标题:MotionEditor: Editing Video Motion via Content-Aware Diffusion
作者:Shuyuan Tu、Qi Dai、Zhi-Qi Cheng、Han Hu、Xintong Han、Zuxuan Wu、Yu-Gang Jiang
单位:复旦大学计算机学院上海市智能信息处理重点实验室;上海智能视觉计算协同创新中心;微软亚洲研究院;卡内基梅隆大学;Huya Inc.
发表:CVPR 2024
论文链接 :https://arxiv.org/abs/2311.18830v1 / https://arxiv.org/pdf/2311.18830
项目主页 :https://francis-rings.github.io/MotionEditor/
代码链接 :https://github.com/Francis-Rings/MotionEditor
关键词:视频运动编辑、扩散模型、内容感知、ControlNet、注意力注入、骨骼对齐、 latent diffusion model(LDM)、时空一致性
在视频编辑领域,传统扩散模型多聚焦于纹理、风格等低层次属性调整,却难以在保留主体外观与背景的同时实现高精度运动操控。来自复旦大学、微软亚洲研究院等机构的研究团队提出的MotionEditor,创新性地将内容感知机制与扩散模型结合,首次实现了 "参考视频运动迁移 + 源视频外观保留" 的高阶视频编辑能力。
一、研究背景与问题定义
1.1 视频编辑的技术瓶颈
扩散模型在图像生成与编辑领域已取得突破性进展,但在视频领域仍面临核心挑战:
- 运动编辑缺失:现有方法(如 Tune-A-Video、ControlVideo)多针对纹理、背景等静态属性,忽略了视频最核心的 "运动信息";
- 外观与运动的矛盾:传统 ControlNet 虽支持姿态引导生成,但参考姿态与源视频噪声存在信号冲突,易导致重影、模糊或主体外观失真;
- 时空一致性差:GAN-based 运动迁移方法(如 LWG、MRAA)无法处理动态背景与相机运动,且对初始姿态敏感,复杂场景下效果骤降。
1.2 任务定义:视频运动编辑
MotionEditor 的核心目标是 **运动迁移 + 外观保留**:
- 输入:源视频(需保留外观)、参考视频(提供运动)、文本提示(辅助语义约束);
- 输出:主体运动与参考视频一致,且保留源视频主体外观、动态背景及相机运动的新视频。

该任务与现有相关任务的区别如下表所示,更强调 "视频到视频" 的运动迁移与多信息保留:
| 任务类型 | 输入 | 输出 | 核心局限 |
|---|---|---|---|
| 姿态引导图像生成(ControlNet) | 文本 + 单姿态 | 单图像 | 无视频时序建模 |
| 人体运动迁移(LWG/MRAA) | 单图像 + 姿态序列 | 视频 | 静态背景,无相机运动 |
| 姿态引导视频生成(Follow-Your-Pose) | 文本 + 姿态序列 | 视频 | 不保留源视频外观 |
