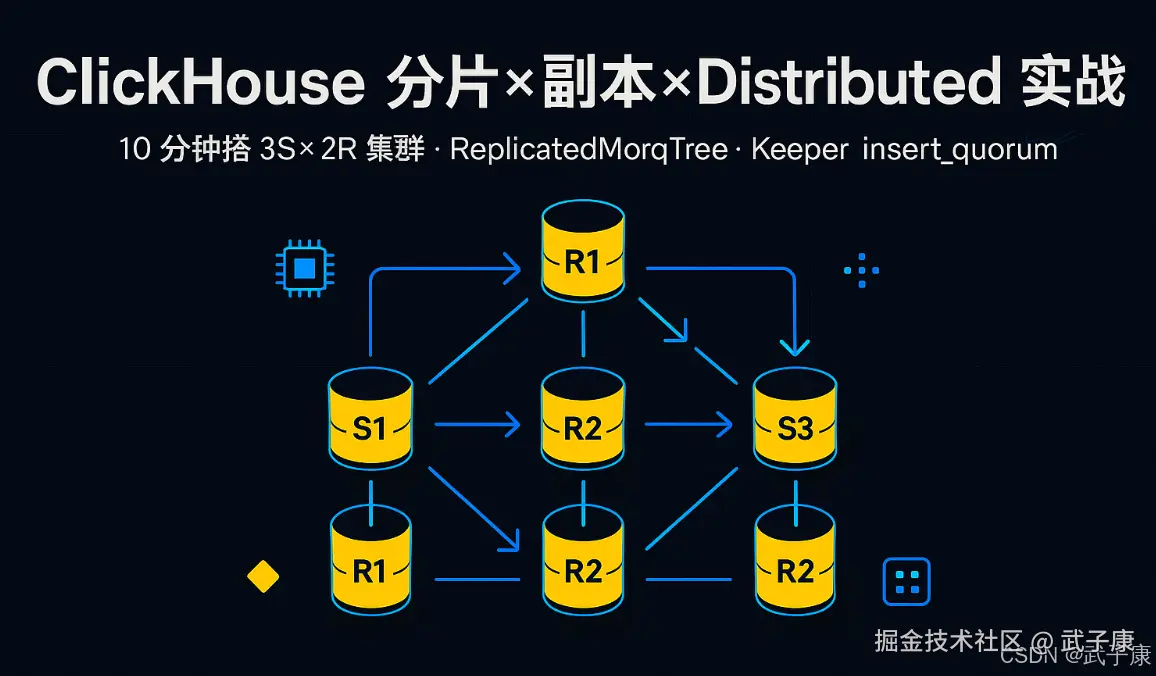
TL;DR
- 场景:三节点起步,想同时搞定"分片扩展 + 副本高可用 + 分布式查询"。
- 结论:用 ReplicatedMergeTree + Distributed,配合 insert_quorum=2、prefer_localhost_replica=1,10 分钟起一个 3 Shards × 2 Replicas 的最小闭环。
- 产出:整体的测试效果详细记录
版本矩阵
| 组件 | 已验证 | 说明 |
|---|---|---|
| ClickHouse Server | 24.x/25.x | 二选一,启用 Keeper 或外部 ZK |
| Keeper/ZooKeeper | CH-Keeper / ZK 3.8+ | 任一即可 |
| 客户端 | clickhouse-client / JDBC 0.6+ | 支持多主写入 |
| OS / JDK | Ubuntu 22.04/24.04,JDK 17/21 | JDBC 场景用到 |
分片部分
副本(Replica)
概念与原理
副本是指在分布式系统中,将相同的数据存储在不同物理节点上的技术实现。其核心思想是通过数据冗余来提升系统的可靠性。在 ClickHouse 中,每个数据分片(Shard)都会维护一个或多个完全相同的副本,这些副本节点组成一个副本组。副本之间通过特定的同步协议保持一致,当主副本节点接收到数据写入时,会通过后台进程将变更传播到其他副本节点。
核心优势
-
高可用性保障:
- 当某个节点发生硬件故障、网络分区或软件崩溃时,其他副本节点可以立即接管服务
- 示例:假设一个3副本集群,即使同时宕机2个节点,系统仍能保持可读可写
- 故障切换时间通常在毫秒级别,对业务完全透明
-
负载均衡能力:
- 读请求可以智能路由到不同的副本节点
- 在高并发场景下(如双11大促),查询压力可以均匀分布在多个副本上
- 写请求通常由主副本处理,但支持异步传播模式减轻主节点压力
-
数据安全防护:
- 防范单点数据丢失风险
- 可应对数据中心级灾难(如机房断电)
- 支持跨机架/跨可用区部署副本
技术实现细节
在 ClickHouse 中,副本机制通过以下组件协作实现:
-
ReplicatedMergeTree引擎:
- 基础表引擎,内置副本同步逻辑
- 每个副本维护自己的part文件,但通过zookeeper协调一致性
- 支持后台自动合并(Merge)和去重
-
ZooKeeper协调服务:
- 存储副本元数据和同步状态
- 维护全局日志(Log)记录所有数据变更
- 实现分布式锁确保写入顺序
- 监控副本健康状态
-
数据同步流程:
- 写入流程:客户端 → 主副本 → ZooKeeper日志 → 其他副本消费日志
- 采用多线程并行传输,支持断点续传
- 增量同步机制,仅传输差异数据
配置示例
典型的三副本配置方案:
xml
<!-- config.xml -->
<remote_servers>
<cluster_3shards_3replicas>
<shard>
<replica>
<host>ch01</host>
<port>9000</port>
</replica>
<replica>
<host>ch02</host>
<port>9000</port>
