📢 本文介绍一个全新的开源 Git 代码统计工具,支持多账户统计、智能工作量计算、缓存加速、导出报告等功能,完美解决了团队协作中代码量统计的各种痛点。
🤔 写在前面:为什么要做这个工具?
作为开发者,你是否遇到过这些场景:
痛点 1:老板要看开发成果
"这个月你写了多少代码?"
"这个项目各个成员的贡献度怎么样?"
"某某离职了,他的代码量有多少?"
传统方案的问题:
git log --author只能看提交记录,看不到具体代码量- GitHub Insights 只能看仓库整体,无法按人员拆分
- GitStats 等工具配置复杂,输出不直观
痛点 2:多账户统计困难
很多开发者有多个 Git 账户:
- 公司电脑:
zhangsan@company.com - 家里电脑:
zhangsan@gmail.com - 临时账户:
zs
传统方案: 只能一个个查,然后手动加总 😫
痛点 3:统计逻辑不合理
传统的 新增 - 删除 = 净增 存在严重问题:
python
# 场景:重构代码
原来 1000 行代码
新增 200 行
删除 300 行
净增 = -100 ❌ # 负数?工作量为 0?
# 实际上:这是一次有价值的代码优化!删除代码也是工作量! 但传统统计方式完全忽略了这一点。
痛点 4:统计速度慢
大型项目统计可能需要 10+ 分钟,每次调整参数都要重新等待 😤
基于这些痛点,我开发了这个 Git 代码统计工具,一次性解决所有问题!
✨ 核心功能
1️⃣ 双维度统计:累计工作量 + 当前代码量
📈 累计工作量(Historical Workload)
基于 git diff,统计历史提交中的所有变更:
- ✅ 反映开发者的真实工作量
- ✅ 包括已删除的代码
- ✅ 适合评估贡献度、绩效考核
📊 当前代码量(Current Codebase)
基于 git blame,统计当前代码库中每行代码的作者:
- ✅ 反映当前活跃的代码
- ✅ 适合维护性评估
- ✅ 了解代码库的构成
示例对比:
张三的统计:
累计工作量:15000 行(包括历史上写过但后来被删除的代码)
当前代码量:8000 行(现在代码库中还存活的代码)
➡️ 说明:张三做了很多工作,包括重构和优化2️⃣ 智能工作量计算算法
传统的 新增 - 删除 完全不合理,我们采用了智能算法:
python
# 根据文件变更类型采用不同策略
if 新建文件:
工作量 = 新增 - 删除
elif 删除文件:
工作量 = 0 # 删除整个文件不算工作量
elif 重命名文件:
工作量 = 新增 - 删除
else: # 修改文件 ⭐ 核心
工作量 = 新增 × 0.9 + 删除 × 0.1为什么是 0.9 和 0.1?
- 新增代码 = 90% 权重(核心工作量)
- 删除代码 = 10% 权重(体现重构、优化的价值)
实际效果:
ini
场景 1:重构优化
新增 200 行,删除 300 行
传统算法:-100(工作量为 0)❌
智能算法:200×0.9 + 300×0.1 = 210 ✅
场景 2:新功能开发
新增 500 行,删除 50 行
传统算法:450
智能算法:500×0.9 + 50×0.1 = 455 ✅
场景 3:代码优化(删除冗余)
新增 0 行,删除 200 行
传统算法:-200(工作量为 0)❌
智能算法:0×0.9 + 200×0.1 = 20 ✅3️⃣ 多账户统计
一次性统计多个账户,自动汇总:
java
输入:
wangzc
jusz@company.com
xucongle
huyulin@gmail.com
输出:
✅ 自动识别用户名和邮箱
✅ 支持详细模式(每个账户独立统计)
✅ 支持汇总模式(合并统计)详细模式效果:
- 每个账户独立的文件清单
- 每个账户的代码类型分布(Java、Python、前端等)
- 账户间的贡献度对比
4️⃣ 过滤合并提交(重要!)
发现的问题:
markdown
张三执行了 git merge dev
- 合并提交包含 100+ 个文件
- 但这些文件不是张三写的!
- 如果统计合并提交,张三的代码量会虚高 ❌解决方案:
python
# 自动跳过合并提交(有多个父提交的提交)
if len(commit.parents) > 1:
return # 跳过✅ 只统计开发者真正写的代码,不统计合并操作!
5️⃣ 智能缓存机制
大型项目统计耗时?没问题!
