标题:DreamVideo: Composing Your Dream Videos with Customized Subject and Motion
作者:Yujie Wei, Yu Liu, Shiwei Zhang, Zhiwu Qing, Hangjie Yuan, Zhiheng Liu, Yingya Zhang, Jingren Zhou, Hongming Shan
单位:1 Fudan University(复旦大学), 2 Alibaba Group(阿里巴巴集团), 3 Huazhong University of Science and Technology(华中科技大学), 4 Zhejiang University(浙江大学)
发表:CVPR 2024
论文链接 :https://arxiv.org/pdf/2312.04433
项目链接 :https://dreamvideot2v.github.io
代码链接 :https://github.com/ali-vilab/VGen (阿里视觉生成库)
关键词:定制化视频生成、扩散模型、主体学习、动作学习、轻量级适配器、文本引导生成、时空一致性
在文本驱动的生成式 AI 领域,图像生成技术已日趋成熟,但视频生成因需同时兼顾空间主体一致性与时间动作连贯性,仍是更具挑战性的课题。本文解读的 CVPR 论文《DreamVideo: Composing Your Dream Videos with Customized Subject and Motion》提出了一种创新方案,首次实现了 "任意主体 + 任意动作" 的灵活定制视频生成。
一、研究背景与动机
1.1 领域现状:图像定制成熟,视频定制存在短板
扩散模型(Diffusion Models)的快速发展推动了定制化生成技术的进步。在图像领域,Textual Inversion、DreamBooth 等方法已能通过少量参考图精准学习主体特征,生成符合用户需求的个性化图像。但在视频领域,定制化生成仍面临两大核心挑战:
- 空间与时间的双重控制:视频需同时保证 "主体身份不变"(空间维度)和 "动作符合目标"(时间维度),现有方法难以兼顾二者。
- 现有方法的局限性:
- 单维度优化:如 Dreamix 仅聚焦主体身份注入,Tune-A-Video 仅优化动作模式,导致另一维度泛化能力下降;
- 缺乏动作多样性:如 AnimateDiff 虽能将图像生成为视频,但更侧重相机运动,无法满足特定动作定制需求;
- 融合冲突:直接组合主体与动作模型时,易出现主体失真或动作断裂的问题。
1.2 研究目标
DreamVideo 的核心目标是:通过少量主体参考图和动作参考视频,生成 "指定主体执行指定动作" 的高保真视频,同时支持主体与动作的灵活组合,无需为每个组合重新训练模型。

二、核心方法:分阶段学习与轻量级适配器设计
DreamVideo 的核心创新在于将视频定制任务解耦为 "主体学习" 和 "动作学习" 两个独立阶段,通过两个轻量级适配器(Identity Adapter、Motion Adapter)分别建模空间主体特征和时间动作模式,最终在推理阶段灵活组合。整体框架如图 2 所示。
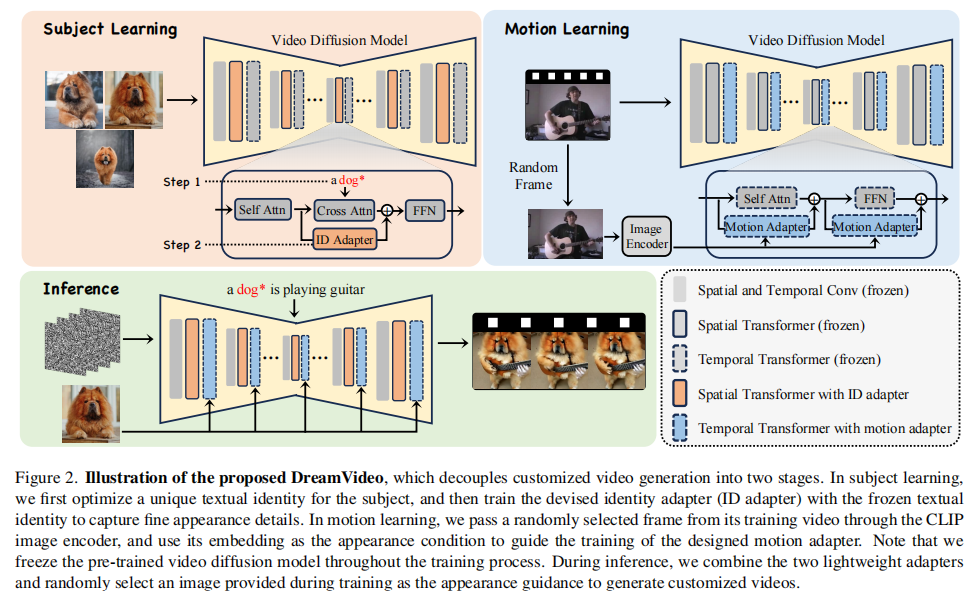
