目录
[1. 数据类型 - set](#1. 数据类型 - set)
[1.1 sadd - 添加元素](#1.1 sadd - 添加元素)
[1.2 smembers - 获取所有元素](#1.2 smembers - 获取所有元素)
[1.3 sismember - 判断元素是否存在](#1.3 sismember - 判断元素是否存在)
[1.4 scard - 查询元素个数](#1.4 scard - 查询元素个数)
[1.5 spop - 随机删除元素](#1.5 spop - 随机删除元素)
[1.6 smove - 移动元素](#1.6 smove - 移动元素)
[1.7 srem - 删除元素](#1.7 srem - 删除元素)
[1.8 交集](#1.8 交集)
[1.8.1 sinter - 求交集](#1.8.1 sinter - 求交集)
[1.8.2 sinterstore - 保存交集](#1.8.2 sinterstore - 保存交集)
[1.9 并集](#1.9 并集)
[1.9.1 sunion - 求并集](#1.9.1 sunion - 求并集)
[1.9.2 sunionstore - 保存并集](#1.9.2 sunionstore - 保存并集)
[1.10 差集](#1.10 差集)
[1.10.1 sdiff - 求差集](#1.10.1 sdiff - 求差集)
[1.10.2 sdiffstore - 保存差集](#1.10.2 sdiffstore - 保存差集)
[1.11 srandmember](#1.11 srandmember)
[1.12 set 内部编码](#1.12 set 内部编码)
[1.13 set 应用场景](#1.13 set 应用场景)
[1.13.1 存储用户画像](#1.13.1 存储用户画像)
[1.13.2 计算公共好友](#1.13.2 计算公共好友)
[1.13.3 统计 UV](#1.13.3 统计 UV)
[2. 数据类型 - zset](#2. 数据类型 - zset)
[2.1 zadd - 添加元素](#2.1 zadd - 添加元素)
[2.2 zcard - 查看元素总个数](#2.2 zcard - 查看元素总个数)
[2.3 zcount - 根据 score 查询元素个数](#2.3 zcount - 根据 score 查询元素个数)
[2.4 zrange - 根据下标查询元素](#2.4 zrange - 根据下标查询元素)
[2.5 zrevrange - 逆序查询元素](#2.5 zrevrange - 逆序查询元素)
[2.6 zrangebyscore - 根据 score 查询元素](#2.6 zrangebyscore - 根据 score 查询元素)
[2.7 zpopmax - 删除最大元素](#2.7 zpopmax - 删除最大元素)
[2.7.1 bzpopmax(阻塞版本)](#2.7.1 bzpopmax(阻塞版本))
[2.8 zpopmin - 删除最小元素](#2.8 zpopmin - 删除最小元素)
[2.8.1 bzpopmin(阻塞版本)](#2.8.1 bzpopmin(阻塞版本))
[2.9 zrank - 获取元素下标(升序顺序)](#2.9 zrank - 获取元素下标(升序顺序))
[2.10 zrevrank - 获取元素下标(降序顺序)](#2.10 zrevrank - 获取元素下标(降序顺序))
[2.11 zscore - 获取元素的 score](#2.11 zscore - 获取元素的 score)
[2.12 zrem - 删除指定元素](#2.12 zrem - 删除指定元素)
[2.13 zremrangebyrank - 删除区间内元素(下标)](#2.13 zremrangebyrank - 删除区间内元素(下标))
[2.14 zremrangebyscore - 删除区间内元素(分数)](#2.14 zremrangebyscore - 删除区间内元素(分数))
[2.15 zincrby - 修改分数](#2.15 zincrby - 修改分数)
[2.16 交集 & 并集](#2.16 交集 & 并集)
[2.16.1 zinterstore - 求交集](#2.16.1 zinterstore - 求交集)
[2.16.2 zunionstore - 求并集](#2.16.2 zunionstore - 求并集)
[2.17 zset 内部编码](#2.17 zset 内部编码)
[2.18 zset 应用场景](#2.18 zset 应用场景)
[2.18.1 排行榜系统](#2.18.1 排行榜系统)
[2.18.2 计算综合热度](#2.18.2 计算综合热度)
1. 数据类型 - set
数据类型 set (集合), 依旧是指 value 的类型, 在 Redis 中, set 具有以下特点:
- 元素不重复(唯一性).
- 顺序不相关(无序).
set 中的每个元素, 必须是 string 类型, 但是可以使用 json 的格式来存储结构化数据.
注意: list 是有序的, 而 set 是无序的.
这里的 "有序" 和 "无序" 是指, 是否和顺序相关.
- list 有序: 1, 2, 3 和 1, 3, 2 是两个不同的 list.
- set 无序: 1, 2, 3 和 1, 3, 2 是两个相同的 list.
1.1 sadd - 添加元素
语法: SADD key member member ...
使用 sadd 命令, 往 set 中添加元素, 可以一次添加一个, 也可以一次添加多个.
**时间复杂为 O(1), 返回值: 成功添加的元素的个数.**严谨来说, 其实是 O(N), N 是添加的元素的个数, 但是一般来说, 添加的元素不会特别多, 因此可以视为 O(1).

1.2 smembers - 获取所有元素
语法: SMEMBERS key
查看 set 中所有的元素.
1.3 sismember - 判断元素是否存在
语法: SISMEMBER key member
时间复杂度: O(1)
返回值: member 存在返回 1, 不存在返回 0.

1.4 scard - 查询元素个数
查询 set 中 member 的总个数.
语法: SCARD key
返回值: set 中 member 的个数.

1.5 spop - 随机删除元素
从 set 中随机删除 count 个元素. (注: 由于 set 是无序的, 因此是随机删除)
语法: SPOP key count
其中, count 可写可不写:
- 不写 count 时: 随机删除 1 个元素.
- 写 count 时: 随机删除 count 个元素.
返回值: 删除的元素的值.


1.6 smove - 移动元素
语法: SMOVE source destination member
作用: 把 member 从 source 上删除, 再插入到 destination 中.
返回值: 移动成功的元素的个数.

若 source 为空, 则返回 0, 表示移动失败:

1.7 srem - 删除元素
从 set 中删除元素, 可以一次删除一个, 也可以一次删除多个.
语法: SREM key member member ...
时间复杂度: O(1)
返回值: 删除成功的个数.

1.8 交集
1.8.1 sinter - 求交集
语法: SINTER key key ...
每个 key 就是一个 set, 使用 sinter 查询多个 set 的交集.
时间复杂度: O(M * N), M 是最小集合元素的个数, N 是最大集合元素的个数.
返回值: 交集的结果数据.

1.8.2 sinterstore - 保存交集
语法: SINTERSTORE destination key key ...
将多个 set 的交集保存到一个新的 set 中(destination).
返回值: 交集的元素个数.

1.9 并集
1.9.1 sunion - 求并集
语法: SUNION key key ...
功能: 求多个 set 的并集. 时间复杂度为 O(N), N 是指所有集合总的元素个数.
返回值: 并集的结果数据.

1.9.2 sunionstore - 保存并集
语法: SUNIONSTORE destination key key ...
将多个 set 的并集保存到一个新的 set 中.

1.10 差集
1.10.1 sdiff - 求差集
语法: SDIFF key1 key2 ...
功能: 查询第一个集合(key1)与后面所有集合(key2...)的差集. 时间复杂度为 O(N).
注意: 求差集, 和前面的 交集/并集 不同, 交集/并集 满足交换律, 而 求差集 不满足交换律 , 比如 A 交/并 B 和 B 交/并 A 得出的结果是相同的. 而 A - B 和 B - A 的结果是不同的.

