文章目录
- 前言
- [一. 版本控制器Git](#一. 版本控制器Git)
-
- [1.1 版本控制器](#1.1 版本控制器)
- [1.2 git简史](#1.2 git简史)
- [1.3 安装git](#1.3 安装git)
- [1.4 在Gitee上创建项目](#1.4 在Gitee上创建项目)
- [1.5 git三板斧](#1.5 git三板斧)
-
- [git add](#git add)
- [git commit](#git commit)
- [git push](#git push)
- 首次使用git的配置
- [1.6 git的其它操作](#1.6 git的其它操作)
-
- [git status](#git status)
- [git log](#git log)
- [git pull](#git pull)
- [二. 调试器-gdb/cgdb的使用](#二. 调试器-gdb/cgdb的使用)
- 最后
前言
在上一篇文章中,我们详细介绍了自动化构建工具make和Makefile和第一个系统程序---进度条的内容,内容还是挺多的,希望大家可以多去练习熟悉一下,那么本篇文章将带大家详细讲解版本控制器Git和调试器---gdb/cgdb的使用的内容,接下来一起看看吧!
一. 版本控制器Git
1.1 版本控制器
为了能够更方便我们管理这些不同版本的文件,便有了版本控制器。所谓的版本控制器,就是能让你了解到一个文件的历史,以及它的发展过程的系统。通俗的讲就是一个可以记录工程的每一次改动和版本迭代的一个管理系统,同时也方便多人协同作业。