注:框架分为主体学习(左上图)和动作学习(右上图),推理时组合两个适配器生成定制视频(下图),预训练视频扩散模型全程冻结。
2.1 基础:视频扩散模型(VDM) preliminaries
DreamVideo 基于预训练的视频扩散模型(VDM)构建,其核心原理是通过 "逐步去噪" 学习视频数据分布。VDM 将视频表示为 latent 代码 (B = 批量大小、F = 帧数、H/W = 分辨率、C = 通道数),训练目标是最小化噪声预测损失:
,其中,
是含噪 latent 代码,
是 3D UNet 噪声预测网络(包含时空卷积、空间 Transformer、时间 Transformer 层),
是预训练文本编码器。
2.2 阶段 1:主体学习(Subject Learning)------ 精准捕捉主体外观
主体学习的目标是从 3~5 张参考图中学习主体的 "粗粒度概念" 和 "细粒度外观细节",采用两步策略:
2.2.1 步骤 1:文本身份学习(Textual Inversion)
通过优化一个伪词(如 )的文本嵌入,让模型用该嵌入表示主体的粗粒度概念。此阶段冻结预训练 VDM ,仅更新
的文本嵌入,使用 prompt"a
" 训练约 3000 轮(学习率
)。
- 作用:为主体建立一个可被模型理解的 "文本标签",避免直接微调模型导致的过拟合。
2.2.2 步骤 2:身份适配器训练(Identity Adapter)
仅靠文本嵌入无法捕捉主体的细节(如纹理、颜色),因此设计轻量级身份适配器,在冻结文本嵌入和 VDM 的前提下,进一步学习细粒度外观。
- 适配器结构(图 3 (a)):采用瓶颈(Bottleneck)架构,含下投影层(
,
- 初始化技巧:
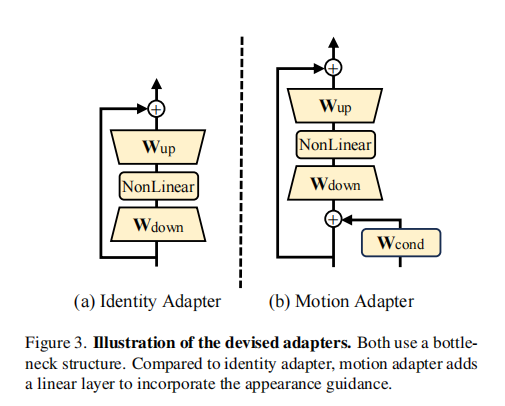
注:(a) 身份适配器(瓶颈架构 + 残差连接);(b) 动作适配器(在身份适配器基础上增加外观引导线性层)。
2.3 阶段 2:动作学习(Motion Learning)------ 纯动作建模,解耦外观
动作学习的目标是从 1~ 多段参考视频中学习动作模式,同时避免学习参考视频中的主体外观(防止与目标主体冲突),核心是动作适配器与外观引导机制。
2.3.1 动作适配器设计(Motion Adapter)
动作适配器结构与身份适配器类似(图 3 (b)),但新增 "外观引导层",强制模型仅关注动作:
- 外观引导获取 :从参考视频中随机选 1 帧,通过 CLIP 图像编码器生成图像嵌入
- 适配器前向过程 :
- 关键作用:外观引导为模型提供 "非动作" 的外观基准,使其专注于学习帧间动作变化,而非参考视频中的主体外观。
2.3.2 训练细节
动作适配器训练约 1000 轮(学习率),冻结 VDM 和 CLIP 编码器,仅更新适配器参数。支持从 "单段视频" 或 "多段同类动作视频" 中学习动作模式。
2.4 适配器位置选择:基于参数重要性分析
为确定适配器在 VDM 中的最佳插入位置,论文分析了微调时各层参数的变化率(),将参数分为 4 类:交叉注意力(仅空间层)、自注意力、前馈网络(FFN)、其他。
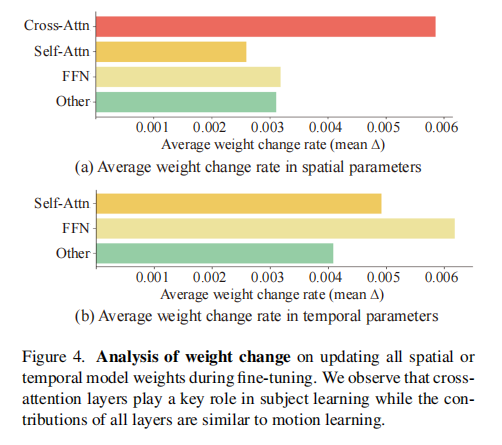
注:(a) 空间参数(主体学习):交叉注意力层变化率最高,是主体特征学习的关键;(b) 时间参数(动作学习):所有层变化率相近,需在全层插入适配器。