| 视频属性编辑(Tune-A-Video) | 视频 + 文本 | 视频 | 无法编辑运动信息 |
| 视频运动编辑(MotionEditor) | 源视频 + 参考视频 + 文本 | 视频 | 兼顾运动迁移与外观保留 |
二、核心方法:MotionEditor 的技术架构
MotionEditor 基于 latent diffusion model(LDM,即 Stable Diffusion)与 ControlNet 扩展,核心创新包括 "内容感知运动适配器""高保真注意力注入""骨骼对齐算法" 三大模块,整体架构如图 2 所示。
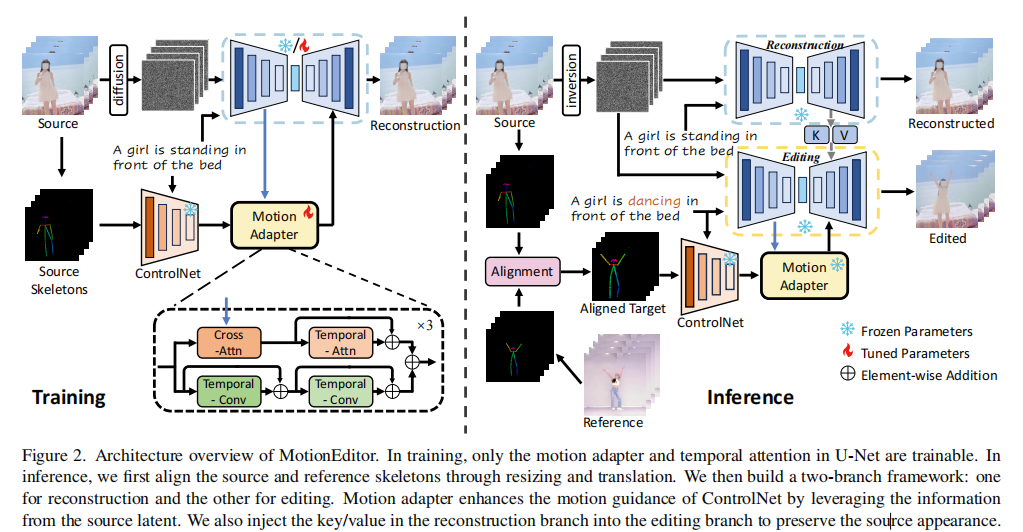
2.1 整体流程概览
MotionEditor 分为训练阶段 与推理阶段,流程如下:
- 训练阶段:冻结 LDM 与 ControlNet 主干参数,仅训练 "运动适配器" 与 "时序注意力模块",通过 "单样本学习(one-shot learning)" 让模型学习源视频的外观特征;
- 推理阶段:
- 骨骼对齐:统一源视频与参考视频的骨骼大小与位置;
- 双分支架构:重建分支(保留源外观)与编辑分支(迁移参考运动)并行;
- 注意力注入:将重建分支的关键特征注入编辑分支,保证外观保留。
2.2 核心创新模块 1:内容感知运动适配器
解决传统 ControlNet "姿态与噪声冲突" 问题的核心模块,通过源视频内容引导姿态信号调整,实现运动与外观的无缝融合。
模块设计
适配器分为两条并行路径,分别处理不同粒度的特征:
-
全局建模路径:
- 内容感知交叉注意力:以 ControlNet 输出的姿态特征为 Query,LDM 的源视频 latent 特征为 Key/Value,建立姿态与源内容的关联,公式如下:
)(
- 时序注意力:捕捉帧间运动一致性,避免时序抖动。
- 内容感知交叉注意力:以 ControlNet 输出的姿态特征为 Query,LDM 的源视频 latent 特征为 Key/Value,建立姿态与源内容的关联,公式如下:
-
局部建模路径:通过两个时序卷积块,捕捉局部运动细节(如肢体关节运动)。
核心作用
- 消除 "参考姿态" 与 "源视频噪声" 的信号矛盾,避免重影与模糊;
- 让姿态引导更贴合源视频内容,确保运动迁移后主体外观不失真。
2.3 核心创新模块 2:高保真注意力注入
解决 "运动迁移导致背景 / 主体外观丢失" 的问题,通过前景与背景特征解耦,实现精准的特征传递,框架如下图。
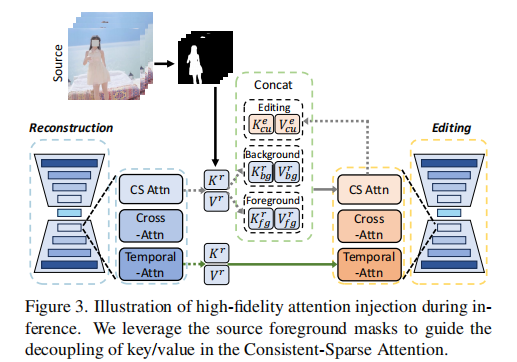
关键技术:Consistent-Sparse Attention(CS 注意力)
替换传统 U-Net 的空间注意力,以前一帧 + 当前帧 的特征作为 Key/Value(而非 Sparse Attention 的 "首帧 + 前一帧"),避免运动偏向首帧导致的闪烁,公式如下:(
为重建分支当前帧特征,
为前一帧特征)
注意力注入流程:
- 特征解耦 :利用现成分割模型获取源视频前景掩码M,将重建分支的 Key/Value 拆分为前景与背景:
- 特征融合 :将解耦后的前景 / 背景特征与编辑分支的当前帧特征拼接,作为编辑分支的新 Key/Value:
核心作用:
- 明确区分前景(主体)与背景特征,避免编辑分支混淆两者导致的外观失真;
- 仅在推理阶段激活,无需额外训练,兼顾效果与效率。
2.4 核心创新模块 3:骨骼对齐算法
解决 "源视频与参考视频骨骼大小 / 位置不一致" 导致的运动迁移错位问题,分为缩放 与平移两步:
-
缩放操作:
- 对源视频与参考视频的前景掩码进行边缘检测,获取主体 bounding box;
- 根据源视频 bounding box 的宽高比,缩放参考骨骼至与源视频主体大小一致。
-
平移操作:
- 计算源视频与参考视频前景像素的中心坐标;
- 生成平移矩阵,将缩放后的参考骨骼移动至源视频主体位置,最终得到对齐后的目标骨骼
算法细节可参考如下伪代码,其核心优势是无需复杂姿态估计后处理,仅通过掩码与几何变换即可实现高精度对齐。

2.5 扩散过程与采样策略
- 潜在空间扩散:基于 LDM 框架,将视频帧压缩至 latent 空间进行扩散,降低计算成本;
- 推理采样:采用 DDIM 逆扩散生成初始噪声,并结合 "空文本优化(null-text optimization)" 与 "无分类器引导(classifier-free guidance)",平衡运动准确性与外观保真度;
- 时间成本:单 NVIDIA A100 GPU 上,每段视频编辑约需 10 分钟(主要来自 DDIM 逆扩散与注意力计算)。
三、实验验证:定量与定性分析
3.1 实验设置
- 数据集:YouTube 真实场景视频 + TaichiHD 数据集(每段视频≥70 帧,分辨率统一为 512×512);
- 对比方法:涵盖 GAN-based 运动迁移(LWG、MRAA)、视频扩散编辑(Tune-A-Video、ControlVideo)、姿态引导生成(Follow-Your-Pose)等 6 类 SOTA 方法;
- 评价指标:
- 定量:CLIP 得分(文本一致性)、LPIPS-S(与源视频外观相似度)、LPIPS-N(帧间一致性)、LPIPS-T(与参考视频运动相似度);
- 定性:用户研究(运动对齐、外观对齐、文本对齐三维度偏好)。
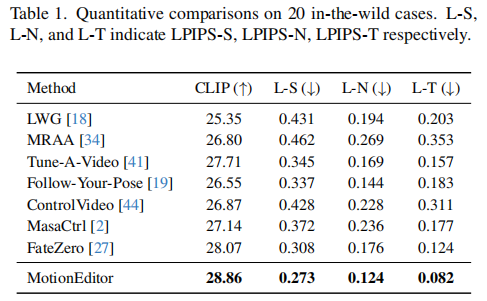
3.2 定量结果:全面领先 SOTA
表 1 展示了 20 个真实场景案例的定量对比,MotionEditor 在所有指标上均显著优于对比方法:
- CLIP 得分最高(28.86):说明生成视频与文本提示的语义一致性最强;
- LPIPS-S 最低(0.273):证明对源视频外观的保留效果最好;
- LPIPS-N(0.124)与 LPIPS-T(0.082)最低:体现最优的帧间时序一致性与运动迁移准确性。
3.3 定性结果:视觉效果更优
图 5 展示了关键案例的定性对比,MotionEditor 的优势主要体现在:
- 无重影模糊:Tune-A-Video、ControlVideo 等方法存在主体头部 / 腿部重叠,而 MotionEditor 运动清晰;
