项目论文:https://arxiv.org/abs/2412.09442
项目代码:GitHub - zhengli97/ATPrompt: ICCV 2025 Official PyTorch Code for "Advancing Textual Prompt Learning with Anchored Attributes"
一、背景
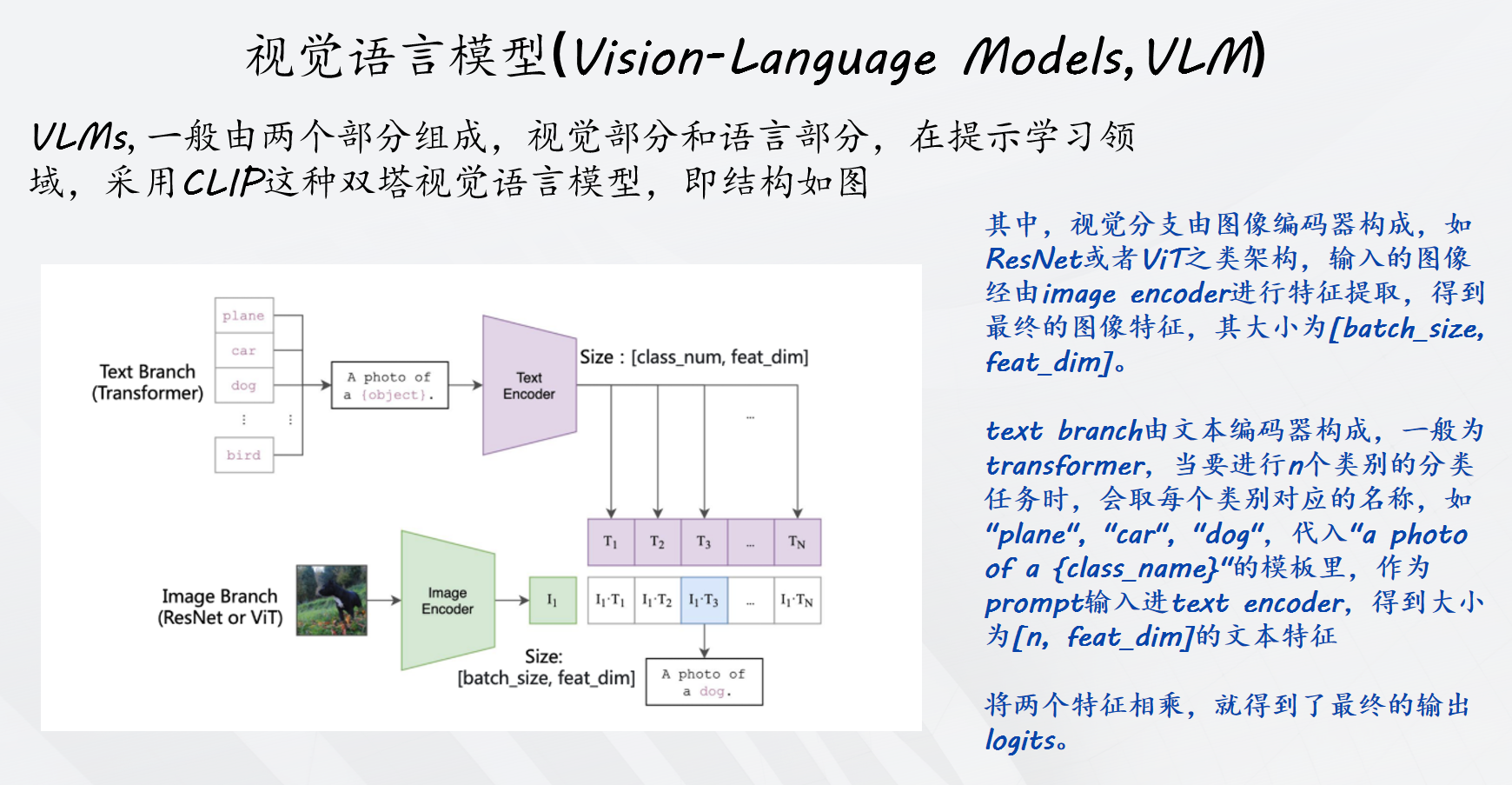
提示学习:已有的文本模版提示具有两个问题:(1) 传统的固定的文本提示往往不是最优,(2) 针对性设计的文本模板费时费力,且不同数据集之间无法泛化通用。CoOp首先提出了将多个可学习词元(learnable soft token)与类别词元(class token)级联的形式,以此让模型自己学出适合的文本提示。
本文讨论了提示学习现有的缺点:例如CoOp引入软文本标记和硬类别标记相结合作为输入,但是这种形式将软提示限制在一维的、预定义的类别空间内与图像对齐,从而限制了它们在未知类别上的适用性。因此,基于当前文本形式进行训练更有可能过拟合已知类别,降低了它们对未知类别的零样本泛化能力。
