k8s --- Intro
- [k8s出现的俩个前提 --- 容器化和微服务](#k8s出现的俩个前提 --- 容器化和微服务)
- [为什么需要k8s --- 微服务带来的问题](#为什么需要k8s --- 微服务带来的问题)
- k8s的基本架构
-
- [两大核心部分之一: 控制平面(Control Plane)](#两大核心部分之一: 控制平面(Control Plane))
- [两大核心部分之一: 工作节点(Node)](#两大核心部分之一: 工作节点(Node))
k8s出现的俩个前提 --- 容器化和微服务
什么是容器化
- 容器化是一种操作系统级别的虚拟化技术,其核心目标是将应用程序及其全部依赖项(库、环境变量、配置文件等)打包在一个标准化、轻量级、可移植的镜像中,并在一个隔离的"容器"进程中运行.
场景: 一个团队开发了一个网站,现在需要部署到服务器上。
- 没有容器化时:
- 运维人员需要登录服务器,检查操作系统版本、安装特定版本的 Python(比如 3.9)、安装项目依赖包(比如 Django 4.2)。
- 他们需要配置正确的环境变量(比如数据库连接地址)。
- 如果这个服务器上还要运行另一个需要 Python 3.11 的网站,就会产生冲突,部署变得非常复杂和容易出错。这就是常说的"环境依赖"问题。
- 使用容器化后:
- 开发者将他们的网站代码、Python 3.9 运行时、Django 4.2 库以及所有配置文件,一起打包成一个单一的、标准化的 容器镜像。
- 运维人员要部署时,无需关心服务器本身是什么系统,只需要一条简单的命令,就能基于这个镜像启动一个 容器。
- 这个容器在服务器上是一个完全隔离的进程。它内部有自己的 Python 3.9 和 Django 4.2 环境,与服务器本身以及其他容器互不干扰。即使服务器上运行的是 Python 2.7,也完全不影响容器内的应用。
这个打包好的镜像可以轻松地在开发者的笔记本电脑、测试环境和生产服务器上以完全相同的方式运行,彻底解决了"在我这儿是好的,到你那儿怎么就错了"的问题。
容器化就是把一个应用和它需要的一切(从运行时环境到系统工具)统统打包在一起,让它可以在任何地方都能以一致、独立的方式运行起来
什么是微服务
- 在过去,很多应用是"单体架构"的,即所有功能都打包在一个大的应用程序里。部署时,只需要把这一个程序放在一台或几台服务器上运行即可。管理起来相对简单。
- 但随着业务复杂度的提升,微服务架构成为主流。一个大型应用被拆分成几十个甚至上百个小的、独立的服务(即微服务)。每个服务都可以用不同的技术栈,独立开发、部署和扩展
- 容器和微服务是天作之合。容器技术为微服务架构的实现提供了强大的支持。容器可以将微服务打包成独立的、可移植的单元,确保服务在不同环境中运行一致性,并且可以在不同的主机之间快速迁移。
为什么需要k8s --- 微服务带来的问题
微服务这种架构带来了巨大的灵活性,但也引入了新的复杂性 (包括但不限于):
- 服务数量爆炸: 手动管理这么多服务的部署、启动、停止、监控是不现实的。
- 依赖关系复杂: 服务之间需要相互发现和通信。
- 资源利用不均: 有的服务负载高,有的负载低,如何合理分配服务器资源?
- 故障排查困难: 一个请求可能经过多个服务,出问题时定位故障点非常麻烦
有需求就有改变,于是乎,市场上就出现了一批容器编排工具,典型的是 Swarm、Mesos 和 K8S。最后,K8S"击败"Swarm 和 Mesos,几乎成了当前容器编排的事实标准
Kubernetes(简称 K8s,其中8代指中间的8个字符),是一个全新的基于容器技术的分布式架构方案。K8S 最初是由 Google 开发的,后来捐赠给了 CNCF(云原生计算基金会,隶属 Linux 基金会)。K8S是 Google 十几年来大规模应用容器技术的经验积累和升华的重要成果,确切的说是 Google 一个久负盛名的内部使用的大规模集群管理系统------Borg的开源版本,其目的是实现资源管理的自动化以及跨数据中心的资源利用率最大化
