标题:SimDA: Simple Diffusion Adapter for Efficient Video Generation
作者:Zhen Xing, Qi Dai, Han Hu, Zuxuan Wu, Yu-Gang Jiang
单位:复旦大学、微软亚洲研究院
会议:CVPR 2023
论文链接:https://arxiv.org/abs/2308.09710
项目主页:https://chenhsing.github.io/SimDA/
代码链接 :https://github.com/ChenHsing/SimDA
关键词:文本驱动视频生成、参数高效微调、潜在扩散模型、时空适配器、Latent-Shift Attention、视频超分辨率、文本引导视频编辑、轻量级模型架构、单样本视频编辑、高效推理
一、引言:从图像生成到视频生成的跨越
近年来,人工智能生成内容(AIGC)浪潮席卷全球,其中文本到图像(Text-to-Image, T2I)技术取得了巨大成功。以Stable Diffusion、DALL·E 2为代表的扩散模型,凭借其强大的可控性、稳定性和逼真的生成效果,成为主流。
然而,文本到视频(Text-to-Video, T2V)生成技术的发展却相对滞后。主要原因如下:
- 数据稀缺:高质量、大规模的文本-视频配对数据集远少于图像数据集。
- 时序建模困难:视频不仅包含空间信息,还包含复杂的时序动态和运动一致性。
- 训练成本高昂:直接从头训练一个视频生成模型,或对大型T2I模型进行全参数微调,都需要巨大的计算资源和显存。
为了解决这些问题,现有工作主要分为两类:
- 从头训练:如CogVideo、Video Diffusion Models,但训练周期长、成本高。
- 模型适配:如Make-A-Video、Imagen Video,通过在T2I模型中引入时序模块来适配视频生成,但参数量巨大(如Imagen Video达16.3B),训练依然昂贵。
在此背景下,本文提出了 SimDA (Simple Diffusion Adapter) ,一种参数高效的扩散适配器,旨在用极小的可训练参数量,将强大的T2I模型(如Stable Diffusion)高效地迁移到视频生成任务中。

二、核心思想与贡献
SimDA的核心思想是:冻结原始T2I模型的绝大部分参数,仅引入少量轻量级的"适配器"模块进行微调。这种方法在NLP领域(如LoRA、Adapter)已被证明高效,但在视频生成领域尚属探索。
主要贡献
- 极简适配 :仅微调1.1B参数模型中的2400万(24M)参数(占比仅0.02%),即可实现高质量的视频生成。
- 轻量级时空适配器:
- 空间适配器(Spatial Adapter):用于迁移图像空间特征。
- 时序适配器(Temporal Adapter):用于建模视频时序动态。
- 提出Latent-Shift Attention (LSA) :替代原始的空间注意力,通过"潜在位移"机制增强时序一致性,且不增加额外参数。
- 多功能扩展 :同一框架可扩展至视频超分 (生成1024×1024高清视频)和文本引导视频编辑(One-shot Editing),训练效率显著提升。
- 高效性:训练显存需求低于8GB(16×256×256分辨率),推理速度比自回归方法(如CogVideo)快39倍。
三、方法详解
3.1 基础:Stable Diffusion回顾
SimDA基于潜在扩散模型(Latent Diffusion Model, LDM),即Stable Diffusion。其核心流程如下:
