大家好,我是你们的扯蛋蛋,已经很久没有写文章了,最近在看到网上有蛮多的学习langchain的视频,我看到也是比较吸引和好奇的大模型,为什么能够调用那么多的工具和那么好呢,它本身就是对话式的文本模型,为什么会这么会用这么精彩呢,在这个的好奇心下我也开始我的大模型之旅啦
什么是 LangChain
LangChain 是一个基于 python 语言的模块化、可组合、面向开发者的开源框架,旨在简化基于大型语言模型的应用程序开发。它由 Harrison Chase 于 2022 年 10 月发起,迅速成为 GitHub 上增长最快的开源项目之一。
顾名思义,LangChain中的"Lang"是指language,即⼤语⾔模型,"Chain"即"链",也就是将⼤模型与外部数据&各种组件连接成链,以此构建AI应⽤程序。 LangChain中文网 - 跟着LangChain学AI开发 、
为什么需要LangChain
当ChatGPT、QwenLM、DeepSeek等大语言模型(LLM)横空出世时,开发者们立刻意识到:LLM不是终点,而是构建智能应用的"大脑"。但要让这个"大脑"真正解决实际问题,还需要解决三个关键痛点:
信息过时
LLM的知识截止于训练数据的时间节点(如GPT-4的训练数据截止到2023年),无法回答诸如"2024年最新AI论文内容"或"今天纽约股市收盘价"这样的问题。但是这个我们可以怎么去弥补这个不足呢,我们可以用到嵌入模型,或者是RGA,这俩个东西,我目前还在学习当中。
无法调用外部工具
LLM虽然是自然语言大模型,但是不能去执行外部操作,比如调用API、计算数值、查询数据库、发送邮件等。它就像一个只会思考的"脑壳",没有"手脚"。 但是这个的现在也有解决的方法,MPC协议,这个也是去年大家统一的一个协议,有时间我也会总结一下写一篇文章,MCP 中文站(Model Context Protocol 中文) (mcpcn.com)
记忆有限
LLM的上下文窗口(例如GPT-4最多支持32,768个tokens)限制了它处理长文本的能力,难以记住对话历史或文档细节。但是这个的也有解决的方法也是通过RAG来解决
LangChain技术体系
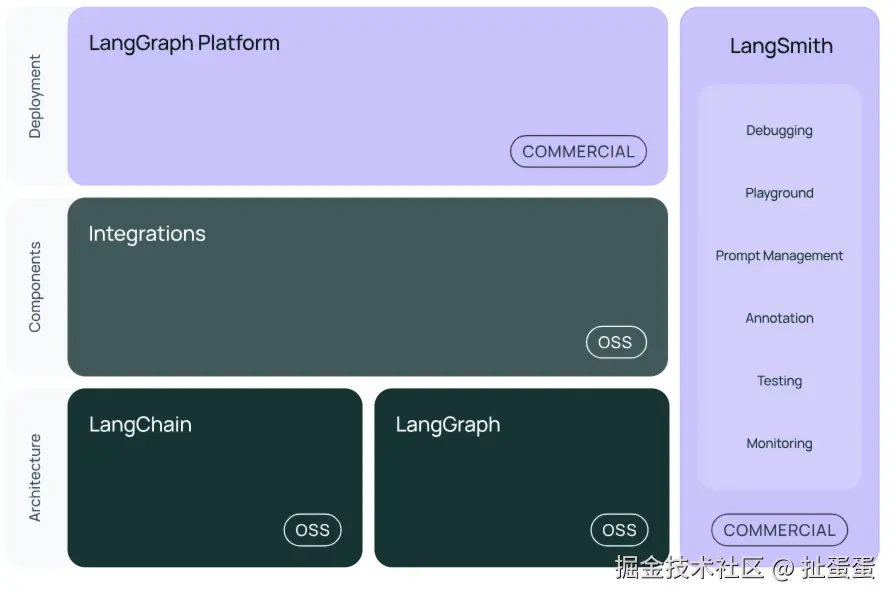
LangChain技术体系主要包括以下模块:
核心库
langchain-core
-
功能:提供 LangChain 的核心抽象和基类,是其他模块的基础。
-
主要组件:
- Runnable:LangChain 的核心执行接口,所有链、代理和工具都基于此抽象。
- PromptTemplate:用于动态生成模型输入的模板,支持字符串和聊天消息格式。
- OutputParser:解析语言模型的输出(如 JSON、列表、结构化数据)。
- Callbacks:用于监控和调试执行过程,支持日志记录、性能分析等。
-
用途:定义通用的接口和工具,确保模块之间的兼容性和可扩展性。
langchain
-
功能:主包,包含核心功能模块,依赖
langchain-core。 -
主要子模块:
- LLMs:与语言模型交互的接口(如 OpenAI、Hugging Face)。
- Chat Models:专为对话场景优化的模型接口。
- Memory:管理对话上下文的模块(如
ConversationBufferMemory)。 - Chains:组合提示、模型和其他组件的工作流(如
LLMChain、RetrievalQA)。 - Agents:动态决策和工具调用的模块。
- Tools:外部工具接口(如搜索、计算器)。
-
用途:提供构建复杂应用的完整工具集,适合快速开发。
langchain-community
-
功能:社区贡献的扩展模块,包含大量第三方集成和工具。
-
主要内容:
- 向量存储:支持 Chroma、FAISS、Pinecone 等向量数据库。
- 文档加载器:支持从 PDF、CSV、网页等加载数据。
