目录
[1. 数据并行(Data Parallelism)](#1. 数据并行(Data Parallelism))
[2. 模型并行(Model Parallelism)](#2. 模型并行(Model Parallelism))
[3. 混合并行(Hybrid Parallelism)](#3. 混合并行(Hybrid Parallelism))
[(3)DeepSpeed ZeRO Stage 1------ 优化器状态分片](#(3)DeepSpeed ZeRO Stage 1—— 优化器状态分片)
[(4)DeepSpeed ZeRO Stage 2 ------ 优化器状态 + 梯度分片](#(4)DeepSpeed ZeRO Stage 2 —— 优化器状态 + 梯度分片)
[(5)DeepSpeed ZeRO Stage 3 ------ 优化器状态 + 梯度 + 参数分片](#(5)DeepSpeed ZeRO Stage 3 —— 优化器状态 + 梯度 + 参数分片)
分布式训练主要是在模型过大或数据集过大,我们单张显卡的显存不足以支撑训练模型,这时候就需要准备多张显卡来进行训练,多显卡配置一般如下表所示。为了能够让模型在多张显卡上运行,我们就需要使用到分布式训练的算法,本文将会依次介绍各个方法。
| 范围 | 示例 | 描述 |
| 单机多卡 | 1台服务器 + 4/8张GPU | 最常见,通信走NVLink或PCIe |
| 多机多卡 | 多节点GPU集群 | 通信走高速网络(InfiniBand, RoCE) |
| 异构训练 | GPU + TPU + CPU 混合 | 未来趋势,但难度高 |
|---|