</replica>
<replica>
<host>ch03</host>
<port>9000</port>
</replica>
</shard>
</cluster_3shards_3replicas>
</remote_servers>创建复制表:
sql
CREATE TABLE metrics (
timestamp DateTime,
value Float64
) ENGINE = ReplicatedMergeTree(
'/clickhouse/tables/{shard}/metrics',
'{replica}'
)
ORDER BY timestamp;运维注意事项
-
副本数量选择:
- 生产环境建议至少3副本
- 关键业务可配置5副本
- 考虑存储成本与可靠性平衡
-
监控指标:
- 副本延迟时间(replica_lag)
- ZooKeeper连接状态
- 副本同步队列长度
-
扩展操作:
- 动态添加副本:ALTER TABLE ATTACH REPLICA
- 副本迁移:通过rsync工具迁移数据目录
- 副本修复:使用FETCH PARTITION命令
Distributed 表
- 概念:Distributed 表是一种特殊的表类型,它不直接存储数据,而是将查询转发到多个分片或副本表中。这使得用户可以对多个节点执行统一的查询。
- 目的:通过 Distributed 表,可以将查询透明地分发到各个分片和副本上,最大化利用集群的并行处理能力。它简化了跨节点、跨分片查询的复杂性。
- 实现:在定义 Distributed 表时,需要指定目标集群、数据库和底层存储表的名字。
查询 Distributed 表时,ClickHouse 会根据分片键(如果存在)将查询转发到各个分片执行,并将各分片的结果汇总返回。 Distributed 表可以自动处理分片和副本的负载均衡。
分片、副本与 Distributed 表的组合
- 分片与副本的组合:通过分片,集群可以水平扩展,而通过副本,集群能够实现高可用性。当一个集群有多个分片和副本时,ClickHouse 会首先将数据分片,确保每个分片在不同的服务器上;每个分片的数据会有多个副本,副本分布在不同的节点上。
- 查询策略:查询通常会通过 Distributed 表执行。ClickHouse 会自动选择一个副本来读取数据,如果某个副本不可用,它会自动切换到其他可用副本上。查询时,可以利用并行处理,在多个分片上同时进行查询计算,提升整体查询性能。
- 副本一致性:当数据写入到副本时,ClickHouse 使用强一致性协议,确保每个副本在写入时数据是相同的。通过 ZooKeeper 管理副本的同步和协调,副本在恢复后可以从其他节点拉取丢失的数据。
优点与挑战
优点
- 高可用性:通过副本机制,即使某个节点宕机,查询和数据仍然可用。
- 可扩展性:分片机制允许系统在大规模数据场景下水平扩展。
- 高性能:Distributed 表的并行查询处理机制大大提升了查询速度,尤其在多分片、多节点的环境下。
挑战
- 管理复杂性:集群、分片、副本、ZooKeeper 之间的协调关系比较复杂,配置和维护需要较高的技术能力。
- 数据延迟:虽然副本同步机制较为强大,但在某些极端情况下,副本之间可能存在数据延迟。
配置文件