k8s的基本架构
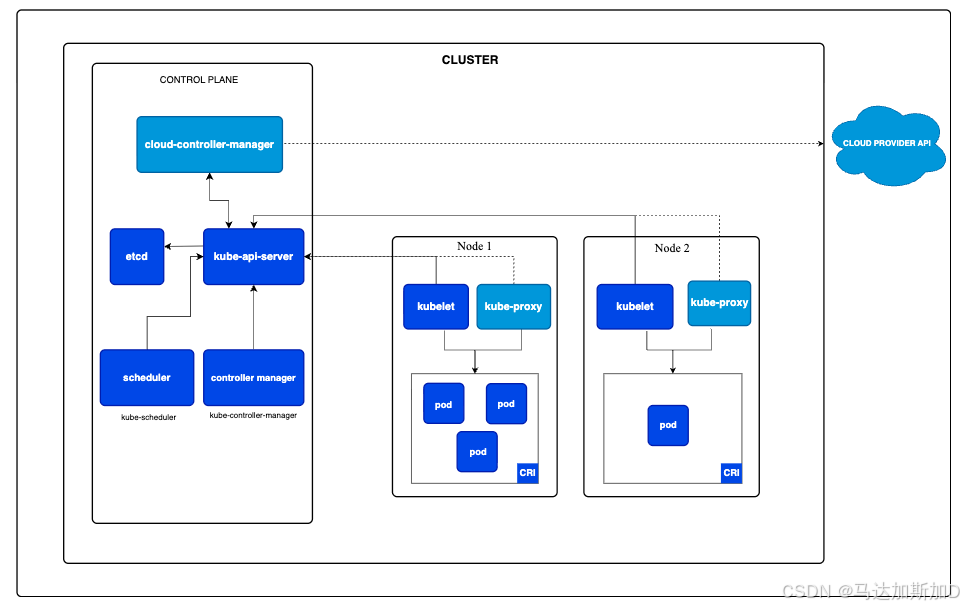
两大核心部分之一: 控制平面(Control Plane)
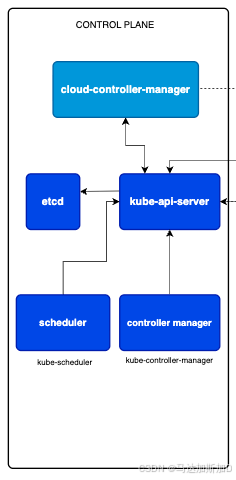
这是 Kubernetes 集群的"大脑"或"指挥中心"。Í它负责管理集群的所有全局决策,比如调度、检测和响应集群事件(例如,当一个 Pod 崩溃时启动新的副本)。通常运行在独立的、高可用的机器上。
kube-apiserver
- 这是集群的前端,是唯一直接与外部(用户、命令行工具 kubectl、节点等)通信的组件。
- 所有对集群的操作(创建、查询、更新、删除资源)都必须通过 API Server。它是整个系统的"网关"和"通信枢纽"。
etcd
- 这是一个高可用的键值存储数据库,可以看作是 Kubernetes 集群的"配置中心"或"记忆库"。
- 它持久化存储了集群的所有配置数据、状态和元数据(例如,有哪些 Pod、在哪个节点上、当前状态是什么)。
kube-scheduler
- 这是集群的"调度专家"。
- 它负责监视新创建的、还未被分配节点的 Pod,并根据资源需求、策略等因素,为 Pod 选择一个最合适的工作节点来运行。它只做决策,不负责实际启动 Pod。
kube-controller-manager
- 这是集群的"自动化运维中心", 实际的运维代码逻辑都在这里定义。
- 它内部运行着很多不同的控制器 (controller),每个控制器都是一个独立的调节循环,不断地将当前状态调整到期望状态。
- 例如:
- 节点控制器:负责在节点宕机时做出响应。
- 副本集控制器:负责保证指定数量的 Pod 副本始终在运行。
cloud-controller-manager
- 这是一个可选组件,当您的集群运行在公有云(如 AWS、Azure、GCP)上时才非常重要。
- 它允许您将集群与云服务商的 API 对接,从而管理云平台提供的负载均衡器、存储卷、节点(虚拟机)等资源
两大核心部分之一: 工作节点(Node)
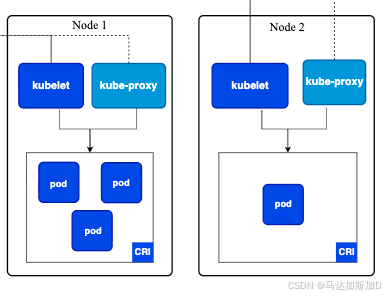
kubelet
- 这是节点上的"节点代理"或"监工"。
- 它负责与控制平面通信,接收指令(例如,需要在本节点运行一个 Pod),并确保本节点上的容器 都按照 Pod 规格说明健康地运行。
- 它是控制平面和节点上容器运行时之间的桥梁。
kube-proxy
- 这是节点上的"网络代理"和"负载均衡器"。
- 它负责维护节点上的网络规则,这些规则允许从集群内部或外部与 Pod 进行网络通信(例如,将发送到某个服务的请求转发到后端正确的 Pod 上)。
容器运行时(CRI)
- 这是真正负责运行容器的软件,例如 Docker、containerd、CRI-O 等。
- 它根据 kubelet 的指令来拉取镜像、启动和停止容器。图表中标注的 CRI 是 Kubernetes 与各种容器运行时交互的标准接口。
Pod
- Pod 是 Kubernetes 中能够创建和管理的最小部署单元。它是一个或多个容器的逻辑分组,这些容器共享网络和存储资源。
- 您的应用程序(例如 Web 服务器、数据库)就是在 Pod 的容器中运行的。
Kubernetes 的工作流程:
- 用户通过 kubectl 向 kube-apiserver 提交一个部署请求(例如,运行一个 Web 应用)。
- kube-scheduler 观察到此请求,为这个应用 Pod 选择一个合适的 Node。
- 该 Node 上的 kubelet 收到指令,通过 容器运行时 拉取镜像并启动容器。
- kube-proxy 确保这个新启动的 Pod 能够被网络访问。
*与此同时,kube-controller-manager 会持续监控,确保 Pod 的数量和状态始终符合用户的期望。- 所有集群的状态信息都被可靠地存储在 etcd 中。