首先,先介绍分布式训练的分类,分布式训练主要分为数据并行,模型并行,混合并行这三个类别,三个类别如下边所示:
一、分布式训练的三大主线分类
从核心理念上看,分布式训练可以分为三种主流类型:
1. 数据并行(Data Parallelism)
核心思想: 每个节点(GPU)保存完整模型副本,但处理不同的数据子集。
特点:
-
各 GPU 拿到不同 batch 的数据;
-
前向传播独立完成;
-
反向传播后需要同步梯度(gradient synchronization)。
常用实现:
-
DP (Data Parallel)
-
PyTorch 的
DistributedDataParallel (DDP) -
Horovod
-
DeepSpeed Stage 1/2
-
Megatron-LM 的 hybrid parallel 里也用到它。
通信瓶颈: 主要发生在梯度同步阶段,采用 AllReduce 通信模式。
适用场景: 模型能放进单卡显存,但数据太多,需要多卡加速训练。
2. 模型并行(Model Parallelism)
核心思想: 模型太大放不下单个 GPU,把模型的不同部分拆开到多 GPU 上。
常见形式:
-
张量并行(Tensor Parallelism):
把同一层的权重矩阵在不同 GPU 上切分,比如一部分乘法在 GPU0 上做,另一部分在 GPU1 上做,最后拼接。
-
代表框架:Megatron-LM, DeepSpeed-MoE。
-
通信开销高(需频繁 gather/scatter)。
-
-
流水线并行(Pipeline Parallelism):
把不同层的网络放在不同 GPU 上,比如 GPU0 负责前几层,GPU1 负责后几层。