基于分析结果,适配器插入位置如下:
- 身份适配器:仅插入空间 Transformer 的交叉注意力层(主体学习依赖文本 - 图像交叉注意力);
- 动作适配器:插入时间 Transformer 的所有层(动作学习需全层建模帧间依赖)。
2.5 推理阶段:灵活组合,零额外训练
推理时无需重新训练,仅需:
- 组合训练好的身份适配器和动作适配器;
- 从主体参考图中随机选 1 张,通过 CLIP 生成外观引导,输入动作适配器;
- 使用 DDIM 采样(50 步)和无分类器引导(classifier-free guidance),生成 32 帧、8fps 的视频。
三、实验验证:定性与定量双重证明
论文构建了大规模实验数据集(20 个定制主体 + 30 种动作模式 + 42 个文本 prompt),从 "主体 - 动作联合定制""单独主体定制""单独动作定制" 三个维度,与主流方法进行对比。
3.1 实验设置
- 基线方法:
- 联合定制:AnimateDiff(图像扩散 + 动作模块)、ModelScopeT2V(全微调空间 / 时间参数)、LoRA(低秩适应组合);
- 单独主体定制:Textual Inversion、Dreamix、Custom Diffusion;
- 单独动作定制:ModelScopeT2V(仅微调时间参数)、Tune-A-Video;
- 评价指标:
- 主体相关:CLIP-T(生成帧与文本嵌入相似度)、CLIP-I(生成帧与参考图相似度)、DINO-I(自监督模型度量的主体相似度);
- 动作相关:时间一致性(T. Cons.,连续帧 CLIP 相似度均值);
- 效率:参数量(Para.)。
3.2 联合定制:主体与动作的和谐融合
3.2.1 定性结果分析

- AnimateDiff:主体外观保留较好,但动作多样性不足(如 "狗滑板" 动作僵硬);
- ModelScopeT2V/LoRA:存在 "融合冲突"------ 要么主体失真(如猫的形态扭曲),要么动作断裂;
- DreamVideo:精准保留主体身份(如狗的纹理、猫的轮廓),同时动作连贯(如滑板姿态自然),且支持多样场景(如 "卢浮宫前奔跑")。
3.2.2 定量结果分析
DreamVideo 在所有关键指标上均优于基线,且参数量仅 85M(远低于 ModelScopeT2V 的 1.31B):
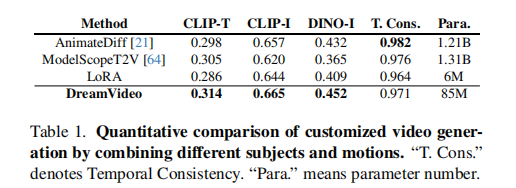
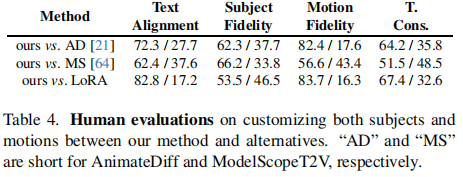
3.2.3 人类评估(表 4)
5 名标注者对 50 组视频(5 种动作 + 10 个主体)进行投票,DreamVideo 在 "文本对齐""主体保真度""动作保真度""时间一致性" 四项指标上均获最高偏好:
3.3 单独主体定制:细节保留与场景适配
3.3.1 定性结果分析

- Textual Inversion:主体细节丢失(如 "怪物跳舞" 中怪物形态模糊);
- Dreamix:主体细节较好,但易过拟合(动作幅度小),且无法生成 prompt 中的额外物体(如 "披萨");
- DreamVideo:主体细节精准(如 "狼奔跑" 的毛发纹理),动作自然,且能生成场景中的额外物体(如 "披萨")。
