1. 为什么是 Flink CDC(而不是手写一堆作业)
传统方案常见三类痛点:
- 开发心智重:手写 Flink SQL/Connector、复制几十份 Job,DDL/路由/命名不统一。
- 多表/整库难落地:上百张表初始化、断点续传、后续 DDL 对齐易出错。
- 一致性难保证:Source、State、Sink 三端需要协同的事务与幂等策略。
Flink CDC 把上述复杂度收敛为一份 YAML 配置:声明 Source/Sink、并行度、表集合、Transform/Route、Schema 演进策略;脚本提交后自动生成定制算子与 Flink 作业,端到端可观测、可回滚。
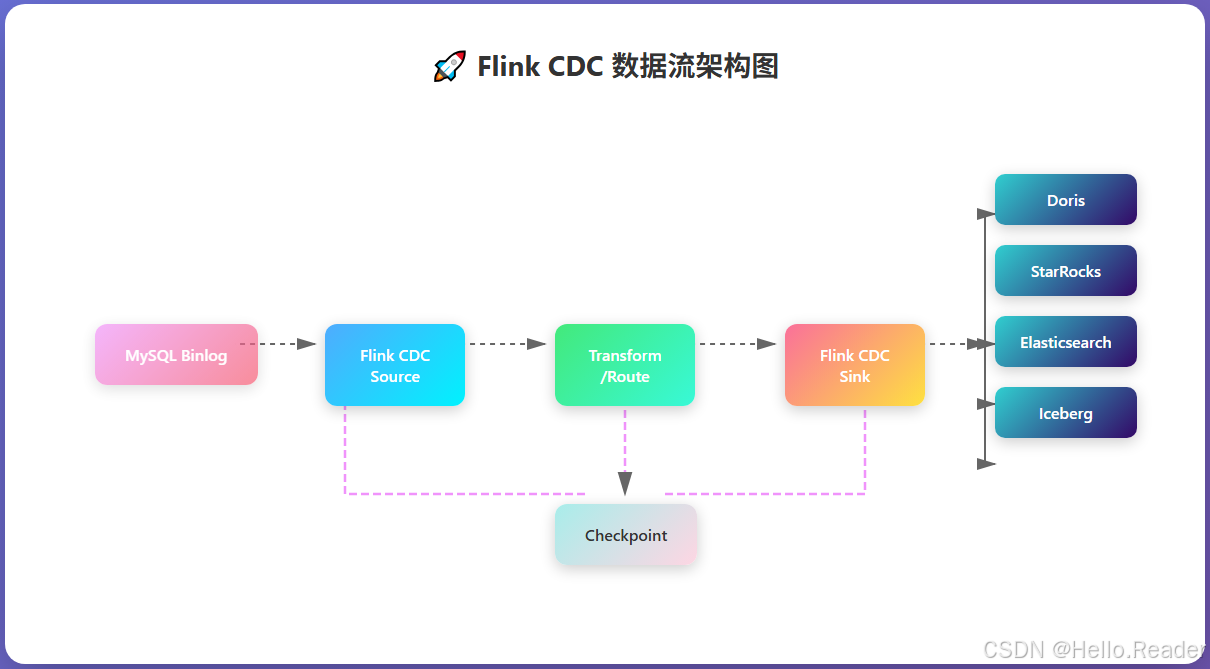
2. 工作原理与核心术语速览
- 一致性快照(Snapshot) + 变更订阅(Streaming/CDC):先做全量快照,再实时消费 Binlog(或等价变更流)。
- Pipeline:一次端到端同步任务,包含 Source、Transform/Route、Sink、并行度、容错配置。
- Transform / Route:入流字段投影/改名/派生与按规则路由到不同目标表。
- Schema Evolution:自动或半自动跟随源端 DDL 变化。
- Exactly-Once:借助 Flink Checkpoint + Sink 事务/幂等实现"端到端不重不漏"。
简化数据流:
3. 五分钟上手:MySQL → Doris(整库同步)
3.1 先决条件
- MySQL 开启 Binlog(ROW 格式),同步账号具备
REPLICATION SLAVE/CLIENT与SELECT。 - Doris FE/BE 正常,可写入目标库;网络互通、时钟同步(NTP)。
- Flink 集群可用(Standalone/YARN/K8s 均可)。
3.2 一份 YAML 就够了
yaml
source:
type: mysql
hostname: 127.0.0.1
port: 3306
username: root
password: 123456
tables: app_db\.\* # 整库同步
server-id: 5400-5404 # 选择未占用的ID区间
server-time-zone: UTC # 显式时区,避免时间字段偏移
sink:
type: doris
fenodes: 127.0.0.1:8030
username: root
password: ""
table.create.properties.light_schema_change: true
table.create.properties.replication_num: 1 # 示例;生产建议>=3
pipeline:
name: Sync MySQL Database to Doris
parallelism: 23.3 一条命令提交
bash
sh bin/flink-cdc.sh run -f pipeline.yaml启动后:先做快照 ,再切入增量。在 Flink Web UI 观察吞吐、延迟、反压与 checkpoint 健康度。
4. 常见配置与最佳实践
- 并行度 :
pipeline.parallelism随表数与目标吞吐调节;注意下游并发与配额。 - 表通配 :
tables: db\.\*一次性涵盖整库;建议建立白名单策略与命名规范。 - Server-ID:避免与现网复制/其他采集冲突。
- 时区 :统一声明
server-time-zone,彻底解决TIMESTAMP偏移。 - 自动建表属性:Doris/StarRocks 的轻量级 schema 变更,让 DDL 跟随更平滑。
5. Transform / Route:把数据"整好再落地"
5.1 典型需求
- 字段改名/投影 、类型修正、派生字段 (如
full_name = concat(first,last))。 - 多表按规则路由 到不同目标库/前缀(如