- 外观无失真:Follow-Your-Pose、MasaCtrl 等方法导致发型、衣物纹理变化,MotionEditor 完全保留源视频外观;
- 背景一致性:所有对比方法均存在背景细节丢失(如墙面纹理、地面图案),MotionEditor 通过注意力注入完美保留背景。

注:源提示 "穿黑裙的女孩跳舞",目标提示 "穿黑裙的女孩练太极",MotionEditor 在运动与外观上均实现最优匹配。
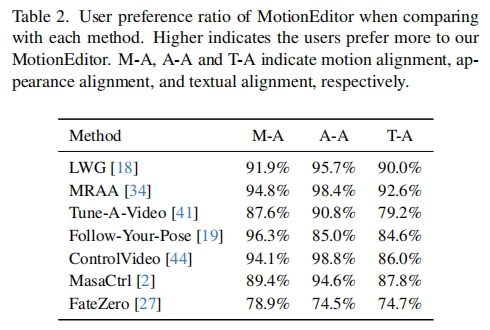
3.4 用户研究:主观偏好显著
表 2 展示了 20 个案例的用户研究结果(参与者为大学生,共 30 人),MotionEditor 在三个维度的偏好率均远超对比方法:
- 运动对齐(M-A):偏好率最高达 96.3%(vs Follow-Your-Pose);
- 外观对齐(A-A):偏好率最高达 98.8%(vs ControlVideo);
- 文本对齐(T-A):偏好率最高达 92.6%(vs MRAA)。
3.5 消融实验:核心模块必要性验证
图 6 通过消融实验验证了各核心模块的作用,关键结论如下:
- 无 CS 注意力(c):运动偏向首帧,导致主体姿态闪烁;
- 无运动适配器(e):ControlNet 无法处理姿态与噪声冲突,运动完全失效;
- 无注意力注入(f):背景细节丢失(如女孩身后的路标消失);
- 无骨骼对齐(g):骨骼错位导致主体外观变形(如肢体比例异常)。

注:源提示 "女孩跳舞",目标提示 "女孩练太极",仅完整 MotionEditor(h)实现运动与外观的双重保真。
四、局限性与未来方向
4.1 现有局限
- 小目标运动失真:当主体部位(如手部)与背景颜色相近时,前景 / 背景解耦不彻底,导致手部姿态模糊(如图 7);
- 长视频效率低:当前推理需 10 分钟 / 段视频,长视频(如≥100 帧)的时间成本过高;
- 复杂运动适配差:对于快速旋转、多主体交互等极端运动,时序一致性仍需提升。

注:女孩手部与背景混淆,导致手部姿态失真。
4.2 未来研究方向
- 更精细的特征解耦:在扩散前对前景 / 背景进行独立编码,避免特征混淆;
- 高效采样策略:探索更快速的逆扩散方法(如 Progressive Distillation),降低长视频编辑成本;
- 多模态引导:结合光流、深度信息,提升复杂运动的建模能力;
- 端到端训练:当前仅训练适配器与注意力模块,未来可探索全模型端到端训练,进一步提升效果。
五、总结
MotionEditor 的核心贡献在于首次将 "内容感知" 引入视频运动编辑,通过三大创新模块突破传统方法的瓶颈:
- 内容感知运动适配器:解决姿态与噪声的信号冲突,实现运动精准引导;
- 高保真注意力注入:通过前景 / 背景解耦,完美保留源视频外观与背景;
- 骨骼对齐算法:消除骨骼错位,保证运动迁移的空间一致性。
该工作不仅为视频运动编辑提供了全新范式,也为扩散模型在 "高阶视频编辑" 领域的应用开辟了新方向,未来有望在影视后期、游戏动画、虚拟人等领域实现落地。