标题:AVID: Any-Length Video Inpainting with Diffusion Model
作者:Zhixing Zhang, Bichen Wu, Xiaoyan Wang, Yaqiao Luo, Luxin Zhang等
单位:作者团队来自罗格斯大学、Meta GenAI (含金量拉满)
发表:CVPR 2024
论文链接 :https://arxiv.org/pdf/2312.03816
项目主页 :https://zhang-zx.github.io/AVID/
代码链接 :https://github.com/zhang-zx/AVID(代码不全)
关键词:视频修复、扩散模型、时序一致性、任意时长、结构引导、时序多扩散
想象这样一个场景:你拍摄了一段"汽车行驶在公路"的视频,想把普通汽车换成MINI Cooper,只需在第一帧框选汽车、输入文本提示,就能生成一段时空连贯的新视频,且未框选区域丝毫不改------这不是科幻电影里的特效,而是CVPR 2024 论文《AVID: Any-Length Video Inpainting with Diffusion Model》实现的核心能力。今天这篇精读,我们就拆解这款"视频编辑神器"的技术内核,看看它如何解决任意时长视频修复的三大核心痛点。
一、引言:视频修复的"三座大山"与AVID的破局之道
在扩散模型席卷图像生成领域后,文本引导的图像修复已相当成熟------但视频修复却一直是"老大难"。为什么?因为视频相比图像多了"时间维度",这直接催生了三大核心挑战,也是AVID要解决的核心问题:
-
时序一致性:修复后的内容必须"前后统一"。比如把汽车改成绿色,全程都得是同一种绿色,不能从荧光绿渐变到墨绿;
-
任务适配性:不同修复任务对"结构保真度"要求天差地别。比如"物体替换"要保留原物体的运动轨迹,而"视频扩边"则完全没有原结构可参考;
-
长度通用性:输入视频时长不固定,模型得能稳健处理从几秒到几十秒的任意视频。
做过视频编辑的同学肯定懂:传统工具要么时序混乱(修完的物体突然变样),要么只能处理固定时长(长视频得截断分段修),要么任务单一(换物体和扩边得用两个工具)。而AVID的牛之处,就在于用一套框架解决了这三大痛点。
先看论文给出的核心效果(图1),感受下AVID的能力边界:从5.3秒的物体替换、2.7秒的纹理修改,到8.0秒的视频扩边,都能实现高质量修复,且修复区域与原视频无缝融合。

图1 AVID核心效果展示,第一行是原始视频及修复区域标注,中间是文本提示和视频时长,最下方是AVID的修复结果。可以看到无论是MINI Cooper的替换、枫叶的颜色修改,还是山间桥梁上火车的扩边,结果都兼具视觉真实感和时序连贯性。
二、相关工作:从图像到视频,修复技术的演进与瓶颈
要理解AVID的创新,得先理清视频修复技术的发展脉络。论文将相关工作分为三类,每一类都暴露了此前的技术瓶颈:
2.1 图像修复:扩散模型的天下,但无法延伸到视频
扩散模型已成为图像修复的主流:比如Latent Blended Diffusion通过融合生成图和原图的 latent 空间实现修复,SmartBrush则在物体中心数据集上微调掩码预测分支。但这些方法只考虑单帧空间信息,直接套用到视频上会出现"帧间跳跃",完全没有时序一致性。
2.2 视频生成:时序能力有了,但缺乏精准修复的可控性
Text-to-Video模型(如CogVideo、Make-a-Video)能生成连贯视频,但它们是"从头生成",而非"定向修复"。比如要替换视频中的汽车,这些模型可能会连背景一起改掉,无法精准定位掩码区域。
2.3 现有视频修复:要么灵活度低,要么效果差
少数尝试视频修复的方法也有明显缺陷:比如VideoComposer虽然支持掩码输入,但要求所有帧的掩码区域完全一致,灵活度极低;而基于DDIM反转的方法依赖文本提示而非掩码,很容易修改到非目标区域。