于是,ATPrompt提出利用属性作为桥梁来增强图像与未知类别的对齐。为VLM引入基于属性锚定的文本提示方法。通过将多个固定的通用属性标记整合到可学习的软提示中,将软提示的学习空间从原来的一类别层面扩展到多维属性层面。软标记在训练过程中不仅能获得特定于类别的表示,还能获得与属性相关的通用表示。
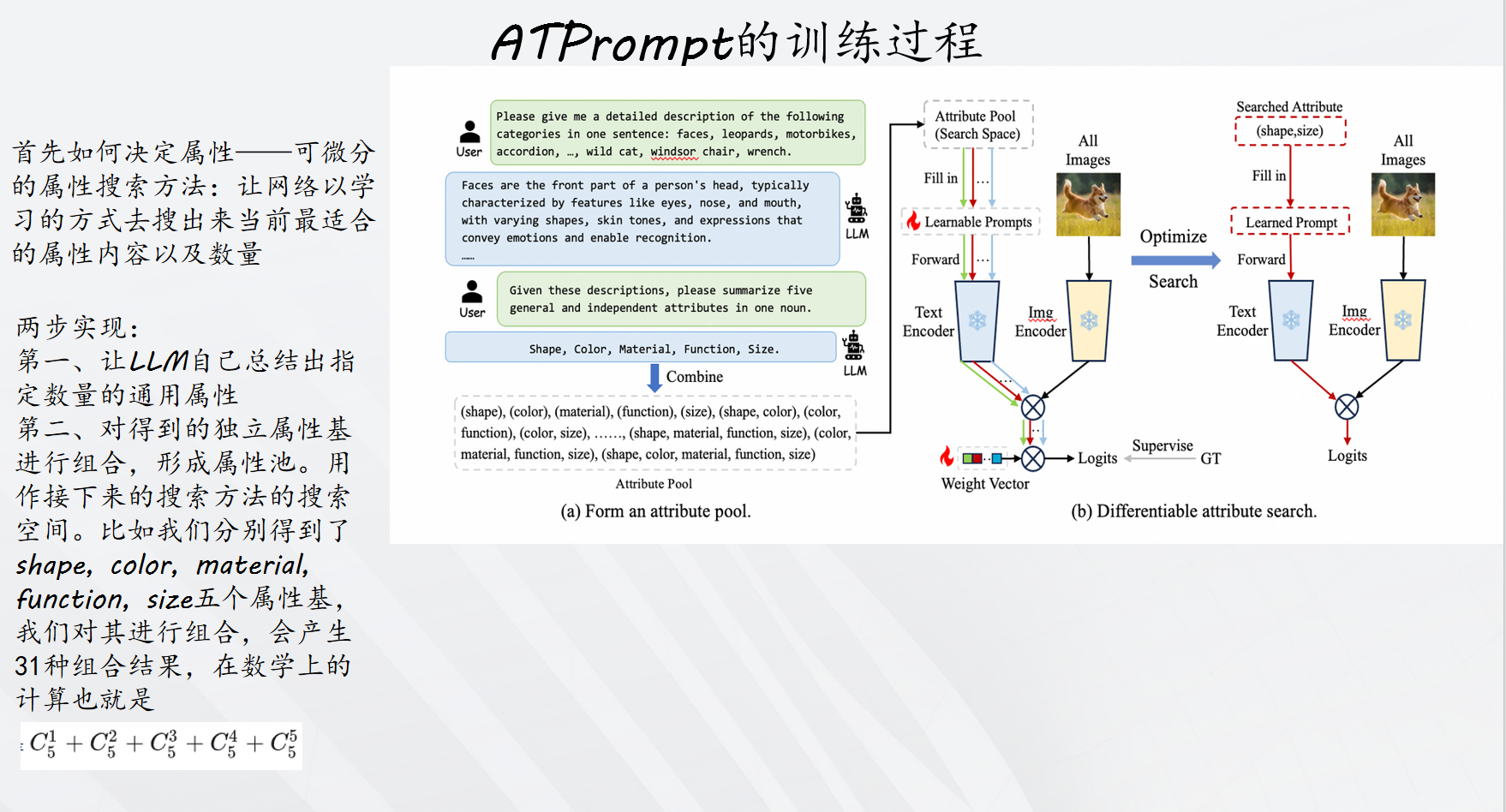
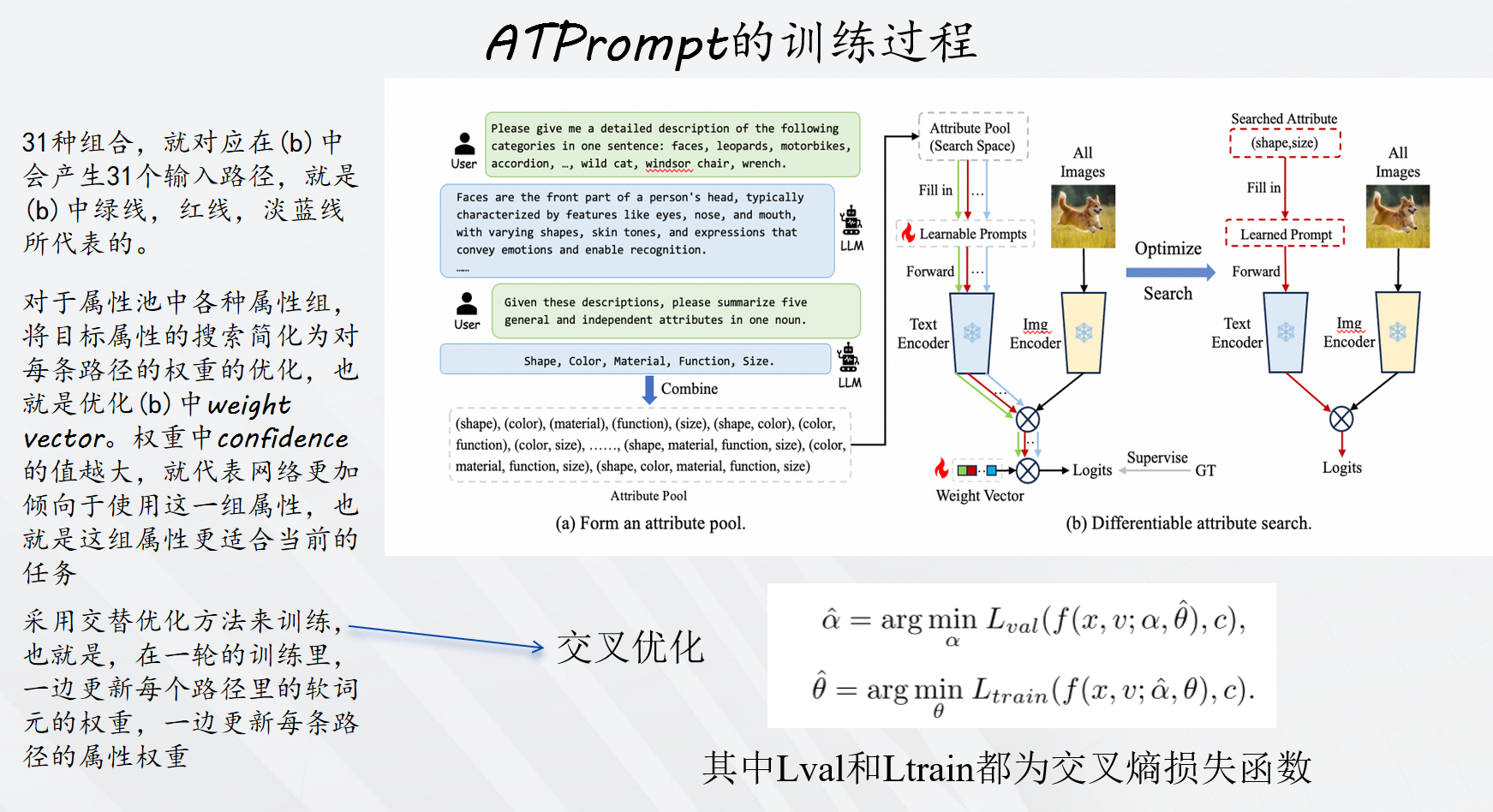
该方法有两个创新点:(1)属性搜索 :引入可微分的属性搜索,旨在从搜索空间V找到具有代表性的属性V。为了使搜索空间连续,将离散的属性选择放宽为对所有可能的候选属性进行softmax加权求和。于是属性搜索变成为候选池学习权重向量α。(2)联合学习属性权重α和软提示标记θ,通过最小化验证损失Lval和最小化训练损失Ltrain来学习,采用交叉优化算法解决这个双层优化问题,其中两个损失函数均使用交叉熵损失函数,搜索之后,选择权重最高的属性组合。
训练过程如下:
二、实际代码实战
首先是按照github给出的要求:创建环境并安装依赖项。
创建conda环境:
python
# Create a conda environment
conda create -y -n atprompt python=3.8
# Activate the environment
conda activate atprompt
# Install torch (requires version >= 1.8.1) and torchvision
# Please refer to https://pytorch.org/ if you need a different cuda version
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html克隆 ATPrompt 代码存储库和安装要求
python
git clone https://github.com/zhengli97/ATPrompt.git
cd ATPrompt/
# Install requirements
pip install -r requirements.txt
cd ..安装 dassl 库:
python
cd Dassl.pytorch/
# Install dependencies
pip install -r requirements.txt
# Install this library (no need to re-build if the source code is modified)
python setup.py develop接下来下载具体的数据集,按照官方给出的数据集格式进行准备:不需要全部下载,我这里只对擦了caltech101和stanfordcas。
python
$DATA/
|---- imagenet/
|---- caltech-101/
|---- oxford_pets/
|---- stanford_cars/接下来可以下载预训练权重到本地(可选):

需要在/trainers/coop.py下修改到本地路径。
接下来可以直接进行训练,按照论文的说法,训练主要按照base基类进行训练,然后对new新类进行zero-shot测试和泛化测试。
第一步要修改数据集的路径:scripts/coop/base2new_train.sh的第四行
然后使用ATPrompt进行训练,比如对caltech101进行训练:
python
# CoOp+ATPrompt, dataset=caltech101
sh scripts/coop/atp_base2new_train.sh caltech101训练会进行5轮,选取最优种子。
如果想进行对比实验,不使用ATPrompt,可以使用:
python
# Vanilla CoOp
sh scripts/coop/vanilla_base2new_train.sh imagenet对于泛化训练过程也是类似:
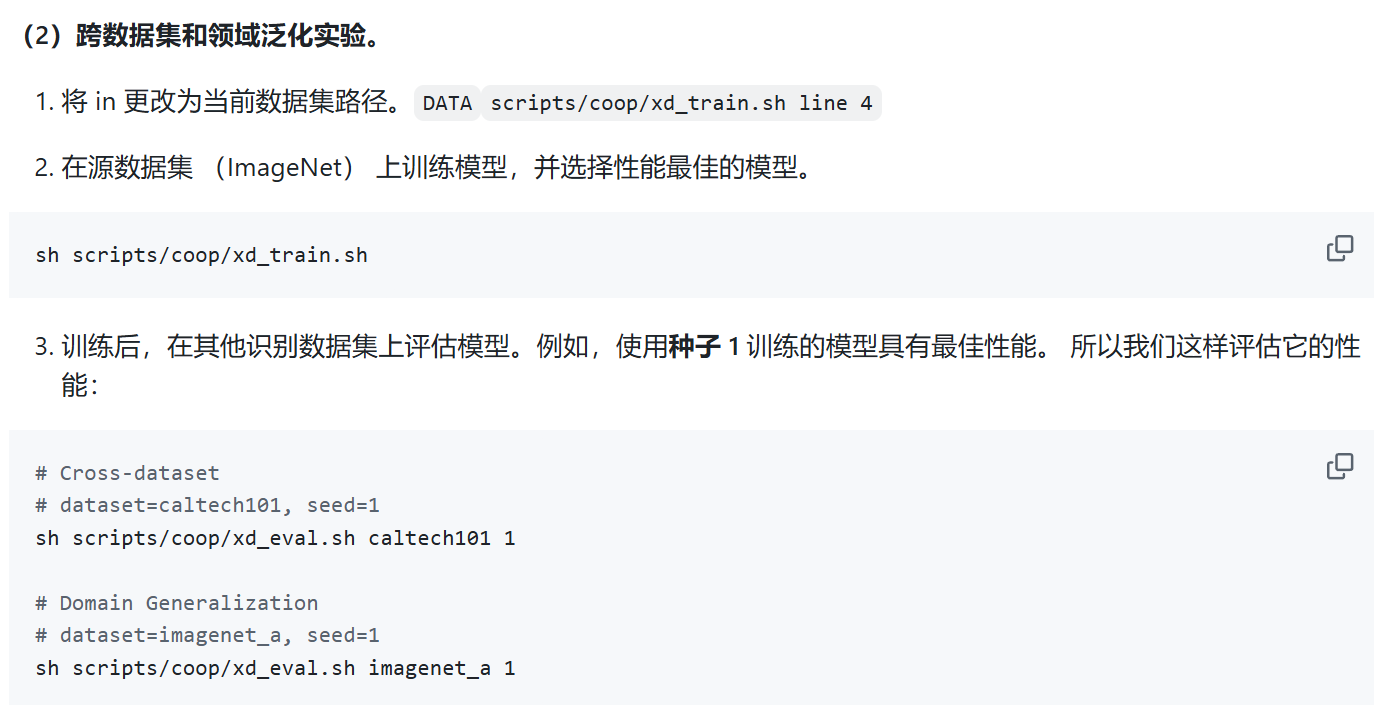
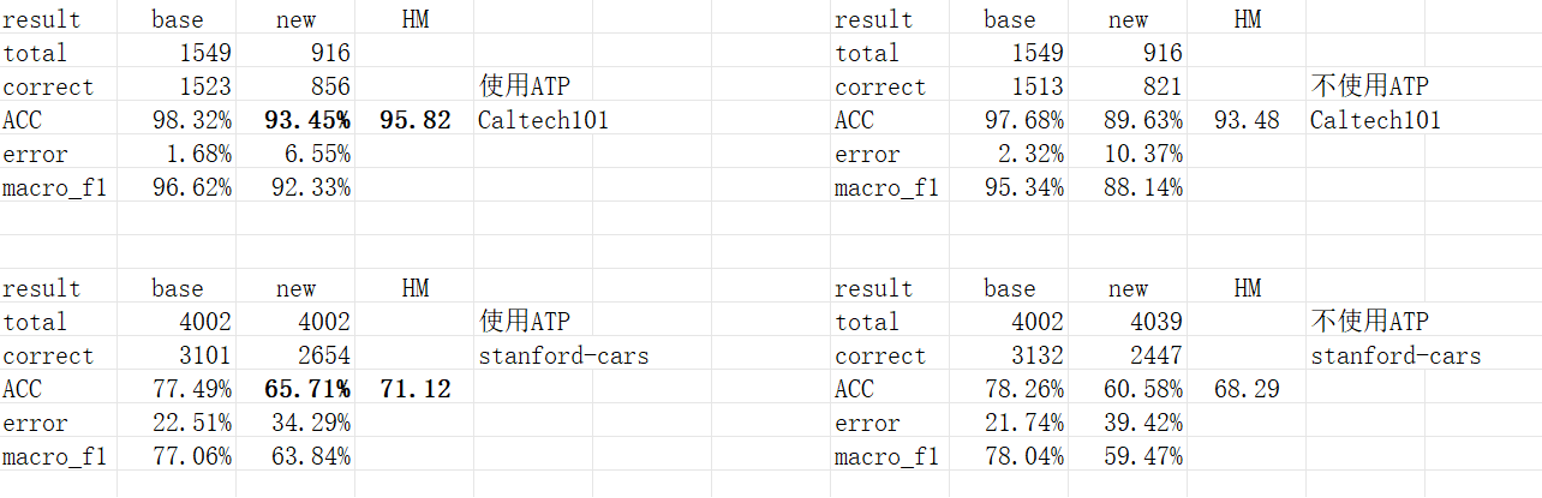
复现实验结果,使用Caltech101和Stanfordcars数据集,使用和不使用 ATPrompt 的情况下,从base到new的泛化实验。ATPrompt对baseline的Coop方法的性能有所提高。
以上为全部内容!