缓存策略:
首次统计:10 分钟 ⏱️
再次打开:0.5 秒 ⚡(从缓存读取)
缓存有效条件:
✅ 仓库路径相同
✅ 分支相同
✅ 用户列表相同
✅ 统计模式相同
✅ 最后一次提交相同缓存位置:
- Windows:
C:\Users\<用户名>\.git-counter-cache\ - macOS/Linux:
~/.git-counter-cache/
✅ 跨电脑、跨项目位置都能正确读取缓存!
6️⃣ 多格式报告导出
📊 HTML 报告(强烈推荐!)
特性:
- 🎨 现代化的 UI 设计
- 📑 多 Tab 页面(汇总、各账户、对比)
- 📈 Chart.js 可视化图表
- 📁 详细的文件清单
- 🔍 支持浏览器内搜索、排序
适合场景: 给老板、PM 看,直观、专业
📑 Excel 报告
特性:
- 📊 多 Sheet 页面(汇总、各账户、对比)
- 🎨 自动列宽、样式美化
- 📈 可进一步用 Excel 分析数据
适合场景: 需要二次加工、数据分析
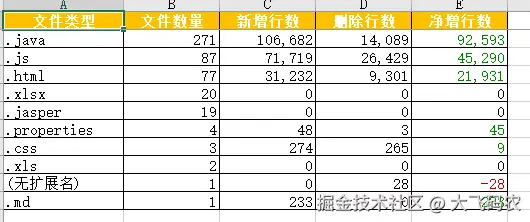
7️⃣ 文件类型分类统计
自动识别 20+ 种文件类型:
python
代码类别:
✅ 后端代码:Java、Python、Go、C++、C#、PHP...
✅ 前端代码:Vue、React、JavaScript、TypeScript、HTML、CSS...
✅ 移动端:Swift、Kotlin、Dart...
✅ 数据库:SQL
✅ 配置文件:XML、JSON、YAML、Properties...
✅ 文档:Markdown、TXT
✅ 其他:Shell、Dockerfile...效果:
yaml
张三的代码分布:
Java 代码:8500 行(累计)/ 6200 行(当前)
Vue 前端:3200 行(累计)/ 2800 行(当前)