基于此,AVID的核心创新为:把图像修复的"精准可控"和视频生成的"时序连贯"结合起来,还解决了任意时长的问题,具体怎么做的?咱们往下拆。
三、核心方法:AVID的"三板斧"破解三大痛点
AVID的整体框架基于文本引导的图像扩散修复模型(Latent Diffusion Model),但通过三大核心模块的改造,实现了从"图像"到"任意时长视频"的跨越。先看整体框架(图2):底层是图像扩散模型,中间叠加运动模块和结构引导模块,顶层是时序多扩散采样管道------三者分别对应解决时序一致性、任务适配性、长度通用性问题。
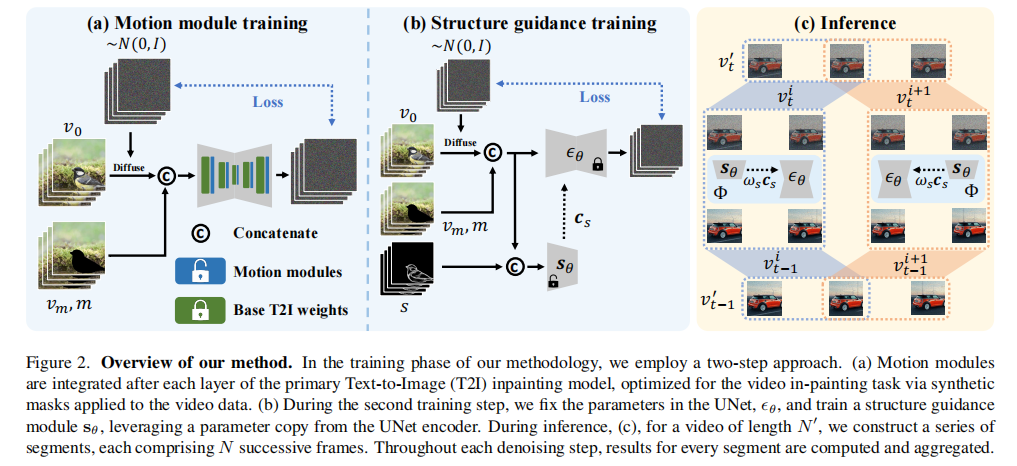
3.1 第一板斧:运动模块------让修复内容"动起来"且"不跑偏"
要解决时序一致性,关键是让模型学到帧间运动信息。AVID借鉴了AnimateDiff的思路,对基础图像扩散模型做了两个关键改造:
-
2D层转伪3D层:将原模型的2D卷积和注意力层,扩展为"空间-时间"伪3D层。比如空间卷积保持不变,时间维度上通过滑动窗口捕捉相邻帧的关联;
-
新增运动模块:在UNet的编码器和解码器之间,插入基于像素级时序自注意力的运动模块。这个模块专门学习帧间的运动轨迹,比如汽车行驶时的位置变化、树叶飘动的姿态变化。
更聪明的是,AVID只微调运动模块的参数,冻结预训练图像模型的权重------这样既能保留图像修复的高精度,又能快速学到时序信息,避免从头训练的巨大成本。
训练目标也相应调整为视频层面的噪声预测: 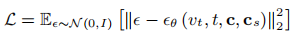 , 其中
, 其中是视频帧的噪声版本,
包含掩码视频、掩码序列和文本嵌入,确保模型在修复时同时参考空间掩码和时序运动。
3.2 第二板斧:结构引导模块------按需调整"结构保真度"
不同修复任务对"是否保留原结构"要求不同,比如:
-
纹理修改(如"把红枫叶改成黄枫叶"):需要严格保留原树叶的形状和运动轨迹;
-
物体替换(如"把普通汽车改成MINI Cooper"):需要保留原汽车的运动路径,但形状可以变;
-
视频扩边(如"给火车视频加上下边框"):完全不需要原结构,自由生成即可。
AVID的解决方案是可调节的结构引导模块,借鉴ControlNet的设计思路:
-
结构信息提取 :用HED(整体嵌套边缘检测)提取每帧的边缘结构,作为结构条件
;
-
结构引导注入:在UNet的跳跃连接和中间块输出中,插入结构引导模块的特征图(13个特征图,4种分辨率);
-
保真度调节 :通过缩放因子\(\omega_s\)控制结构引导的强度------纹理修改设
效果对比看图7:纹理修改时开结构引导,金色熊猫完全保留原熊猫的运动姿态;物体替换时关引导,浣熊不会被原熊猫的形状束缚,更符合文本提示。

这里有个工程落地的关键:结构引导的强度不是固定的,要根据任务类型动态调整。
3.3 第三板斧:时序多扩散+中间帧注意力------打破时长限制
AVID的基础模型是用16帧视频训练的,直接处理32帧、48帧的长视频会出现质量下降;而简单的"分段修复"又会导致段间断裂(比如前16帧的MINI Cooper是红色,后16帧突然变蓝色)。AVID用两个创新点解决这个问题:
3.3.1 时序多扩散(Temporal MultiDiffusion):分段生成+无缝衔接
把长视频按固定窗口(比如16帧)分成多个重叠片段,然后用多扩散策略生成:
-
重叠采样:片段之间设置重叠区域(比如重叠8帧),避免段间跳跃;
-
并行生成:每个片段独立生成,支持多GPU并行,提升效率。
3.3.2 中间帧注意力引导:保证全视频身份一致
分段生成还不够,比如生成"MINI Cooper行驶"的长视频,可能前半段车头朝左,后半段朝右。AVID的解决方案是中间帧注意力引导:
-