- 工具:如 Wikipedia、SerpAPI、Arxiv 等。
- 模型集成:支持 Hugging Face、Anthropic、Cohere 等模型。
-
用途:扩展 LangChain 的功能,适合需要特定集成或开源替代方案的场景。
语言模型集成库
LangChain 支持与多种语言模型和嵌入模型的集成,这些集成通常以单独的子包形式提供,需单独安装。以下是常见的模型集成库:
langchain-openai
- 功能:与 OpenAI 的 GPT 模型和嵌入模型(如 text-embedding-ada-002)交互。
- 用途:适合需要高性能模型的商业应用。
langchain-huggingface
- 功能:支持 Hugging Face 的开源模型和嵌入模型(如 SentenceTransformers)。
- 用途:适合本地部署或开源模型的场景
其他模型集成
langchain-cohere: 支持 Cohere 的嵌入和生成模型。langchain-mistralai: 支持 Mistral AI 的模型。langchain-google-genai: 支持 Google 的 Gemini 模型。
向量存储和检索库
LangChain 支持多种向量数据库,用于存储和检索文本的向量表示。这些库通常在 langchain-community 中,或以独立包形式提供。
langchain-chroma
- 功能:与 Chroma 向量数据库集成,支持高效的向量存储和检索。
- 用途:适合本地或小型应用的向量存储。
langchain-pinecone
- 功能:与 Pinecone 云向量数据库集成。
- 用途:适合大规模、分布式向量存储。
langchain-faiss
- 功能:与 FAISS(Facebook AI Similarity Search)集成,支持高效的本地向量搜索。
- 用途:适合高性能、本地化场景。
其他向量存储
- Weaviate (
langchain-weaviate): 支持云原生向量数据库。 - Qdrant (
langchain-qdrant): 高性能向量搜索。 - Elasticsearch (
langchain-elasticsearch): 结合 Elasticsearch 的搜索能力。
工具和外部服务集成
LangChain 提供了大量工具库,用于与外部服务交互。这些工具通常在 langchain-community 中,或者需要单独安装。
langchain-serpapi
- 功能:与 SerpAPI 集成,用于网页搜索。
- 用途:为代理提供实时搜索能力。
langchain-wikipedia
- 功能:查询 Wikipedia 的内容。
- 用途:快速获取百科知识。
- 安装:包含在
langchain-community。
其他工具
- Arxiv:查询学术论文。
- Wolfram Alpha:数学和科学计算。
- Zapier:自动化工作流集成。
辅助库
LangChain 生态还包括一些辅助库,用于调试、部署和增强功能。
langsmith
- 功能:LangChain 官方的调试和监控平台,用于记录链和代理的执行细节。
- 用途:优化性能、分析模型行为。
langserve
- 功能:将 LangChain 应用部署为 REST API。
- 用途:快速上线 LangChain 应用。
langgraph
- 功能:构建基于图的工作流,适合复杂、有状态的应用程序。
- 用途:实现多步骤推理或循环任务。
文档加载和处理库
LangChain 提供多种文档加载器和文本处理工具,通常在 langchain-community 中。
文档加载器
- PDF:
PyPDF2,pdfplumber。 - Web:
BeautifulSoup,WebBaseLoader。 - CSV/Excel:
pandas。
文本分割器
-
功能:将长文本切分为适合模型处理的块。
-
类型:
CharacterTextSplitter:按字符数分割。RecursiveCharacterTextSplitter:递归分割,保留语义。TokenTextSplitter:按 token 数分割。
LangChain核心模块
LLM 大模型接口
LangChain 封装了不同模型的调用方式,它统一了各种模型的接口,切换不同模型变得轻松。
PromptTemplate提示词模板
大模型的输出质量在很大程度上取决于提示词(Prompt)的设计,在LangChain 把提示词封装成模板,支持变量动态替换,管理起来更清晰,能灵活控制 Prompt 内容,避免硬编码。
Chain链
Chain链是 LangChain 的核心思想之一,一个 Chain 就是将多个模块串起来完成一系列操作,Chain链可以将上一步操作的结果交给下一步进行执行,比如用提示词模板生成 Prompt,将渲染后的提示词交给大模型生成回答,再将大模型的回答将结果输出到控制台,Chain和Linux中的管道符十分类似,每一步的输出自动作为下一步输入,实现模块串联。
Memory记忆
在和大模型对话时,大模型本身并不具备有记忆历史对话的功能,但是在使用ChatGPT、DeepSeek等大模型时,发现它们在同一个会话内有"上下文记忆"的能力,这样能使对话更加连贯。
LangChain 也提供了类似的记忆功能。通过 memory,可以把用户的历史对话保存下来,使大模型拥有历史记忆的能力,如下示例,每一轮对话会从ConversationSummaryBufferMemory中读取历史对话,渲染到Prompt供大模型使用。
对话结束之后,会将对话内容保存到ConversationSummaryBufferMemory,如果历史记忆超过一定大小,为了节省和大模型之间调用的token消耗,会对历史记忆进行摘要提取、压缩之后再保存,这样大模型拥有了记忆功能。
MCP 与工具调用
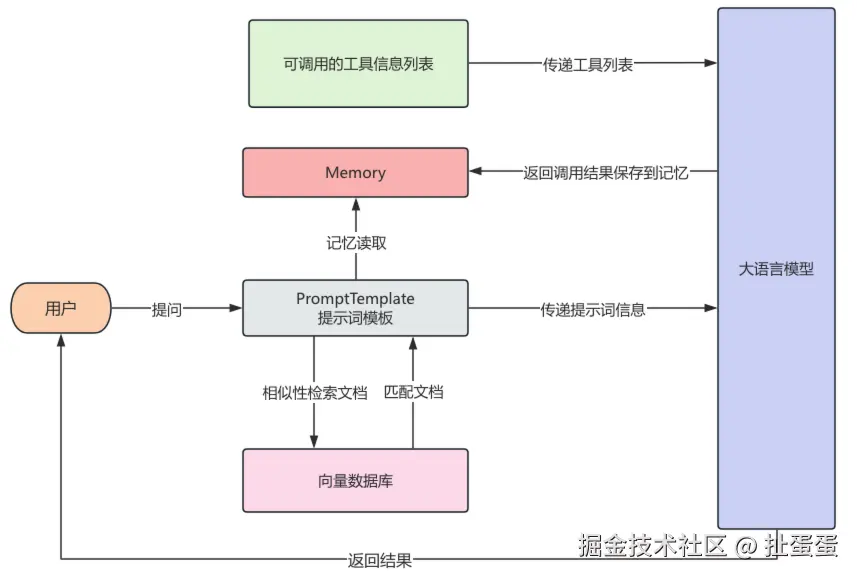
大语言模型本身是一种基于大量数据训练而成的人工智能,它本身是基于大量的数据为基础对结果进行预测,因此,大模型可能会出现给出1+1=3这种情况,大模型本身是不会"上网", 也不会算数的,因此,可以给大模型接入各种各样的工具如Google搜索、高德地图定位信息查询、图像生成等等。
那么大模型是怎么使用工具的呢?在现如今,很多的大模型都支持了工具调用,也就是将可用的工具信息列表在调用大模型时传递过去,这些信息包括工具的用途、参数说明等等,大模型会根据这些工具的作用确定调用哪些工具,并且根据参数的描述,来返回调用工具的参数。
最终将工具调用结果返回给大模型,完成用户交给的任务,整个过程中,大模型会根据任务判断是否调用工具,并组织执行,这个自动决策执行的过程,就是由 agent 完成的。
agent 会自己思考、分步骤执行,非常适合复杂任务处理,后续我们也会深入介绍如何通过 LangChain 创建一个完整的 agent,自动协调多个工具完成复杂任务。
对于那些不支持工具调用的大模型,也可以根据提示词将可选的工具和调用方法传递给大模型,但是大模型的预测有很强的不确定性,返回结果的准确率会显著下降。
RAG检索
在一些LLM的使用场景,需要使用一些特定的文档让LLM根据这些文档的内容进行回复,而这些特定的文档通常不在LLM的训练数据中,此时RAG检索就有用武之地。
在LangChain中,可以读取文档作为大模型的知识库,来进行增强搜索,LangChain封装各种类型的文档读取器,可以将读取文档得到的数据,通过LangChain文档分割器对文档进行分割,通过文本嵌入模型对文本进行向量化,将文本的向量信息保存到向量数据库。
当用户向AI发起提问时,在向量数据库中检索出与提问相关的文档,然后与用户问题一起发送给大模型,这个过程就叫做RAG(检索增强生成,Retrieval-Augmented Generation),RAG 能让大模型回答特定领域的问答变得更加精准、实时,避免出现幻觉。