- 编码 :通过预训练的VAE编码器
将图像
- 前向扩散 :在
- 反向去噪 :训练一个U-Net网络
- 解码 :通过预训练的VAE解码器
训练目标为:
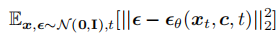
其中 是文本条件的嵌入。
3.2 SimDA整体架构
SimDA的架构如图2所示。
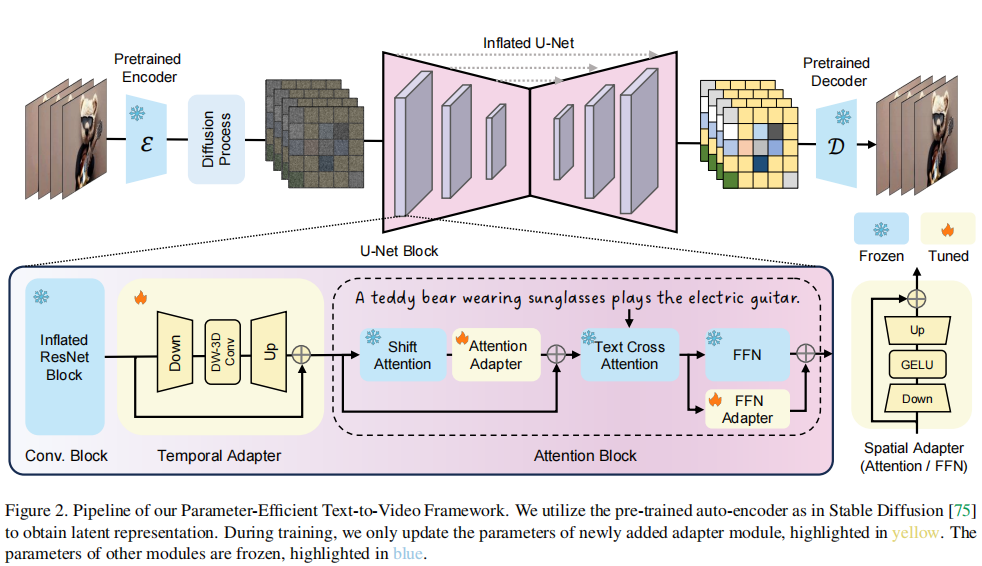
- 输入处理:对于包含 tt 帧的视频 {Ii}i=1t{Ii}i=1t,使用预训练的编码器 EE 得到潜在特征 {xi}i=1t{xi}i=1t。
- 前向扩散:对视频潜在特征逐步加噪。
- 反向去噪 :使用膨胀的U-Net(Inflated U-Net)进行去噪预测。
- 卷积块:将2D ResNet块膨胀为3D块以处理视频输入。
- 注意力块 :引入Latent-Shift Attention (LSA) 和 空间适配器。
- 时序建模 :通过时序适配器捕捉帧间关系。
- 推理阶段:使用DDIM采样从高斯噪声中生成视频潜在码,再通过解码器 DD 重建视频。
关键点 :训练时,仅更新新添加的适配器模块 (黄色部分),原始T2I模型的参数完全冻结(蓝色部分),极大降低了训练成本。
3.3 核心组件:适配器与注意力
3.3.1 空间适配器(Spatial Adapter)
受NLP和CV领域高效微调技术的启发,SimDA在U-Net的注意力块和前馈网络(FFN)后添加了瓶颈结构的适配器。
-
结构:两个全连接层(FC) + GELU激活,形成"下采样-上采样"瓶颈。
-
公式:
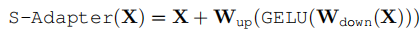
其中 -
初始化 :
-
位置:添加在LSA层之后,帮助网络迁移图像空间信息到视频任务。
3.3.2 时序适配器(Temporal Adapter)
为建模时序信息,SimDA设计了轻量级的时序适配器。
-
结构 :与空间适配器类似,但中间层使用深度可分离3D卷积(depth-wise 3D Conv)而非FC层。
-
公式:
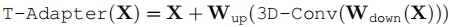
-
优势:在低维特征上进行3D卷积,显著降低了计算复杂度和显存占用,实现了高效的时序建模。
3.3.3 Latent-Shift Attention (LSA)
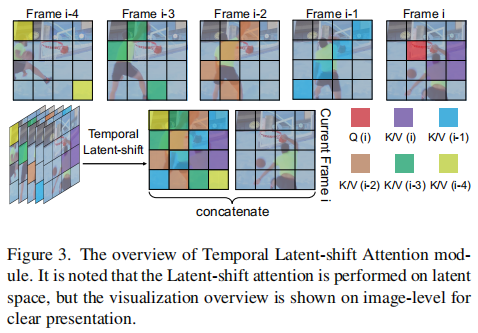
这是SimDA的核心创新之一,旨在解决时序一致性问题,且不增加参数,LSA模块示意图如下。
-
问题:原始T2I的注意力仅在单帧内进行,忽略了帧间关系。
-
方案 :LSA在潜在空间进行块级位移(patch-level shifting)。
- 将前
- 将当前帧的潜在特征
- 使用拼接后的特征作为Key和Value,当前帧特征作为Query进行注意力计算。
- 将前
-
公式:
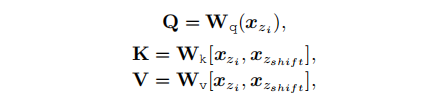
-
优势:
- 复杂度低 :从全局时空注意力的
- 一致性好:强制模型学习相邻帧间的关系,提升生成视频的流畅性。
- 复杂度低 :从全局时空注意力的
3.4 扩展应用:超分与编辑
3.4.1 视频超分辨率(Super Resolution)
由于显存限制,大多数方法(包括SimDA第一阶段)只能生成256×256的视频。为此,SimDA采用两阶段级联训练:
- 第一阶段:使用SimDA生成256×256视频。
- 第二阶段 :训练一个4倍超分模型,将256×256视频提升至1024×1024。