选中间帧当"锚点":因为中间帧到所有帧的距离最短,用它当参考能最大化全局一致性;
-
注意力融合:每个帧的自注意力计算,同时参考自身和中间帧的特征:
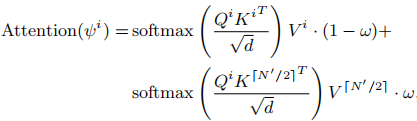
其中
效果看图8和图9:没有时序多扩散时,两段视频的鹅脖子纹理和浣熊位置突然变化;没有中间帧引导时,MINI Cooper从红色渐变到深红色;而开启两者后,全视频内容连贯、身份一致。


四、实验:全方位验证AVID的优越性
论文做了大量实验,从定性、定量、消融三个维度验证效果,我们挑核心结果解读:
4.1 对比实验:碾压主流方法
对比对象包括:Per-Frame(单帧图像修复叠加)、Text2Video-Zero(零样本视频生成)、VideoComposer(专用视频编辑模型)。评价指标有三个:
-
背景保留(BP):越低越好(L1距离,越小说明非掩码区域改动越小);
-
文本-视频对齐(TA):越高越好(CLIP分数,说明修复结果符合文本提示);
-
时序一致性(TC):越高越好(帧间CLIP特征余弦相似度)。
定量结果看表1:
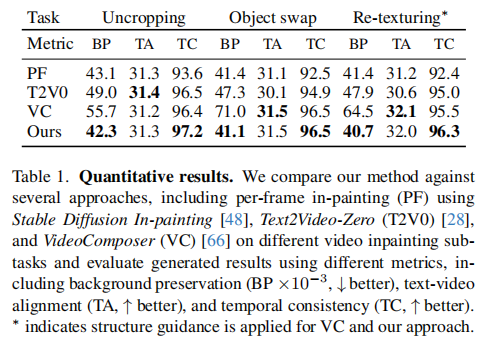
-
背景保留(BP):AVID在物体替换和纹理修改任务中均为最低(41.1、40.7),说明精准定位掩码区域,不改动背景;
-
时序一致性(TC):AVID在所有任务中均达到96%以上,远超Per-Frame(92%左右);
-
文本对齐(TA):与其他方法持平,说明时序一致性提升不牺牲文本匹配度。
定性结果看图5:Per-Frame的紫色汽车形状忽大忽小,Text2Video-Zero的火烈鸟位置跳跃,VideoComposer的背景出现色偏,而AVID的修复结果既符合文本,又连贯自然。

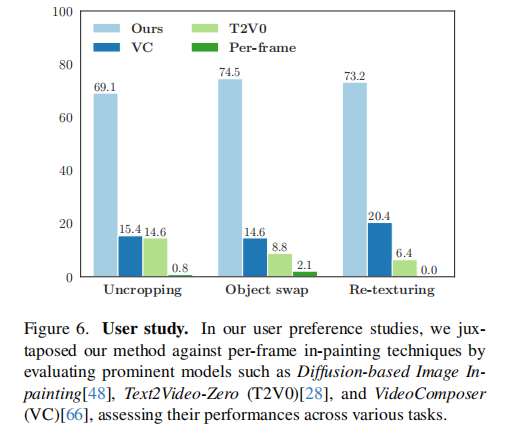
4.2 用户研究:人类偏好度碾压
论文找了多名标注者,对不同方法的结果打分。从图6可以看到:AVID在三个任务中均获得最高偏好率------扩边69.1%、物体替换74.5%、纹理修改73.2%,远超第二名VideoComposer。
4.3 消融实验:核心模块缺一不可
论文通过消融实验验证了三大模块的必要性:
-
去掉运动模块:TC分数下降15%+,帧间出现明显跳跃;
-
去掉结构引导:纹理修改任务的TA分数下降8%,因为无法保留原物体形状;
-
去掉时序多扩散/中间帧引导:长视频段间断裂、身份不一致问题突出。
这些实验告诉我们:做视频修复类模型,时序一致性、任务适配性、长度通用性三者缺一不可。AVID的模块设计逻辑,完全可以复用到其他视频编辑任务(比如视频超分、风格迁移),关注我,持续跟进新的应用!
五、局限与未来方向:理性看待技术边界
论文很坦诚地指出了AVID的局限性,这也是我们后续优化的方向:
-
复杂动作处理能力弱:比如文本提示"马转头从左到右",AVID会出现马头消失再重现的问题,原因是运动模块无法建模复杂姿态变化;
-
掩码精度敏感:如果掩码没有完全覆盖目标物体,未覆盖部分无法修复(因为模型会保留非掩码区域);
-
长视频跨段一致性待提升:物体进出画面时,容易出现身份断裂。
未来方向也很明确:更强的运动模块、可学习的结构引导参数、更精细的跨段注意力机制。
六、总结:AVID的核心价值与落地启示
AVID不是简单的"图像修复+视频生成"拼接,而是通过三大核心创新,定义了"任意时长文本引导视频修复"的新范式:
-
运动模块:冻结预训练图像模型,仅微调时序模块,兼顾精度与效率;
-
可调节结构引导:用单一模块适配不同任务,提升泛化性;
-
时序多扩散+中间帧引导:零样本解决长视频问题,突破训练时长限制。
对于工程落地来说,AVID的轻量化思路(不用从头训练大模型)非常友好。你觉得AVID还能应用在哪些场景?比如电影修复、短视频编辑、游戏素材生成?欢迎在评论区留言讨论!