order_202501 → dwd.order_2025_01)。 - 条件过滤(仅同步在职员工等)。
具体语法以所用版本文档为准,下例仅作可读性演示:
yaml
transform:
- tables: app_db\.hr_employee
mapping:
emp_no: empNo
first_name: firstName
last_name: lastName
computed:
fullName: "concat(first_name, ' ', last_name)"
filters:
- "employment_status = 'ACTIVE'"
route:
- from: app_db\.order_.*
to: "ods.orders_${yyyyMM}" # 依据事件时间分月路由6. Schema Evolution:DDL 跟随的姿势
- 新增列 :启用轻量级 schema 变更(Doris/StarRocks),下游自动补列,默认
NULL/默认值。 - 类型调整:优先向后兼容(扩位/更宽类型);谨慎收窄类型。
- 删列/改名:删列前确认业务消费者;改名倾向"新增新列+迁移+下线旧列"的灰度策略。
- 演练 :在测试库先复现 DDL,确保路由/Transform 仍然正确。
7. Exactly-Once:端到端一致性的三要素
- Source 一致性:一致性快照 + Binlog/变更订阅;
- Flink Checkpoint:配置稳定的存储(HDFS/对象存储),合理的间隔/超时/并发/重试;
- Sink 写入语义 :选择幂等 (有主键/唯一键的 Upsert)或事务性写入(部分 Sink 支持两阶段提交或带 label 的幂等载入)。
工程建议:
- Checkpoint 间隔 30--120s 起步;Checkpoint 与作业日志分存;
- 重要变更前打 Savepoint,升级/回滚有保障;
- 确保下游表有主键/唯一键支撑 Upsert 语义(尤其 Doris/StarRocks/ES)。
8. 实战场景精选
8.1 MySQL → StarRocks(主键表 Upsert)
yaml
sink:
type: starrocks
jdbc-url: "jdbc:mysql://fe1:9030"
load-url: "fe1:8030,fe2:8030"
database: ods
username: root
password: ""
table.create.properties.duplicate_key: false
table.create.properties.primary_key: "emp_no"
sink.properties.enable_upsert: true以主键表承载 Upsert,结合 label/事务机制,可获得强一致的"最后写入生效"。
8.2 MySQL → Elasticsearch(文档型检索)
yaml
sink:
type: elasticsearch
hosts: "http://es1:9200,http://es2:9200"
index: "emp_index"
id.key: "emp_no" # 文档ID = 业务主键
write.mode: upsert
index.create.mappings:
emp_index: |
{
"mappings": {
"properties": {
"emp_no": {"type": "keyword"},
"fullName": {"type": "text"},
"hire_date": {"type": "date"}
}
}
}以 upsert 模式避免重复文档;时间字段用
date,并明确format(如需要)。
8.3 MySQL → Iceberg(湖仓分层)
yaml
sink:
type: iceberg
catalog: "hive"
namespace: "ods"
warehouse: "hdfs:///warehouse/iceberg"
write.distribution.mode: "hash"