-
输入 :低分辨率视频
-
架构:与第一阶段T2V模型类似,但加入空间和时序适配器,并仅微调这些新模块。
-
训练目标:
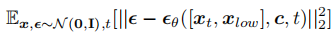
-
3.4.2 文本引导视频编辑(Text-guided Video Editing)
SimDA可轻松扩展至单样本视频编辑(One-shot Editing),灵感来自Tune-A-Video。
- 训练:与T2V相同,使用一个视频-文本对进行微调。
- 推理 :采用DDIM反演(DDIM inversion):
- 将输入视频通过编码器和前向扩散过程,得到其"反演潜在码"。
- 以此反演码为起点,结合修改后的文本提示 ,进行反向去噪生成。
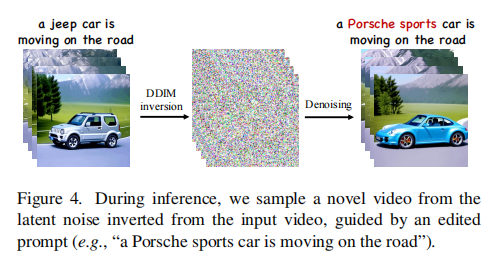
- 优势 :由于适配器轻量,SimDA仅需200步 微调(Tune-A-Video需500步),训练和推理速度快3倍。
四、实验与结果
4.1 实验设置
- 数据集:WebVid-10M(训练),MSR-VTT(评估)。
- 评估指标:
- FVD (Frechet Video Distance):越低越好,衡量生成视频与真实视频的分布距离。
- CLIPSIM:越高越好,衡量视频与文本提示的语义一致性。
- 对比方法:CogVideo, Make-A-Video, Video LDM, Latent-Shift等。
4.2 文本到视频生成性能
下表展示了在MSR-VTT数据集上的文本到视频生成性能对比评估结果。
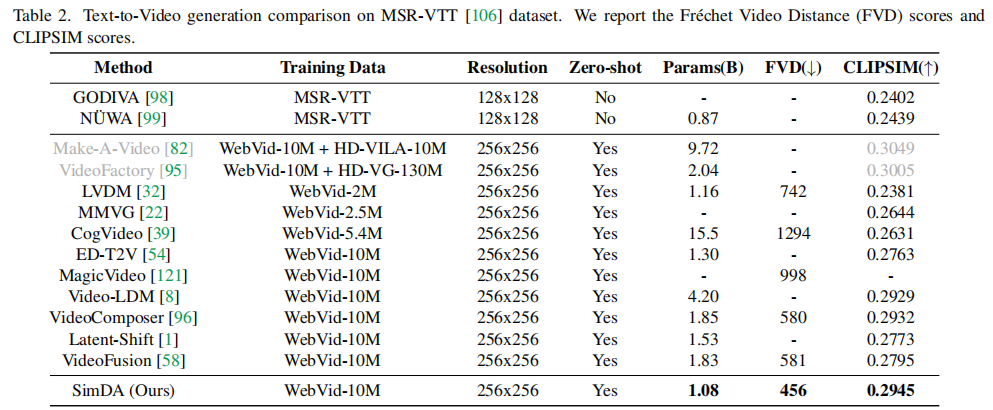
- SimDA (Ours) 在FVD(456)和CLIPSIM(0.2945)上均优于或媲美现有方法。
- 参数量:总参数1.08B,可调参数仅0.025B(24M),远小于CogVideo(15.5B)和Make-A-Video(9.72B)。
4.3 效率对比
下表展示了模型规模与推理速度的对比。
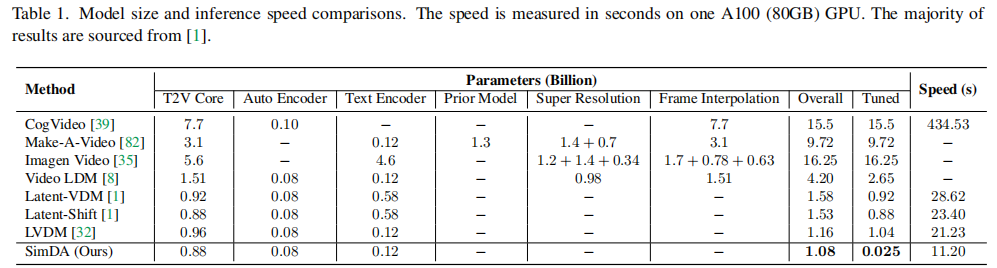
- 推理速度 :SimDA仅需11.20秒 ,而CogVideo需434.53秒,快39倍。
- 显存需求:训练显存<8GB,远低于其他方法。
4.4 生成效果对比
下图展示了与其他方法的生成效果对比。

SimDA生成的视频在视觉质量和时序连贯性上表现优异。
五、总结与展望
5.1 总结
SimDA提出了一种简单而高效的视频生成框架,其核心在于:
- 参数高效:仅微调0.02%的参数,即可实现高质量视频生成。
- 架构创新 :通过轻量级的空间/时序适配器 和无参数的Latent-Shift Attention,有效解决了时空建模问题。
- 多功能性:可无缝扩展至视频超分和视频编辑任务,且训练效率极高。
- 实用性强:低显存、高速度,更易于部署和应用。
5.2 局限与未来方向
- 分辨率限制:第一阶段生成分辨率较低,依赖两阶段超分。
- 长视频生成:当前方法可能难以生成超长、高动态的复杂视频。
- 可控性:相比一些专用编辑方法,精确控制能力有待提升。
未来工作可探索更高效的超分方案、更长的时序建模,以及与物理引擎的结合,以生成更真实、可控的视频内容。
六、结语
SimDA的成功表明,并非需要庞大的参数量才能实现高质量的视频生成。通过巧妙的架构设计和参数高效的微调策略,我们可以在极低的训练成本下,释放大型图像生成模型的巨大潜力。这为AIGC从"图像"迈向"视频"的普及化、平民化提供了重要的技术路径。