SQL 脚本:450 行(累计)/ 380 行(当前)
配置文件:280 行(累计)/ 220 行(当前)8️⃣ 智能过滤
过滤逻辑:
python
# 只显示有实际贡献的文件
if added > 0 or deleted > 0 or current > 0:
显示该文件
else:
过滤掉(避免噪音)✅ 报告清爽,没有无关文件!
🚀 快速开始
方式 1:使用打包好的 EXE(Windows)
- 下载
Git代码统计工具.exe - 双击运行
- 选择仓库,输入账户,开始统计!
✅ 无需安装 Python 环境!
方式 2:从源码运行
bash
# 1. 克隆项目
git clone https://gitee.com/gaoerfu/git-counter.git
cd git-counter
# 2. 创建虚拟环境
python -m venv venv
venv\Scripts\activate # Windows
# source venv/bin/activate # macOS/Linux
# 3. 安装依赖
pip install -r requirements.txt
# 4. 运行 GUI 版本
python git_counter_gui.py
# 或运行命令行版本
python git_counter.py --repo <仓库路径> --user <用户名>📸 效果展示
主界面
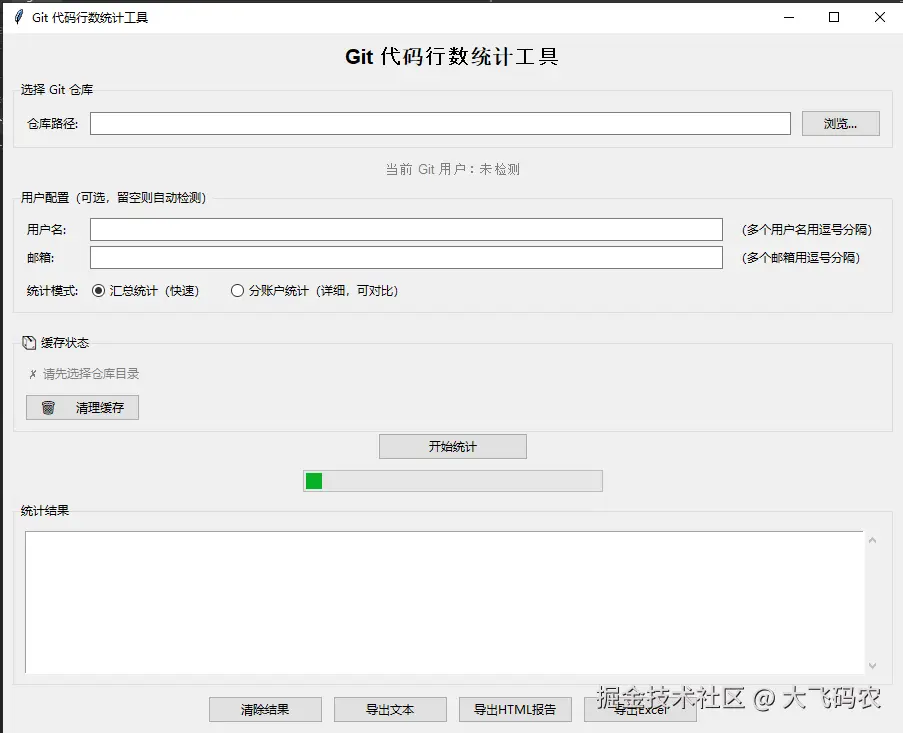
功能区域:
- 📁 仓库选择
- 👤 当前 Git 用户信息(自动识别)
- 📝 多账户输入(支持用户名、邮箱)
- 🔄 缓存状态(加载缓存 / 重新统计)
- 📊 统计模式(快速/详细)
- ▶️ 开始分析按钮
- 📋 实时日志输出
- 📤 导出报告按钮
HTML 报告示例
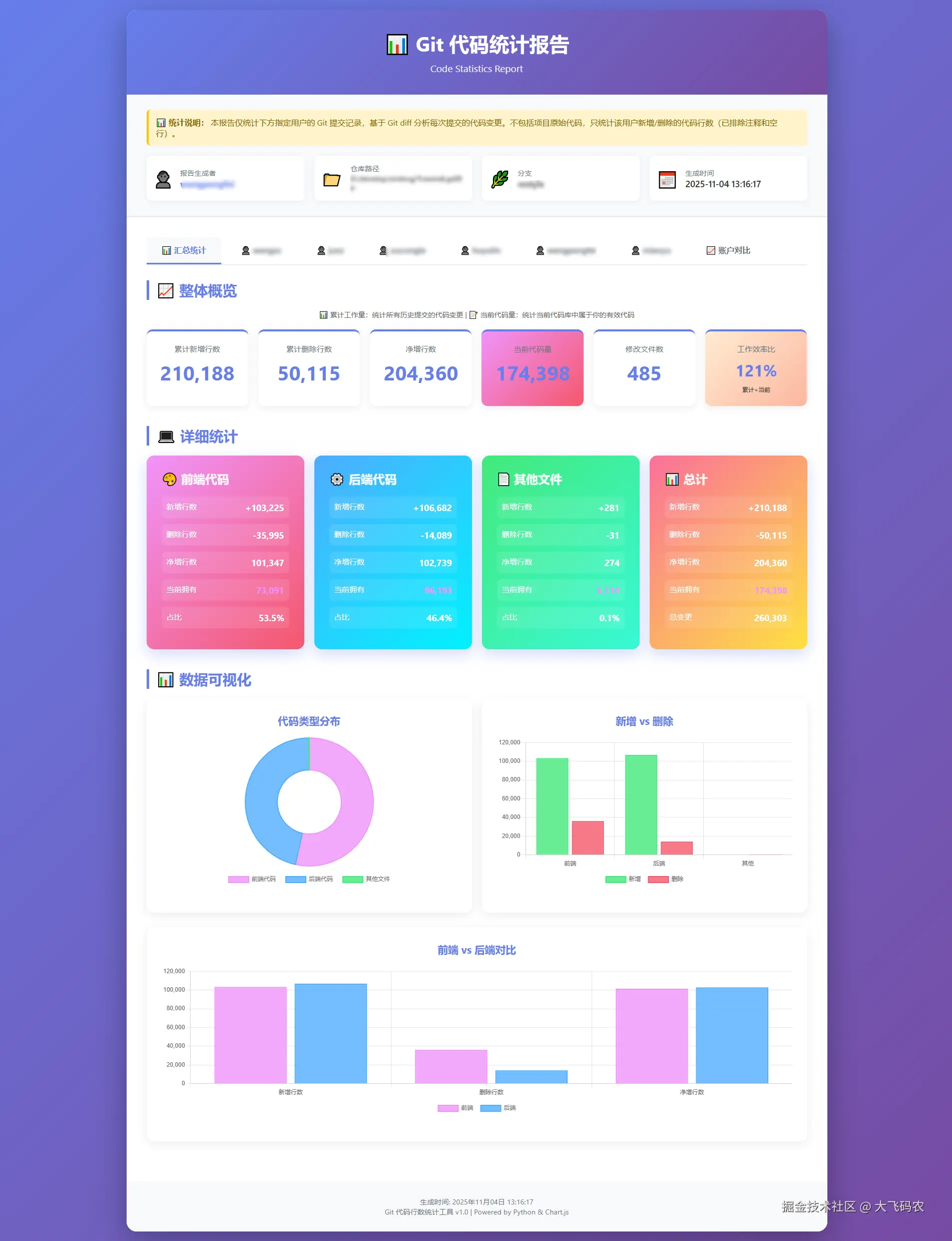
