1. 技术选型
| 组件 | 类型 |
|---|---|
| 大语言模型 | deepseek r1 |
| embedding模型 | bge-m3 |
| 框架选择 | spring ai 1.0.1(JDK 17以上) |
| 向量数据库 | pgvector |
2. 项目功能及接口文档
- 提供将法律法规文档通过embedding模型将知识导入向量库(导入文件格式只支持pdf和word)
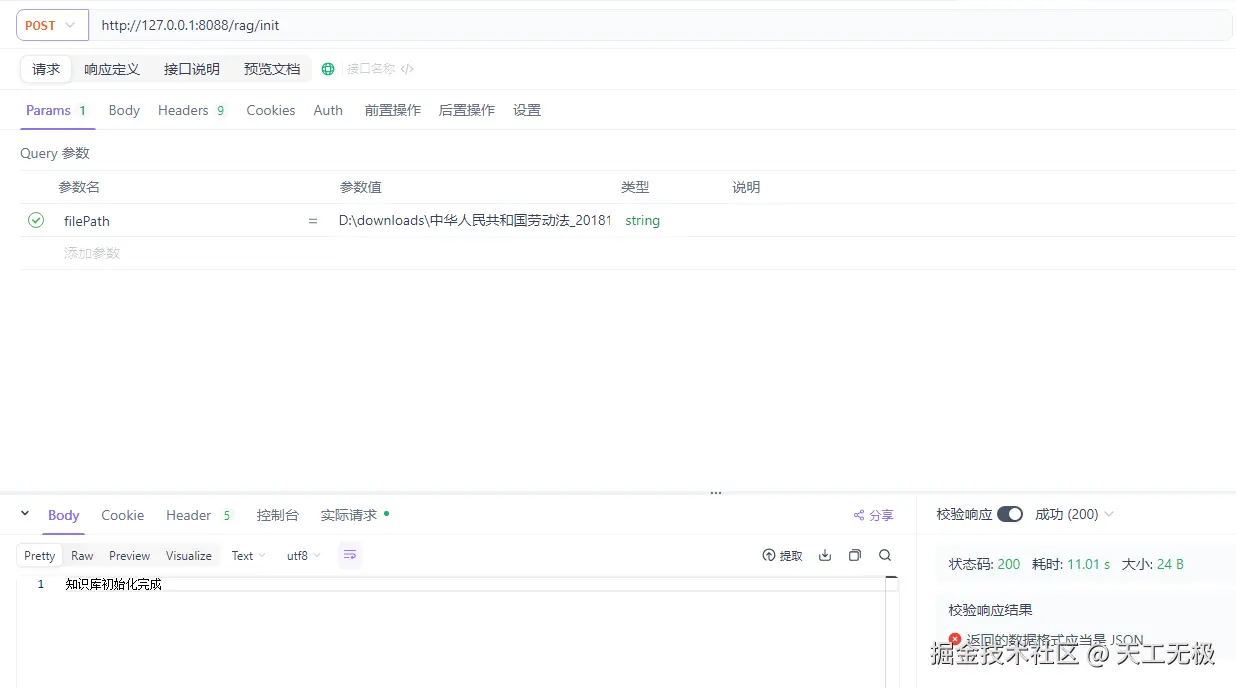
POST http://127.0.0.1:8088/rag/init?filePath=D:\downloads\中华人民共和国劳动法_20181229.docx
- 提供法律咨询问答的接口
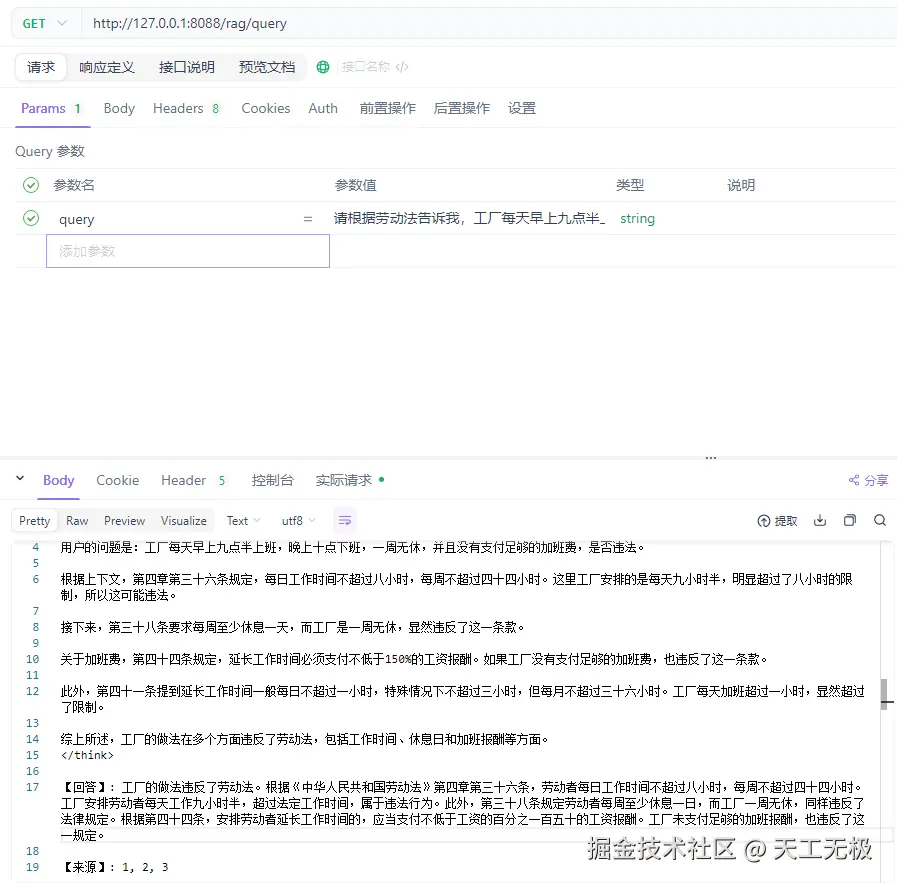
GET http://127.0.0.1:8088/rag/query?query=请根据劳动法告诉我,工厂每天早上九点上班,晚上十点下班,且没有支付足够响应报酬补偿的,一周无休,是否违法
3. 项目结构和依赖及配置项
pom.xml
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.4</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.sikaryofficial</groupId>
<artifactId>spring-ai-chat</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>17</java.version>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<!-- Spring Boot -->
<spring-boot.version>3.2.4</spring-boot.version>
<!-- Spring AI -->
<spring-ai.version>1.0.1</spring-ai.version>
<!-- Spring Alibaba AI -->
<spring-ai-alibaba.version>1.0.0.2</spring-ai-alibaba.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>${spring-ai-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-autoconfigure-model-openai</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-autoconfigure-model-chat-client</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>io.projectreactor.netty</groupId>
<artifactId>reactor-netty-http</artifactId>
</dependency>
<!-- <dependency>-->
<!-- <groupId>org.springframework.ai</groupId>-->
<!-- <artifactId>spring-ai-ollama-spring-boot-starter</artifactId>-->
<!-- <version>1.0.0-M6</version>-->
<!-- </dependency>-->
</dependencies>
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<releases>
<enabled>false</enabled>
</releases>
</repository>
<repository>
<id>aliyunmaven</id>
<name>aliyun</name>
<url>https://maven.aliyun.com/repository/public</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>public</id>
<name>aliyun nexus</name>
<url>https://maven.aliyun.com/repository/apache-snapshots</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>配置文件application.yml
yaml
server:
port: 8088
spring:
datasource:
url: jdbc:postgresql://192.168.232.194:5432/ai_data?currentSchema=public
username: postgres
password: ske@001
jpa:
show-sql: true
hibernate:
ddl-auto: update
properties:
hibernate:
format_sql: true
dialect: org.hibernate.dialect.PostgreSQLDialect
defer-datasource-initialization: true # 允许先创建扩展再初始化表
ai:
openai:
api-key: hismk
base-url: http://192.168.201.230:3045/
chat:
options:
model: deepseek-r1:32b_awq
max_tokens: 1024
temperature: 0.2
top_p: 0.9
embedding:
options:
model: bge-m3
base-url: http://192.168.201.250:11434
enabled: true
# 打印日志
logging:
level:
com.sikaryofficial: DEBUG提示词模板
makefile
当前日期:{current_date}
请基于以下上下文信息回答问题。请遵循以下规则:
1. 回答要专业、准确
