当你在生产环境中尝试运行 pgvector 时,就会发现有各种坑,而这些坑可能被网上各个博文刻意忽略。
理论上,大家都喜欢 pgvector
如果你过去一年在向量搜索领域有所涉猎,你可能读过一些博客文章,解释为什么 pgvector 是满足你向量数据库需求的最佳选择。论点大致如下:你已经有了 Postgres,向量嵌入只是另一种数据类型,既然可以将所有数据集中在一个地方,为什么还要增加专用向量数据库的复杂性呢?
这是一个引人入胜的故事。但就像我时间线上充斥的大多数人工智能网红的垃圾内容一样,它掩盖了许多不便的细节。
我并不是说 pgvector 不好。它很好。它是一个很有用的扩展,能为 Postgres 带来向量相似性搜索功能。但是,在尝试基于它构建生产系统一段时间后,我发现"在演示环境中运行良好"和"在生产环境中扩展可扩展"之间的差距......相当大。
目前还没有人在生产环境中实际运行过这个方案
最令我困扰的是:大多数关于 pgvector 的内容读起来就像是出自某个人之手,他只是搭建了一个本地 Postgres 实例,插入了 10,000 个向量,运行了几条查询,然后就草草收工了。文章内容乐观,基准测试数据清晰明了,结论也十分自信。
他们还遗漏了你实际需要知道的大约 80% 的信息。
我已经阅读了数十篇这样的帖子。
它们的内容大同小异:比如如何安装 pgvector,如何创建向量列,以及一个简单的相似性搜索查询。有些文章甚至提到你可能应该添加索引。