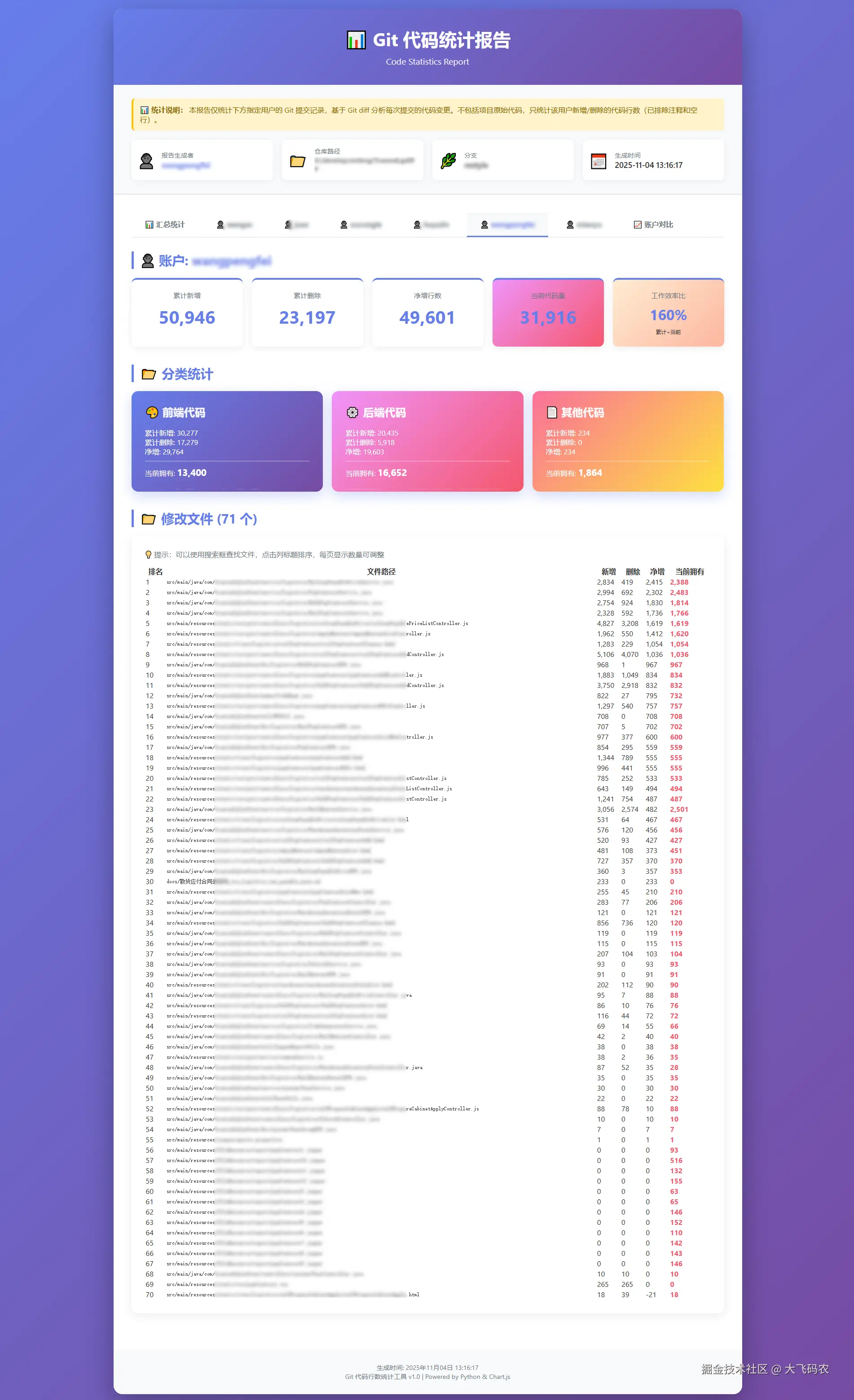
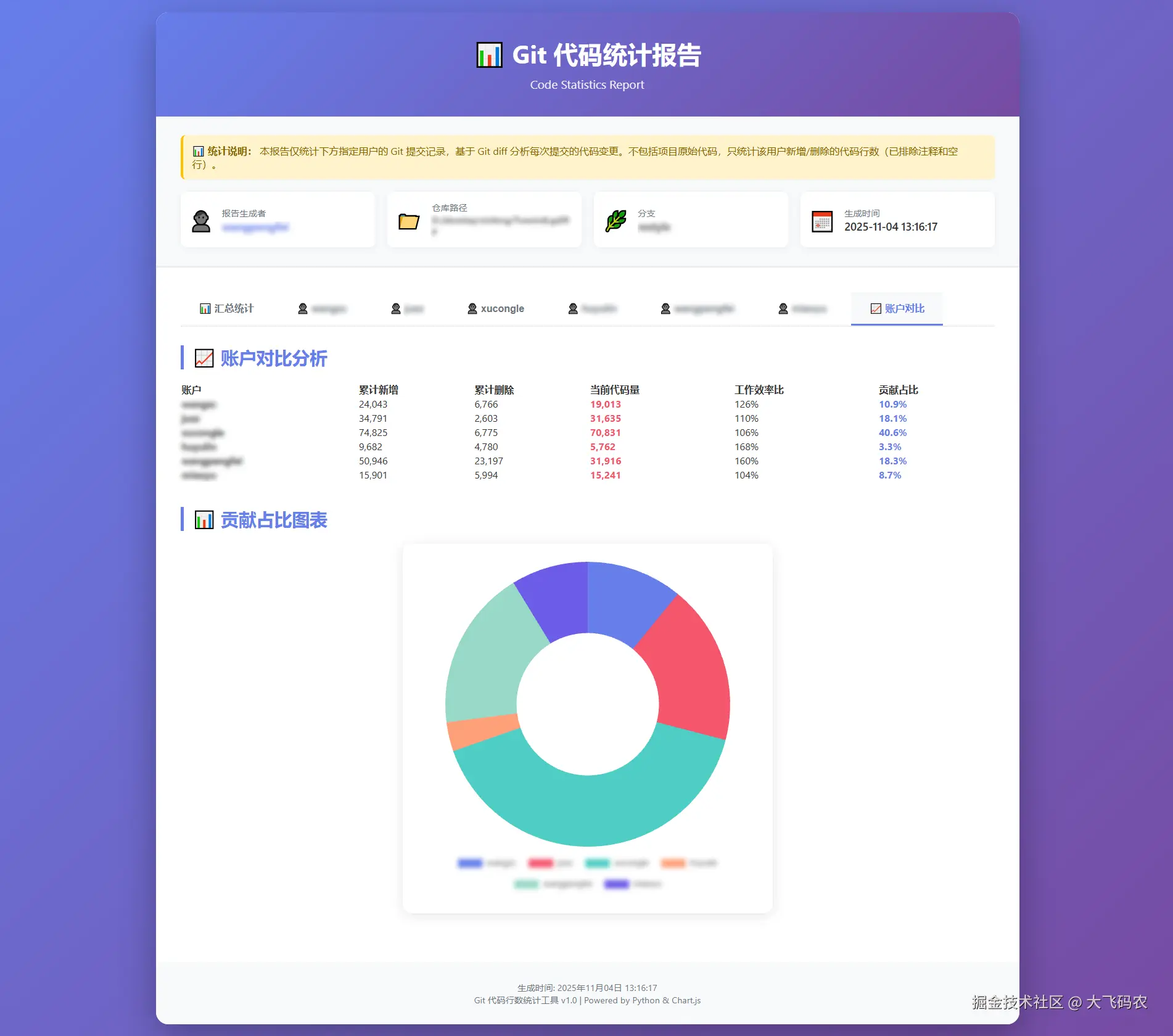
Excel 报告示例
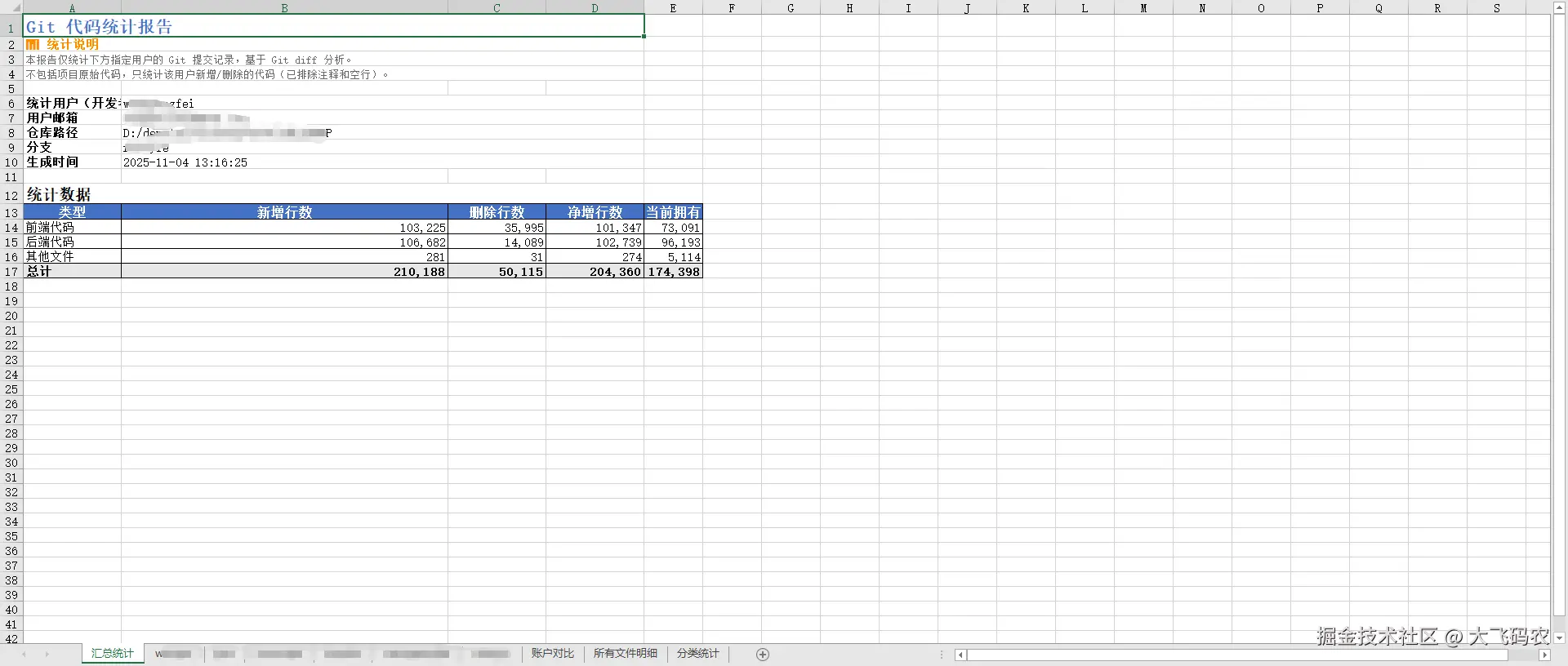
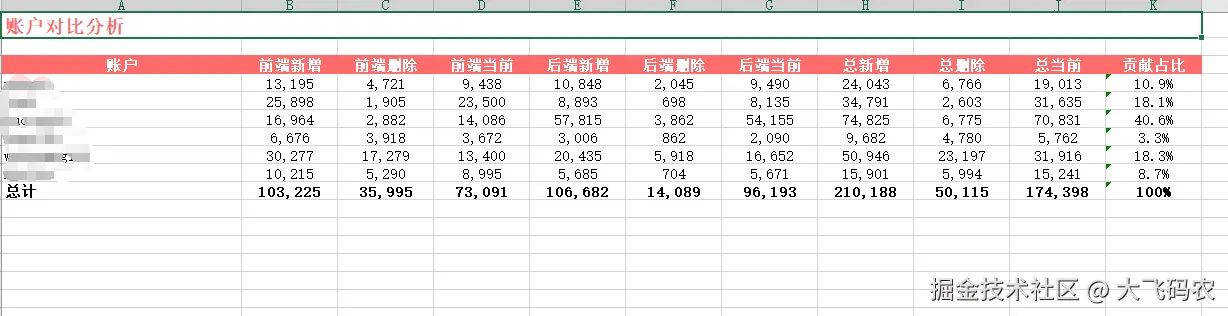
🎯 使用场景
场景 1:团队绩效评估
需求: 统计本季度各成员的代码贡献
操作:
markdown
1. 选择项目仓库
2. 切换到目标分支(如 dev)
3. 输入所有成员的账户(用户名或邮箱)
4. 选择"详细模式"
5. 点击"开始分析"
6. 导出 HTML 报告得到:
- ✅ 每个成员的详细统计
- ✅ 成员间的贡献度对比图表
- ✅ 每个成员的代码类型分布
- ✅ 详细的文件清单
场景 2:个人工作总结
需求: 年终总结,展示自己一年的工作成果
操作:
markdown
1. 选择项目仓库
2. 只输入自己的账户(可输入多个,如公司邮箱+个人邮箱)
3. 选择"快速模式"(汇总多个账户)
4. 点击"开始分析"
5. 导出 Excel 报告得到:
- ✅ 全年累计代码量
- ✅ 当前代码库中的活跃代码量
- ✅ 各种编程语言的代码量
- ✅ 可视化图表(放进 PPT)
场景 3:代码审计
需求: 了解某个项目的代码构成和维护者
操作:
markdown
1. 选择项目仓库
2. 不输入账户(或输入所有参与者)
3. 选择"详细模式"
4. 导出 HTML 报告得到:
- ✅ 当前代码库中各成员的活跃代码量
- ✅ 了解谁是主要维护者
- ✅ 代码类型分布
- ✅ 文件级别的作者信息
场景 4:项目交接
需求: 离职员工的代码量统计,方便交接
操作:
markdown
1. 选择项目仓库
2. 输入离职员工的账户