-
数据像"装配线"一样传递。
-
可与微批(micro-batch)结合使用来提高 GPU 利用率。
-
代表框架:GPipe、PipeDream、DeepSpeed Pipeline。
-
适用场景: 模型超大(例如百亿、千亿参数),单卡放不下权重。
3. 混合并行(Hybrid Parallelism)
核心思想: 结合数据并行 + 模型并行 + 专用优化。
常见组合:
-
张量并行 + 数据并行(如 Megatron-LM)
-
流水线并行 + 数据并行(如 DeepSpeed)
-
甚至三者融合(如 GPT-3 训练架构)
额外增强手段:
-
ZeRO 优化(Zero Redundancy Optimizer):把优化器状态、梯度、参数在 GPU 之间分片,极大降低显存占用。
-
MoE(Mixture of Experts):不同 GPU 仅激活部分专家网络,进一步提升扩展性。
适用场景: 大规模预训练、超大参数模型(BLOOM、ChatGPT、Llama等都用这类架构)。
二、常用的数据并行
本文主要介绍数据并行的方法,模型并行将会在下篇文章更新。
(1)DP方法
分布式数据并行(Distributed Data Parallel, DP)是一种常见的分布式训练方法,用于加速深度学习模型的训练过程。其核心思想是将训练数据划分到多个计算节点(如GPU或机器),每个节点独立计算梯度,最后通过聚合梯度实现模型参数的同步更新。