1.10.2 sdiffstore - 保存差集
**语法: SDIFFSTORE destination key1 key2 ...**
将第一个集合(key1)与后面所有集合(key2...)差集的结果, 保存到一个新的 set 中.

注意:
上面命令的时间复杂度/返回值, 不用刻意去背, 用到的时候查一下文档就好.
只需记住几个常用的即可.
1.11 srandmember
语法: SRANDMEMBER key count
从 set 中随机获取 count 个元素. (count 不写, 默认为 1)

1.12 set 内部编码
对于 set 类型, 有两种内部编码:
- intset(整数集合): 当存储的元素都是整数, 且元素个数教少时使用. 可以节省内存空间,
- hashtable(哈希表)
正是因为 set 的内部编码是 inset 和 hashtable,
因此, 当元素个数少时, 在 intset 中的 增(sadd)/删(srem)/查(sismember) 的效率可以认为是 O(1); 当. 当元素个数多时, 在 hashtable 中的 增/删/查 的效率也是 O(1).
因此, 可以认为 set 的增删查操作, 时间复杂度为 O(1)
1.13 set 应用场景
1.13.1 存储用户画像
用户"画像", 就是用户标签, 描述了用户的特征, 比如: 年龄/性别/喜好/居住地/性格/....
很多互联网公司, 都会根据用户在其软件上浏览的内容, 分析出用户的特征, 再根据用户的特征, 给用户推送其感兴趣的内容.
搜集到的用户标签, 就会以一个简短的字符串的形式, 存储到 set 中.
为什么是存到 set, 而不是 list 中呢? 正是因为 set 有以下特性:
- 唯一性: 一个用户不会被重复打上完全相同的标签.
- 无序性: 用户拥有一系列标签, 这些标签之间通常没有先后顺序. (哪些标签, 哪些标签在后, 不重要)
- 高效的增删查.
- 给用户新增标签: sadd, 时间复杂度 O(1)
- 删除用户的标签: srem, 时间复杂度 O(1)
- 判断用户是否具有某个标签: sismember, 时间复杂度 O(1)
1.13.2 计算公共好友
这个应用场景, 是基于 set 支持集合求交集的功能.
由于 set 提供了 求交集 的操作命令(sinter/sinterstore), 因此就可以将用户的好友信息存储到 set 中, 再利用 sinter 计算出不同用户的共同好友(求交集), 进行好友推荐.
1.13.3 统计 UV
这个应用场景, 是基于 set 的去重功能.
一个互联网产品, 主要是通过以下两点, 去衡量用户规模的:
- page view(PV): 浏览量, 用户每访问一次服务器, 就是一个 pv. (即使是同一个用户多次访问, 也会计算进去)
- 局限性: 无法区分流量是由少数用户反复刷新页面产生的, 还是由大量不同用户产生的.
- user view(UV): 在一个周期中( 一天/一周/一月), 访问服务器的独立用户数量. 同一个用户的多次访问, 只会被计算一次.
因此统计 UV 时, 需要对重复的用户进行去重, 这个去重功能, 就可以通过 set 实现.
2. 数据类型 - zset
zset 是 set 的有序版本, 有序集合.
这里 zset 的有序, 并非指 "和顺序相关", 而是指 zset 中元素是升序排序的,
在 zset 中, 每个 member 还有一个与之绑定的 score(分数, 浮点类型), zset 就是根据 score 对元素进行升序排序的. (若多个 member 的 score 值相同, 则按照 member 自身的字符串字典序排序)
在 zset 中, member 依旧不可重复, 但是 score 可以重复.
注意: score 只是 member 的 "辅助" 描述, 最关键的信息依旧是 member. 且 member 和 score 不是键值对, 可以认为是一个二元组(Pair), 可以通过 member 找到 score, 也可以通过 score 找到 member.
2.1 zadd - 添加元素
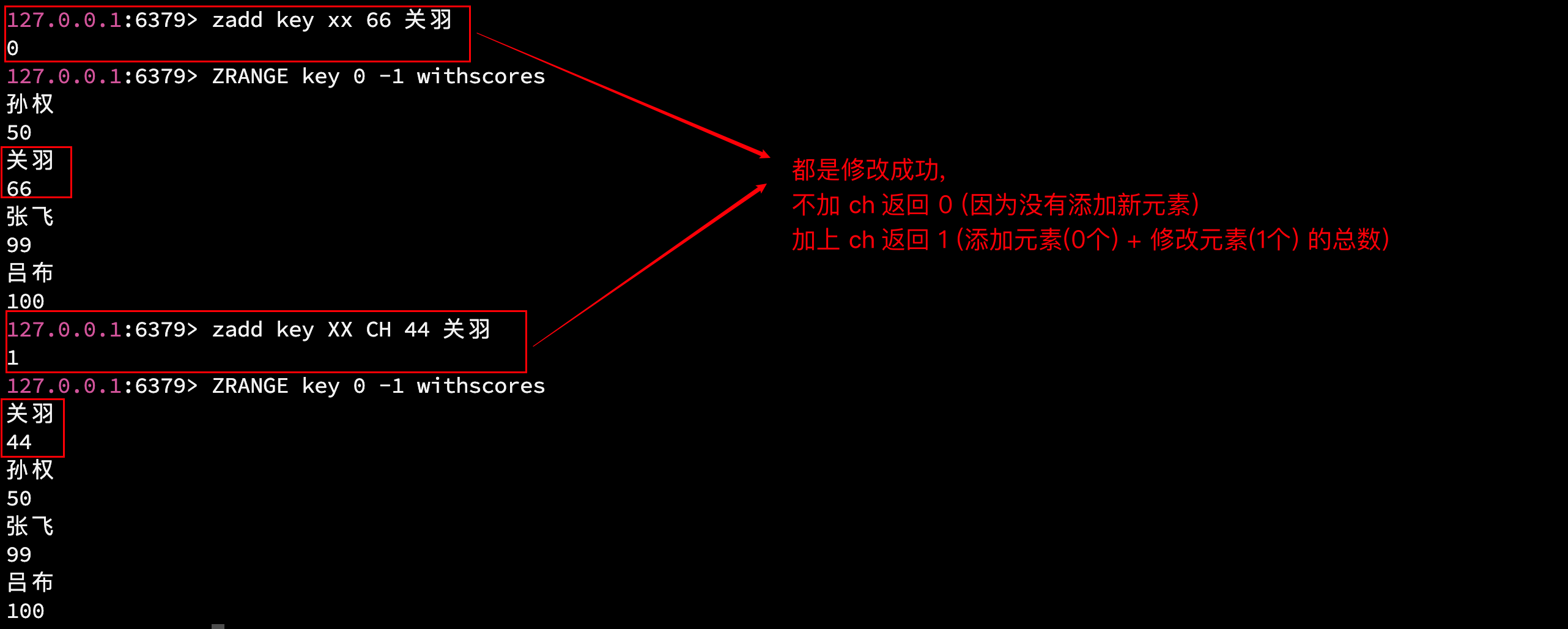
语法: ZADD key NX \| XX GT \| LT CH INCR score member score member ...
- NX: 当 member 不存在时, 才会添加成功.

- XX: 当 member 存在时, 才会更新分数.