目前最主流的版本控制器就是 Git 。Git 可以控制电脑上所有格式的文件,例如 doc、excel、dwg、dgn、rvt等等。对于我们开发⼈员来说,Git 最重要的就是可以帮助我们管理软件开发项目中的源代码文件。
1.2 git简史
同生活中的许多伟大事物一样,Git 诞生于一个极富纷争大举创新的年代。
Linux 内核开源项目有着为数众多的参与者。 绝大多数的 Linux 内核维护工作都花在了提交补丁和保存归档的繁琐事务上(1991−2002年间)。 到 2002 年,整个项目组开始启用一个专有的分布式版本控制系统 BitKeeper 来管理和维护代码。
到了 2005 年,开发 BitKeeper 的商业公司同 Linux 内核开源社区的合作关系结束,他们收回了 Linux内核社区免费使用 BitKeeper 的权力。 这就迫使 Linux 开源社区(特别是 Linux 的缔造者 Linus Torvalds)基于使用 BitKeeper 时的经验教训,开发出自己的版本系统。 他们对新的系统制订了若干目标:
- 速度
- 简单的设计
- 对非线性开发模式的强力支持(允许成千上万个并行开发的分支)
- 完全分布式
- 有能力高效管理类似 Linux 内核一样的超大规模项目(速度和数据量)
自诞生于 2005 年以来,Git 日臻成熟完善,在高度易用的同时,仍然保留着初期设定的目标。 它的速度飞快,极其适合管理大项目,有着令人难以置信的非线性分支管理系统。
1.3 安装git
在CentOS系统下,可以使用如下命令安装git
powershell
yum install git可以使用如下指令查看git的版本
powershell
git --version
1.4 在Gitee上创建项目
打开链接:https://gitee.com/,先在Gitee上注册一个账号
创建仓库
点击头像旁边的+号,再点击新建仓库
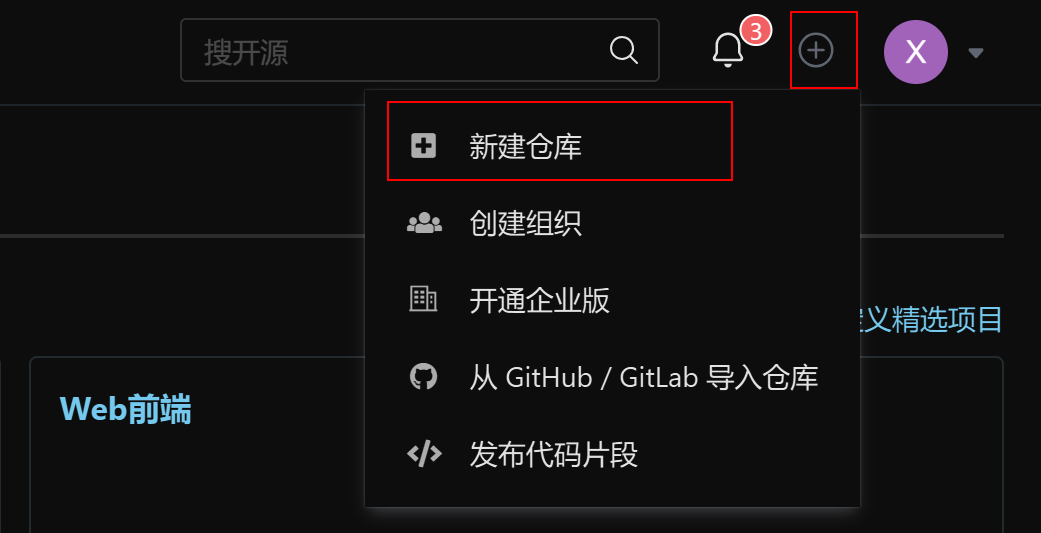
然后进入到以下界面:
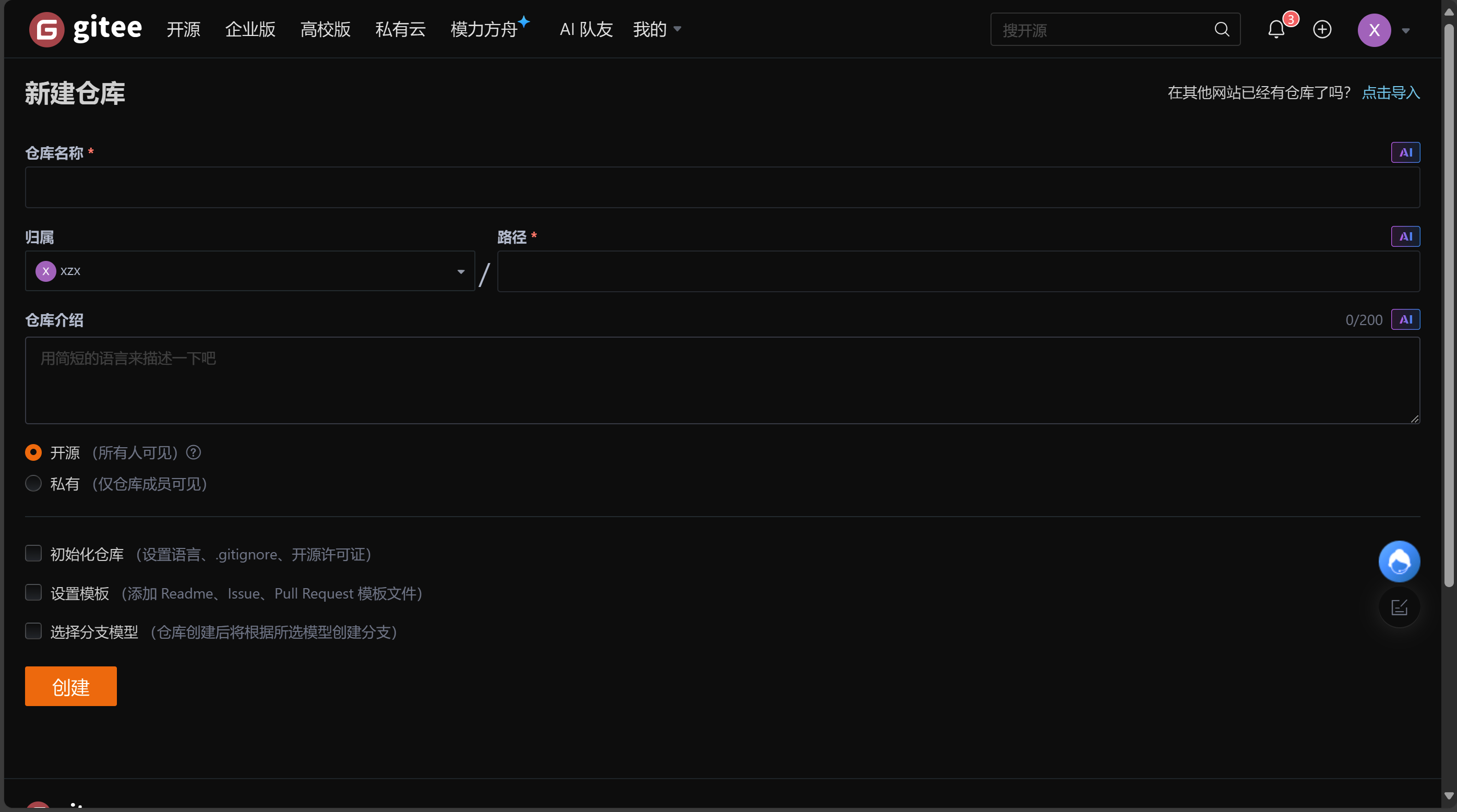
填一下自己的仓库信息:
- 仓库名称:给自己的仓库起个名字
- 仓库介绍:描述你的项目是做什么的,会显示在仓库列表和仓库首页
- 初始化仓库:是否自动构建初始文件(如 README.md、.gitignore、开源许可证等)
- 设置模板:自动添加一些常用文件,方便项目规范起步
- 选择分支模型:决定默认创建哪些分支,影响团队协作方式
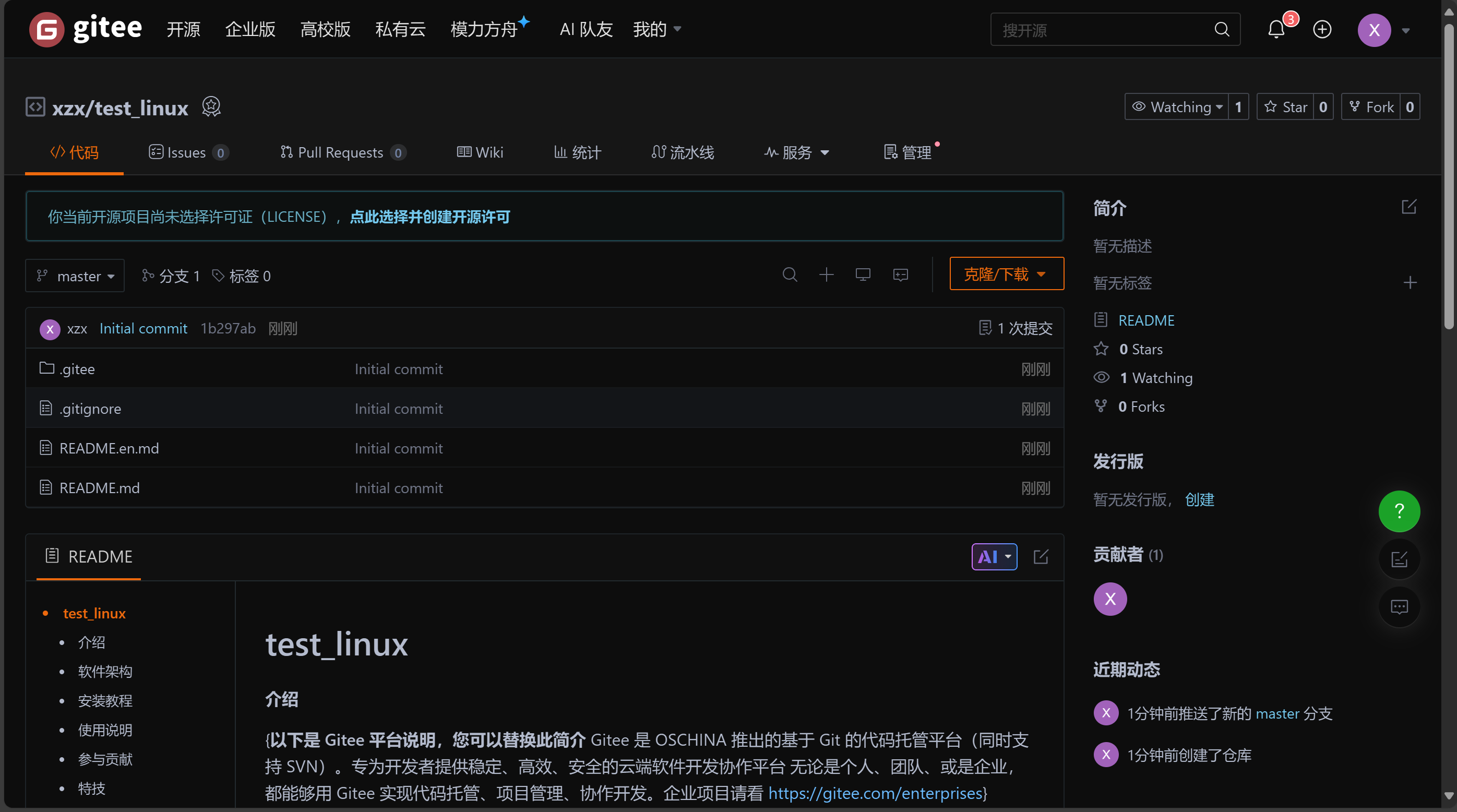
创建完仓库之后,我们将这个仓库克隆到本地
点击克隆/下载,获取到这个仓库的地址,点击复制
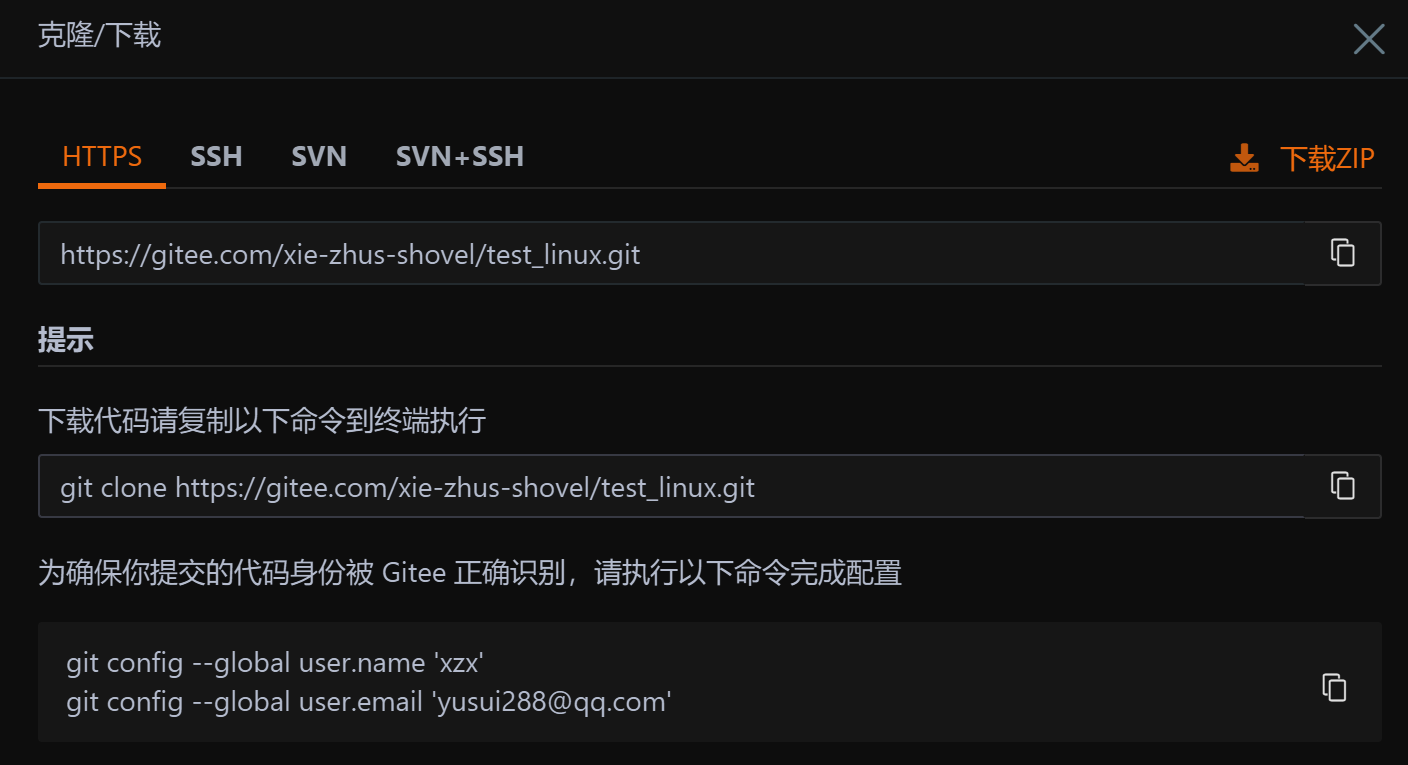
powershell
git clone https://gitee.com/xie-zhus-shovel/test_linux.git
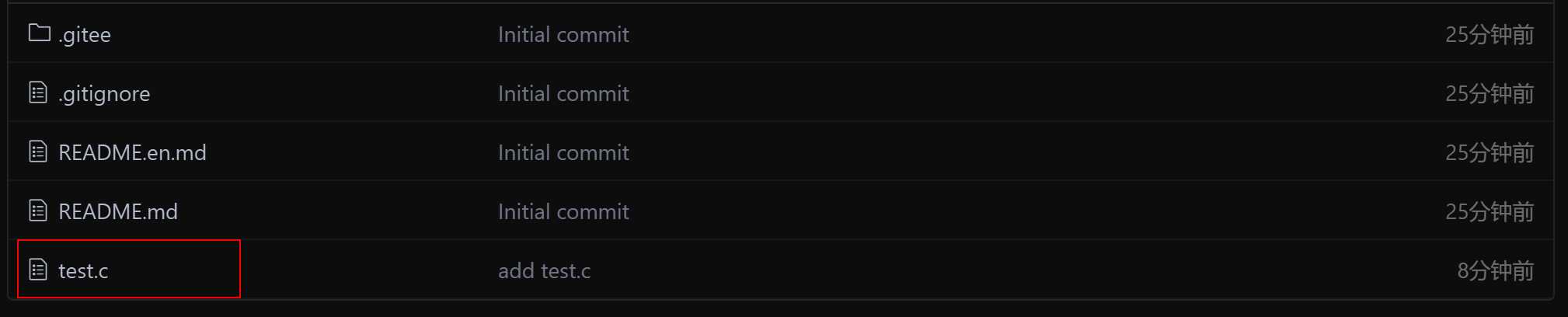
这样可以在Linux中查看仓库里的内容了

1.5 git三板斧
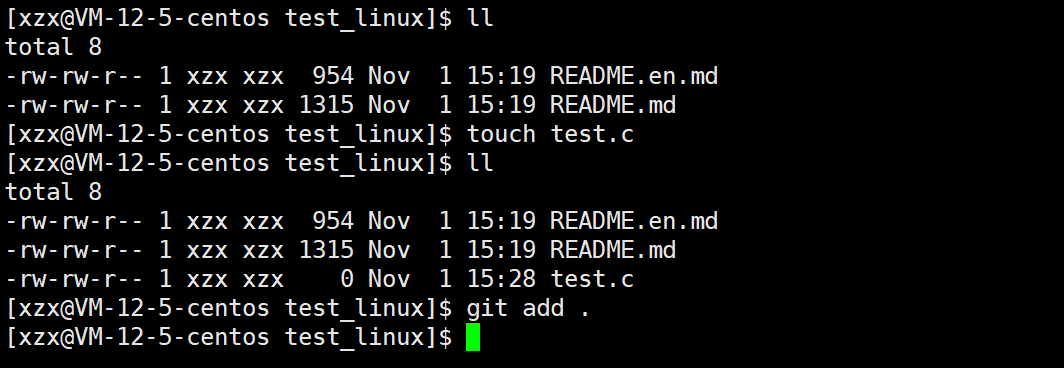