但DP方法也有着明显的缺点,它是单进程,多线程的运行方法,假设我们目前有四块GPU,即计算是由全部GPU分别进行的,但对于参数的更新是GPU2, GPU3, GPU4把各自在自己那部分数据集上更新完后的参数传给GPU1,由GPU1来进行平均全部四个部分的梯度,然后对模型参数进行更新,最后把更新的参数分发到其余的三块GPU上边,这才完成了一次模型权重的更新。可以发现,在计算梯度的时候全部GPU都参与了计算,但在更新参数时,只有GPU1在进行参数广播,其他GPU都没发挥作用,这时候就需要新的方法,也就是我们的DDP方法(Distributed Data Parallel)。
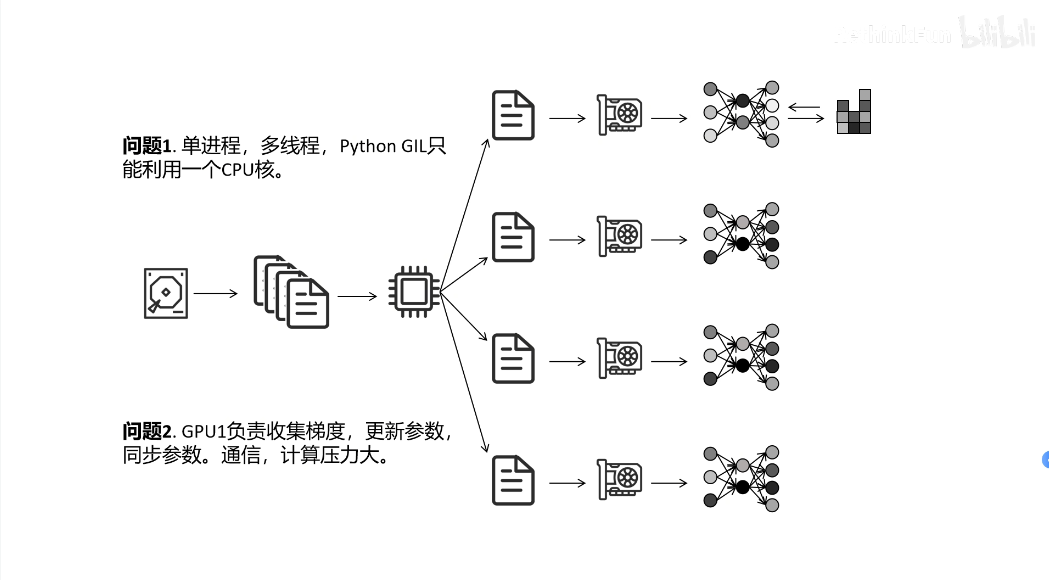
(2)DDP方法
DDP(Distributed Data Parallel)是一种分布式深度学习训练方法,用于在多GPU或多节点环境下并行训练模型。其核心思想是将数据分片分配到不同设备上,每个设备独立计算梯度,最后通过同步机制聚合梯度更新模型参数。
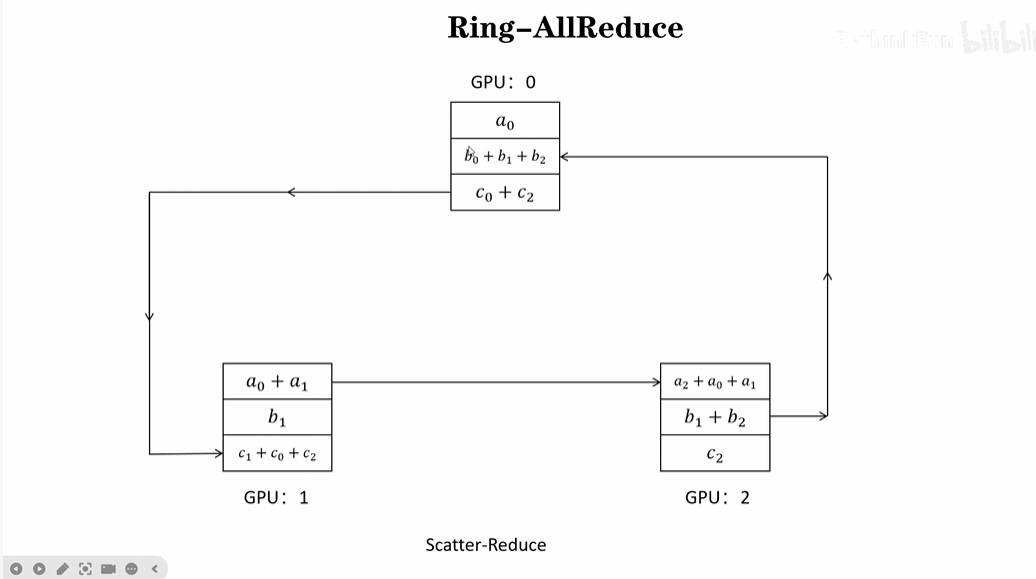
DDP方法的核心在于Ring-ALLReduce,ALLReduce分为两个部分:Scatter-Reduce和ALLGather。接下来将分别介绍这两个方法:
1)Scatter-Reduce:Scatter-Reduce主要是在每个GPU上边进行反向传播计算出梯度并更新后,分别由不同的GPU对模型的参数进行循环式更新,例如在GPU0上更新了参数a0,GPU0把参数a0传个GPU1,得到a0+a1,然后GPU1再把a0+a1传给GPU2,此时一次循环更新结束,GPU2获得了最终的更新参数a0+a1+a2。其他参数也是如此,以此类推,GPU0获得了b0+b1+b2,GPU1获得了c0+c1+c2。