他们不会告诉你的是,当你在生产环境中实际运行它时会发生什么。
应该选择哪种索引类型 ?(没有银弹,只有权衡)
让我们从索引类型开始,因为权衡取舍就从这里开始。
pgvector 提供了两种索引类型:IVFFlat 和 HNSW。博客文章会告诉你 HNSW 是更新的索引类型,通常也更好,这......从技术上讲没错,但实际上毫无帮助。
IVFFlat
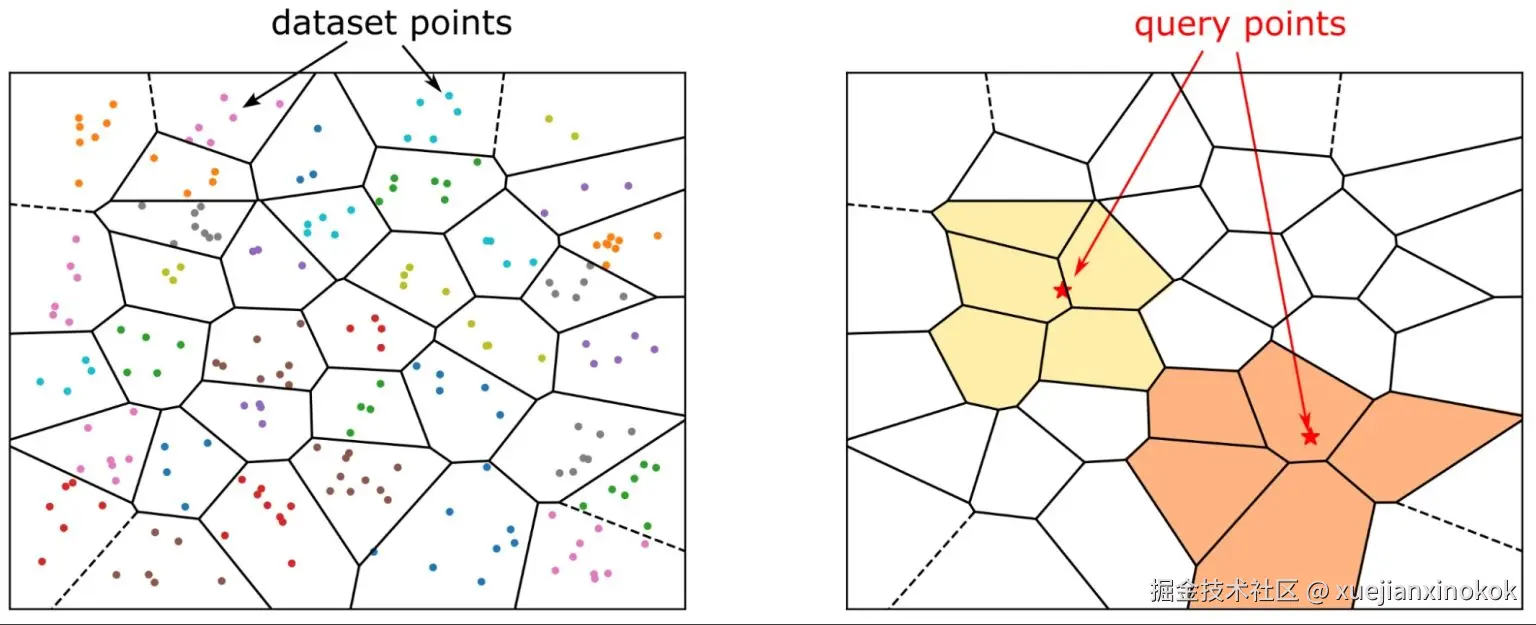
IVFFlat(平坦量化的倒排文件 Inverted File with Flat quantization)将向量空间划分为若干簇。在搜索过程中,它会识别最近的簇,并且仅在这些簇内进行搜索。
优点:
- 创建索引期间占用内存更少
- 在许多用例中都具有合理的查询性能
- 索引创建速度比 HNSW 快
缺点:
- 需要您预先指簇(clusters)的数量。
- 这个数值对召回率和查询性能都有显著影响。
- 常用的公式(
rows / 1000)充其量只是一个起点。 - 召回率可能会......令人失望,这取决于你的数据分布。
- 新的向量会被分配给现有的簇(cluster),但如果不进行完全重建,簇(cluster)不会重新平衡。
 图片来源: IVFFlat 还是 HNSW 索引用于相似性搜索? 作者:Simeon Emanuilov*
图片来源: IVFFlat 还是 HNSW 索引用于相似性搜索? 作者:Simeon Emanuilov*
HNSW
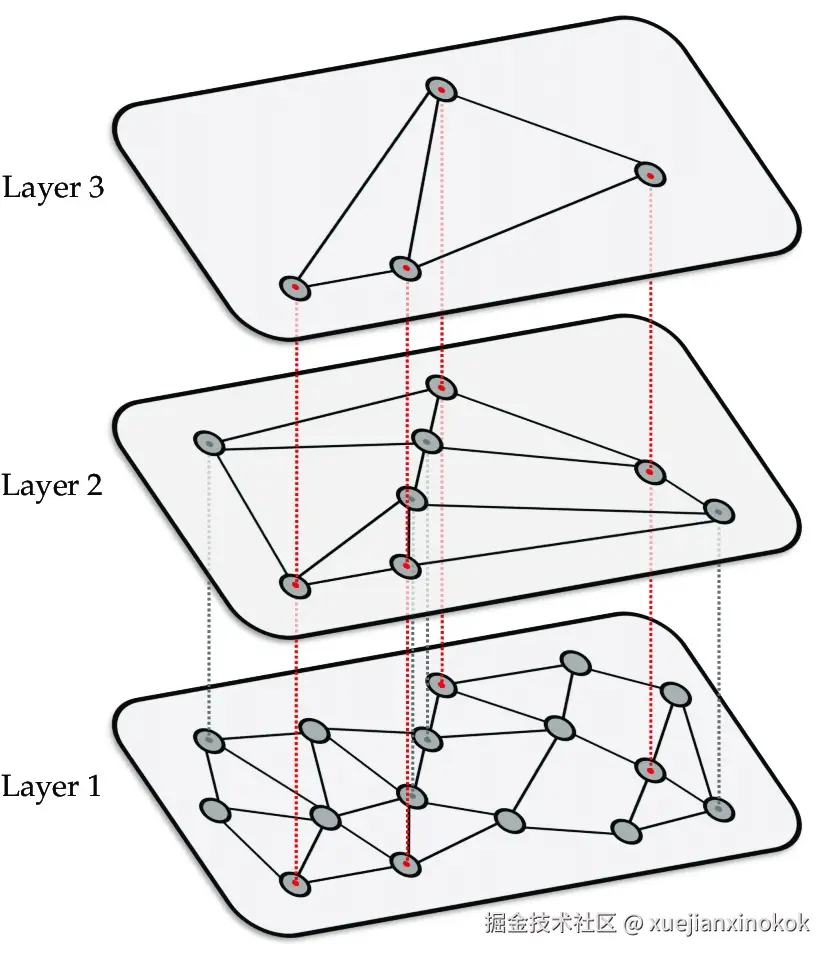
HNSW(Hierarchical Navigable Small World,分层可导航小世界)构建了一个用于搜索的多层的图结构。
优点:
- 对于大多数数据集,其召回率优于 IVFFlat。
- 更稳定的查询性能
- 能够很好地扩展到更大的数据集
缺点:
- 索引构建期间内存需求显著增加
- 索引创建速度很慢------对于大型数据集来说慢得令人难以忍受。
- 内存需求并非理论上的,而是实实在在的,如果不小心,它们会导致数据库崩溃。
 图片来源: IVFFlat 还是 HNSW 索引用于相似性搜索? 作者:Simeon Emanuilov*
图片来源: IVFFlat 还是 HNSW 索引用于相似性搜索? 作者:Simeon Emanuilov*
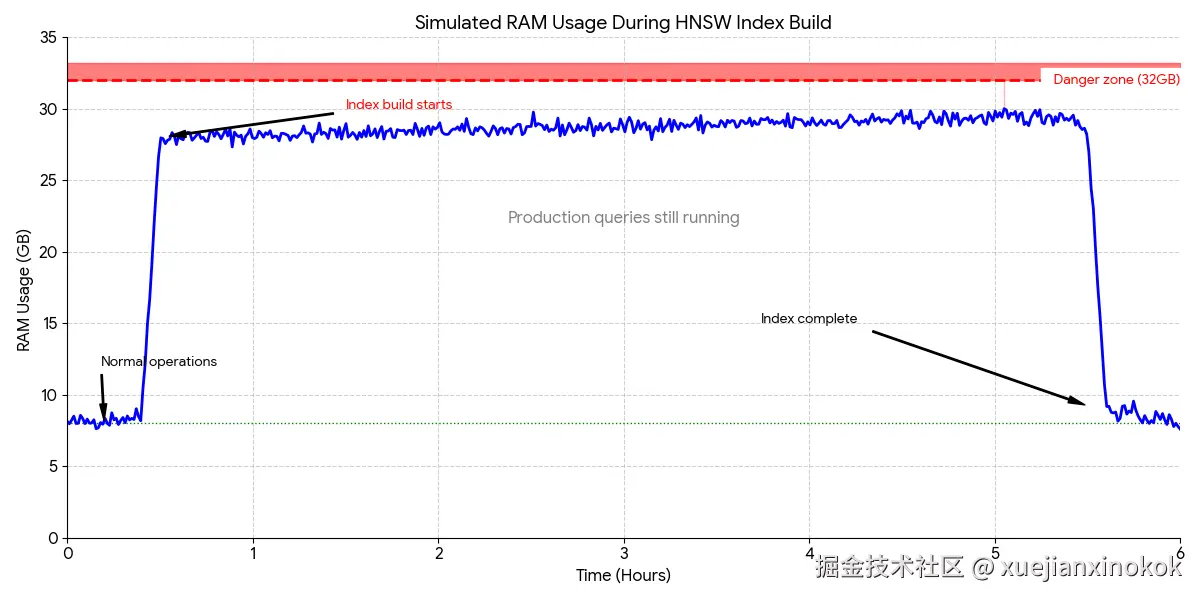
所有博客都没有提到,在数百万个向量上构建 HNSW 索引可能会消耗 10GB 甚至更多的内存(具体取决于向量维度和数据集大小)。而且是在生产数据库运行期间,可能持续数小时。
实时搜索基本上是不可能的
在典型的应用中,您希望新上传的数据能够立即被搜索到。用户上传文档后,您生成嵌入向量,将其插入数据库,然后这些嵌入向量应该出现在搜索结果中。很简单,对吧?
索引更新的实际工作原理
当您向带有索引的表中插入新向量时,会发生以下两种情况之一:
-
IVFFlat :新向量会根据现有结构插入到相应的簇中。这种方法虽然可行,但随着时间的推移,簇分布会变得越来越不理想。解决方案是定期重建索引。这意味着需要停机维护,或者维护一个单独的索引并执行原子交换,或者接受搜索质量下降。
-
HNSW :向图结构中添加新向量。这比 IVFFlat 好,但并非没有代价。每次插入都需要更新图,这意味着内存分配、图遍历以及潜在的锁争用。
单独来看,这两点都不是致命的。但实际情况是这样的:你一天到头都在不断地插入向量。每次插入的成本都很低,但累积起来的负载却相当可观。你的数据库现在不仅要处理正常的事务性工作负载、分析查询,还要在内存中维护用于向量搜索的图结构。
处理新插入的数据
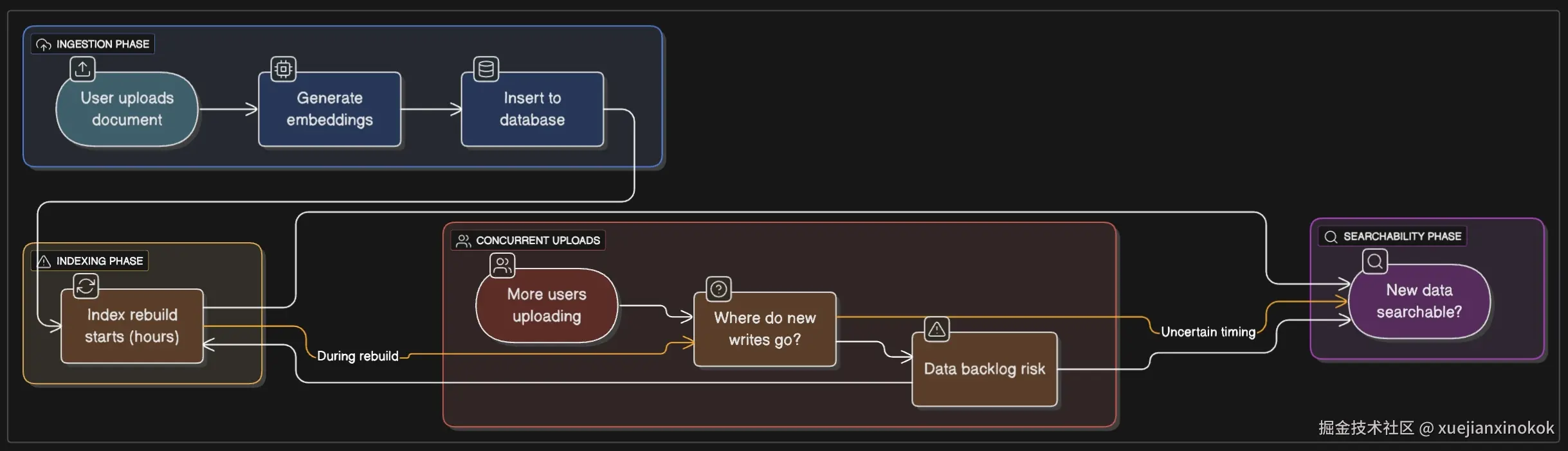
假设你正在构建一个文档搜索系统。用户上传 PDF 文件,你提取文本,生成嵌入代码,然后将其插入。用户希望能够立即搜索到该文档。
实际情况是这样的:
如果没有索引 :插入速度很快,文档可以立即访问,但搜索会进行完整的顺序扫描。对于几千份文档来说,这没问题。几十万份呢?搜索就要花几秒钟。几百万份呢?只能祝你好运。
使用 IVFFlat :插入操作仍然相对较快。向量会被分配到一个簇。但是,糟糕,问题来了。这些初始簇分配是基于构建索引时的数据分布情况 。随着数据量的增加,尤其是在数据分布不均匀的情况下,一些簇会过载,导致搜索质量下降。虽然可以定期重建索引来解决这个问题,但在重建过程中(对于大型数据集,重建可能需要数小时),如何处理新插入的数据呢?将它们放入队列?写入一个单独的未索引表,稍后再合并?
使用 HNSW 时 :每次插入操作都会通过增量插入更新图,这听起来很棒。但更新 HNSW 图并非没有成本------你需要遍历图来找到插入新节点的正确位置并更新连接。每次插入操作都会获取图结构的锁。在高写入负载下,这会成为瓶颈。如果写入速率足够高,就会出现锁争用,从而降低写入和读取速度。
实际操作情况
真正的难题在于:你存储的不仅仅是向量。你还有元数据------文档标题、时间戳、用户 ID、类别等等。这些元数据存储在其他表(或同一张表中的其他列)中。你需要确保这些元数据和向量保持同步。
在普通的 Postgres 表中,这很容易------事务会自动处理。但是,当索引构建耗时数小时时,保持数据一致性就变得复杂了 。对于 IVFFlat 索引,定期重建几乎是维持搜索质量的必要条件。对于 HNSW 索引,如果需要调整参数或性能下降,则可能需要重建。
问题在于索引构建是内存密集型操作,而 Postgres 并没有很好的方法来限制这种操作。你实际上是在要求生产数据库为一项可能耗时数小时的操作分配数 GB(甚至数十 GB)的内存,同时还要继续处理查询。
最终你会得到类似这样的策略:
- 写入暂存表,离线构建索引,然后将其替换进去(但这样一来,搜索就会出现一段时间内无法获取新数据的情况)。
- 维护两个索引并同时写入(内存占用翻倍,更新成本翻倍)
- 在副本上构建索引并提升其级别
- 接受最终一致性(用户上传的文档在 N 分钟内无法搜索)
- 分配的内存要比你的"工作集"建议的要多得多
这些方法都不算"错误"。但它们都是为了弥补 pgvector 并非 真正为高速实时数据插入 而设计的缺陷而采取的变通方案。
预过滤与后过滤(或者:为什么你需要成为查询规划器专家)
好的,假设你已经解决了索引和插入问题。现在你有一个包含数百万个向量的文档搜索系统。文档带有元数据------例如,它们可能被标记为 draft 、 published 或 archived 。用户搜索某个内容,而你只想返回已发布的文档。
sql
1 SELECT * FROM documents
2 WHERE status = 'published'
3 ORDER BY embedding <-> query_vector
4 LIMIT 10;很简单。但现在你遇到了一个问题:Postgres 应该先按 status 过滤(预过滤),还是先进行向量搜索再过滤(后过滤)?
这看起来像是一个实现细节,但并非如此。这决定了查询的执行时间,有的查询耗时50毫秒,有的查询耗时5秒。这也决定了能否返回最相关的结果。

当筛选条件非常严格时(例如从 1000 万个文档中筛选出 1000 个), 预先过滤 (Pre-filter)效果非常好。但如果筛选条件不够严格,预筛选的效果就会很差------因为你仍然需要搜索数百万个向量。
后过滤 (Post-filter)适用于宽松的过滤器。但它在以下情况下会失效:假设你使用 LIMIT 10 请求 10 个结果。pgvector 会找到 10 个最近邻,然后应用你的过滤器。这 10 个最近邻中只有 3 个是已发布的。因此,你只会得到 3 个结果,即使在嵌入空间中可能存在数百个稍远一些的相关已发布文档。
用户进行了搜索,得到了 3 个平庸的结果,却不知道自己错过了更好的匹配结果,这些结果并没有出现在最初的 k=10 搜索中。

你可以通过获取更多向量(例如, LIMIT 100 )然后进行筛选来解决这个问题,但是现在:
- 你做的距离计算太多了。
- 你仍然不知道100是否足够。
- 您的查询性能受到影响。
- 你猜对了过采样因子 (oversampling factor)。
使用预过滤可以避免这个问题,但会带来我提到的性能问题。
多重过滤
现在再增加一个维度:您正在按 user_id、category 和 date_range 进行筛选。
sql
1 SELECT * FROM documents
2 WHERE user_id = 'user123'
3 AND category = 'technical'
4 AND created_at > '2024-01-01'
5 ORDER BY embedding <-> query_vector
6 LIMIT 10;现在正确的策略是什么?
- 先应用所有筛选条件,然后再搜索?(预过滤)
- 先搜索,再应用所有筛选条件?(后过滤)
- 先应用一些筛选条件,进行搜索,然后再应用剩余的筛选条件?(混合模式)
- 应该按什么顺序应用哪些筛选条件?
规划器会查看表统计信息、索引选择性和预估行数,并生成一个执行计划。这个计划很可能是不准确的,或者至少不是最优的,因为规划器的成本模型并非针对向量相似性搜索而设计的。
情况会变得更糟:你每天都在插入新的向量。你的索引统计信息已经过时。执行计划会越来越不理想,直到你对表进行 ANALYZE 操作。但是,对包含数百万行的大型表进行 ANALYZE 操作需要耗费大量时间和资源。而且,它并不能真正有效地理解向量数据的分布------它可以告诉你有多少行匹配 user_id = 'user123' ,但无法告诉你这些向量在嵌入空间中的聚集程度,而这才是真正影响搜索性能的关键所在。
变通方法
最终你会得到一些变通方法:针对不同用户类型重写查询、将数据划分到单独的表中、使用 CTE 来强制规划器执行操作,或者只是获取比需要的更多的结果,然后在应用程序代码中进行过滤。
这些方法都无法大规模实施。
向量数据库的作用
专用矢量数据库已经解决了这个问题。它们了解过滤矢量搜索的成本模型,并能做出智能决策:
- 自适应策略 :一些数据库会根据估计的选择性动态选择预过滤器或后过滤器。
- 可配置模式 :其他模式允许您在了解数据分布的情况下显式指定策略。
- 专用索引 :有些索引支持高效的过滤搜索(例如过滤后的 HNSW)。
- 查询优化 :它们跟踪向量运算的特定统计信息并据此进行优化。
例如,OpenSearch 的 k-NN 插件允许您指定预过滤或后过滤行为。Pinecone 会自动处理过滤器的选择性。Weaviate 针对常见的过滤模式进行了优化。
使用 pgvector,你可以自己构建所有这些功能。或者忍受次优的查询。或者聘请一位 Postgres 专家,花几周时间优化你的查询模式。
混合搜索?自己动手构建
哦,如果你想要混合搜索------将向量相似性与传统的全文搜索相结合------你也可以自己构建它。
Postgres 拥有出色的全文检索能力,pgvector 拥有出色的向量检索能力。如何将它们有效地结合起来?这就需要你自己去探索了。
你需要:
-
决定如何权衡向量相似度和文本相关性
-
将两种不同评分系统的分数进行标准化
-
根据您的使用场景调整平衡
-
或许可以实现互惠等级融合或其他类似机制。
这并非不可能。许多专业的矢量数据库都提供这项功能,而且是开箱即用的。
pgvectorscale 插件(但它并不能解决所有问题)
Timescale 发布了 pgvectorscale ,解决了其中一些问题。它还增加了以下功能:
- StreamingDiskANN,一种更节省内存的新型搜索后端
- 更好地支持 增量索引构建
- 改进的过滤性能
这太棒了!这也承认了 pgvector 本身的功能 不足以满足生产环境的需求。
pgvectorscale 仍然是一个相对较新的库,采用它意味着要增加一个依赖项、一个扩展程序,以及需要管理和升级的额外东西。对某些团队来说,这没问题。但对另一些团队来说,这恰恰证明了"保持简单,使用 Postgres"的论点或许并不像看起来那么简单。
哦,对了,如果你用的是 RDS,pgvectorscale 就用不了了。AWS 不支持它。所以,如果你想要这些改进,就得自己管理 Postgres 实例,或者......继续忍受原生 pgvector 的种种限制。
"直接使用 Postgres"的简单性还在不断简化。
只需使用真实的矢量数据库即可
我理解 pgvector 的吸引力。整合技术栈是好事,降低运维复杂度是好事,不用管理另一个数据库也是好事。
但我学到的是:对于大多数团队,尤其是小型团队来说,专用矢量数据库实际上更简单。
你实际会得到什么
使用托管矢量数据库(例如 Pinecone、Weaviate、Turbopuffer 等),通常可以获得以下结果:
- 针对筛选搜索的智能查询规划
- 内置混合搜索
- 实时索引,无内存峰值
- 无需复杂操作即可进行水平扩展
- 专为向量工作负载设计的监控和可观测性

可能比你想象的要便宜。
是的,这又是一项需要付费的服务。但请比较一下:
- 为您的工作负载构建托管向量数据库的成本
- 与为了处理索引构建而过度配置 Postgres 实例的成本相比
- 与调整查询和管理索引重建所需的工程时间相比
- 与因为与数据库作斗争而放弃构建功能的机会成本相比
对于很多团队来说,托管服务实际上更便宜。
我希望有人能告诉我
pgvector 是一项令人印象深刻的技术。它以技术上可靠且对许多应用真正有用的方式,将向量搜索引入了 Postgres。
但这并非万灵药。要明白其中的利弊。
如果您正在构建一个生产级向量搜索系统:
-
索引管理很困难 。重建索引会占用大量内存、耗时且会造成服务中断。从一开始就应该考虑到这一点。
-
查询规划至关重要 。过滤向量搜索与传统查询截然不同,Postgres 的查询规划器并非为此而设计。
-
实时索引是有成本的 ,无论是内存占用、搜索质量下降,还是管理所需的工程时间。
-
这些博客文章(通过隐瞒真相)在欺骗你 。它们只向你展示美好的前景,却忽略了实际操作中的种种问题。
-
托管服务的存在是有原因的 。Pinecone、Weaviate、Qdrant 等服务之所以存在并蓬勃发展,也是有原因的。大规模向量搜索面临着通用数据库无法应对的独特挑战。
问题不是"我应该使用 pgvector 吗?",而是"我是否愿意承担在 Postgres 中运行向量搜索的操作复杂性?"
对于某些团队来说,答案是肯定的。你们拥有数据库方面的专业知识,需要紧密集成,也愿意投入时间。
对很多团队------或许是大多数团队------来说,答案很可能是否定的。使用专为这项工作设计的工具。未来的你会感谢自己的。