- GT: 当新 score 比当前的 score 大时, 才会更新分数. (若 member 不存在, 则直接添加)
- LT: 当新 score 比当前的 score 小时, 才会更新分数. ( 若 member 不存在, 则直接添加 )
- CH: 将返回值修改为: 新增和修改的 member 的总数. (原本默认只返回 新增元素的个数)
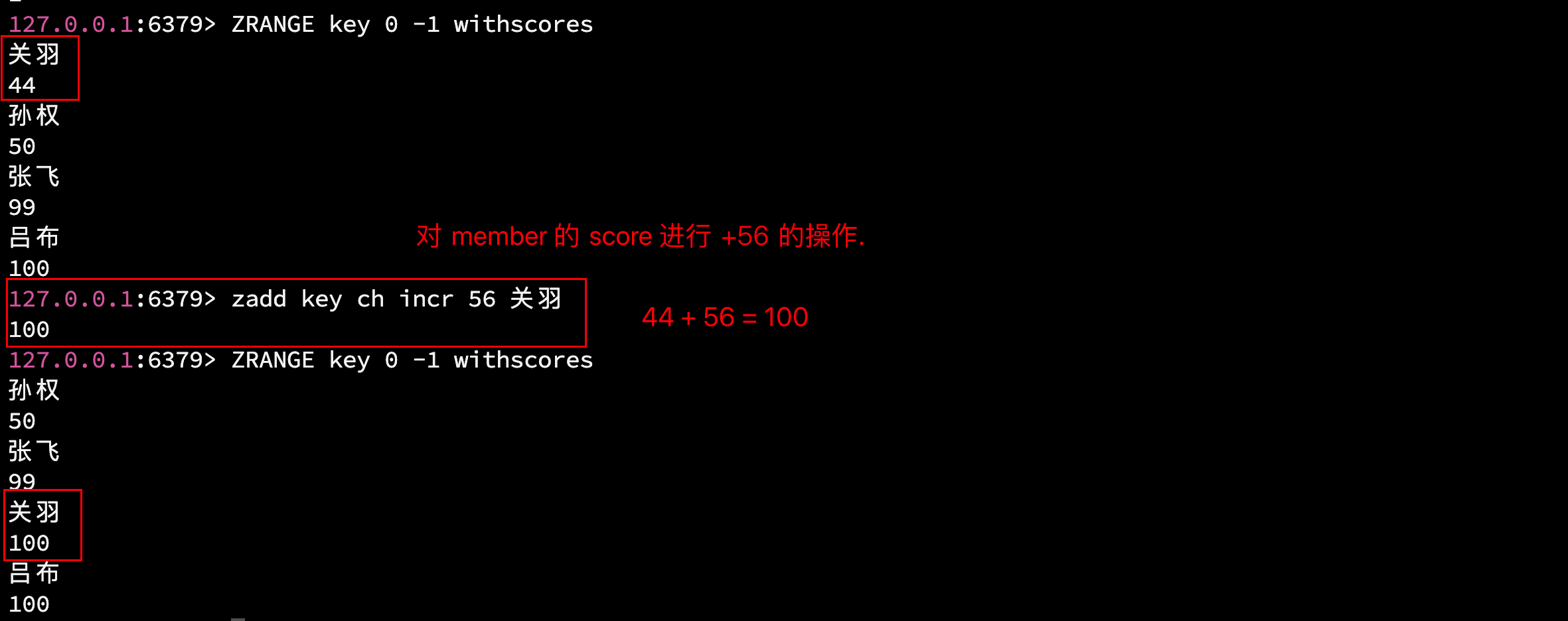
- INCR: 对元素的 score 进行加减操作. (返回值: 执行 INCR 后的新分数 )
返回值: 默认返回新添加的元素的个数. (可以通过添加 CH 选项修改)
时间复杂度: O(logN), 由于 zset 是有序集合, 其内部的跳表结构, 可以根据 score 快速定位到指定元素.
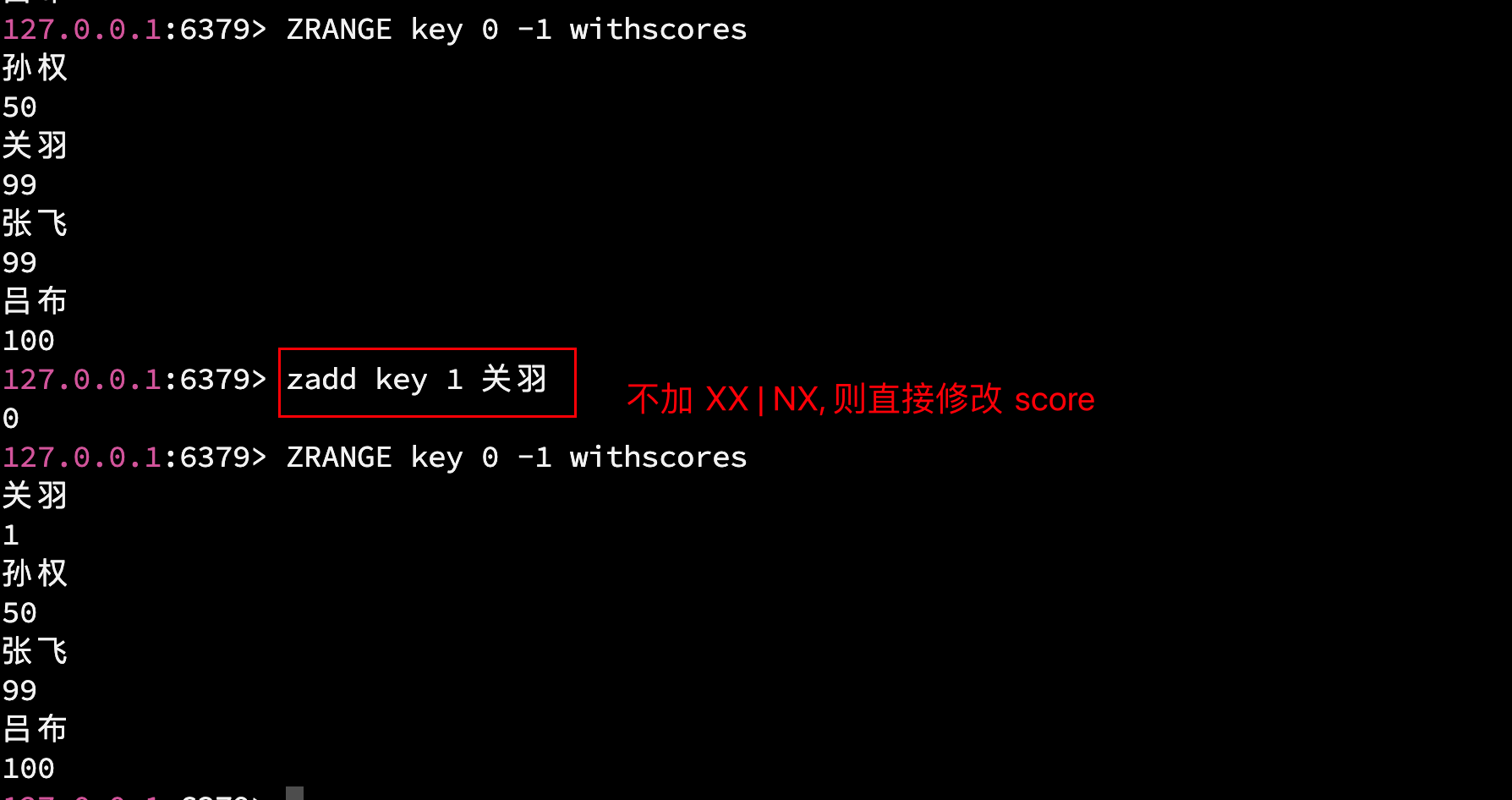
NX 和 XX 是可选的, 若不加 NX 和 XX:
- 若 member 存在, 则更新对应的 score
- 若 member 不存在, 则添加新的 member 和 score
(注: 由于 zset 是有序集合, 本身元素就是有先后顺序的, 因此 member 是具有下标的)
可以看到, 通过 zrange 查看到的 member 是按照 score 进行升序排序后的.
2.2 zcard - 查看元素总个数
语法: ZCARD key
返回 member 的个数.