2)ALLGather:第二步则进行ALLGather,每个GPU把自己得到的最终参数分别传给其他的GPU,这样每个GPU就都拥有了更新完后的参数。
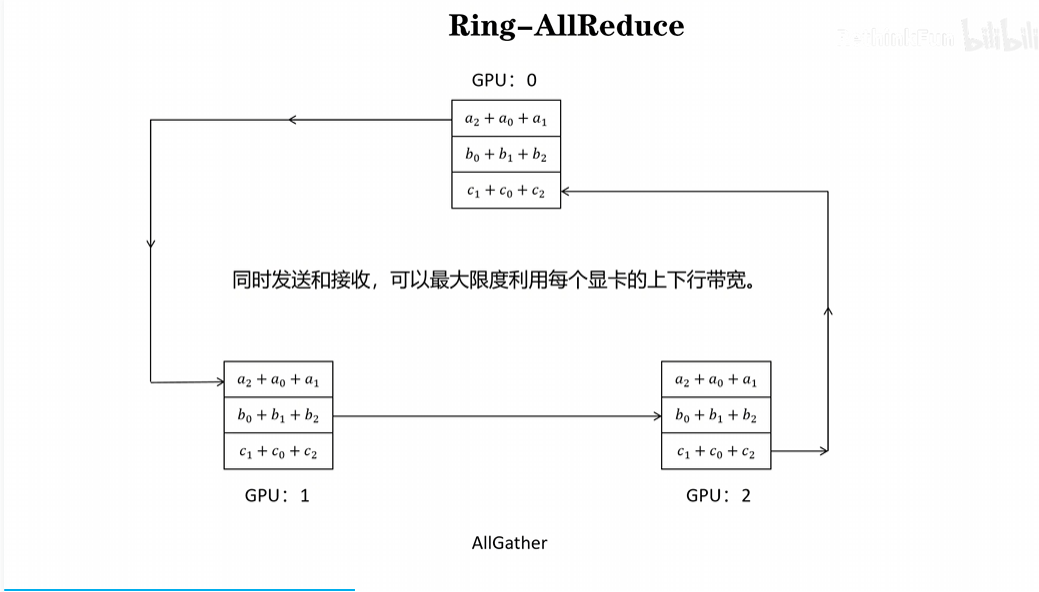
DDP方法通过Ring-ALLReduce让每个GPU都参与进了参数更新的过程当中,即使用了多个进程,每个GPU的参数传入传出量都是相同的。
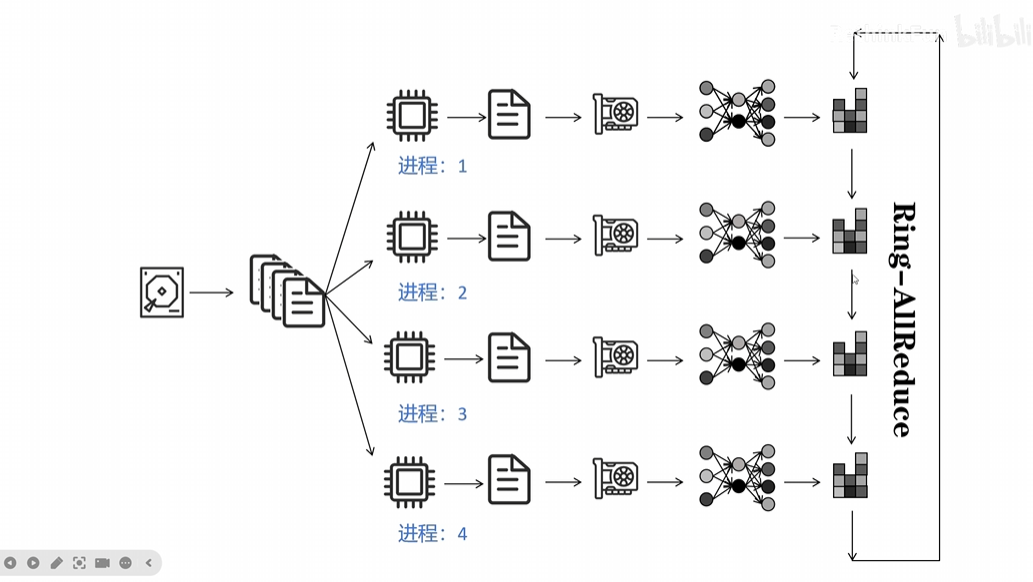
(3)DeepSpeed ZeRO Stage 1------ 优化器状态分片
首先先理解 ZeRO 的设计初衷ZeRO,全称 Zero Redundancy Optimizer,目标是解决一个关键问题:
在分布式数据并行中,每个 GPU 都保存完整的模型参数、副本、梯度和优化器状态,造成巨大冗余。
比如,一个 10 亿参数的模型,Adam 优化器会额外存储:
-
参数(weights)
-
梯度(gradients)
-
一阶动量(m)
-
二阶动量(v)
合计大约是原模型大小的 3~4 倍显存消耗 。
如果每张 GPU 都保存这些副本,就浪费得惊人。
ZeRO 就是为了解决这个问题的:
它将模型训练状态在 GPU 之间分片存储(partition),让每张卡只保存一部分,而不是全量副本。
ZeRO 的三个阶段概览如下所示
| 阶段 | 优化对象 | 主要思路 | 显存节省 | 通信代价 |
|---|---|---|---|---|
| Stage 1 | 优化器状态 (Optimizer States) | 将优化器状态切分分布在不同 GPU 上 | 大约 4× 节省 | 低 |
| Stage 2 | 优化器状态 + 梯度 (Gradients) | 再切分梯度张量 | 大约 8× 节省 | 中 |