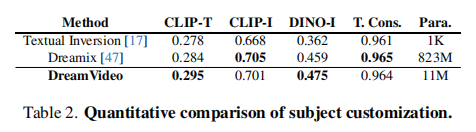
3.3.2 定量结果分析
DreamVideo 在 CLIP-T(文本对齐)和 DINO-I(主体相似度)上最优,参数量仅 11M(远低于 Dreamix 的 823M):
3.4 单独动作定制:纯动作建模,无外观污染
3.4.1 定性结果分析

- ModelScopeT2V:会学习参考视频中的主体外观(如 "人举重" 视频导致生成 "熊举重" 时带有人的特征);
- Tune-A-Video:动作不连贯(帧间跳变);
- DreamVideo:完全忽略参考视频的外观,仅学习动作模式(如 "熊举重" 姿态与 "人举重" 一致,但外观是纯熊),且帧间连贯。
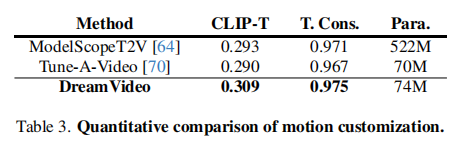
3.4.2 定量结果分析
DreamVideo 在 CLIP-T(动作与文本对齐)和 T. Cons.(时间一致性)上最优,参数量 74M(低于 ModelScopeT2V 的 522M):
3.5 消融实验:验证各组件必要性
论文对 "文本身份学习""动作适配器""外观引导" 三个核心组件进行消融,结果如下:
3.5.1 定性结果分析

- 无文本身份:主体细节丢失(如 "树懒举重" 的毛发纹理模糊);
- 无动作适配器:无法生成目标动作(如 "狼弹吉他" 仅为静态帧);
- 无外观引导:主体与背景失真(如 "狼弹吉他" 中狼的形态扭曲);
- DreamVideo(全组件):主体细节完整,动作连贯,背景合理。
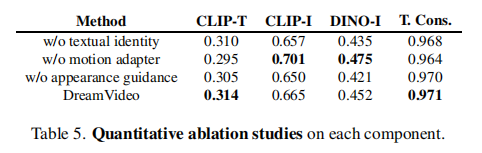
3.5.2 定量结果分析
所有组件移除后,指标均下降,证明各组件的必要性:
四、创新价值与局限性
4.1 核心创新
- 首次实现 "任意主体 + 任意动作" 定制:突破现有方法单维度优化的局限,通过解耦学习支持灵活组合;
- 轻量级高效设计:适配器参数量仅 85M,训练成本低(单 A100 GPU 上主体学习 12 分钟、动作学习 15~30 分钟);
- 外观 - 动作解耦:通过 CLIP 外观引导,避免动作学习时污染主体特征,解决融合冲突问题;
- 参数高效微调:预训练 VDM 全程冻结,仅更新适配器参数,兼顾性能与泛化。
4.2 局限性
- 多主体多动作支持不足:目前仅能生成 "单个主体执行单个动作" 的视频,无法处理 "多主体 + 多动作" 场景(如 "猫追狗");
- 依赖基础模型能力:若基础 VDM 无法生成某些场景(如 "狼骑自行车"),DreamVideo 会继承该局限;
- 精细动作建模不足:从单段视频学习时,难以实现 "帧级动作对齐",仅能学习粗粒度动作模式。
五、总结与展望
DreamVideo 通过 "分阶段学习 + 轻量级适配器" 的设计,为定制化视频生成提供了全新思路,其核心价值在于平衡了 "定制灵活性""生成质量" 与 "训练效率"。未来可从以下方向进一步优化:
- 设计多主体融合模块,支持复杂场景生成;
- 结合视频编辑技术,提升精细动作建模能力;
- 探索跨模态引导(如音频、骨骼动画),进一步增强动作可控性。
该论文的技术方案不仅推动了视频生成领域的发展,也为其他时空序列生成任务(如 3D 动画、自动驾驶场景模拟)提供了借鉴意义。