
目录
前言:
上一篇文章我们学习了string,但是我们也提到了string并不属于STL库里面的类。而我们今天就要学习到我们真正意义上的一个STL类,vector。也就是我们在C语言中学习的顺序表。今天我带大家了解一下evctor的用法,以及实现自己的vector。
一.vector的介绍
vector是表示可变大小数组的序列容器
vector本质就是我们之前数据结构学到的数据结构,我们可以用来存储自定义变量以及内置变量。包括我们上一章使用的string也可以存储在vector中。
并且vector 在访问元素的时候更加高效,在末尾添加和删除元素相对高效。对于其它不在末尾的删除和插入操作,效率更低。比起list 和 forward_list 统一的迭代器和引用更好。
二.vector的使用
下面我们来讲一下vector中的内置函数,vector与string不同的一点主要是vector是采用模板的方式来实现的。这就使得vector可以存储各种变量。
1.push_back和pop_back
正如字面意思push_back的主要作用就是对vector进行尾插。与之对应的就是pop_back尾删操作。在介绍我们的尾插为尾删时我们先搭建一个vector的基本框架
cpp
namespace lesson {
template<class T>
class vector {
typedef T* iterator;
//注意在vector和string中我们可以单纯的将迭代器当
//作是一个指针但是在后续的链表之中就不能这么认为了
public:
private:
iterator _start;
iterator _finish;
iterator _endOfStorage;
};
}注意上面注释内容,这对我们后面学习链表有很大帮助。
不过再提我们的尾插操作时肯定是要对我们的空间进行一个设置,包括我们的构造函数。在进行为尾插时我们首先还是要介绍一下我们的reserve函数,为了大家方便查找我把它放到尾插的子目录中
1.reserve
下面我们开始进行对reserve的实现
cpp
void reserve(size_t n)
{
if (n > capacity())
{
size_t oldsize = size();
T* tmp = new T[n];
if (_start)
{
//memcpy(tmp, _start, sizeof(T) * old_size);
for (size_t i = 0; i < oldsize; i++)
{
tmp[i] = _start[i];
}
delete[] _start;
}
_start = tmp;
_finish = _start + oldsize;
_endOfStorage = _start + n;
}
}memcpy(tmp, _start, sizeof(T) * old_size);需要注意的是我们不可以用这段代码进行拷贝,因为memcpy底层的本质还是一个浅拷贝,当需要第一次进行扩容时第一块的内容被释放,就找不到原本的数据了。
2.push_back
有了我们的扩容函数我们进行尾插就很容易了,话不多说直接开始吧
cpp
void push_back(const T& x)
{
if (_finish == _endOfStorage)
{
size_t newcapacity = capacity() == 0 ? 4 :( capacity() * 2);
reserve(newcapacity);
}
*_finish = x;
_finish++;
}怎么样很精简吧,那么写了这么多我们要怎么去检查一下我们的代码是否正确呢?下面我们再来实现几个函数end和begin也就是我们的迭代器。这时我们把T*定义为迭代器的作用就来了,不过需要注意的是并不是只有叫iterator才可以是迭代器,其实我们只需要有我们的begin函数和end函数就可以了。
cpp
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}下面是我们的测试代码:
cpp
void test()
{
vector<int>v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
vector<int>::iterator it = v1.begin();
for (auto e : v1)
{
cout << e << ' ';
}
}3.pop_back
那么随之而来的就是我们的尾删了,这个就更简单了
cpp
void pop_back()
{
--_finish;
}
cpp
void test()
{
vector<int>v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
v1.pop_back();
vector<int>::iterator it = v1.begin();
for (auto e : v1)
{
cout << e << ' ';
}
}2.insert和erase
接下来就改讲到我们的insert和erase了,这也是我们本篇文章的重点内容,因为这边涉及到我们的迭代器失效问题需要我们去特别注意。在说这两个函数之前我们先看一下这了两个函数的返回值和参数
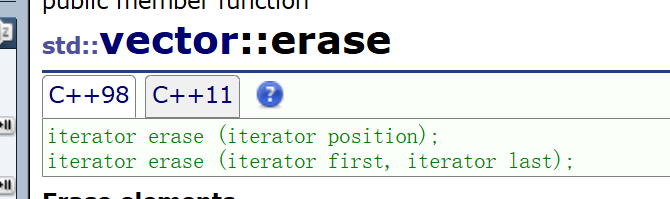
我们可以看到这两个在指定位置插入或删除时都会带一个返回值,那这个返回值的作用是什么呢?返回的又是什么东西呢?我们可以想一下当我们插入一个数据后我们的迭代器pos是指向哪里呢?是继续指向pos?还是保持位置不变呢?或者erase更加明显当pos被删除之后我们的迫使还存在吗?
那这就是我们返回值的作用了,在我们的函数介绍里面会有返回值的解释我们可以去看一下

一个指向紧跟erase的最后一个元素之后的新位置的元素的迭代器。简单来说就是pos位置的下一个元素的迭代器,好了现在我们来一一的实现一下我们的insert和erase吧。
1.insert
cpp
iterator insert(iterator pos, const T& x)
{
if (_finish == _endOfStorage)
{
size_t tmp = pos - _start;
size_t newcapacity = capacity() == 0 ? 4 : (capacity() * 2);
reserve(newcapacity);
//当扩容时原来的地址被释放,所以原来的pos已经失效所以需要记录pos的位置
pos = _start + tmp;
}
iterator end = _finish;
while (end != pos)
{
*end = *(end - 1);
end--;
}
*pos = x;
_finish++;
return pos;
}
cpp
void test()
{
vector<int>v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
v1.push_back(4);
v1.pop_back();
v1.insert(v1.begin(), 100);
v1.insert(v1.begin(), 100);
v1.insert(v1.begin(), 100);
vector<int>::iterator it = v1.begin();
for (auto e : v1)
{
cout << e << ' ';
}
}2.erase
cpp
iterator erase(iterator pos)
{
assert(pos < _finish);
assert(pos >= _start);
iterator pt = pos;
while (pt+1 != end())
{
*pt =*( pt + 1);
pt++;
}
_finish--;
return pos;
}3.拷贝构造,operate=和operate\[\]
接下来就是我们一些琐碎的功能了,不过这边博主只写几个比较常见的函数。不过vector的成员函数的接口也是比较多的。有些常用有些不太常用(如果有想了解其他函数的可以跟博主留言哦)
1.operate\[\]
这个也是很简单只需要去访问我们内部的元素就可以了:
cpp
T& operator[](size_t n)
{
return *(_start + n);
}
cpp
void test1()
{
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
cout << v1[0] << ' ' << v1[1] << ' ' << v1[2] << endl;
}是吧很简单,需要注意的是为什么我们要选择返回引用呢?目的是为了减少一层拷贝构造,在之前的构造和拷贝构造中我们讲到过。
2.operator=和拷贝构造
这个跟我们的赋值构造很像所以就放到一起讲了,不过这边就有小伙伴们要问了,系统不会自动生成一个拷贝构造吗?那个不可以用吗?我们不妨去试一下
cpp
void test2()
{
vector<int> v1;
v1.push_back(1);
v1.push_back(2);
v1.push_back(3);
vector<int>v2(v1);
for (auto e : v1)
{
cout << e << ' ';
}
cout << endl;
for (auto e : v2)
{
cout << e << ' ';
}
cout << endl;
}
看着好像并没有什么问题但是我们打开调试界面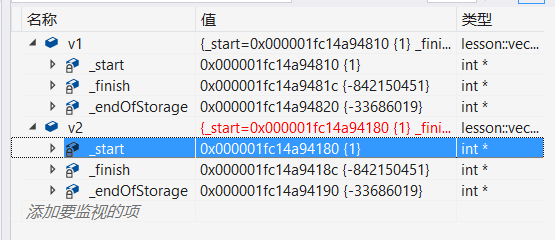
我们可以看到两处的地址是相同的这就说明我们进行的是一个浅拷贝,当增加我们的析构函数时就会崩溃。所以说要完成目标的话就需要实现深拷贝。
cpp
vector(const vector<T>& v)
{
//reserve(v.capacity());
for (auto e : v)
{
push_back(e);
}
}为了防止频繁的扩容我们可以事先开好空间,会减少扩容的时间。
当然我们的operator=也可以这样写只需要把*this返回就可以了。不过我们有更加方便的写法
cpp
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_endOfStorage, v._endOfStorage);
}
}
vector<int> operator=(vector<T> v)
{
swap(v);
return *this;T
}我们在c语言中学到过形参是实参的一份拷贝出函数的作用域之后会销毁,那么我们就可以直接交换形参和*this的内容这样我们就方便了很多。
4.迭代器区间的构造函数
其他方式的构造函数都很简单我们主要讲一下这个迭代器区间去进行初始化。这个主要会涉及到我们的函数模板的作用,这样我们就可以将任意类型的类转换为我们的vector了下面来看一下代码吧。
cpp
template <class InputIterator>
vector(InputIterator first, InputIterator last)
{
while (first != last)
{
push_back(*first);
++first;
}
}
cpp
void test3()
{
vector<string> v1;
v1.push_back("111111111111111111");
v1.push_back("111111111111111111");
v1.push_back("111111111111111111");
v1.push_back("111111111111111111");
v1.push_back("111111111111111111");
for (auto e : v1)
{
cout << e << " ";
}
cout << endl;
}结言:
好了我们的vector就到此为止了,希望喜欢博主的朋友关注一下哦。博主会不定期的分享学习历程。我们一起加油!!!