3. 选择"详细模式"
4. 导出 Excel 报告得到:
- ✅ 该员工的历史贡献量
- ✅ 当前代码库中该员工的代码量(需要交接的部分)
- ✅ 详细的文件清单(便于分配接手人)
🔧 技术实现
技术栈
markdown
核心:
- GitPython:Git 仓库操作
- Tkinter:GUI 界面
统计逻辑:
- git diff:累计工作量统计
- git blame:当前代码量统计
报告生成:
- openpyxl:Excel 导出
- Chart.js:HTML 图表
- 自研 HTML 模板
打包:
- PyInstaller:打包成 EXE核心算法
1. 累计工作量统计(基于 git diff)
python
def analyze_commit(commit):
# 跳过合并提交
if len(commit.parents) > 1:
return
# 获取 diff
parent = commit.parents[0] if commit.parents else None
diffs = parent.diff(commit, create_patch=True)
for diff_item in diffs:
# 统计新增/删除行数
added, deleted = count_diff_lines(diff_item.diff)
# 根据文件类型计算工作量
if diff_item.new_file:
workload = added - deleted
elif diff_item.deleted_file:
workload = 0
elif diff_item.renamed_file:
workload = added - deleted
else: # 修改文件
workload = int(added * 0.9 + deleted * 0.1)