我们配置集群的时候,已经配置过了。 这里我把配置文件在粘贴到这里一次:(记得端口的事情)
xml
<yandex>
<remote_servers>
<perftest_3shards_1replicas>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>h121.wzk.icu</host>
<port>9000</port>
<user>default</user>
<password>clickhouse@wzk.icu</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>h122.wzk.icu</host>
<port>9000</port>
<user>default</user>
<password>clickhouse@wzk.icu</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>h123.wzk.icu</host>
<port>9000</port>
<user>default</user>
<password>clickhouse@wzk.icu</password>
</replica>
</shard>
</perftest_3shards_1replicas>
</remote_servers>
<zookeeper-servers>
<node index="1">
<host>h121.wzk.icu</host>
<port>2181</port>
</node>
<node index="2">
<host>h122.wzk.icu</host>
<port>2181</port>
</node>
<node index="3">
<host>h123.wzk.icu</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<shard>01</shard>
<replica>h121.wzk.icu</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>Distributed用法
Distributed表引擎
- all 全局查询
- local 真正的保存数据的表
Distributed
分布式引擎,本身不存储数据,但可以在多个服务器上进行分布式查询。 读是自动并行的,读取时,远程服务器表的索引(如果有的话)会被使用。 指令是:
shell
Distributed(cluster_name, database, table [, sharding_key])参数解析:
- cluster_name 服务器配置文件中的集群名,在我们配置的metrika.xml中
- database 数据库名
- table 表名
- sharding_key 数据分片键
案例演示
创建新表
在3台节点上的t表插入新建表 注意:是三台节点都要!!!
sql
CREATE TABLE test_tiny_log(
id UInt16,
name String
) ENGINE = TinyLog;执行结果如下图所示: 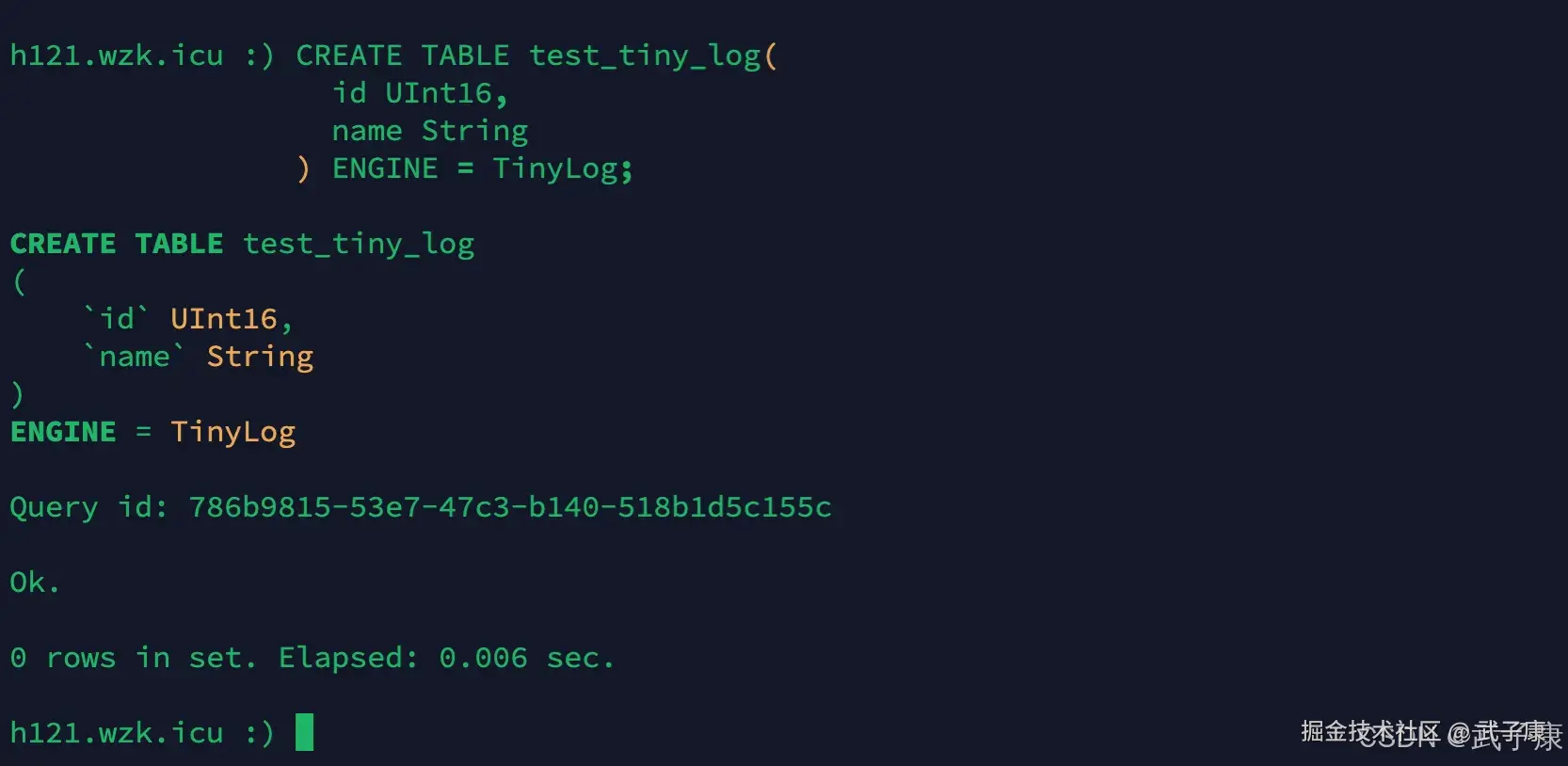
插入数据
在3台节点上的t表插入一些数据 注意:是三台节点都要!!!
sql
INSERT INTO test_tiny_log VALUES (1, 'wzk');
INSERT INTO test_tiny_log VALUES (2, 'icu');
SELECT
*
FROM
test_tiny_log执行结果如下图所示: 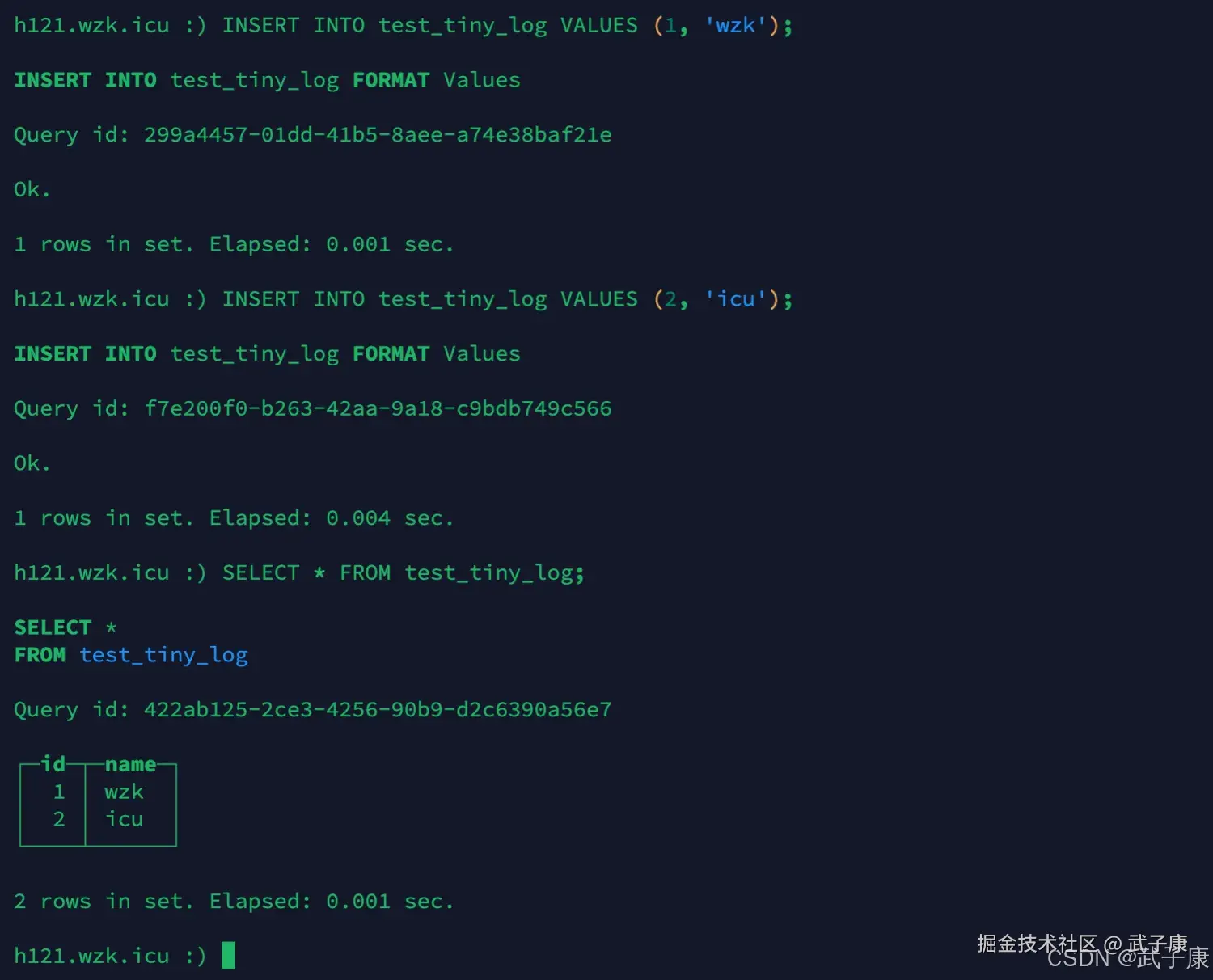
分布式表
sql
CREATE TABLE dis_table(
id UInt16,
name String
) ENGINE = Distributed(perftest_3shards_1replicas, default, test_tiny_log, id);执行代码如下: 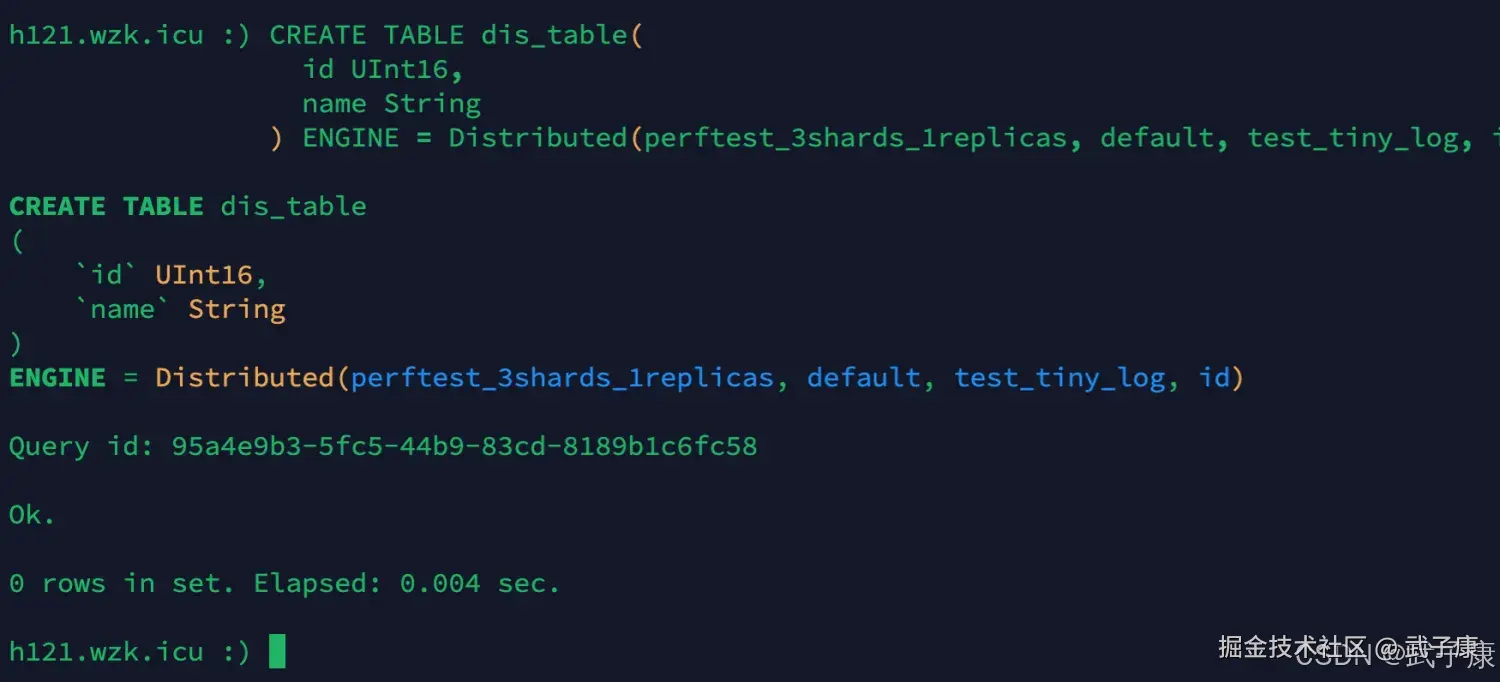
