一.导入lxml包时的一些注意事项
上面这张图是lxml包的结构
这里可以复习一下Python的包和模块的知识:
- 模块(Model):一个.py文件就是一个模块,可以直接导入,导入后可以直接使用其中的函数、类等。通过import语句来导入模块
- 包(Package):一个包含多个模块的文件夹,通常还有一个__init__.py文件。导入包时,Python会自动执行__init__.py中的代码。init.py这个文件可以为空,也可以包含初始化代码或定义包级别的导入。通过点号(.)来访问包中的模块
- 子模块(Submodel):包中的模块就是子模块。例如:lxml包中有etree
- 子包(Subpackage):包下面的文件夹称为子包(子包下通常也有一个__init__.py文件)。通过点号(.)来访问子包,然后再通过点号访问子包中的模块
包、模块、库之间的区别与联系
区别:
| 概念 | 定义 | 级别 | 例子 |
|---|---|---|---|
| 模块 | 一个.py文件 |
文件级别 | mymodule.py |
| 包 | 包含多个模块和__init__.py的目录 |
目录级别 | mypackage/ |
| 库 | 一组相关功能的模块和包的集合 | 集合级别 | numpy、requests |
联系:
-
模块是组织代码的基本单位。
-
包是组织模块的方式,可以包含多个模块和子包。
-
库是由多个包和模块组成的集合,提供一系列相关功能。
注意:
-
在Python中,库不是一个严格的语言概念,而是一个通用的说法。通常我们说的库可能是一个包(如
requests)或者多个包组成的集合(如SciPy生态系统)。 -
有时库和包这两个词会被混用,比如我们常说"安装一个库"和"安装一个包"意思差不多,都是指通过pip安装一个软件包(可能是一个包,也可能是多个包和依赖的集合)。
实际项目中的结构
一个典型的库项目可能的结构:
mylibrary/
setup.py
mylibrary/
__init__.py
module1.py
module2.py
subpackage1/
__init__.py
module3.py
subpackage2/
__init__.py
module4.py当用户安装这个库后,就可以这样使用:
python
from mylibrary import module1
from mylibrary.subpackage1 import module3注意:上面最顶层的mylibrary只是一个项目根目录,不是包
通过上面的一些回顾,可以知道如果直接import lxml,然后使用lxml.html会报错,因为html是一个子包,而在lxml包下面的__init__.py中并没有设置导入lxml时对html子包进行初始化,所以就不能使用这种错误的方式了
应该直接导入需要的子包(子模块),如:from lxml import html
更多的,更完整详细的关于包和模块的知识有需要可以额外地去学习,这里只需要知道为什么不能直接import lxml后使用lxml.html来进行编程了、
二.lxml库的介绍和初步使用
lxml库是Python中处理XML和HTML数据的强大工具,lxml 是 Python 中一个高性能、功能丰富的 XML 和 HTML 处理库 ,它结合了 libxml2 和 libxslt 这两个 C 语言库的速度优势,并提供了 Pythonic 的 API 接口
函数和方法快查
为了让你能快速上手,下面这个表格汇总了其最常用的一些函数和方法:
| 类别 | 函数/方法 | 主要用途 |
|---|---|---|
| 📥 解析与加载 | etree.XML() / etree.fromstring() |
从XML字符串解析并返回根节点。 |
etree.HTML() / html.fromstring() |
从HTML字符串解析,能自动补全缺失标签,返回根节点。 | |
etree.parse() |
从文件 或类文件对象 解析XML/HTML,返回一个 ElementTree 对象。 |
|
html.document_fromstring() / html.fragment_fromstring() |
分别用于将字符串作为完整文档 或HTML片段解析。 | |
| 📤 序列化与输出 | etree.tostring() |
将元素或其子树序列化为XML/HTML的字节字符串 。支持 pretty_print 美化格式。 |
etree.tounicode() |
将元素序列化为Unicode字符串。 | |
| 🔧 元素创建与操作 | etree.Element() |
创建一个新的XML元素节点。 |
etree.SubElement() |
为指定父元素创建一个新的子元素。 | |
element.get() / element.set() |
获取 或设置元素的属性值。 | |
element.append() / element.addnext() / element.addprevious() |
向元素内部追加 、在其之后添加 或之前添加兄弟节点。 | |
element.text 和 element.tail |
获取或设置元素的直接文本内容,以及元素结束标签后的后续文本。 | |
| 🔍 导航与查询 | element.xpath() |
使用XPath表达式查询和选择节点,返回匹配的列表。这是非常强大的数据提取工具。 |
element.find() / element.findall() |
使用类XPath路径 (不支持完整XPath)查找第一个 或所有匹配的子元素。 | |
element.iter() / element.iterfind() |
迭代查找匹配给定标签的所有子孙元素或根据路径表达式迭代查找。 | |
element.getparent() / element.getchildren() |
获取元素的父节点 或所有直接子节点列表。 | |
element.getnext() / element.getprevious() |
获取下一个 或上一个兄弟元素。 | |
| 🧹 文档清理 | etree.strip_elements() / etree.strip_tags() |
移除 文档中指定的元素或标签,但保留其文本内容(如tail文本)。 |
主要用途和功能
1. XML/HTML 解析
-
解析各种格式:可以解析格式良好或格式不太好的 HTML/XML
-
多种解析器:支持多种解析方式,如 HTML 解析器、XML 解析器
-
编码处理:自动处理文档编码问题
2. XPath 查询
-
高效提取数据:使用 XPath 表达式精确定位和提取数据
-
复杂查询:支持复杂的 XPath 查询和条件筛选
3. 数据提取(Web 爬虫)
-
网页抓取:最常用于网络爬虫中提取结构化数据
-
元素定位:通过标签名、类名、ID、属性等定位元素
4. XML/HTML 生成和修改
-
创建文档:可以构建新的 XML/HTML 文档
-
修改内容:添加、删除、修改元素和属性
5. XSLT 转换
-
文档转换:使用 XSLT 样式表转换 XML 文档
-
格式转换:将 XML 转换为 HTML、PDF 或其他格式
基本使用:
1.解析HTML并提取信息
得到python之禅页面的标题:
python
from lxml import html
import requests
url = 'https://peps.python.org/pep-0020/'
headers = {
'User-Agent':"Mozilla/5.0 (iPhone; CPU iPhone OS 18_5 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/18.5 Mobile/15E148 Safari/604.1"
}
response = requests.get(url,headers=headers)
html_str = response.text
#lxml.html是lxml包中专门用于处理HTML文档的子模块
#html.fromstring函数将HTML字符串或字节内容解析为可查询的文档树对象
tree = html.fromstring(html_str)
# print(type(tree)) # <class 'lxml.html.HtmlElement'>
# print(tree) # <Element html at 0x23a719482d0>
#html.tostring函数将解析后的HTML文档树重新转换为HTML字符串格式
output = html.tostring(tree,pretty_print=False)
# print(output)
# 使用XPath提取页面标题和所有链接
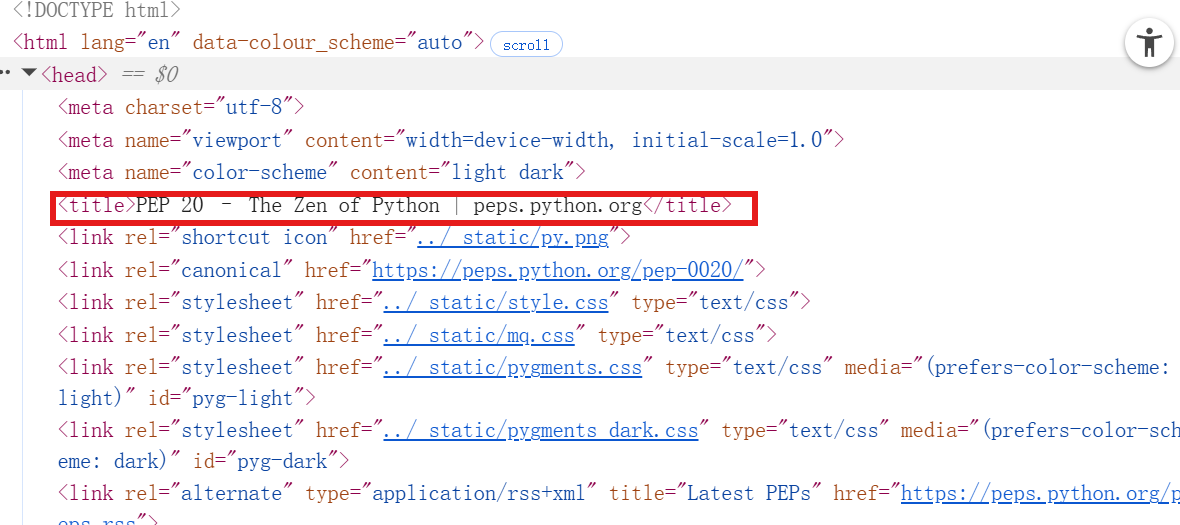
title = tree.xpath('//title/text()')[0] # 提取标题文本
print(title)输出:PEP 20 -- The Zen of Python | peps.python.org
三.XPath语法
XPath 使用路径表达式在 XML/HTML 文档中导航和选择节点
1. 节点选择基础
节点类型
-
元素节点 :
<element> -
属性节点 :
attribute="value" -
文本节点:元素中的文本内容
-
注释节点 :
<!-- comment --> -
根节点:文档的根
基本路径表达式
| 表达式 | 描述 | 示例 |
|---|---|---|
节点名 |
选择所有该名称的子节点 | book |
/ |
从根节点开始选择 | /bookstore |
// |
从任意位置选择 | //book |
. |
选择当前节点 | ./title |
.. |
选择父节点 | ../price |
@ |
选择属性 | @lang |
2. 谓语(条件筛选)
谓语用于对节点集进行筛选,写在方括号 [] 中:
位置谓语
python
//book[1] # 第一个 book 元素
//book[last()] # 最后一个 book 元素
//book[last()-1] # 倒数第二个 book 元素
//book[position()<3] # 前两个 book 元素属性谓语
python
//book[@category] # 有 category 属性的 book
//book[@category='web'] # category 属性等于 'web'
//book[@category!='web'] # category 属性不等于 'web'
//book[not(@category)] # 没有 category 属性的 book内容谓语
python
//title[text()='XML Guide'] # 文本内容精确匹配
//title[contains(text(),'XML')] # 文本包含 'XML'
//book[price>35] # price 元素值大于 35
//book[author='John'] # author 子元素等于 'John'3. 通配符
| 通配符 | 描述 | 示例 |
|---|---|---|
* |
匹配任何元素节点 | //book/* |
@* |
匹配任何属性节点 | //book/@* |
node() |
匹配任何类型的节点 | //book/node() |
7. 完整示例
假设有以下 XML 文档:
XML
<bookstore>
<book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<year>2003</year>
<price>49.99</price>
</book>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
</bookstore>复杂查询示例
XML
# 选择价格大于 35 的所有书的标题
//book[price>35]/title
# 选择包含 "Italian" 的书的作者
//book[contains(title,'Italian')]/author
# 选择第一个 book 元素的所有属性
//book[1]/@*
# 选择所有有 lang 属性的 title 元素
//title[@lang]
# 选择 category 为 'cooking' 且价格小于 40 的书
//book[@category='cooking' and price<40]
# 选择所有书的平均价格
sum(//book/price) div count(//book)
# 使用轴选择兄弟元素
//author[text()='Giada De Laurentiis']/following-sibling::year