| Stage 3 | 优化器状态 + 梯度 + 参数 (Parameters) | 参数也分片存储和加载 | 高达 16× 节省 | 高(需动态通信) |
Stage 1 和 Stage 2 是"轻量级分布式显存优化",Stage 3 则是"极限节省版"。
接下来,正式介绍DeepSpeed ZeRO Stage 1 ------ 优化器状态分片
工作机制
在标准数据并行(DDP)中,每个 GPU 都保存:
优化器状态(Adam的m、v)、梯度、参数副本。
如下图所示,每块GPU右侧的图示标识的意思是:模型的网络结构------>模型的参数------>模型的梯度------>Adam优化器
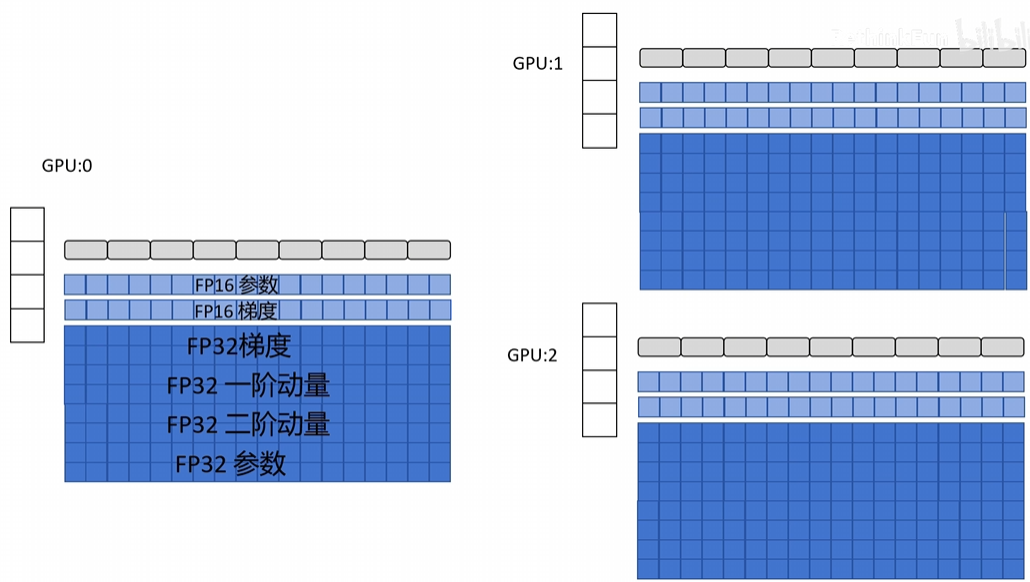
Stage 1 只分片优化器状态:
-
参数和梯度仍完整保留;
-
,如下图所示,优化器状态被切分到不同 GPU 上,每张卡只持有自己负责的一部分参数对应的优化器状态;
-
在更新权重时,DeepSpeed 自动把对应的状态收集回来计算,然后再同步更新。
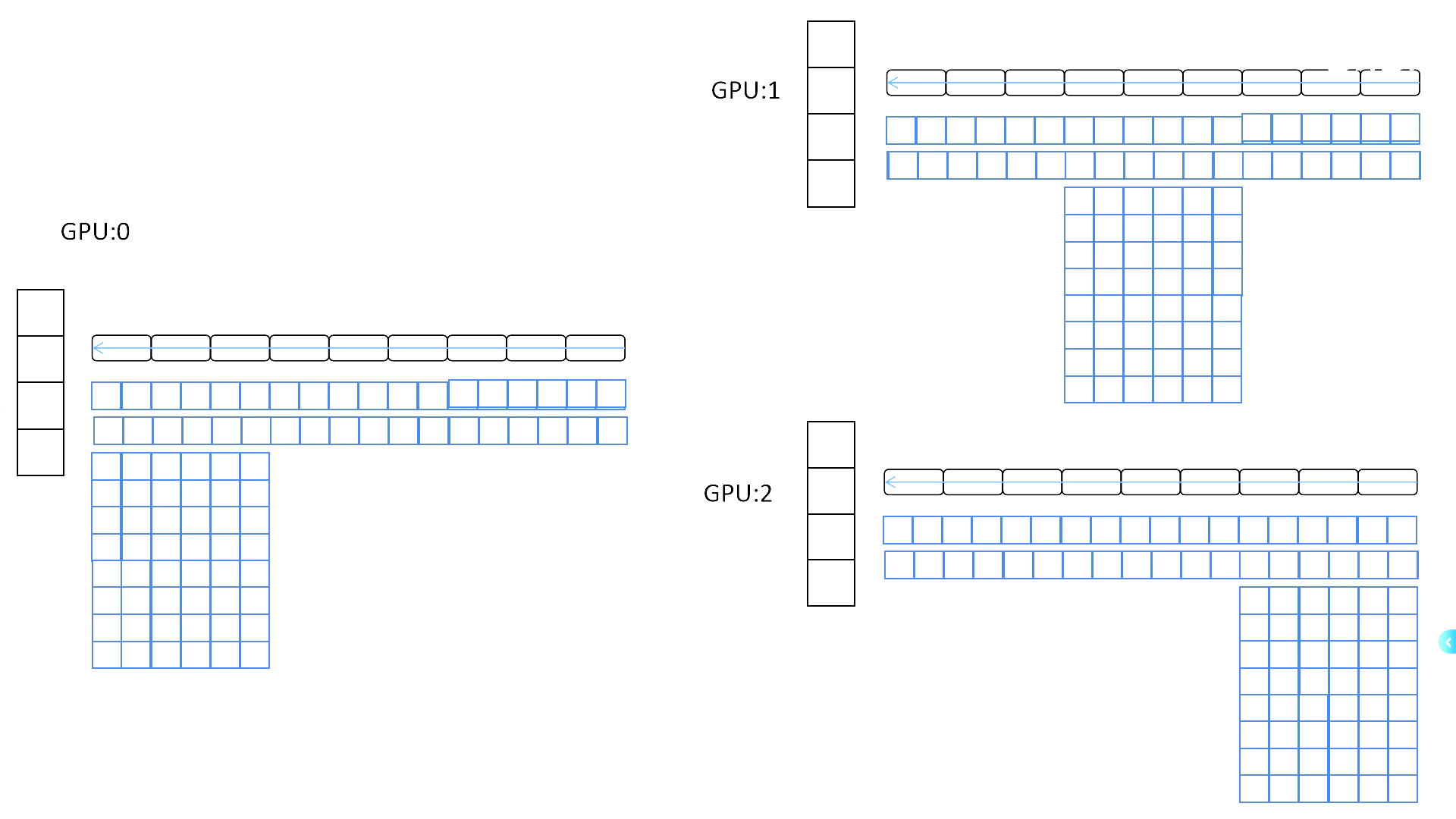
通信过程
通信非常少:只有在参数更新时需要跨设备访问对应分片。
前向、反向传播几乎不受影响。
显存效果
-
模型 + 梯度仍然保留;
-
优化器状态分片 → 显存降低约 3~4 倍;
-
对计算效率影响极小。
适用场景:
-
中等规模模型(几亿参数);
-
有多张 GPU,但希望几乎不牺牲训练速度。
(4)DeepSpeed ZeRO Stage 2 ------ 优化器状态 + 梯度分片