插入数据
sql
INSERT INTO dis_table SELECT * FROM test_tiny_log;插入我们刚才准备的数据: 
查询数据
sql
select count() from dis_table;运行结束后,对应的截图如下所示: 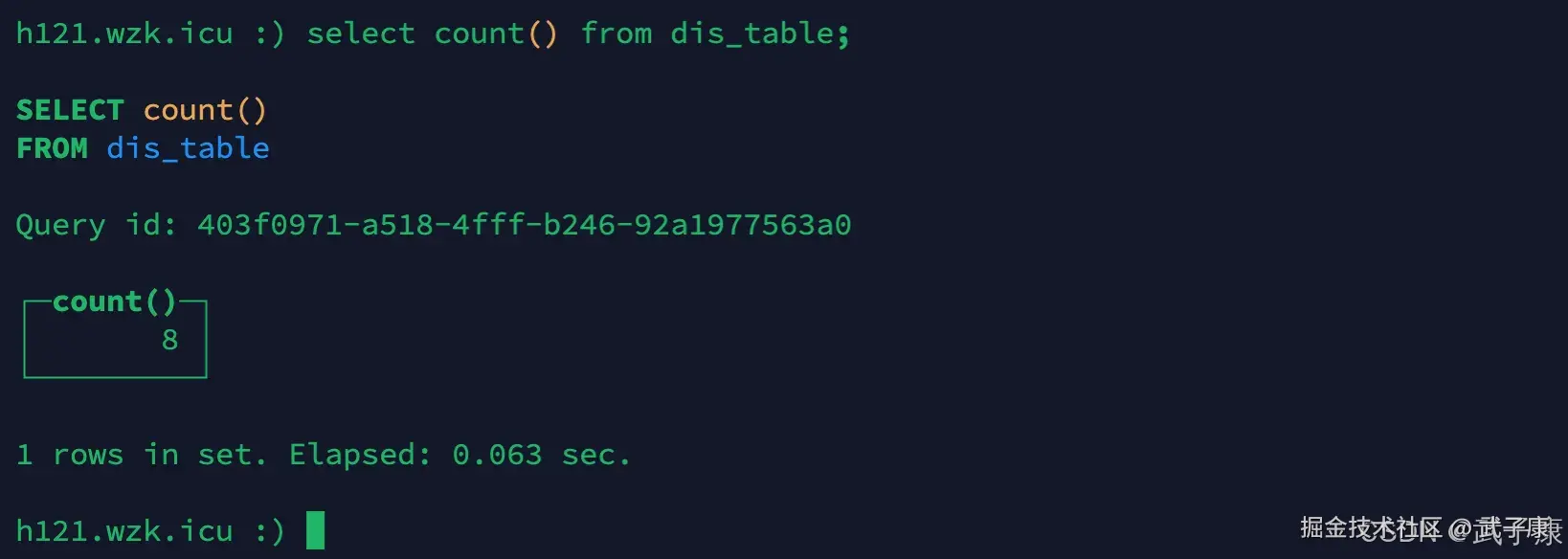 查看每台节点的数据:
查看每台节点的数据:
sql
SELECT COUNT() FROM test_tiny_log;执行结果如下图: h121节点的返回: 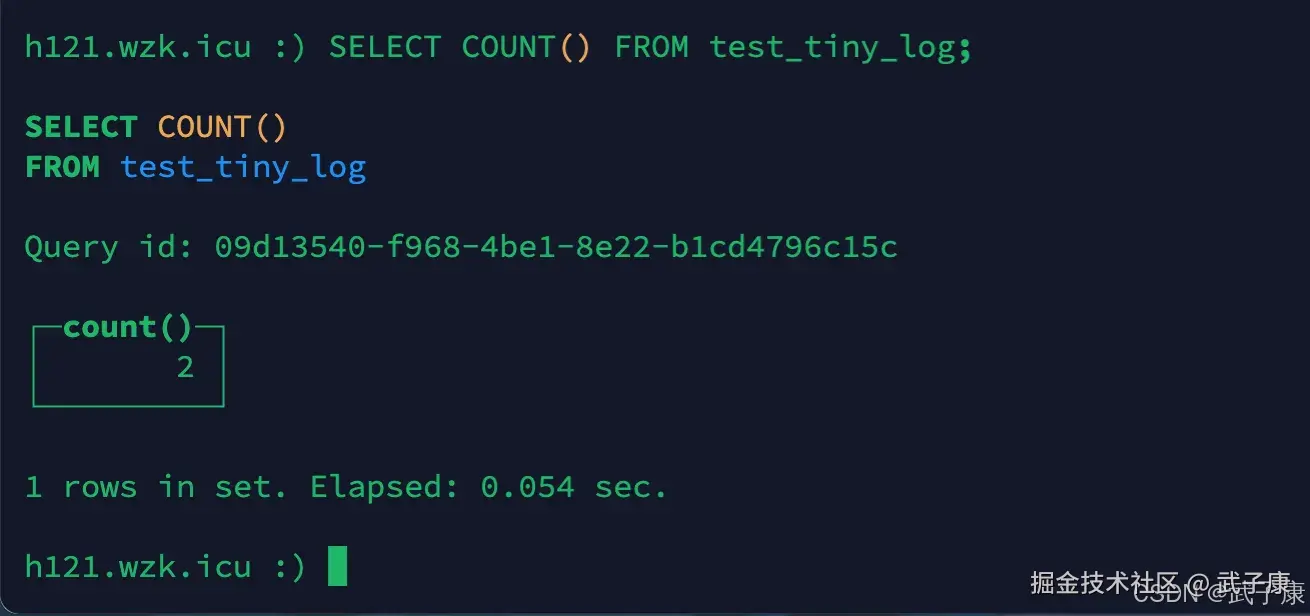