git add
powershell
git add 文件名将改动的文件放进"暂存区"
powershell
git add .把当前目录所有改动放进"暂存区"
git commit
当我们git add之后,文件只是放进了"暂存区",并没有传到本地仓库,也就是没有被管理起来,所有我们执行git commit将文件从"暂存区"传到本地仓库,让文件被管理起来。
powershell
git commit -m "本次提交说明"把暂存区的内容正式提交到本地仓库(Repository)。

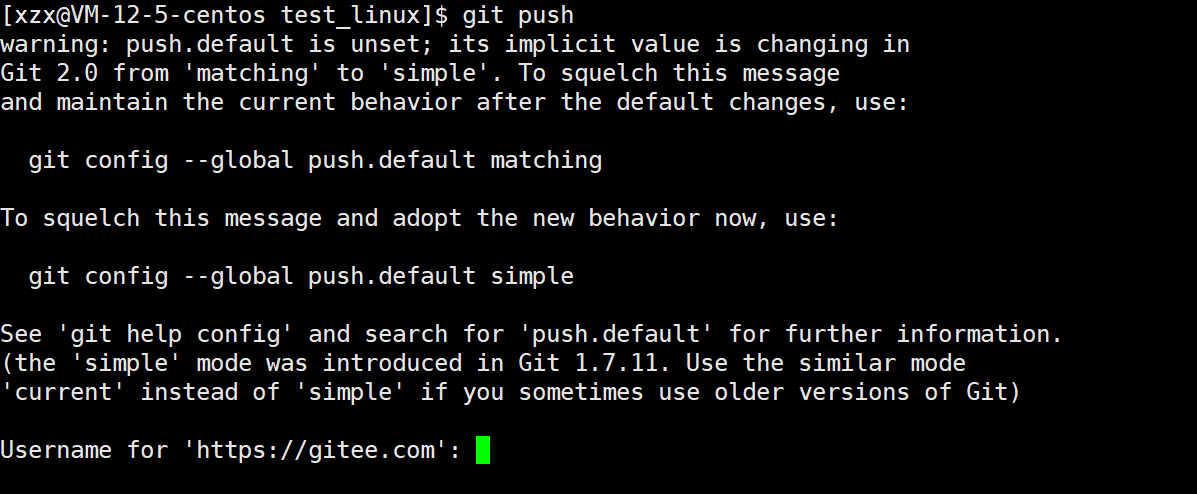
git push
git commit之后,我们已经将文件在本地仓库被管理起来了,但是这些文件还没有同步到远端仓库,所以我们在gitee上还是无法看到这些新增的文件。
使用git push就是将本地仓库同步到远端仓库
powershell
git push把本地仓库的新提交推送到远程仓库(Gitee / GitHub / GitLab 等)。
在执行git push之后,需要我们输入gitee的用户名和密码才能推送成功
首次使用git的配置
首次使用git时,为了确保提交的代码身份被 Gitee 正确识别,请执行以下命令完成配置

在Linux上也会提醒你,让你完成身份的识别
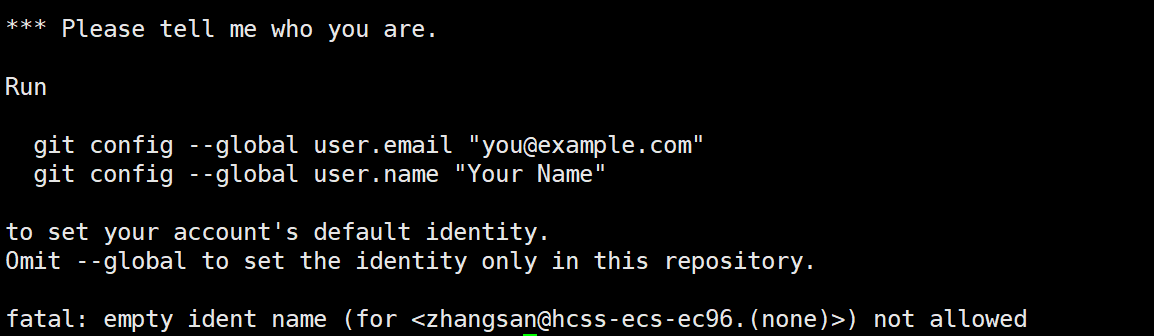
执行下面的两个指令,用你自己的用户名和邮箱
powershell
git config --global user.email "you@example.com"
git config --global user.name "Your Name"1.6 git的其它操作
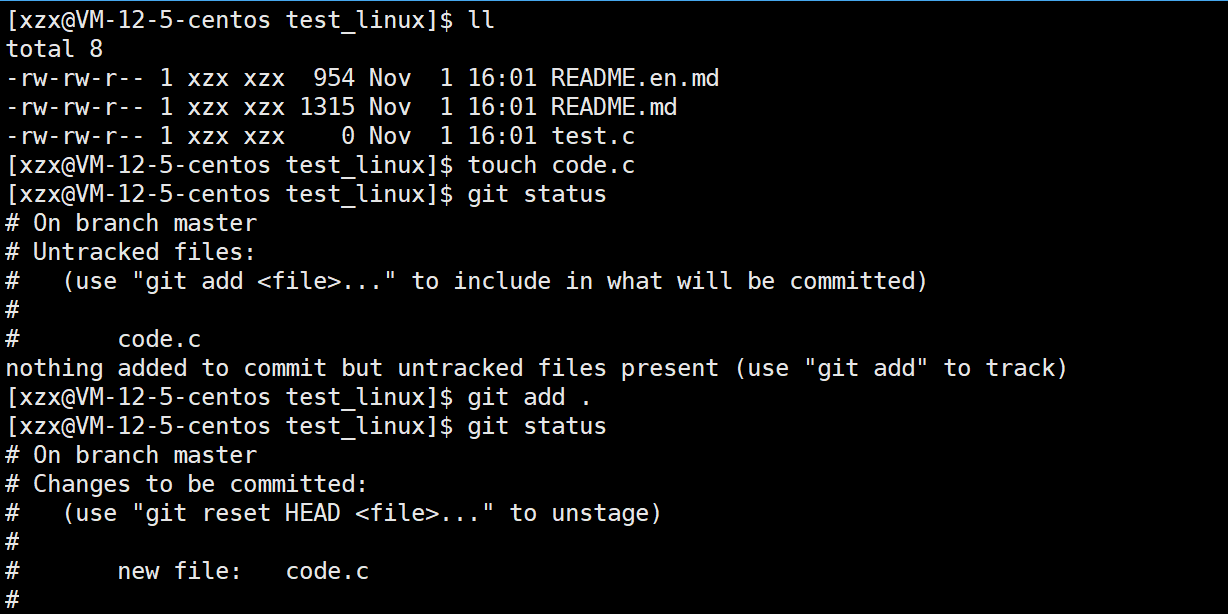
git status
作用 :显示工作区(本地修改)和暂存区(git add后的内容)的状态
git add之后
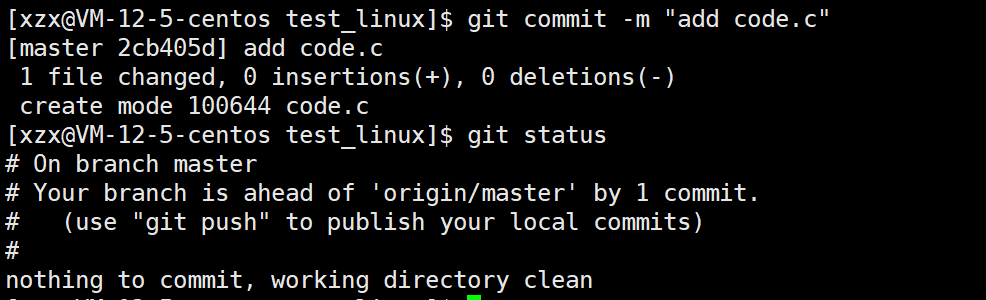
git commit之后
git push之后

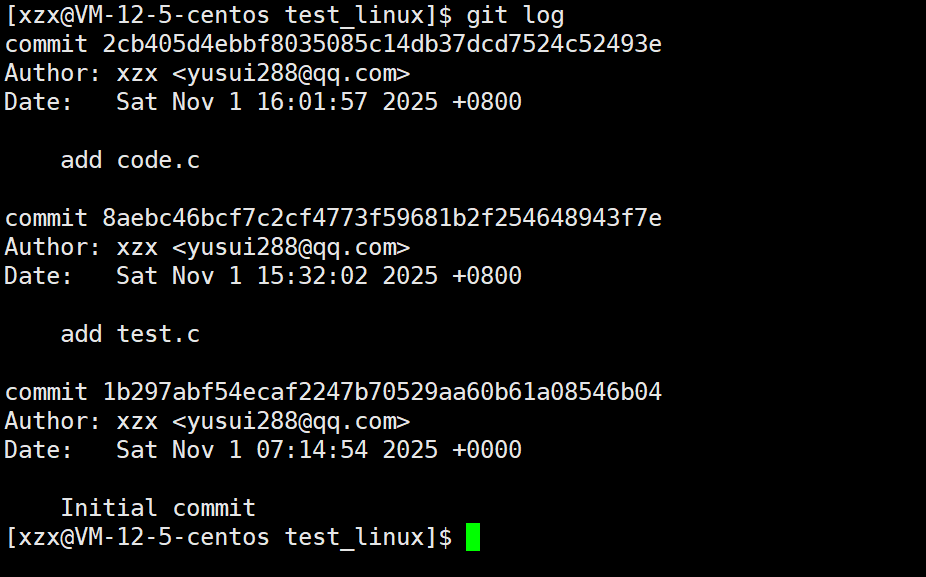
git log
作用 :查看提交历史。展示当前分支的提交记录,包括每个提交的哈希值(版本号)、作者、提交时间、提交说明等,用于回溯历史改动。按 q 键退出 git log 的浏览界面。
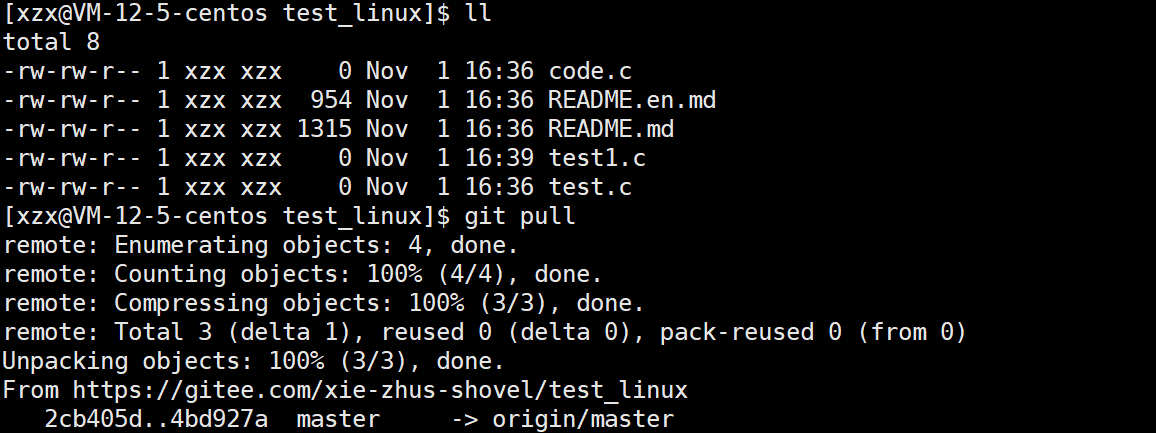
git pull
作用 :拉取远程代码并合并。从远程仓库拉取指定分支的最新代码,并自动合并到本地当前分支,确保本地代码与远程同步。
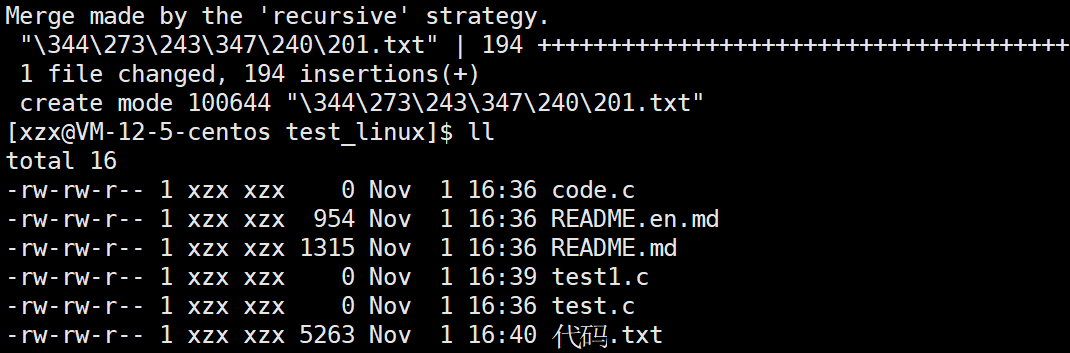
我们可以看到该目录下有一个.git文件夹,正因为有它,该目录才被识别成"仓库"
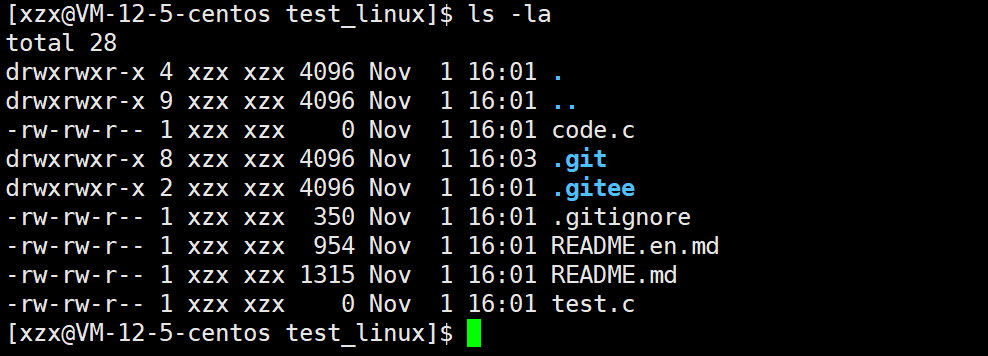
隐藏的 .git 文件夹是 Git 仓库的核心目录,它存储了 Git 用于版本控制的所有元数据、配置信息和历史记录,是 Git 能够实现代码追踪、版本管理的 "幕后大脑"。
另外还有一个.gitignore文件,这个文件是用来干什么的?
在我们将本地仓库同步到远端仓库时,有些文件是不能传过去的,因为git只帮我们存储和管理源文件,一些可执行程序文件、二进制文件等是不能存储的,所以就需要我们的
.gitignore文件帮我们过滤,里面写的就是我们需要忽略的特定后缀的文件列表。
powershell
# Prerequisites
*.d
# Compiled Object files
*.slo
*.lo
*.o
*.obj
# Precompiled Headers
*.gch
*.pch
# Linker files
*.ilk
# Debugger Files
*.pdb
# Compiled Dynamic libraries
*.so
*.dylib
*.dll
# Fortran module files
*.mod
*.smod
# Compiled Static libraries
*.lai
*.la
*.a
*.lib
# Executables
*.exe
*.out
*.app
# debug information files
*.dwo.gitignore文件存在多种文件的后缀,比如我们在编译时可能会产生临时文件.o,但是我们不希望将这个临时文件上传,这时.gitignore文件中有.o,在上传的时候就会忽略后缀为.o的文件,不会将其上传。
二. 调试器-gdb/cgdb的使用
2.1 Debug/Release模式
Debug模式
为开发者提供便捷的调试环境,优先保证 "可调试性",方便定位代码中的错误(如逻辑漏洞、内存问题等)。几乎关闭所有编译优化 (如代码折叠、循环展开、变量合并等)。会在编译时生成详细的调试符号信息 (如变量名、函数地址、源码行号映射等),存储在可执行文件或额外的调试文件(如.pdb、.dSYM)中。可执行文件体积更大。
Release模式
为最终用户生成可运行的程序,优先保证 "性能和体积",去除调试相关的冗余信息,让程序更高效、更精简。开启全量编译优化 (由编译器自动处理,如 GCC 的-O2、-O3,VS 的 "最大化速度" 等)。通常不生成或仅保留极少调试信息 (默认情况下)。体积更小(无调试信息 + 优化后精简代码),运行速度更快(编译优化 + 无冗余检查)。
Linux中 gcc编译默认生成的是Release版本,我们要生成Debug版本就要带-g选项。
有如下的code.c文件:
cpp
#include <stdio.h>
int Sum(int s, int e)
{
int result = 0;
for(int i = s; i <= e; i++)
{
result += i;
}
return result;
}
int main()
{
int start = 1;
int end = 100;
printf("I will begin\n");
int n = Sum(start, end);
printf("running done, result is: [%d-%d]=%d\n", start, end, n);
return 0;
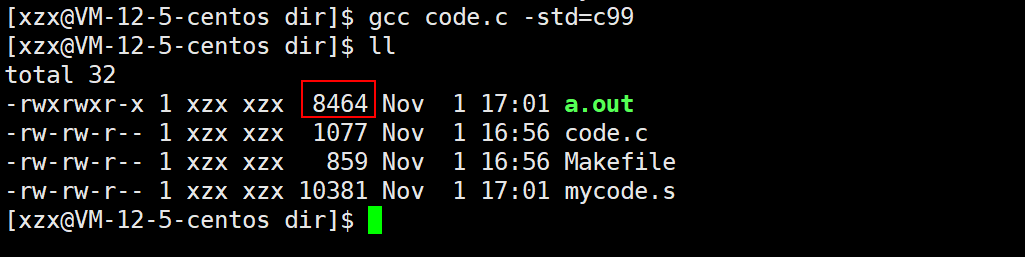
}使用gcc编译代码时,默认使用的是C98,因为C98不支持for循环中定义变量,所以它这里提示我们使用C99

Release模式下产生的可执行程序大小:
Debug模式下产生的可执行程序大小:
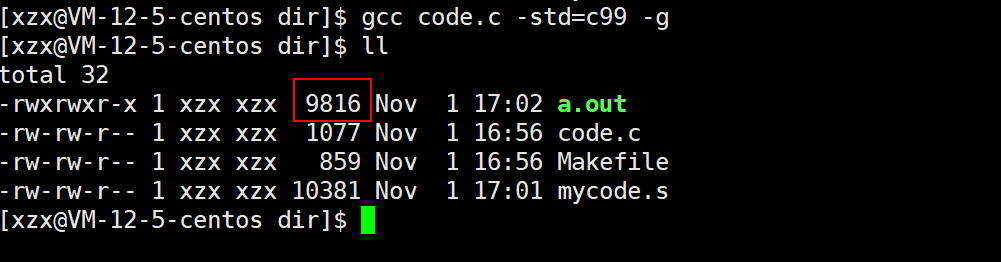
可以看到Debug模式的可执行程序确实比Release模式的要大
Makefile文件就可以默认使用C99来编译器
2.2 gdb/cgdb的使用
在使用之前需要先安装gdb/cgdb
powershell
sudo yum install -y gdb
sudo yum install -y cgdb进入调试
powershell
gdb 可执行程序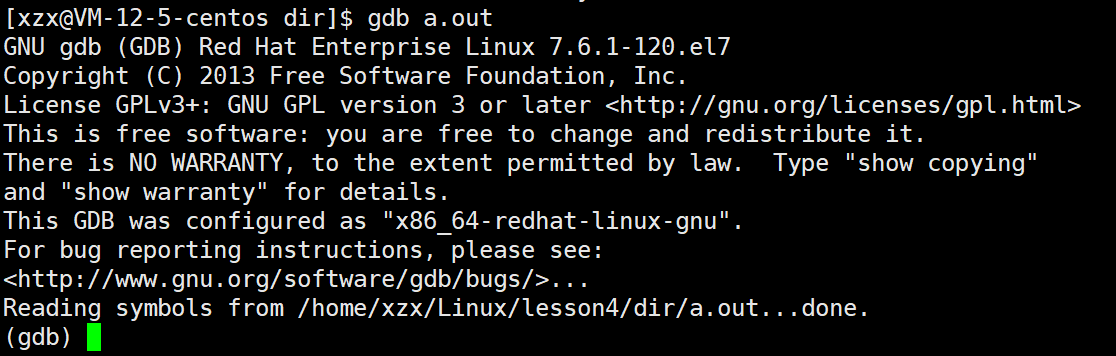
这样我们就进入gdb调试了,但是这样调试非常麻烦,因为不能对照着源代码
退出调试
powershell
quit
现在来看一下cgdb的调试界面:
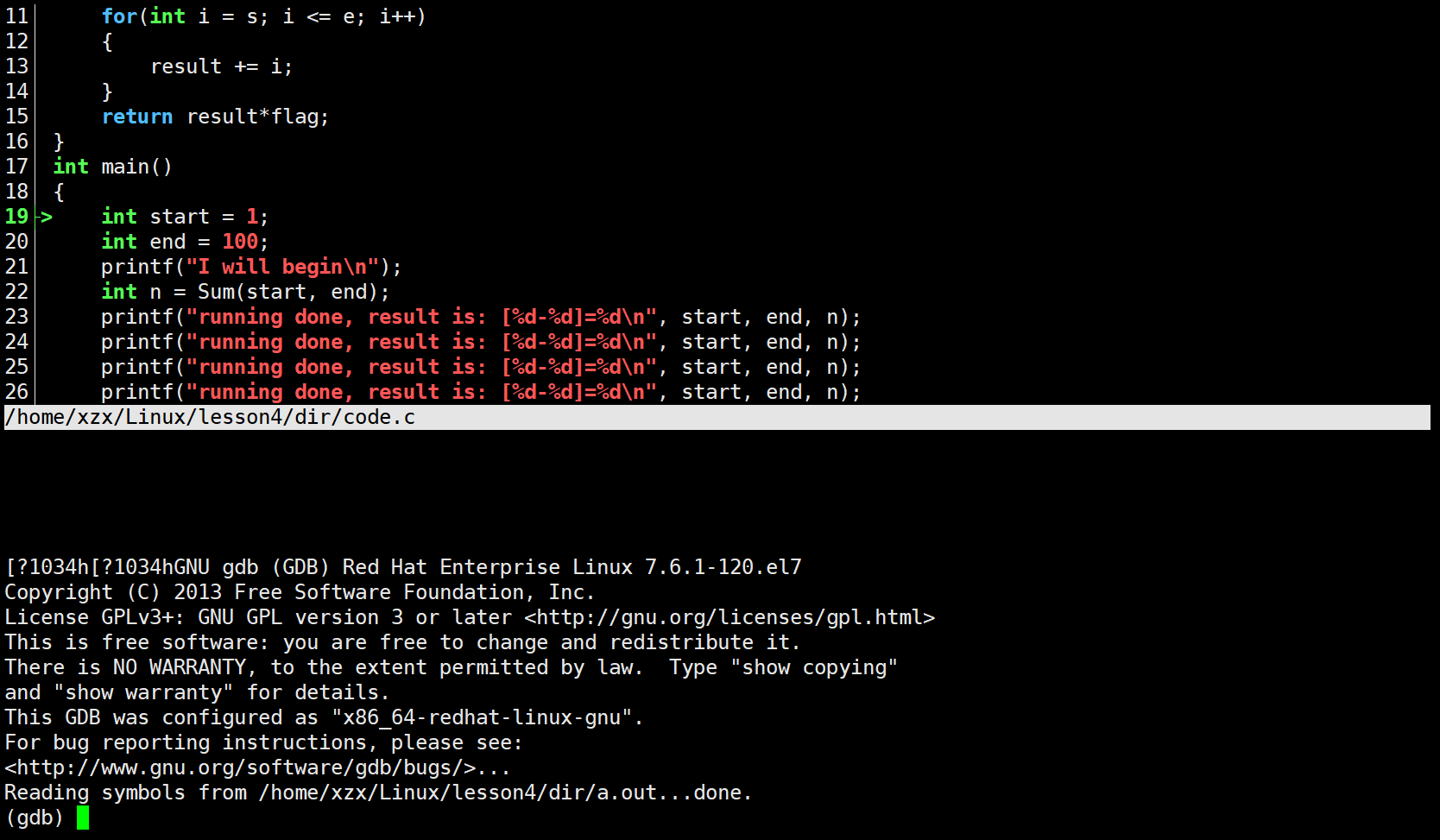
在cgdb调试界面中上半屏幕显示部分代码,下半部分用来调试代码,绿色箭头指向的位置是当前程序运行的位置。
退出调试仍然可以使用quit、q或者ctrl+d
常见的调试命令
list/l:显示源代码,从上次位置开始,每次列出10行list/l 函数名:列出指定函数的源代码list/l 文件名:行号:列出指定文件的源代码r/run:从程序入口main函数开始执行代码n/next:单步执行,不进入函数内部,相当于vs调试中的逐过程F10s/step:单步执行,进入函数内部,相当于vs调试中的逐过程F11break/b [文件名:]行号:在指定行号设置断点。比如:break 10、break test.c:10break/b 函数名:在函数开头设置断点。比如:break maininfo break/b:查看当前所有断点的信息。比如:info break/info bfinish:执行到当前函数返回,然后停止。print/p 表达式:打印表达式的值。比如:print start+endp 变量:打印指定变量的值。比如:p xset var 变量=值:修改变量的值。比如:set var i=10continue/c:从当前位置开始连续执行程序delete/d n(断点编号):删除序号为n的断点delete/d breakpoints:删除所有断点
每次设置断点都会有断点编号Num,不能d 行号,而是d 断点编号disable 断点编号:禁用指定的断点enable 断点编号:启用指定的断点disable breakpoints:禁用所有断点enable breakpoints:启用所有断点
display 变量名:跟踪显示指定变量的值(每次停止时)。比如:display xundisplay 编号:取消对指定编号的变量的跟踪显示。比如:undisplay 1until 行号:执行到指定行号。比如:until 20backtrace/bt:查看当前执行栈的各级函数调用及参数info/i locals:查看当前栈帧的局部变量值quit:退出GDB调试器
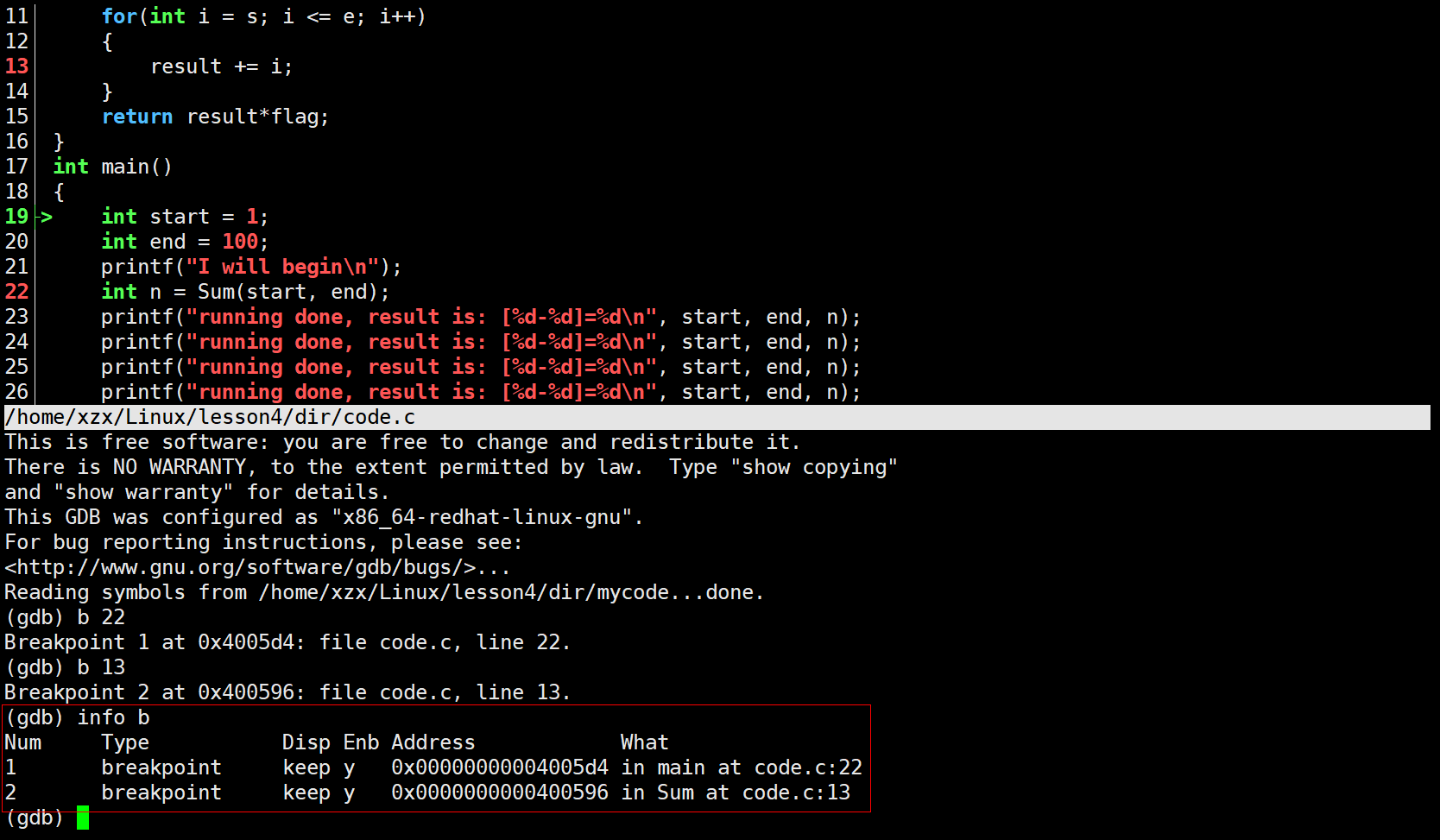
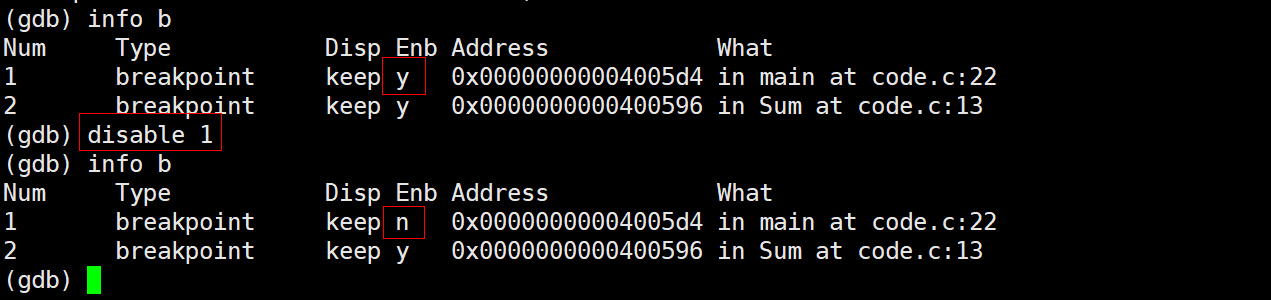
常见的调试技巧
watch
功能:执行时监视一个表达式(如变量)的值。如果监视的表达式在程序运行期间的值发生变化,GDB会暂停程序的执行,并且提示。
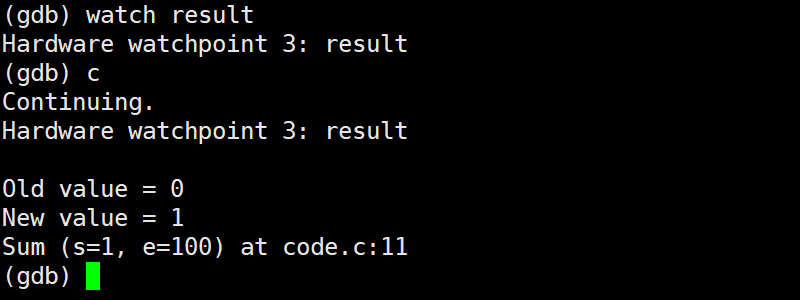
如果有一些变量不应该被修改,但是你怀疑它修改导致了问题,就可以watch这个变量,作用就是监视变量的变化。
set var
功能 :在调试的过程中,可以修改某个变量的值。

条件断点
添加条件断点
powershell
b 行号 if 条件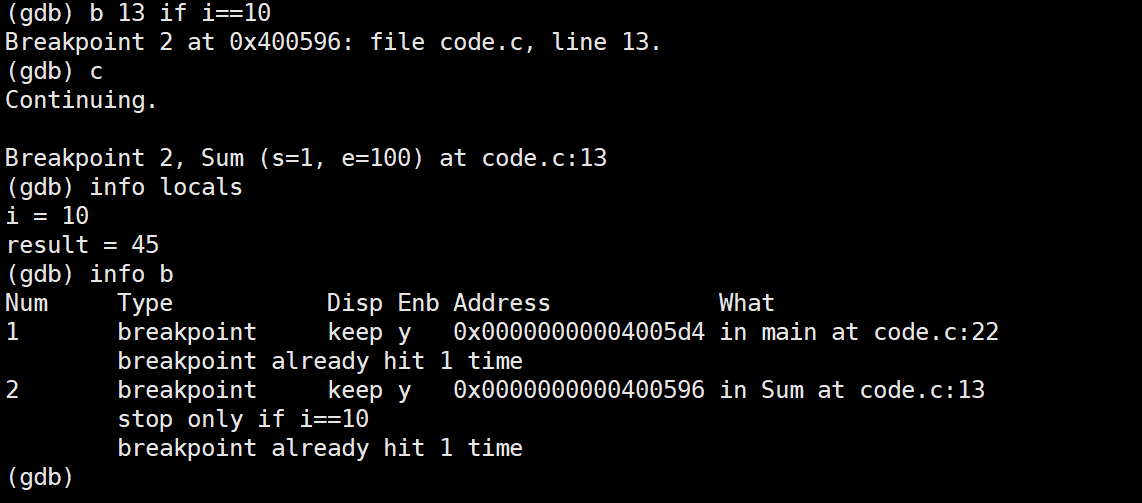
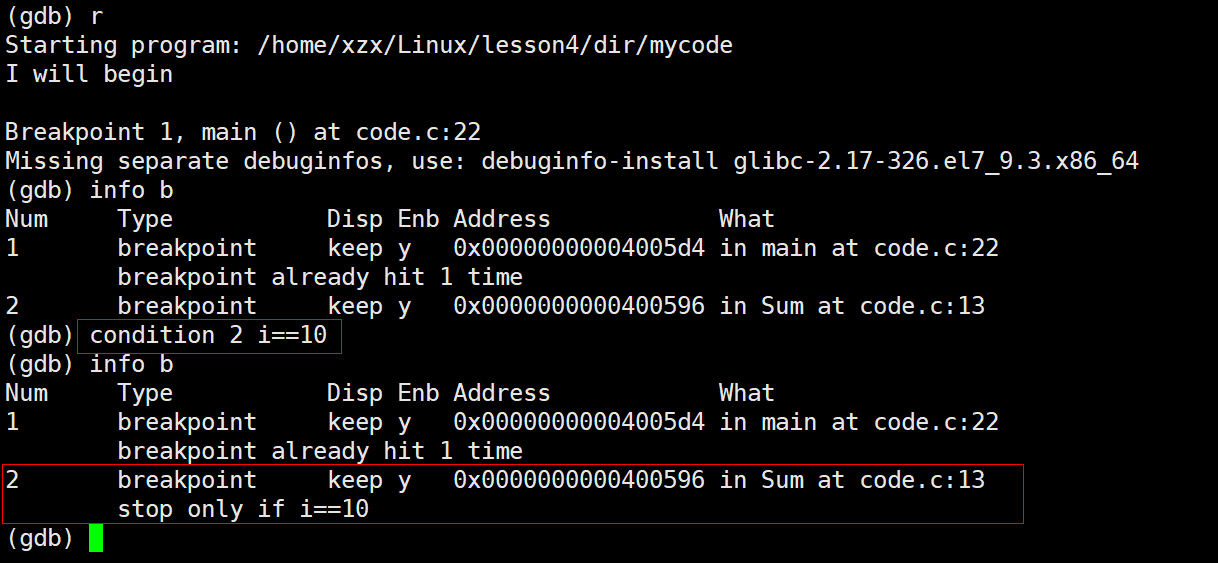
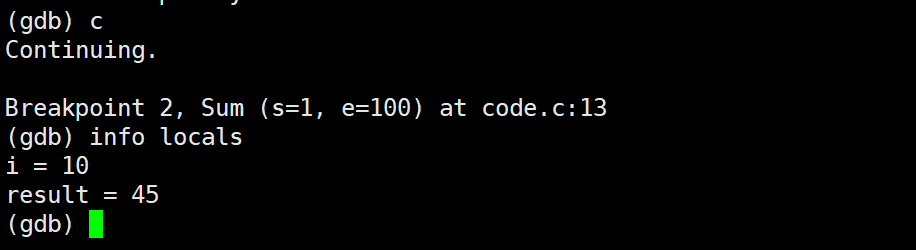
给已存在的断点新增条件
powershell
condition 断点编号 条件注意 :没有if
cgdb的分屏操作:按ESC进入代码屏,按i回到gdb屏。
最后
本篇关于版本控制器Git和调试器---gdb/cgdb的使用到这里就结束了,其中还有很多细节值得我们去探究,需要我们不断地学习。如果本篇内容对你有帮助的话就给一波三连吧,对以上内容有异议或者需要补充的,欢迎大家来讨论!