stats['total'] += workload关键点:
- ✅ 过滤合并提交(避免虚高)
- ✅ 区分文件类型(新建、修改、删除、重命名)
- ✅ 智能工作量算法(体现删除代码的价值)
2. 当前代码量统计(基于 git blame)
python
def analyze_current_code(repo, user_names, user_emails):
# 遍历工作区所有文件
for root, dirs, files in os.walk(repo.working_dir):
if '.git' in root:
continue
for file in files:
# 使用 git blame 分析每一行
blame_data = repo.blame('HEAD', file_path)
for commit, lines in blame_data:
# 检查是否是目标用户
if commit.author.name in user_names or \
commit.author.email in user_emails:
# 统计该用户的行数
stats['current'] += len(lines)关键点:
- ✅ 分析当前工作区的所有文件
- ✅ 逐行识别作者
- ✅ 支持多账户匹配
3. 缓存机制
python
class CacheManager:
def generate_cache_filename(self, repo_path, branch, users, stat_mode):
# 规范化路径(确保跨平台一致)
normalized_path = os.path.abspath(repo_path).replace('/', '\\')
# 生成唯一哈希
path_hash = hashlib.md5(normalized_path.encode()).hexdigest()[:8]
users_hash = hashlib.md5(','.join(users).encode()).hexdigest()[:8]
return f"cache_{path_hash}_{users_hash}_{branch}_{stat_mode}.json"
def validate_cache(self, cache_data, current_params):
# 验证缓存有效性
return (
cache_data['metadata']['repo_path'] == current_params['repo_path'] and
cache_data['metadata']['branch'] == current_params['branch'] and
cache_data['metadata']['users'] == current_params['users'] and
cache_data['metadata']['last_commit_id'] == current_params['last_commit_id']
)关键点:
- ✅ 路径规范化(确保一致性)
- ✅ 多维度验证(仓库、分支、用户、提交)
- ✅ 存储在用户目录(跨项目位置)
💡 设计亮点
1. 用户体验优化
自动识别 Git 用户
markdown
打开仓库后,自动读取:
- 本地 Git 配置(user.name、user.email)
- 全局 Git 配置
- 显示在界面上,无需手动输入实时进度反馈
csharp
[2025-01-15 10:23:45] 开始分析...
[2025-01-15 10:23:46] 账户1/6: 处理提交 10/523
[2025-01-15 10:23:47] 账户1/6: 处理提交 20/523
...