write.upsert.enabled: true适合拉通批流一体与多层分区;注意分区策略、压缩与小文件治理。
9. 部署与运维:Standalone / YARN / Kubernetes
9.1 Standalone(最简姿势)
bash
sh bin/flink-cdc.sh run -f pipeline.yaml # 可加 --detached 后台9.2 YARN(Per-Job / Application)
- 合理设置队列与资源上限;
- 打通日志采集;
- 升级/回滚:Savepoint + 新版本 YAML 重新提交。
9.3 Kubernetes(推荐生产形态)
- 使用 Flink K8s Operator / Deployment;
- Checkpoint 目录挂载持久卷(如对象存储 S3/OSS 或 HDFS 网关);
- 资源:JM/TaskManager 的 CPU/内存、网络缓冲、RocksDB state 背压;
- 指标:接入 Prometheus/Grafana,关键监控见下节。
10. 监控面板要看什么(SRE 友好清单)
- 吞吐 TPS / 延迟(End-to-End Latency):关注 P95/P99。
- Backpressure:定位是 Source 读取、Transform 计算还是 Sink 写入成为瓶颈。
- Checkpoint 成功率与耗时:失败/超时/积压异常。
- Record Lag(Source 端):与 Binlog 最新位点差值。
- 下游拒绝/错误比例:索引写满、唯一键冲突、事务冲突、Quota 限制。
- 资源维度:TM/JM 内存、网络缓冲、RocksDB 读写放大。
11. 性能调优手册(开箱即用)
- 并行度 :按表数/目标吞吐提升
pipeline.parallelism,同时核对下游并发。 - 快照分块:增大 chunk(如 8k--64k)与 fetch size,提升初始化速度。
- 批写与刷盘:调大 Sink 的 batch size / flush interval;控制单批大小避免 OOM。
- 键选择:确保主键/唯一键合理,Upsert 聚合更高效。
- 列裁剪:Transform 只投影必要列,节省网络与序列化。
- 压缩:启用 Source/Sink 压缩(取决于连接器能力)。
- 热点打散:路由/分区键避免倾斜;必要时二次散列。
12. 回滚与变更流程(安全上线)
- 上线前:
--savepoint固化作业状态; - 配置变更:改 YAML(路由/Transform/并行度等);
- 平滑重启:从 Savepoint 恢复;
- 异常回滚:回到上一个 Savepoint;
- 审计:记录位点/DDL/参数变更与工单编号。
13. 常见故障与一针见血的定位
- "server-id in use":与现有复制冲突;换唯一区间。
- 时间错位 8 小时 :忘了
server-time-zone;统一源端/会话时区。 - 初始化卡住:大表快照、锁等待、带宽不足;考虑离线导入 + 增量衔接。
- 下游写入报错:鉴权/建表失败/唯一键冲突;先在测试库复现建表策略。
- 反压在 Sink:提升下游并发、调大批写、扩容;必要时降采样或缓冲。
- DDL 不兼容:收窄类型/改名;走"新增新列→迁移→下线旧列"的灰度流程。
14. 安全与合规
- 最小权限:采集账号仅授予必要权限;
- 密钥管理:K8s Secret/密文文件,禁入仓;
- 数据分级:敏感字段在 Transform 层脱敏/哈希化;
- 审计:保留位点/DDL/变更记录与访问日志。
15. 结语
Flink CDC 的价值在于**"把复杂度装进一份 YAML":
它既能搞定 整库级的快照 + CDC、Schema 演进 、Transform/Route ,也能在运维侧以 Exactly-Once 与 Savepoint 提供生产级的可控性。把规则固化在配置里,流水线就能"复制粘贴 + 小改"快速复用,真正做到规模化、工程化**的实时数据集成。