Stage 2 在 Stage 1 的基础上进一步优化:
不仅优化器状态切分,梯度也被切分。
工作机制
-
每个 GPU 计算自己那一部分梯度;
-
反向传播结束后,通过 reduce-scatter 将梯度分配到对应 GPU;
-
如下图所示,计算完不属于自己负责的梯度,在分配到对应负责的GPU上后就将梯度删除,每张卡只保存与自己负责的参数相关的梯度;
-
更新时,只需用本地梯度和本地优化器状态计算权重更新。
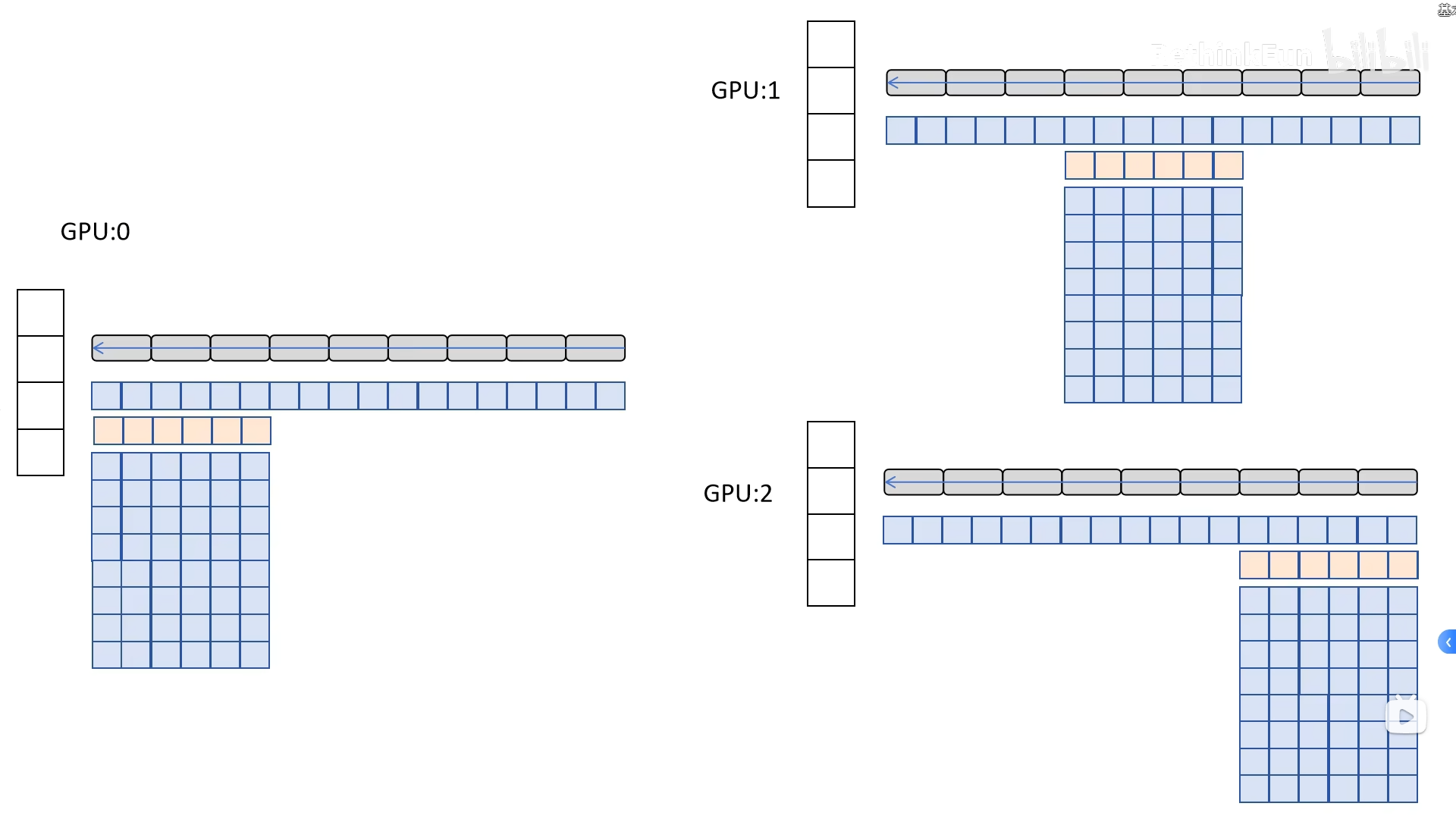
通信机制
使用 reduce-scatter + all-gather 替代传统的 all-reduce ,
减少冗余通信量。
例如:
-
原本 all-reduce 的通信量是 2 × N × 参数量;
-
reduce-scatter + all-gather 的通信量约为 N × 参数量。
显存效果
显存进一步节省至原始的约 1/8;
例如 8 张 GPU,可以近乎线性扩展模型规模。
代价
由于反向传播结束后要多一步 reduce-scatter ,通信开销略增;
但总体性价比极高,常被大规模模型采用。
适用场景:
-
模型参数较大(10亿~100亿级别);
-
追求显存和性能平衡;
-
多节点 GPU 训练集群。
(5)DeepSpeed ZeRO Stage 3 ------ 优化器状态 + 梯度 + 参数分片
Stage 3 的核心思想:
不仅优化器状态、梯度被分片,连模型参数(weights)本身也被分片(partition)。
在 Stage 1 和 2 里,每张 GPU 依然保留了完整一份模型参数 ,只是减少了优化器和梯度的冗余。
