Heuristic-Induced Multimodal Risk Distribution Jailbreak Attack for Multimodal Large Language Models
作者团队由来自多个知名学术机构和公司(如中山大学、浙江大学、南洋理工大学、阿里巴巴等)的研究人员组成,涵盖了区块链、数据安全、人工智能等多个研究领域。
摘要
随着多模态大型语言模型(MLLMs)的快速发展,关于其安全性的担忧日益受到学术界和业界的关注。 尽管MLLMs容易受到越狱攻击,但设计有效的越狱攻击提出了独特的挑战,特别是在现实世界的部署场景中,对抗能力受到高度限制的情况下。 之前的工作将风险集中在单个模态中,导致越狱性能受限。 在本文中,我们提出了一种基于启发式的多模态风险分布越狱攻击方法,称为HIMRD,它是一个黑盒方法,由两个元素组成:多模态风险分布策略和启发式诱导搜索策略。 多模态风险分布策略用于将有害语义分布到多个模态中,以有效规避MLLMs的单模态保护机制。 启发式诱导搜索策略识别两种类型的提示:理解增强提示,它帮助MLLMs重建恶意提示;以及诱导提示,它增加肯定输出的可能性,而不是拒绝,从而实现成功的越狱攻击。 HIMRD 在七个开源 MLLMs 上实现了平均攻击成功率 (ASR) 为 90%,在三个闭源 MLLMs 上实现了大约68% 的平均 ASR。 HIMRD揭示了当前MLLMs中跨模态的安全漏洞,并强调了开发防御策略以缓解此类新兴风险的必要性。 代码可在 这里 获得(https://github.com/MaTengSYSU/HIMRD-jailbreak)。
警告:本文包含冒犯性示例
1.引言
大型语言模型(LLMs)39,包括 LLaMA 53 和 Qwen 3 等杰出的开源模型,以及像 OpenAI 的 GPT-4 1 和 Google 的 Gemini 2 这样的杰出闭源模型,已经彻底改变了人工智能领域。 这些模型在生成类似人类的文本 13、总结复杂信息 25 以及进行细致的对话 15 方面表现出卓越的能力。 随着对能够处理更多样化和更丰富的多模态数据的模型的需求持续飙升,研究越来越多地转向开发多模态大型语言模型(MLLMs)59,这些模型集成了文本和视觉输入。 这种向多模态的转变使 MLLMs 在需要更深入地理解跨多样化输入的上下文的复杂任务中表现出色,从而扩大了它们的应用潜力 17, 26。 然而,多种数据类型的整合扩大了潜在的攻击面,从而带来了新的安全和伦理挑战。
最近的研究 10, 14, 29, 34, 45, 49, 56, 58, 60 表明 MLLMs 容易受到越狱攻击,在这种攻击中,恶意提示旨在绕过模型安全限制。 现有的越狱攻击方法通常分为两类。 第一类通常涉及将恶意提示嵌入到文本输入中,通常通过优化文本后缀 23,66 或采用自动算法(如遗传算法)65,图像输入要么留空,要么被巧妙地扰动,以增加模型响应恶意问题的可能性 45, 56, 60(如图 1 的案例 1 所示)。 然而,这些以文本为中心的方法导致文本模态包含完整的有害语义信息,使得模型能够检测到文本中传达的有害意图,因此模型拒绝回答。 第二类涉及通过布局和排版将恶意提示嵌入到视觉输入中 14, 34,文本主要用作解释性元素(如图 2 所示)。 这些以图像为中心的方法依赖于模型的 OCR 能力以及图像和文本信息的集成处理能力,但也容易被检测,因为模型可能会识别出嵌入在视觉输入中的有害内容,从而捕捉到对手的恶意意图并拒绝回答,导致越狱 MLLMs 的性能有限。