2. 如果上下文不包含答案,请明确说明"根据提供的信息无法确定"
3. 使用中文回答
4. 保持回答简洁明了
上下文:
{context}
问题:{input}
请按以下格式回答:
【回答】: (你的回答)
【来源】: (指出回答基于哪些上下文片段,用1,2,3编号)4. 功能实现
a. 配置相关
- chatClient配置
kotlin
package com.sikaryofficial.ai.config;
/**
* @author : wuweihong
* @desc : TODO 请填写你的功能描述
* @date : 2025-11-04
*/
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ChatClientConfig {
@Bean
public ChatClient chatClient(ChatClient.Builder builder) {
return builder.defaultAdvisors(new SimpleLoggerAdvisor()).build();
}
}- 向量存储配置
kotlin
package com.sikaryofficial.ai.config;
/**
* @author : wuweihong
* @desc : TODO 请填写你的功能描述
* @date : 2025-11-04
*/
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.pgvector.PgVectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import javax.sql.DataSource;
@Configuration
public class VectorStoreConfig {
@Bean
public VectorStore vectorStore(EmbeddingModel embeddingClient, JdbcTemplate jdbcTemplate) {
return PgVectorStore.builder(jdbcTemplate, embeddingClient).dimensions(1024).vectorTableName("law_articles").build();
}
@Bean
public JdbcTemplate jdbcTemplate(DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
}- WebClient配置
kotlin
package com.sikaryofficial.ai.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.http.client.reactive.ReactorClientHttpConnector;
import org.springframework.web.reactive.function.client.WebClient;
import reactor.netty.http.client.HttpClient;
/**
* @author : wuweihong
* @desc : TODO 请填写你的功能描述
* @date : 2025-07-29
*/
@Configuration
public class WebClientConfig {
@Bean
public WebClient webClient() {
// 创建并配置 Netty 的 HttpClient
HttpClient httpClient = HttpClient.create()
.headers(headers -> headers
.remove("Transfer-Encoding") // 显式移除分块头
.set("Connection", "close") // 强制关闭连接避免分块
)
.compress(false); // 禁用压缩
return WebClient.builder()
.clientConnector(new ReactorClientHttpConnector(httpClient))
.build();
}
}ⅰ. 接口实现
- 文档导入向量数据库的接口实现
ini
import lombok.RequiredArgsConstructor;
import org.apache.commons.lang3.StringUtils;
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.ExtractedTextFormatter;
import org.springframework.ai.reader.pdf.PagePdfDocumentReader;
import org.springframework.ai.reader.pdf.ParagraphPdfDocumentReader;
import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.List;
@Service
@RequiredArgsConstructor
public class DocumentService {
private final VectorStore vectorStore;
public void loadAndStoreDocuments(String filePath) throws IOException {
List<Document> documents = null;
if (StringUtils.isNotBlank(filePath) && filePath.endsWith(".pdf")) {
// 读取PDF文档
documents = loadPDFDocuments(filePath);
System.out.println("Total number of documents: " + documents.size());
} else if (StringUtils.isNotBlank(filePath) && filePath.endsWith(".docx")) {
// 读取DOCX文档
documents = loadDOCXDocuments(filePath);
System.out.println("Total number of documents: " + documents.size());
}
// 文本分割
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> splitDocs = splitter.apply(documents);
// 存储到向量数据库
vectorStore.add(splitDocs);
}
public List<Document> loadPDFDocuments(String filePath) throws IOException {
// PDF文档读取配置
PdfDocumentReaderConfig config = PdfDocumentReaderConfig.builder()
.withPageExtractedTextFormatter(new ExtractedTextFormatter.Builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.build();
//先使用目录分段读取方式读取PDF并分段落
Resource resource = new FileSystemResource(filePath);
ParagraphPdfDocumentReader pdfReader = new ParagraphPdfDocumentReader(resource, config);
List<Document> documents = pdfReader.get();
System.out.println("Total number of documents1: " + documents.size());
if (documents.isEmpty()) {
//如果沒有获取到目录,在改用分页方式拆分
PagePdfDocumentReader pdfReader2 = new PagePdfDocumentReader(resource);
documents = pdfReader2.get();
System.out.println("Total number of documents2: " + documents.size());
}
return documents;
}
public List<Document> loadDOCXDocuments(String filePath) throws IOException {
// 读取DOCX文档
Resource resource = new FileSystemResource(filePath);
TikaDocumentReader docxReader = new TikaDocumentReader(resource);
List<Document> documents = docxReader.get();
System.out.println("Total number of documents: " + documents.size());
return documents;
}- rag问答接口实现类
java
package com.sikaryofficial.ai.service;
/**
* @author : wuweihong
* @desc : TODO 请填写你的功能描述
* @date : 2025-11-04
*/
import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.chat.prompt.PromptTemplate;
import org.springframework.ai.document.Document;
import org.springframework.ai.openai.OpenAiChatModel;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.io.Resource;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.Date;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
@Service
@RequiredArgsConstructor
public class RagService {
private final ChatClient chatClient;
private final VectorStore vectorStore;
@Value("classpath:/prompts/rag-prompt-template.st")
private Resource ragPromptTemplate;
public String processQuery(String query) {
// 1. 检索相关文档
List<Document> similarDocuments = vectorStore.similaritySearch(query);
System.out.println("检索到相关文档:" + similarDocuments.size());
// 2. 构建上下文
String context = similarDocuments.stream()
.map(Document::getFormattedContent)
.collect(Collectors.joining("\n\n"));
// 3. 构建提示词
PromptTemplate promptTemplate = new PromptTemplate(ragPromptTemplate);
Prompt prompt = promptTemplate.create(Map.of(
"current_date", new Date().toLocaleString(),
"input", query,
"context", context
));
// 4. 调用LLM生成回答
return chatClient.prompt(prompt).call().content();
}
}5. 效果自测
- 导入接口测试
- 智能问答接口测试