2.3 zcount - 根据 score 查询元素个数
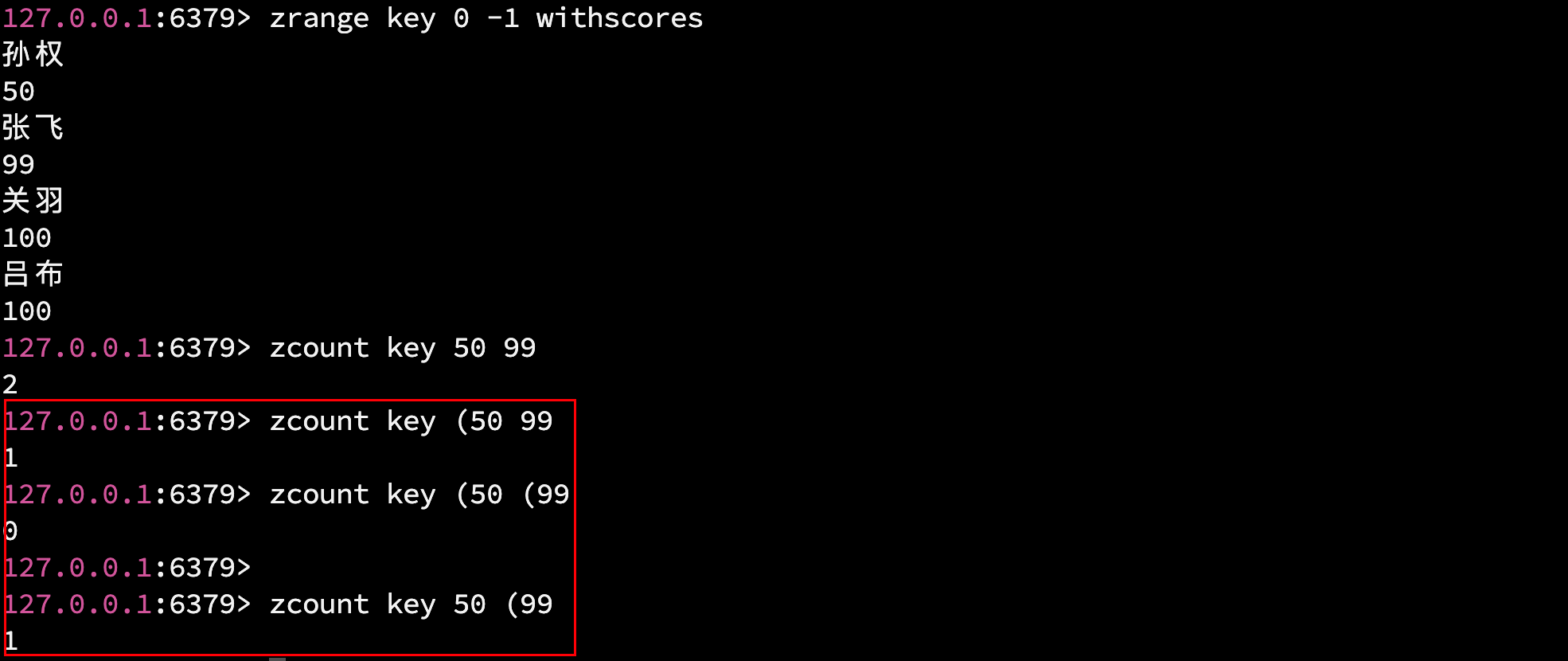
语法: ZCOUNT key min max
注意: 这里的 min 和 max 指的是 score 的值, 而非下标.
查询 score 为 min, max 区间内元素的个数. (默认为闭区间, 但是可以修改)
**时间复杂度: O(logN) ,**先根据 min 和 max 找到两头的 member (zset 是有序集合, 跳表 2 * logN 即可找到), 并且 Redis 内部记录了每个元素的 "下标", 则直接首位下标相减即可得到元素个数( O(1) 复杂度), 无需遍历.
返回值: 区间内的元素个数.

如果要查询开区间, 则在 min 或者 max 的前面加上 '(' , 比如:
- (min, max] : ZCOUNT key (min max
- [min, max) : ZCOUNT key min (max
- (min , max**) : ZCOUNT key (min (max**
2.4 zrange - 根据下标查询元素
语法: zrange key start end (类似于 lrange, start, end 依旧是闭区间)
打印下标为 start, end 范围内的元素(升序打印), 加上 withscores, 会返回 score.
(注: 由于 zset 是有序集合, 本身元素就是有先后顺序的, 因此 member 是具有下标的)

2.5 zrevrange - 逆序查询元素
语法: ZREVRANGE key start end WITHSCORES
把 start end 下标范围内的 member 降序打印.

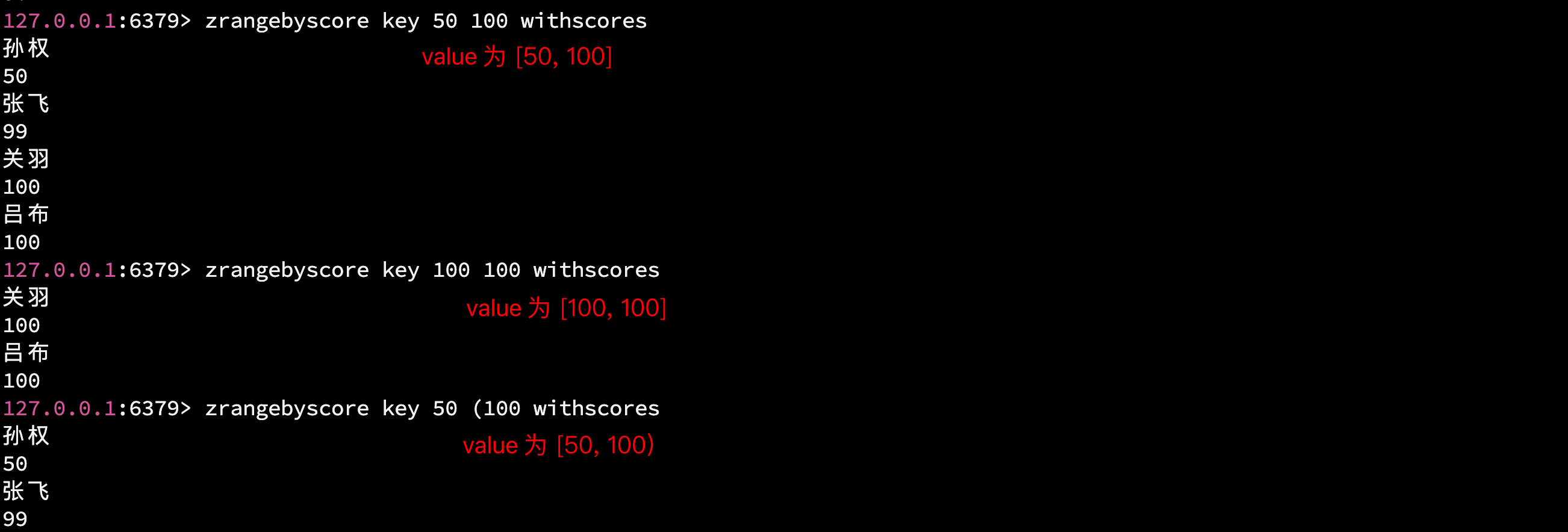
2.6 zrangebyscore - 根据 score 查询元素
语法: ZRANGEBYSCORE key min max WITHSCORES
按照分数去查找元素, 和 zcount 的用法一样, 只不过 zrangebyscore 返回的是 member (和 score) 的值.
时间复杂度: O(logN + M) , logN 是查找头(min 对应的 member)和尾(max 对应的元素), M 是遍历中间的元素.
2.7 zpopmax - 删除最大元素
语法: ZPOPMAX key count
删除并返回 score 最高的 count 个元素, 如果不指定 count, 则默认为 1.
时间复杂度: O(logN * M(count))
返回值: 删除的 member 和 score