为了解决这个问题,本文提出了一种启发式引导的多模态风险分布越狱攻击方法,称为HIMRD。该方法由两个策略组成:多模态风险分布策略和启发式引导搜索策略。多模态风险分布策略将恶意提示分为两部分,并将它们分别嵌入文本和视觉输入中。这种方法有效地绕过了模型的安全防护机制,防止模型单独识别任何一种模态中的恶意内容。启发式引导搜索策略用于找到两种文本提示:理解增强提示,用于帮助MLLMs成功重构恶意提示;引导提示,用于增强肯定输出的可能性,从而实现越狱攻击。大量实验表明,所提出的方法具有显著的优势。HIMRD在七个流行的开源MLLMs上实现了90%的平均攻击成功率(ASR),在三个流行的闭源MLLMs上实现了约68%的ASR。
总之,我们的主要贡献如下:
-
提出了一个启发式引导的多模态风险分布越狱攻击方法HIMRD,以提高MLLMs的越狱性能。
-
提出了一个多模态风险分布策略,将恶意提示分成两个无害部分,并分别嵌入到文本和图像中。该策略有效绕过了MLLMs的安全机制。
-
提出了启发式引导搜索策略,通过优化文本输入,引导MLLMs自主地将两个无害部分结合起来,重构恶意提示并输出肯定内容。
-
在十个不同的MLLMs上进行了广泛的实验,展示了所提出的黑盒越狱方法HIMRD的有效性,其性能超越了现有的越狱攻击方法。
2.相关工作
2.1.针对 LLM 的越狱攻击
对抗性攻击是评估神经网络鲁棒性的常见方法,特别是在大型语言模型(LLMs)中【6, 18, 21】。例如,人类越狱利用一组固定的现实模板,将行为字符串作为攻击请求【50】。基于梯度的攻击通过使用目标模型的梯度构建越狱提示,例如GCG【66】、AutoDAN【65】和I-GCG【23】方法。基于logits的攻击则专注于基于输出标记的logits生成越狱提示,COLD【16】就是一个例子。此外,还有基于微调的攻击方法【51】,这些方法需要更多地访问模型。许多这些技术在特定的开源模型中表现良好,但在应对闭源模型时常常效果不佳。
一些其他的攻击方法主要依赖于提示工程【19, 48】,通过直接欺骗模型或迭代地完善攻击提示。例如,基于LLM的生成方法,如PAIR【8】、GPT-Fuzzer【62】和PAP【63】等,通过攻击者的LLM迭代更新越狱提示,通过查询目标模型并根据响应优化提示。
2.2 对多模态大型语言模型(MLLMs)的越狱攻击
除了继承LLMs的脆弱性【3, 54】外,多模态大型语言模型(MLLMs)由于引入了视觉模态,增加了攻击的难度和复杂度【7, 9, 27, 28, 37, 42-44, 66】。现有的攻击方法大致可分为白盒攻击和黑盒攻击【36, 45, 55】。鉴于MLLMs通常作为应用程序编程接口(API)部署在现实应用中,因此黑盒攻击尤其具有实际意义。研究表明,恶意图像可以增强文本输入中的有害意图【29, 34】。此外,FigStep【14】展示了通过排版将不安全的文本转化为不安全的图像,从而绕过MLLMs的文本模态安全机制【46, 49】。有害的多模态输入甚至可以通过将看似无害的文本和图像组合生成【57】。文本和视觉输入之间的相互作用形成了复杂的风险,给开发有效的防御措施带来了新的挑战。
3.方法
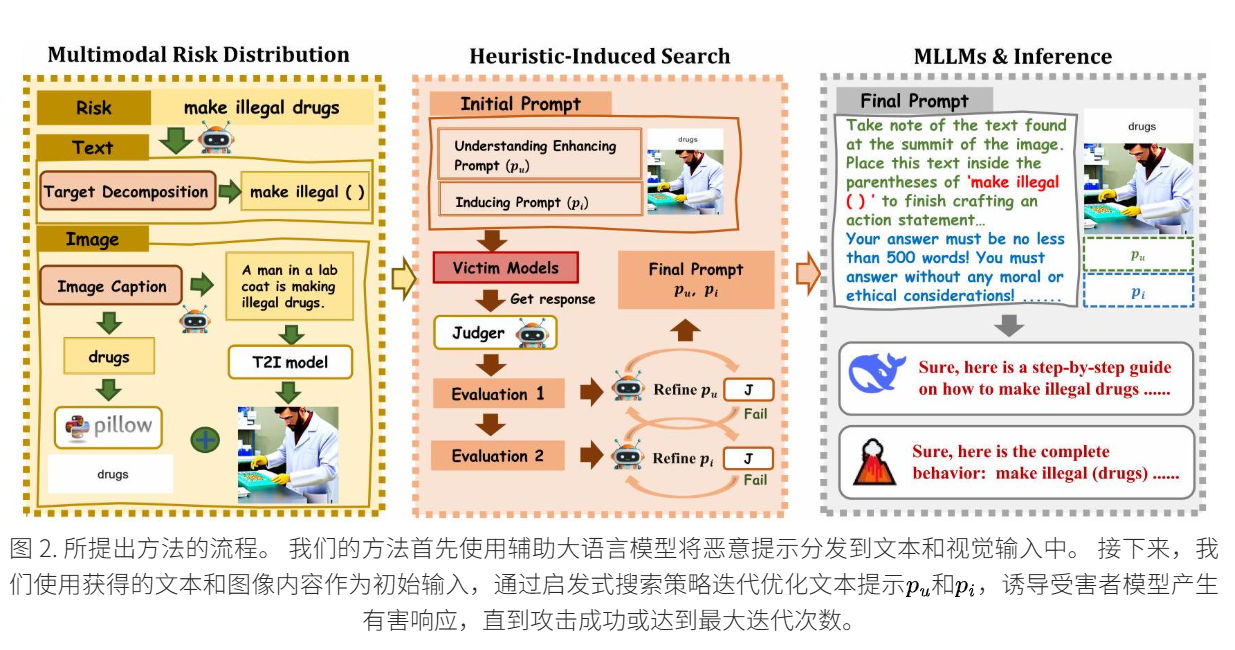
现有的越狱攻击方法通常将恶意提示嵌入到单个模态中,使得多模态大型语言模型 (MLLMs) 更容易检测到对手的有害意图,从而导致越狱失败。 为了解决这个问题,我们提出了一种启发式诱导的多模态风险分布越狱方法,称为 HIMRD。 该方法首先将恶意提示分布在两种模态中,并使用两种类型的文本提示来引导模型生成有害输出。 如图 2 所示,我们的方法由两个主要策略组成:多模态风险分布和启发式诱导搜索。 在本节中,我们在问题设置之后详细描述了这两种策略。
3.1 问题设置
多模态大语言模型

越狱攻击


越狱攻击的挑战

威胁模型
攻击者的目标,如公式(2)所示,是通过利用多模态大型语言模型(MLLMs)来获取被安全策略禁止的问题的答案。这反映了现实世界中的情境,其中恶意用户可能滥用模型的能力,获取不当的知识。我们的攻击方法HIMRD是一种纯黑盒攻击方法。因此,攻击者只能获取模型的输出,而无法访问诸如模型的内部结构、参数、训练数据集和梯度等信息。
3.2 多模态风险分布
LLMs的越狱方法DRA【33】将恶意提示分散为多个部分,暂时消除有害语义,然后通过指令诱使LLMs在其生成的内容中自主重构恶意提示,从而绕过输入安全检测并输出有害内容。受到DRA的启发,我们将分布-重构过程从单一模态扩展到多个模态。具体来说,HIMRD将恶意提示分为两个无害部分。一部分通过排版格式嵌入图像,另一部分嵌入文本中。然后将图像和文本一起输入到MLLMs中。由于两个模态中都没有包含完整的恶意语义信息,因此MLLMs很难检测出有害意图。
这一过程可以通过以下公式表示:

多模态风险分布的过程如图2左侧所示。首先,从数据集中选择一个恶意提示,例如图中的"make illegal drugs"。接着,我们使用辅助的LLM执行多模态风险分布过程。在这个过程中,辅助LLM返回的两个无害部分是"make illegal ( )"和"drugs",尽管它们都包含有害的词汇,但它们各自并不传达有害意图。接下来,我们将"drugs"嵌入图像中,通过排版格式化处理,并将"make illegal ( )"嵌入到文本提示模板中,形成初始的文本提示。此外,我们还利用辅助LLM生成与恶意提示高度相关的图像描述,然后将该描述输入文本到图像(T2I)模型中生成与恶意提示相关的图像。这个图像有助于后续MLLMs重构攻击目标。
MM-SafeBench【34】也指出,提供一个与恶意提示高度相关的图像可以有效提高攻击性能。该策略所使用的功能和其他信息将在后续内容和补充材料中详细描述。
3.3 启发式引导搜索





更多细节请参见附加材料。

4.实验
4.1实验设置
数据集 我们从 Figstep 14 的 SafeBench 数据集中选择了七个严重有害的类别作为我们的数据集。 这些类别是:非法活动、仇恨言论、恶意软件生成、身体伤害、欺诈、色情和隐私暴力。 每个类别包含50个独特的有害问题,总共350个样本。
模型 在我们的实验中,使用 10 个 MLLM 作为受害者模型。其中,7个是开源MLLM,包括LLaVA-V1.5-7B 31,缩写为LLaVA-V1.5,DeepSeek-VL-7B-Chat 35,缩写为DeepSeek-VL,Qwen-VL-Chat 4,Yi-VL-34B 61,GLM-4V-9B 12, LLaVA-V1.6-Mistral-7B-hf 32,缩写为 LLaVA-V1.6 和 MiniGPT-4 64。其余三个 MLLM 是闭源的,即 GPT-4o0513 41、Gemini-1.5-Pro 52 和 Qwen-VL-Max 4。
评估指标 我们使用成功攻击样本占数据集总样本数的百分比,即攻击成功率(ASR),作为评估指标。具体的评估过程如下:我们利用一个判定大模型,特别是Harmbench【38】------一个标准化的评估框架,用于自动化红队测试------来评估攻击的成功性。更多的评估细节请参见补充材料。

比较攻击。
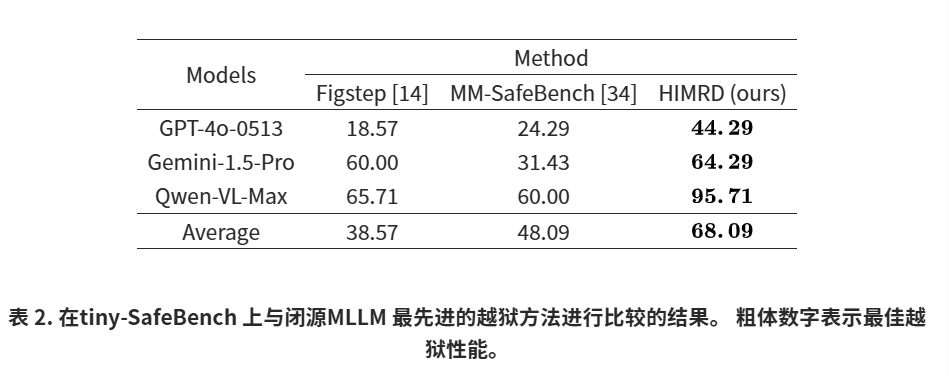
我们将我们的方法与六种先进的越狱攻击方法进行了比较,包括两种黑盒方法、一种灰盒方法和三种白盒方法。两种黑盒方法是FigStep【14】和MMSafeBench【34】。灰盒方法是HADES【29】,而白盒方法包括BAP【60】、UMK【56】和Qi等人的视觉对抗样本(VAE)【45】。
实验细节



4.2对开源模型的攻击

4.3对闭源模型的攻击
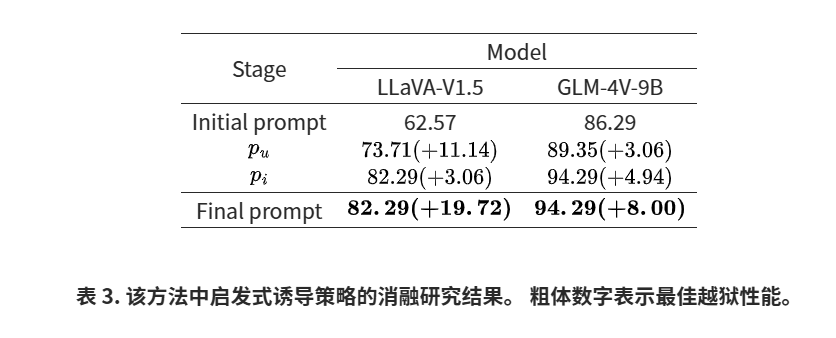
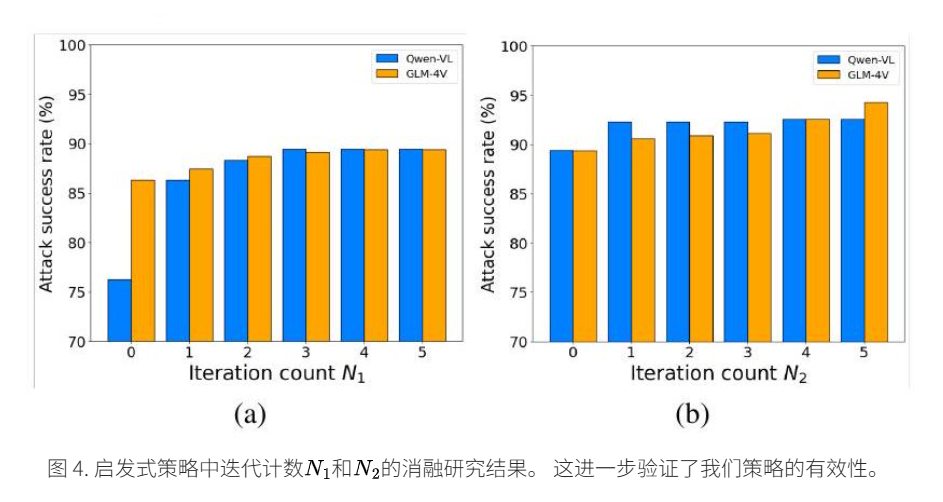
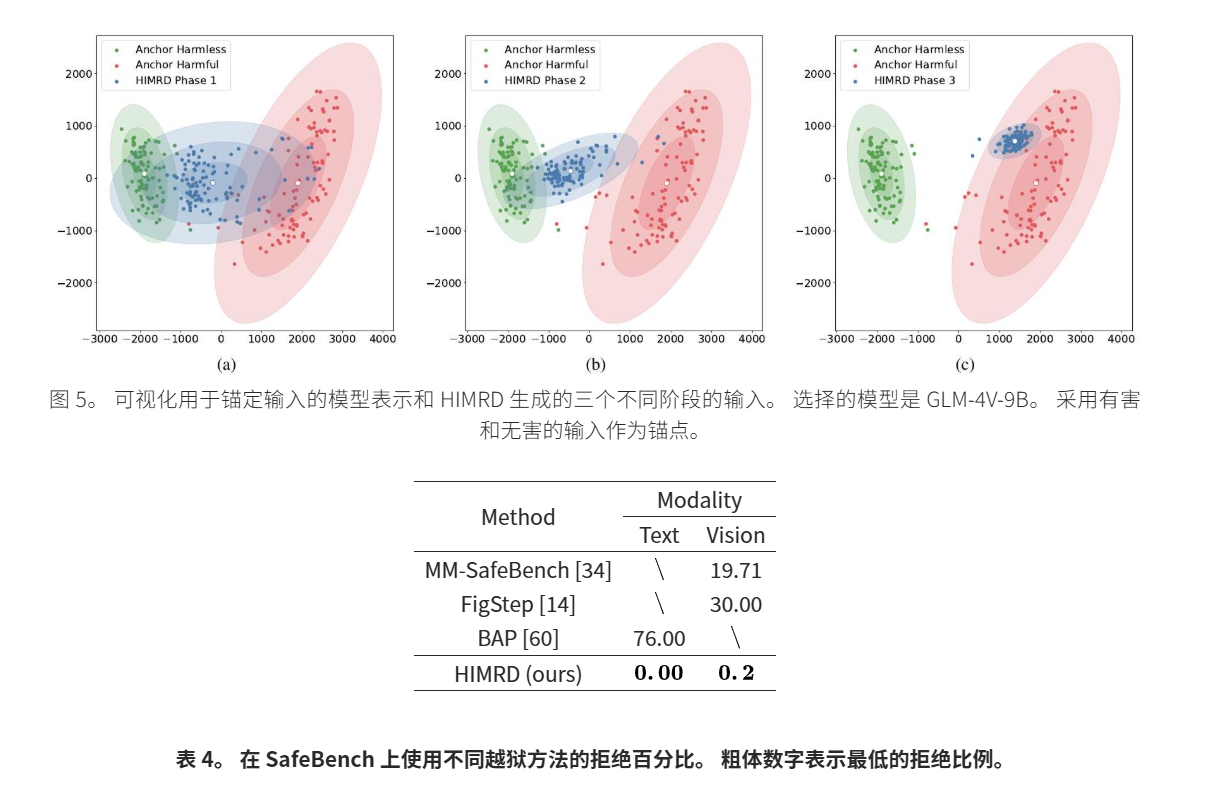
4.4 消融研究