[2025-01-15 10:25:12] ✓ 所有账户分析完成!智能缓存提示
ini
✅ 发现缓存(生成于 2025-01-15 10:23:45)
[加载缓存] [重新统计] [清除所有缓存]2. 代码质量
异常处理
python
# 所有 Git 操作都有异常处理
try:
diffs = parent.diff(commit, create_patch=True)
except Exception as e:
logging.error(f"Diff 失败: {e}")
return编码兼容
python
# 支持各种文件编码
diff_text = diff_item.diff.decode('utf-8', errors='ignore')跨平台支持
python
# 路径处理兼容 Windows/macOS/Linux
cache_dir = os.path.join(os.path.expanduser("~"), ".git-counter-cache")3. 性能优化
增量处理
python
# 每处理 10 个提交更新一次进度
if i % 10 == 0:
update_progress(i, total)数据结构优化
python
# 使用 defaultdict 避免重复判断
from collections import defaultdict
file_stats = defaultdict(lambda: {'added': 0, 'deleted': 0, 'current': 0})缓存策略
python
# 缓存存储完整统计结果
{
'metadata': {...},
'stats': {...},
'file_stats': {...},
'per_user_stats': {...}
}🤝 贡献指南
欢迎提交 Issue 和 Pull Request!
贡献方向:
- 🐛 Bug 修复
- ✨ 新功能建议
- 📖 文档完善
- 🌍 国际化支持
- 🎨 UI 优化
开发环境搭建:
bash
git clone https://github.com/your-username/git-counter.git
cd git-counter
python -m venv venv
venv\Scripts\activate
pip install -r requirements.txt📋 Roadmap
v2.2(计划中)
- 支持 Git 仓库远程 URL 输入
- 支持时间范围筛选(如近 3 个月)
- 支持分支对比统计
- 支持团队统计(多仓库汇总)
v3.0(未来)
- Web 版本(在线使用)
- API 接口(集成到 CI/CD)
- 数据库存储(长期统计分析)
- 更多可视化图表
❓ 常见问题
Q1:统计速度慢怎么办?
A:
- 首次统计会较慢(取决于项目大小)
- 再次打开会自动加载缓存(秒开)
- 如果仓库特别大,建议选择特定分支统计
Q2:多账户怎么输入?
A:
css
一行一个,支持混合输入:
zhangsan
lisi@company.com
wangwuQ3:统计结果为 0?
A: 可能的原因:
- 输入的账户名/邮箱不匹配
- 该账户在当前分支没有提交
- 选择的仓库路径不正确
解决:
- 使用
git log --author=<用户名>验证用户名是否正确 - 检查当前分支是否正确
- 工具会自动显示当前仓库的 Git 用户,可参考
Q4:缓存存在哪里?
A:
- Windows:
C:\Users\<用户名>\.git-counter-cache\ - macOS/Linux:
~/.git-counter-cache/ - 可在 GUI 中点击"清除所有缓存"按钮清空
Q5:导出的报告在哪里?
A:
- 默认保存在仓库根目录
- HTML:
git_stats_report_<时间戳>.html - Excel:
git_stats_detailed_<时间戳>.xlsx
Q6:支持 SVN 吗?
A: 目前只支持 Git 仓库。SVN 的统计逻辑不同,可能会在未来版本支持。
📝 开源协议
MIT License
🙏 致谢
感谢以下开源项目:
- GitPython - Git 操作核心库
- openpyxl - Excel 文件处理
- Chart.js - 图表可视化
- PyInstaller - Python 打包工具
🔗 相关链接
- 🏠 项目主页:gitee.com/gaoerfu/git...
- 📖 完整文档:README.md
- 🐛 问题反馈:Issues
- 💬 讨论区:Discussions
🎉 总结
这是一个真正实用的 Git 代码统计工具,解决了团队协作中的实际痛点:
✅ 智能算法 - 删除代码也算工作量
✅ 多账户支持 - 一次性统计多个账户
✅ 双维度统计 - 累计工作量 + 当前代码量
✅ 缓存加速 - 大型项目秒开
✅ 报告导出 - HTML、Excel 多格式
✅ 过滤合并提交 - 只统计真实代码
✅ 开箱即用 - GUI 界面,无需命令行
如果你也被代码统计困扰过,不妨试试这个工具!
欢迎 Star ⭐、Fork 🍴、PR 🤝!
如果觉得有用,请点赞、收藏、分享!👍
我是 大飞,持续分享实用的开发工具和技术文章,欢迎关注! 🚀