注意: 即使有多个元素的 score 相同, 并且是最大值, 那么也会只删除一个(按 member 的字典序删, 删字段序最大的).
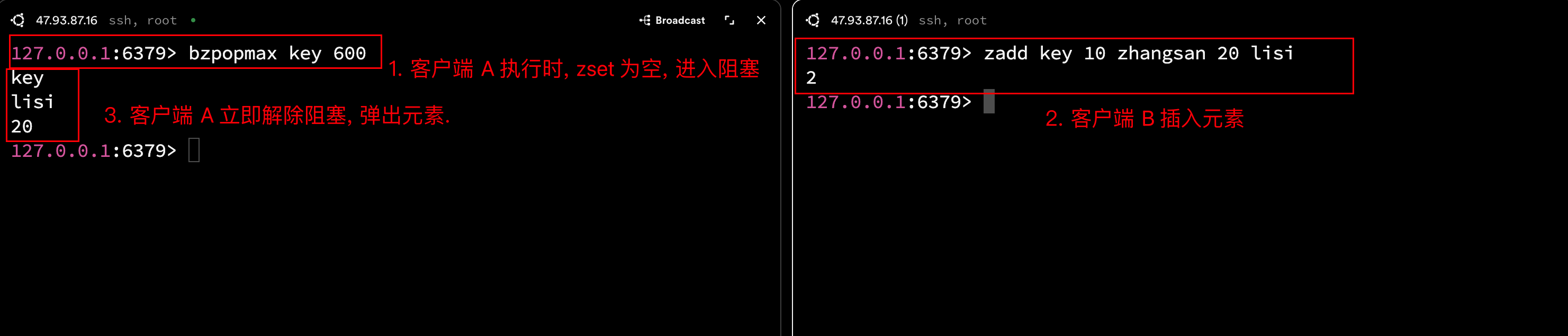
2.7.1 bzpopmax(阻塞版本)
语法: BZPOPMAX key key ... timeout
bzpopmax 和之前的 blpop/brpop 用法相同, 带有阻塞功能. bzpopmax 是 zpopmax 的阻塞版本. k可以指定多个 key, 每一个 key 都是一个 zset(但只会弹出一个元素), 当所有 key 对应的 zset 都为空时会进入阻塞, 若其中任意一个 zset 不为空, 则立即弹出 score 最高的元素.
时间复杂度: O(logN)
返回值: 删除的 key, member, score.
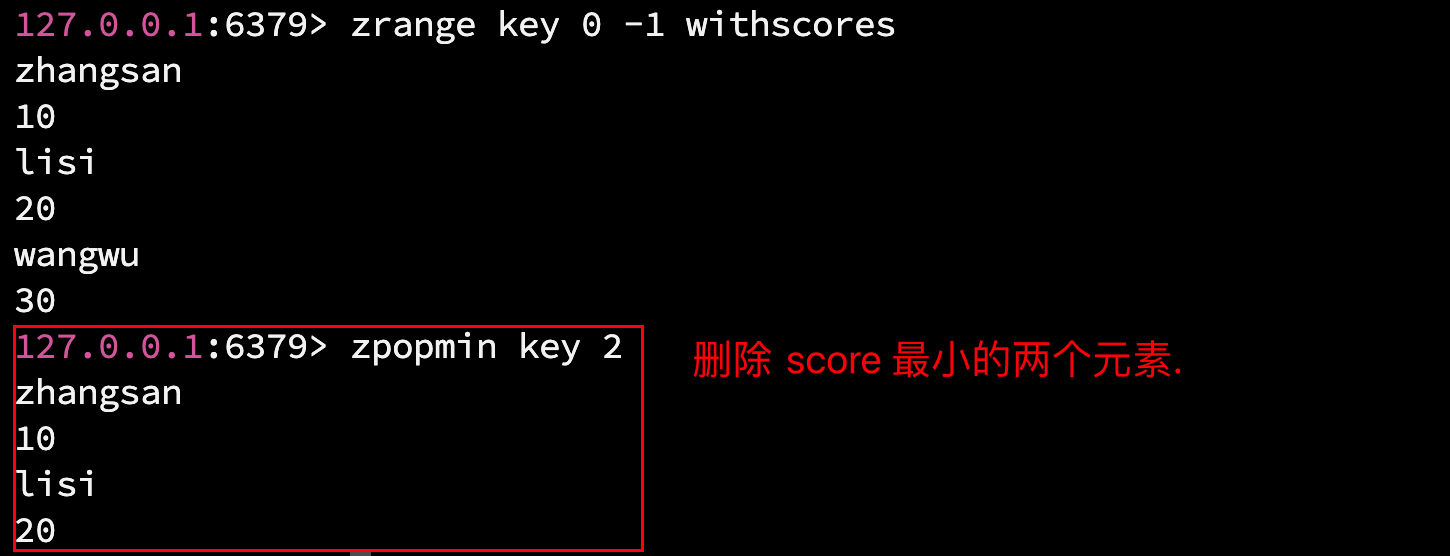
2.8 zpopmin - 删除最小元素
语法: ZPOPMIN key count
删除 score 最小的 count 个元素.(和 zpopmax 用法一样.)
时间复杂度: O(logN * M(count))
返回值: 删除的 member 和 score
2.8.1 bzpopmin(阻塞版本)
语法: BZPOPMIN key key ... timeout
bzpopmin 是 zpopmin 的阻塞版本. 和 bzpopmax 的用法相同.

2.9 zrank - 获取元素下标(升序顺序)
语法: ZRANK key member
zrank 获取到的元素下标, 是以从左到右(升序)的顺序获取的. 时间复杂度为 O(logN).

2.10 zrevrank - 获取元素下标(降序顺序)
语法: ZREVRANK key member
ZREVRANK 是以从右向左(降序)的顺序获取下标的.

2.11 zscore - 获取元素的 score
语法: ZSCORE key member
返回值: 返回指定元素的 score.
时间复杂度: O(1) (之前的命令, 根据 member 找 score, 或者根据 score 找 member 都是 O(logN), 但是 Redis 内部对 zscore 进行特定优化, 因此时间复杂度为 O(1))

2.12 zrem - 删除指定元素
语法: ZREM key member member ...
根据 member 删除元素.
时间复杂度: O(logN * M) , N 是整个 zset 的元素个数, M 是命令中 member 的个数.
返回值: 删除成功的元素的个数.

2.13 zremrangebyrank - 删除区间内元素(下标)
语法: ZREMRANGEBYRANK key start end
删除下标为 start, end 范围内的元素.
返回值: 删除成功的元素的个数.
时间复杂度: O(logN + M). 其中 N 指整个 zset 的个数, M 是指 start~end 中间元素的个数. 只需 O(logN) 的时间找到开头(start 下标)/结尾(end 下标)的元素, 再以 O(M) 的时间遍历并删除中间元素.

2.14 zremrangebyscore - 删除区间内元素(分数)
语法: ZREMRANGEBYSCORE key min max
zremrangebyscore, 删除 score 为 min, max 范围内的元素. 如果想要改成开区间, 依旧在 min / max 前加上 '('
返回值: 删除成功的元素的个数.