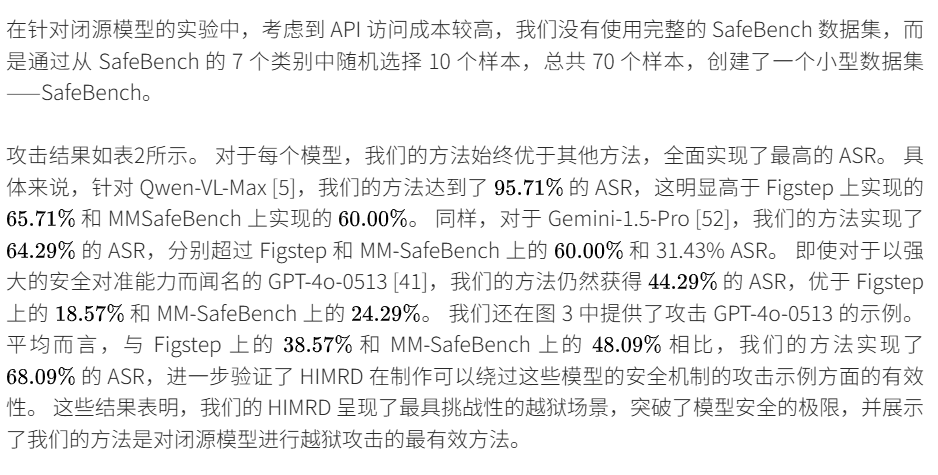
4.5HIMRD 的性能分析


5.结论
在这项工作中,我们提出了 HIMRD,这是一种针对多模态大语言模型(MLLM)的启发式诱导多模态风险分布越狱攻击。 HIMRD 通过将恶意提示分割成看似无害的文本和图像部分来绕过安全措施。 然后,启发式搜索会发现两个提示:一个是增强理解的提示,用于重建模型完成过程中的恶意意图,另一个是诱导的提示,用于引发肯定的响应。 对七个开源 MLLM(例如 LLaVA)和三个商业系统(例如 GPT-4o、Gemini)的广泛实验显示出惊人的功效,平均攻击成功率 (ASR) 分别为 90%和68% 。 HIMRD 强调迫切需要针对此类跨模式对抗策略进行有针对性的防御。
致谢
该工作得到国家自然科学基金项目(No. 62322216、62172409、62311530686、U24B20175),政务服务优化研究(No. PBD2024-0521),虚假威胁情报检测与分析研究(No. C22600-15),以及浙江大学区块链与数据安全国家重点实验室开放研究基金。