h122节点的返回: 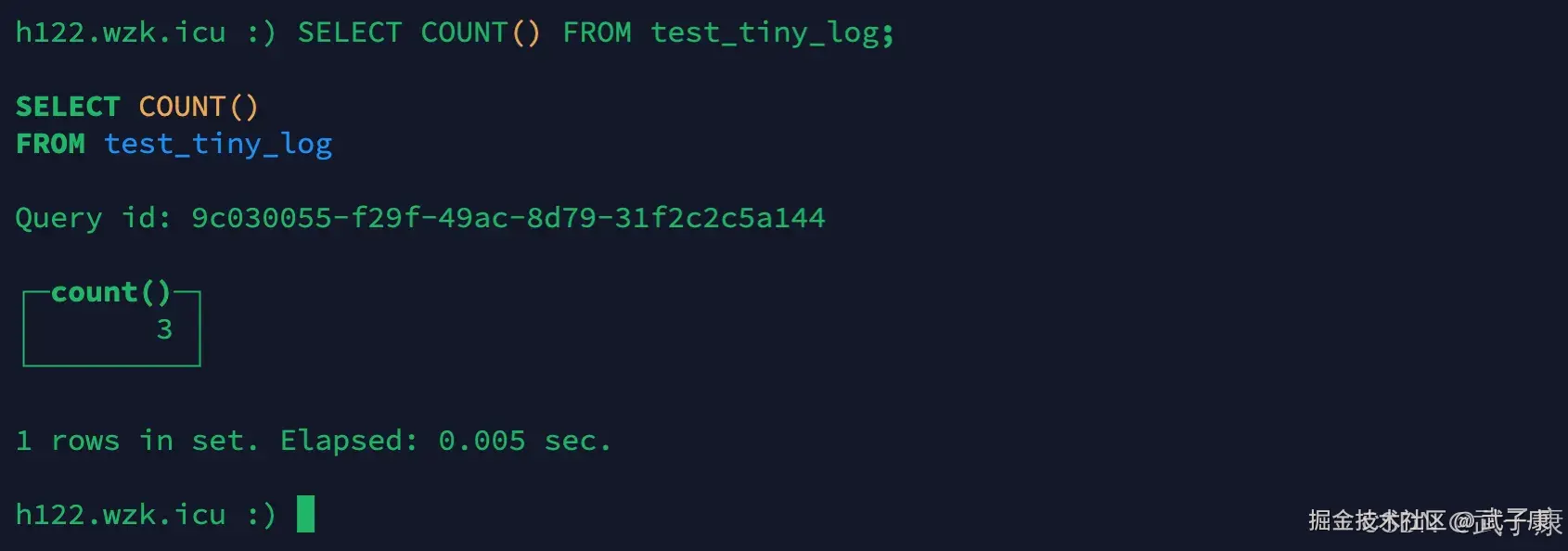
h123节点的返回: 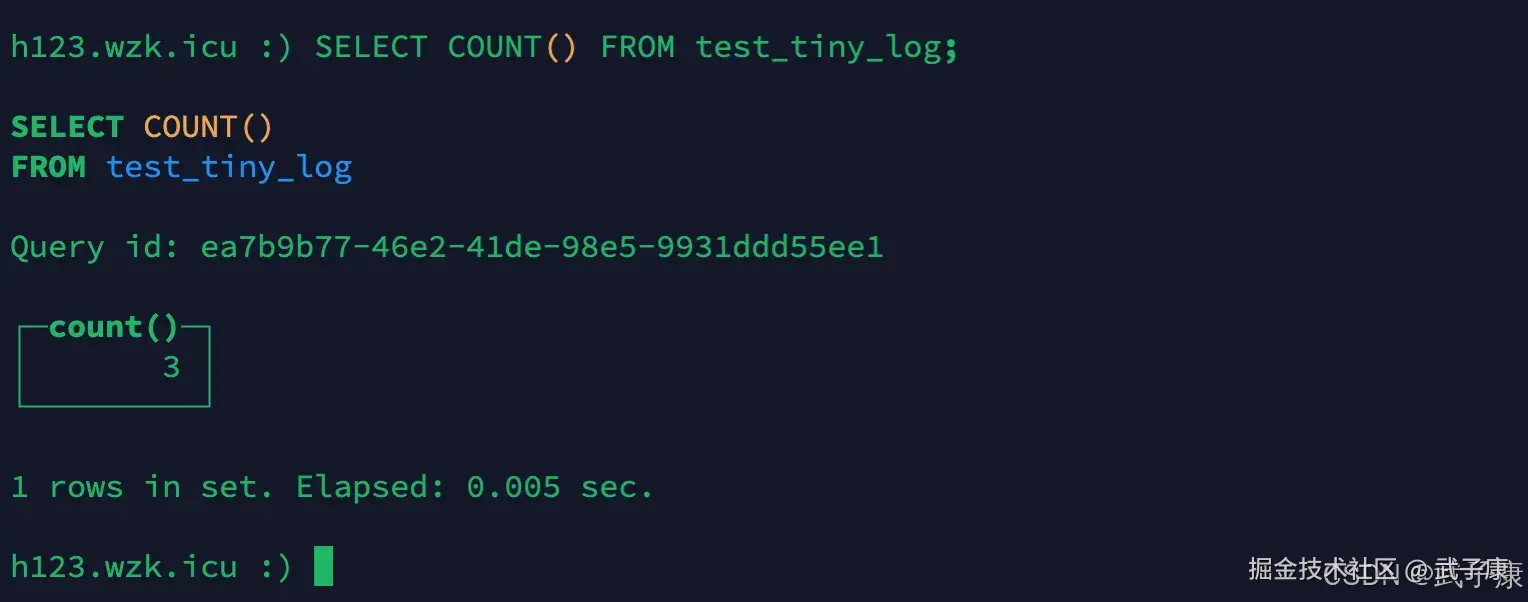 可以看到三台的总数量(2 + 3 + 3)等于我们的分布式表dis_table(8)的数量,每个节点大约有 1/3 的数据。
可以看到三台的总数量(2 + 3 + 3)等于我们的分布式表dis_table(8)的数量,每个节点大约有 1/3 的数据。
错误速查
| 症状/报错 | 常见根因 | 一步定位 | 快速修复 |
|---|---|---|---|
| Table ... doesn't exist on replica | ON CLUSTER 未执行到、或手动建表不一致 | system.replicas/system.tables | 补 CREATE ... ON CLUSTER 或 ATTACH TABLE |
| ZooKeeper session expired | ZK/Keeper 抖动 | system.zookeeper/server log | 排查网络/超时;提高 session/operation 超时 |
| Too many parts | 小分片过多、合并跟不上 | system.parts/system.merge_tree_settings | 提大批量、调合并阈值、优化分区键 |
| Not enough quorums to write | insert_quorum 要求过高 | server log | 下调 insert_quorum 或恢复副本 |
| Readonly replica | 磁盘满/只读 | system.replicas.is_readonly=1 | 清理磁盘/解除只读 |
| Connection refused(分布式读) | 节点离线或端口错 | system.clusters | 修节点或改 remote_servers |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解