2.15 zincrby - 修改分数
语法: ZINCRBY key increment member
对 member 的 score 进行加减操作.
- 若 increment > 0, 则为加操作.
- 若 increment < 0, 则为减操作.
时间复杂度: O(logN). 先找到元素位置并修改 socre 的时间复杂度为 O(logN), 修改完后再对位置进行调整也为 O(logN), 整体为 O(logN).

2.16 交集 & 并集
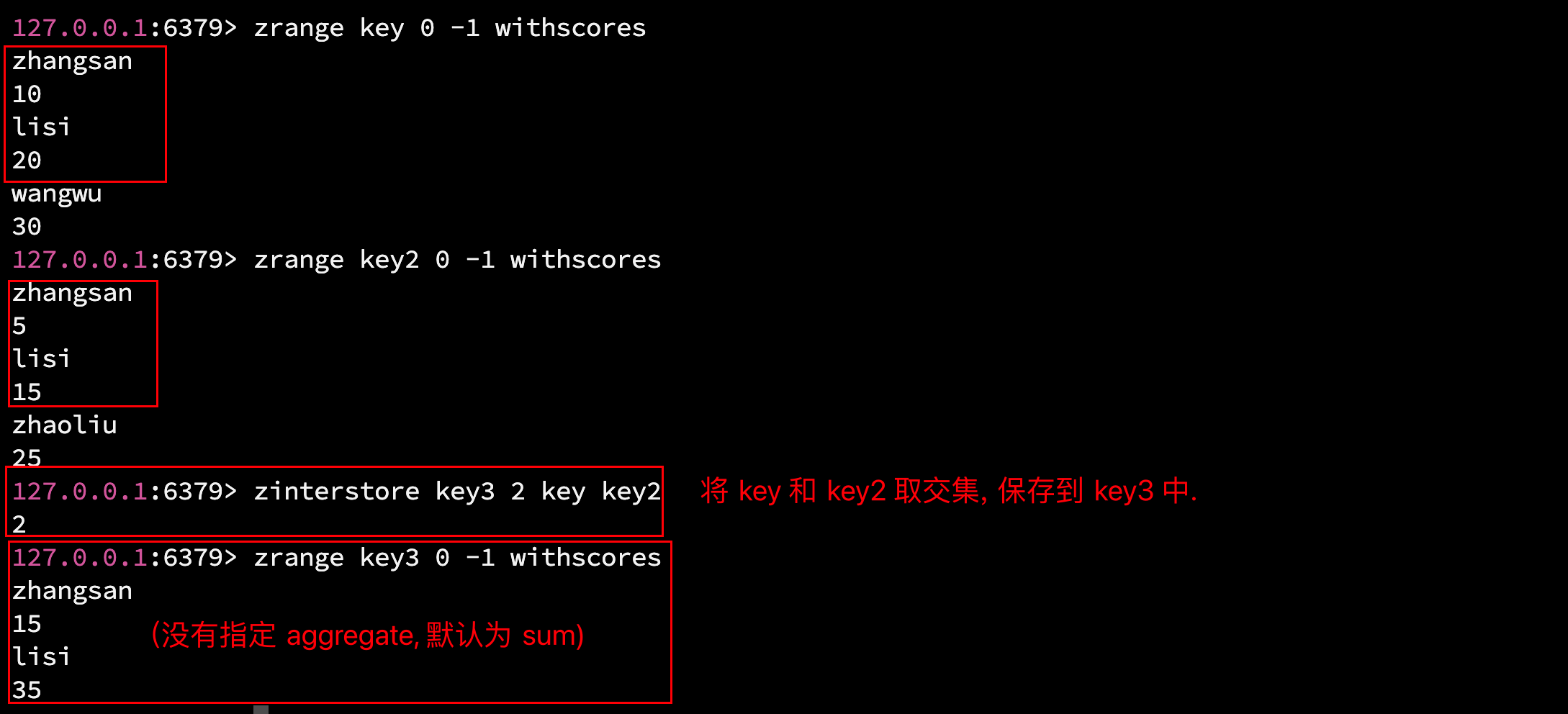
2.16.1 zinterstore - 求交集
语法: ZINTERSTORE destination numkeys key key ... WEIGHTS weight
\[weight ...] AGGREGATE \
时间复杂度: O(N)+O(M log(M))
以下是命令中的必选项:
- destination: (目标键) 一个新的有序集合的键名, 将计算出的交集存储在这里. 如果该键已存在, 其内容将被完全覆盖(清空原有数据).
- numkeys:(键数量, key 的数量) 需要进行交集计算的有序集合的数量.
以下是命令中的可选项:
- WEIGHTS: 权重/系数. 可选项, 给每个有序集合指定一个权重 (按顺序和前面的 key 一一对应), 每个成员的 score 都会乘以其对应的权重.
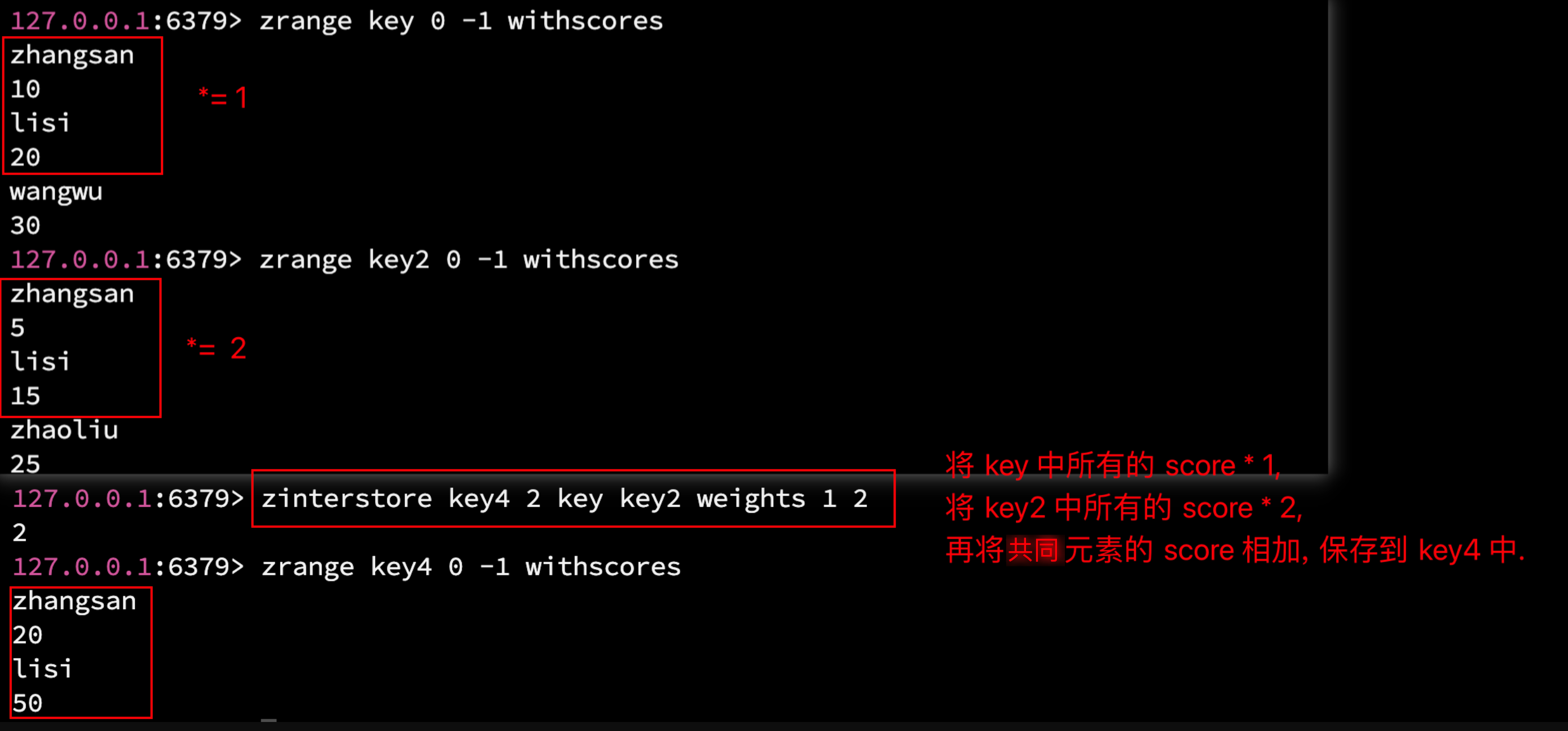
- AGGREGATE: 交集操作选出了共同的成员, 但是这些共同成员的 socre 是各不相同的, 因此最终交集中的成员的 socre 是不确定的, 而 AGGREGATE 则负责处理这些共同成员的分数.
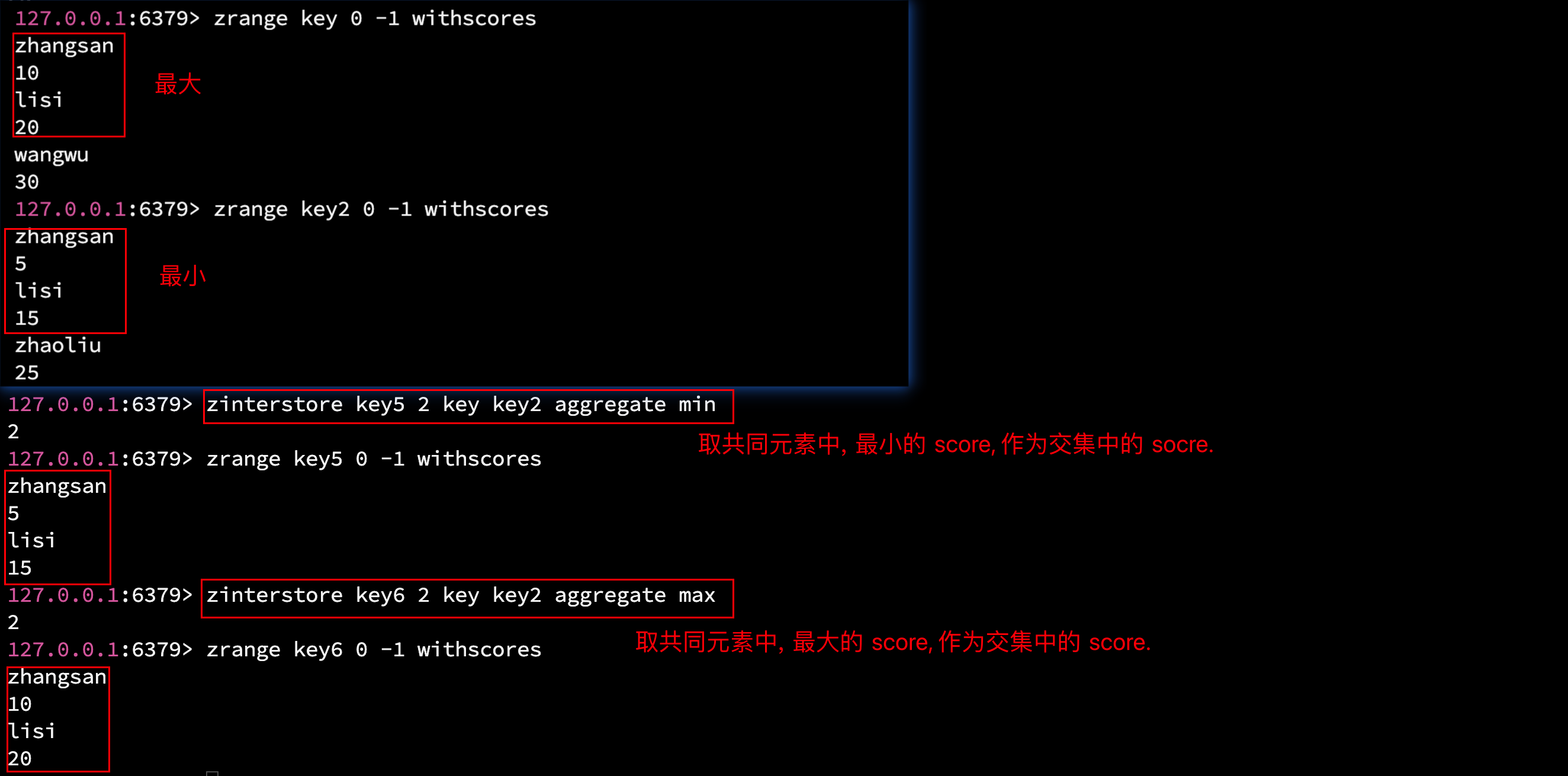
- AGGREGATE sum(默认): 将所有输入集合中该成员的 score 相加, 作为最终的 score.
- AGGREGATE max: 取所有输入集合中该成员的最大值, 作为最终 score.
- AGGREGATE min: 取所有输入集合中该成员的最小值, 作为最终 score.
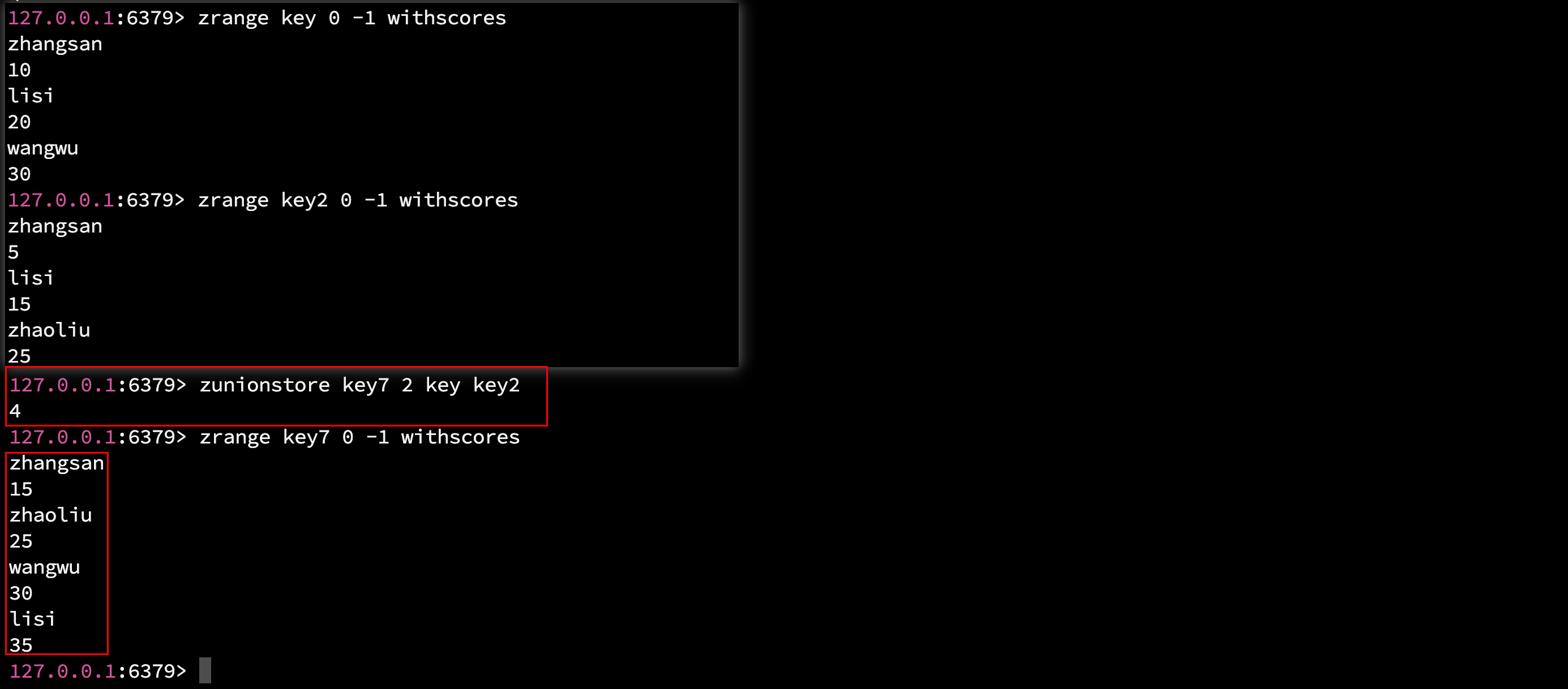
2.16.2 zunionstore - 求并集
语法: ZUNIONSTORE destination numkeys key key ... WEIGHTS weight
\[weight ...] AGGREGATE \
zunionstore 和 zinterstore 的用法一致, 只不过是求并集.
2.17 zset 内部编码
zset 主要使用了两种编码方式:
- ziplist: 压缩列表 , 节省空间, 但操作元素时效率低. 因此, 当元素个数少时, 并且单个元素体积较小时使用.
- skiplist: 跳表, 操作元素的效率为 logN (内部除了 next 和 prev 指针外, 还引入了其他指针, 能够巧妙快速的定位到指定元素) , 但占用空间大. 因此, 当元素个数较多 或者 单个元素体积较大时使用.

2.18 zset 应用场景
2.18.1 排行榜系统
由于 zset 是升序集合, 自带的升序特性, 使其广泛应用于排行榜场景, 比如:
- 微博热搜
- 游戏天梯排行榜
在上述的这些排行榜场景, 有一个关键的特征: 实时变化. 因此, 内部存储数据的结构能够高效的进行更新操作, 而 zset 就能够自动的进行升序排序, 并且时间复杂度为 O(logN).
以微博热搜举例, 就可以把 热搜词条(member) 和其 热度值(score), 存储到 zset 中, zset 就会自动的根据 热度值(socre) 进行升序排序. 并且, 如果某个词条的热度发生改变, 也可以通过 zincrby 快速的修改(O(logN) 的时间复杂度), 修改后 zset 也会自动对排序进行调整(O(logN)).
用户要查找排名前几/多少范围 内的热搜, zset 也可以通过 zrange 通过下标快速的进行范围查找.
2.18.2 计算综合热度
热搜的排行是受多种维度的影响的, 比如:
- 浏览量
- 点赞量
- 转发量
- 评论量
- ....
以上维度都会影响微博的热度, 但是不同的维度所占的权重是不同的(比如点赞量, 比浏览量更能反映热度) , 因此微博内部会对以上维度的数值进行一个综合的计算, 最终得出一个综合的热度值.
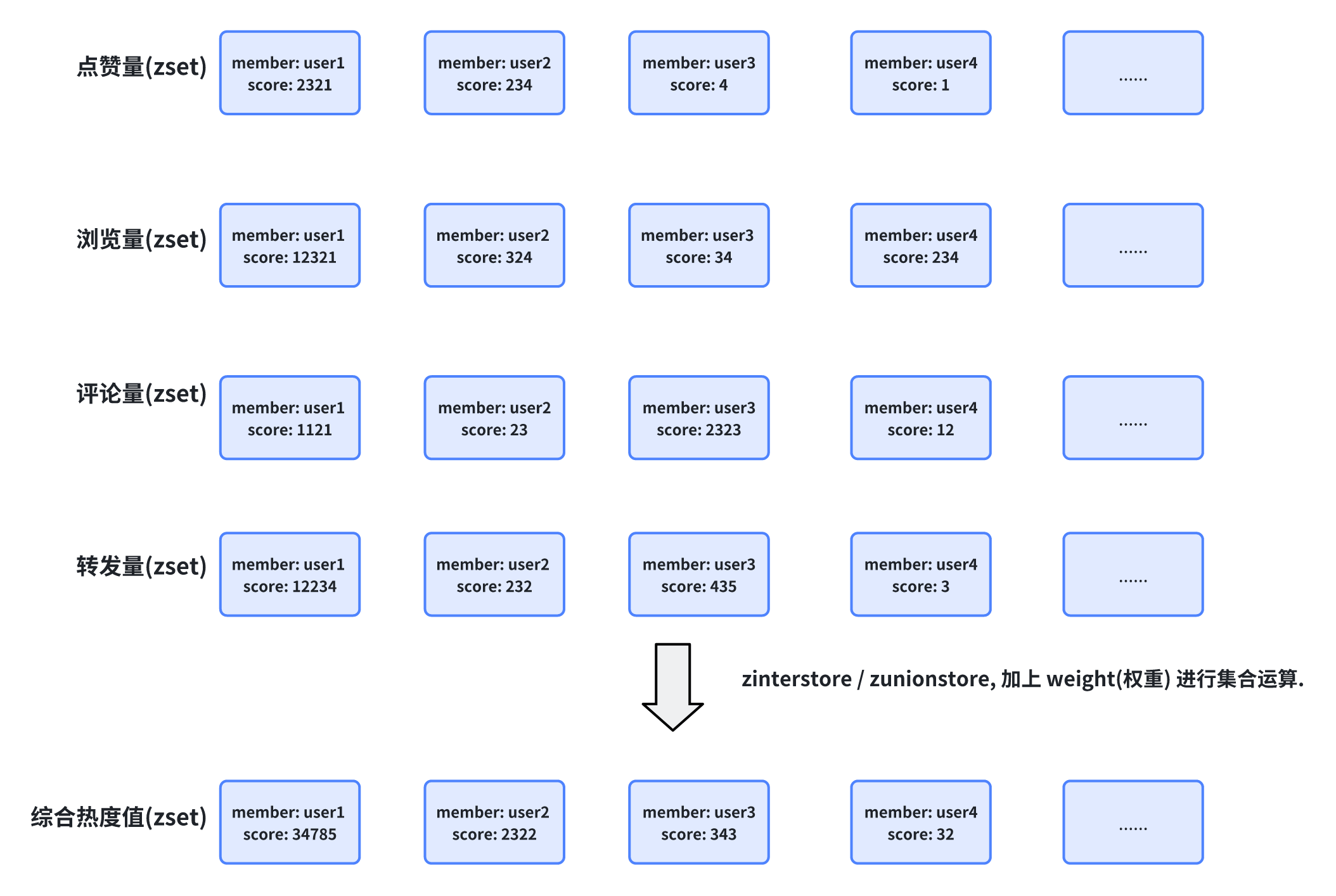
而 zset 的 zinterstore / zunionstore 就提供了 weight(权重) 来进行加权操作.
因此, 可以把 浏览量/点赞量/转发量/评论量 都各自存入一个 zset 中, member 就是 userId, socre 就是各自维度的值, 再通过 zinterstore / zunionstore 按照一定的权重, 进行一个集合间运算, 生成的新集合中的 score, 就是最终的热度值. (并且 zset 也自动进行升序排序, 顺带把排行榜也搞出来了)
end