field : clazz.getDeclaredFields()) {
if (field.isAnnotationPresent(Autowired.class)) {
// 设置字段可访问,处理private字段
field.setAccessible(true);
// 通过字段名称从容器中获取对应的Bean
String dependencyBeanName = field.getName();
Object dependencyBean = getBean(dependencyBeanName);
// 将依赖Bean注入到目标字段中
field.set(bean, dependencyBean);
}
}
}BeanPostProcessor扩展机制
扩展点设计
BeanPostProcessor是Spring提供的重要扩展点,允许在Bean初始化的前后插入自定义逻辑:
java
public interface BeanPostProcessor {
// 初始化前处理
default Object postProcessBeforeInitialization(Object bean, String beanName) {
return bean;
}
// 初始化后处理
default Object postProcessAfterInitialization(Object bean, String beanName) {
return bean;
}
}处理器执行时机
BeanPostProcessor在Bean初始化阶段的两个关键时点执行:
初始化前处理
java
private Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName) {
Object result = existingBean;
for (BeanPostProcessor processor : beanPostProcessorList) {
Object current = processor.postProcessBeforeInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}常见用途:
- 属性验证和修改
- 注解处理(如@PostConstruct)
- 配置检查
- 依赖验证
初始化后处理
java
private Object applyBeanPostProcessorsAfterInitialization(Object existingBean, String beanName) {
Object result = existingBean;
for (BeanPostProcessor processor : beanPostProcessorList) {
Object current = processor.postProcessAfterInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}