到了 Stage 3,DeepSpeed 决定更激进:
每张 GPU 只保留自己负责的那一部分参数、梯度、优化器状态。
这样,显存使用量几乎可以和 GPU 数量线性缩放。
计算和通信过程如下:
-
前向传播 (Forward Pass)
-
需要用到模型参数时,DeepSpeed 从不同 GPU 上 gather 对应分片;
-
执行完该层的计算后,会释放这些参数,防止占显存;
-
下一层重复同样的过程。
-
-
反向传播 (Backward Pass)
-
当计算梯度时,梯度也会被分片存储;
-
只更新本 GPU 负责的参数和梯度;
-
需要时再通过 reduce-scatter/all-gather 进行同步。
-
-
参数更新 (Optimizer Step)
-
每张 GPU 只更新自己那份参数;
-
优化器状态(m, v)也按分片更新;
-
更新完后全局参数保持一致。
-
具体过程如下图所示:
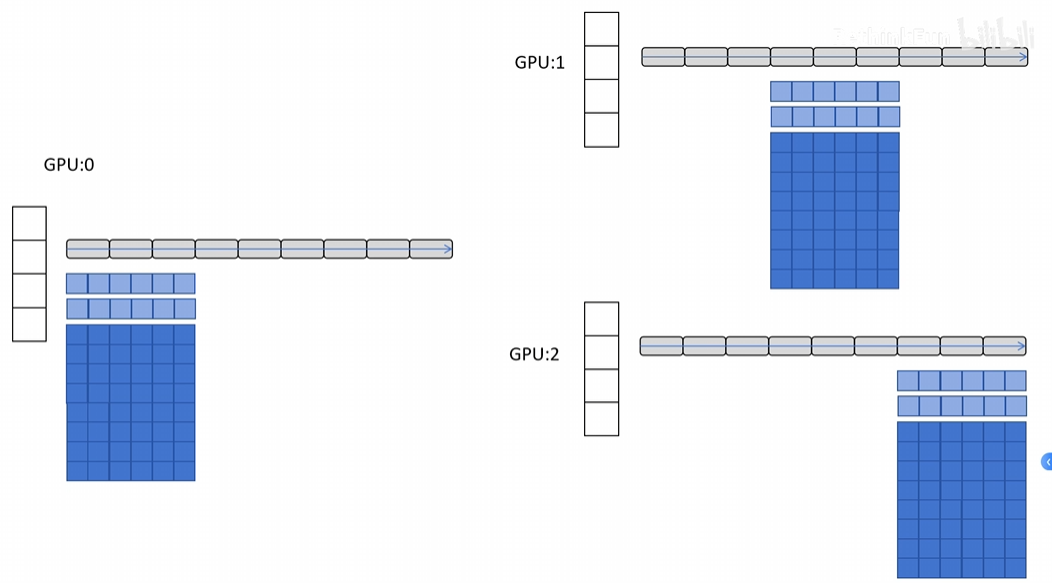
Stage 3 的结构直观理解
假设我们有一个 100 亿参数的模型,用 4 张 GPU。
| 阶段 | 每张 GPU 存的内容 |
|---|---|
| Stage 1 | 全部参数 + ¼ 优化器状态 |
| Stage 2 | 全部参数 + ¼ 梯度 + ¼ 优化器状态 |
| Stage 3 | ¼ 参数 + ¼ 梯度 + ¼ 优化器状态 |
换句话说,每张 GPU 不再持有完整模型,只持有一部分。
当某个层需要计算时,它会临时从其他 GPU gather(收集) 相应的参数,计算完再释放。
挖坑:接下来还会继续更新模型并行,具体代码实现的部分
参考资料: