
文章目录
- [Ⅰ. `HTTP`协议模块的子模块划分](#Ⅰ.
HTTP协议模块的子模块划分) - [Ⅱ. `Util`工具类功能设计与类设计](#Ⅱ.
Util工具类功能设计与类设计) - [Ⅲ. 接口实现](#Ⅲ. 接口实现)
-
- [1、字符串分割函数 `split()`](#1、字符串分割函数
split()) - [2、从文件读取数据 `read_file()`](#2、从文件读取数据
read_file()) - [3、向文件写入数据 `write_file()`](#3、向文件写入数据
write_file()) - [4、`URL`编码 `url_encode()`](#4、
URL编码url_encode()) - [5、`URL`解码 `url_decode()`](#5、
URL解码url_decode()) - [6、状态码对应信息 && 请求资源格式](#6、状态码对应信息 && 请求资源格式)
- 7、判断文件是否为一个目录/普通文件
- 8、判断一个`HTTP`资源路径是否有效
- [1、字符串分割函数 `split()`](#1、字符串分割函数
Ⅰ. HTTP协议模块的子模块划分
我们实现了 muduo 服务器框架之后,就可以被很多应用层协议包装起来使用,下面我们就以最常见的 HTTP 协议为例,搭建一个 HTTP 服务器!
HTTP 协议模块用于对高并发服务器模块进行协议支持,基于提供的协议支持能够更方便的完成指定协议服务器的搭建。而 HTTP 协议支持模块的实现,可以细分为以下几个模块。
1、Util工具模块
这个模块的功能就是 提供一些服务器需要的功能性工具接口,方便使用者直接调用!大概需要提供以下这些接口:
- 读取文件内容
- 向文件写入内容
URL编码URL解码- 通过
HTTP状态码获取描述信息 - 根据文件后缀名获取
mime(即想要请求的文件格式) - 判断一个文件是否是目录
- 判断一个文件是否是一个普通文件
- 判断一个
HTTP资源路径是否有效
2、HttpRequest请求模块
这个模块是 HTTP 请求数据模块,用于存储 HTTP 的请求信息,然后按照 HTTP 请求格式进行解析,得到各个关键要素放到 Request 中,这样子能让 HTTP 请求的分析更加的方便!
要分析的内容无非就是请求信息,如下所示:
- 请求方法
URL:- 资源路径
- 查询字符串
- 协议版本
- 头部字段
- 正文
所以需要提供以下接口:
- 头部字段的插入和获取
- 查询字符串的插入和获取
- 长连接和短连接的判断
- 正文长度的获取
3、HttpResponse响应模块
这个模块和上面的请求模块就是相反的,主要存储 HTTP 的响应信息,在进行业务处理的同时,让使用者向 Response 中填充响应要素,完毕后将其组织成为 HTTP 响应格式的数据,发送给客户端,这样子能让 HTTP 响应的过程操作变得简单!
要操作的内容无非就是响应信息,如下所示:
- 协议版本
- 响应状态码
- 状态码描述信息
- 头部字段
- 正文
所以需要提供以下接口:
- 头部字段的插入和获取
- 长连接和短连接的设置与判断
- 正文的设置
4、HttpContext上下文模块
这个模块用于记录 HTTP 请求的接收和处理进度,因为有可能出现一种情况,就是接收的数据并不是一条完整的 HTTP 请求数据,也就是请求的处理需要在多次收到数据后才能处理完成,所以在每次处理的时候,就需要将处理进度记录起来,以便于下次从当前进度继续向下处理,最终得到一个完整 HttpRequest 请求信息对象,因此 在请求数据的接收以及解析部分需要一个上下文来进行控制接收和处理节奏。
这个模块要关心的要素如下所示:
- 已经接收并处理的请求信息
- 接收状态(即处于何种阶段):
- 接收请求行(当前处于接收并处理请求行的阶段)
- 接收请求头部(表示请求头部的接收还没有完毕)
- 接收正文(表示还有正文没有接收完毕)
- 接收数据完毕(这是一个接收完毕,可以对请求进行处理的阶段)
- 接收处理请求出错
- 响应状态码:
- 在请求的接收并处理中,有可能会出现各种不同的问题,比如解析出错、访问的资源不对、没有权限等等,而这些错误的响应状态码都是不一样的。
所以需要提供以下接口:
- 接收并处理请求数据:
- 接收请求行
- 解析请求行
- 接收头部
- 解析头部
- 接收正文
- 返回解析完毕的请求信息
- 返回响应状态码
- 返回接收解析状态
5、HttpServer服务器模块
这个模块是最终给组件使用者提供的 HTTP 服务器模块了,用于以简单的接口实现 HTTP 服务器的搭建。
HttpServer 模块内部如下元素:
- 一个
TcpServer对象:实现服务器的搭建。 - 两个提供给
TcpServer对象的接口:连接建立成功设置上下文接口,数据处理接口。 - 一个哈希表存储请求与处理函数的映射表 :组件使用者向
HttpServer设置哪些请求应该使用哪些函数进行处理,等TcpServer收到对应的请求就会使用对应的函数进行处理。
Ⅱ. Util工具类功能设计与类设计
这个模块的功能就是 提供一些服务器需要的功能性工具接口,方便使用者直接调用!大概需要提供以下这些接口:
- 从文件读取内容
- 向文件写入内容
URL编码URL解码- 通过
HTTP状态码获取描述信息 - 根据文件后缀名获取
mime(即想要请求的文件格式) - 判断一个文件是否是目录
- 判断一个文件是否是一个普通文件
- 判断一个
HTTP资源路径是否有效
下面是 Util 类的大体框架:(实现时候会有其它辅助函数)
cpp
class Util
{
public:
// 字符串分割函数,将src字符串按照sep字符串进行分割,得到的各个子串放到arr中,最终返回子串的数量
static size_t split(const std::string& src, const std::string& sep, std::vector<std::string>* arr);
// 从文件读取内容,将读取的内容放到一个buffer中
static bool read_file(const std::string& filename, std::string* buffer);
// 向文件写入内容,要写的内容存放在buffer中
static bool write_file(const std::string& filename, const std::string& buffer);
// URL编码,避免URL中资源路径与查询字符串中的特殊字符与HTTP请求中特殊字符产生歧义
// 编码格式:将特殊字符的ascii值,转换为两个16进制字符以及一个前缀% 比如C++ -> C%2B%2B
// 不编码的特殊字符: RFC3986文档规定 . - _ ~ 字母,数字属于绝对不编码字符
// RFC3986文档规定,编码格式 %HH
// W3C标准中规定,查询字符串中的空格,需要编码为+, 解码则是+转空格
static std::string url_encode(const std::string& url, bool convert_space_to_plus);
// URL解码
static std::string url_decode(const std::string& url, bool convert_plus_to_space);
// 通过HTTP状态码获取描述信息
static std::string get_information_from_status(int status);
// 根据文件后缀名获取mime(即想要请求的文件格式)
static std::string get_mime_from_suffix(const std::string& filename);
// 判断一个文件是否是目录
static bool is_directory(const std::string& filename);
// 判断一个文件是否是一个普通文件
static bool is_regular_file(const std::string& filename);
// 判断一个HTTP资源路径是否有效
// /index.html --- 前边的/叫做相对根目录,映射的是某个服务器上的子目录
// 想表达的意思就是,客户端只能请求相对根目录中的资源,其他地方的资源都不予理会
// 而/../login --- 这个路径中的..会让路径的查找跑到相对根目录之外,这是不合理的,不安全的
static bool is_path_valid(const std::string& path);
};Ⅲ. 接口实现
1、字符串分割函数 split()
实现并不难,但是要注意细节,就是如果有重复的 sep 字符串的话,此时我们需要判断一下 cur 和 pre 的关系,如果它们截取的是一个空串的话,那么就得需要过滤一下,简单地说就是如果截取长度为零的话就不用处理!
cpp
// 字符串分割函数,将src字符串按照sep字符串进行分割,得到的各个子串放到arr中,最终返回子串的数量
static size_t split(const std::string& src, const std::string& sep, std::vector<std::string>* arr)
{
// src:"There are two needles in this haystack with needles."
// sep:"needle"
// 则第一个位置为14
size_t cur = src.find(sep);
size_t pre = 0;
while(cur != std::string::npos)
{
if(cur - pre > 0)
arr->push_back(src.substr(pre, cur - pre)); // 要过滤掉空串的情况
pre = cur + sep.size();
cur = src.find(sep, cur + sep.size());
}
if(src.size() - pre > 0)
arr->push_back(src.substr(pre)); // 别忘了最后一个子串(也要判断是否为空串)
return arr->size();
} 测试用例:
cpp
#include "httpserver.hpp"
int main()
{
// std::string src = "There are two needles in this haystack with needles.";
// std::string sep = "needle";
std::string src = "abc asd asdv ";
std::string sep = " ";
std::vector<std::string> arr;
size_t n = Util::split(src, sep, &arr);
for(int i = 0; i < n; ++i)
DLOG("[%s]", arr[i].c_str());
return 0;
}
[liren@VM-8-7-centos http]$ ./main
[140516807022400 2023-10-30 15:02:45 main.cc:12] [abc]
[140516807022400 2023-10-30 15:02:45 main.cc:12] [asd]
[140516807022400 2023-10-30 15:02:45 main.cc:12] [asdv]2、从文件读取数据 read_file()
这里我们使用的是 c++ 中的输入文件流 std::ifstream 来操作,具体参考下面代码:
cpp
// 从文件读取内容,将读取的内容放到一个buffer中
static bool read_file(const std::string& filename, std::string* buffer)
{
// 1. 创建二进制输入文件流
std::ifstream ifs(filename, std::ios::binary);
if(ifs.is_open() == false)
{
ELOG("open %s file failed!", filename.c_str());
return false;
}
// 2. 偏移到末尾,然后通过此时的偏移量来获取文件的大小,最后别忘了重新偏移到开头
ifs.seekg(0, ifs.end);
size_t file_size = ifs.tellg();
ifs.seekg(0, ifs.beg);
// 3. 根据文件大小写到buffer中
buffer->resize(file_size);
ifs.read(&(*buffer)[0], file_size); // 因为c_str()返回的是常量字符串,和参数不匹配,所以这里只能用取地址的方式传入buffer
if(ifs.good() == false)
{
ELOG("read %s file failed!", filename.c_str());
ifs.close();
return false;
}
// 4. 最后关闭文件流
ifs.close();
return true;
} 测试代码(执行结果只给出部分,节省篇幅):
cpp
#include "httpserver.hpp"
int main()
{
std::string buffer;
bool ret = Util::read_file("../../example/eventfd.cpp", &buffer);
if(ret != false)
DLOG("\n%s", buffer.c_str());
return 0;
}
// 执行结果:
[liren@VM-8-7-centos http]$ ./main
[140639060961088 2023-10-30 15:22:26 main.cc:8]
#include <iostream>
#include <sys/eventfd.h>
#include <unistd.h>
using namespace std;
int main()
{
// 创建一个eventfd
int efd = eventfd(0, EFD_CLOEXEC | EFD_NONBLOCK);
if(efd < 0)
{
perror("eventfd error");
......3、向文件写入数据 write_file()
cpp
// 向文件写入内容,要写的内容存放在buffer中
static bool write_file(const std::string& filename, const std::string& buffer)
{
// 1. 创建二进制输出文件流
std::ofstream ofs(filename, std::ios::binary);
if(ofs.is_open() == false)
{
ELOG("open %s file failed!", filename.c_str());
return false;
}
// 2. 将buffer中的数据写入文件中
ofs.write(buffer.c_str(), buffer.size());
if(ofs.good() == false)
{
ELOG("write %s file failed!", filename.c_str());
ofs.close();
return false;
}
// 3. 最后关闭文件流
ofs.close();
return true;
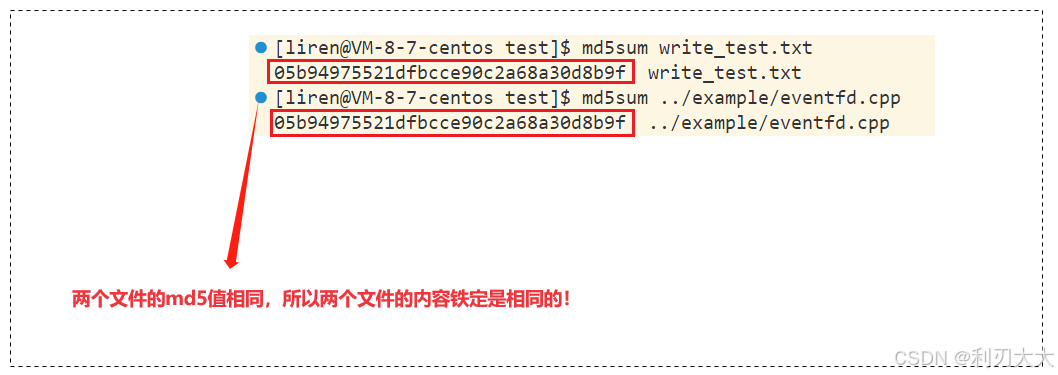
} 测试用例(无非就是上面读取完的结果,写入到一个新文件,然后看看两个文件的 md5 值的区别):
cpp
#include "httpserver.hpp"
int main()
{
std::string buffer;
bool ret = Util::read_file("../../example/eventfd.cpp", &buffer);
if(ret != false)
DLOG("\n%s", buffer.c_str());
// 将buffer中的数据写入新文件
ret = Util::write_file("../../test/write_test.txt", buffer);
if(ret != false)
DLOG("\n%s", buffer.c_str());
return 0;
}
4、URL编码 url_encode()
编码其实不难,主要是注意编码的规则要求,就是将特殊字符的 ascii 值,转换为两个十六进制字符,然后前面带上 % 即可,也就是 %HH 的格式!不过还有一些不编码的特殊字符,比如 RFC3986文档规定 .、 - 、_ 、~、字母以及数字属于绝对不编码字符!
此外 W3C 标准中规定,查询字符串中的空格,需要编码为 + ,而解码则是 + 转空格。所以为了使用者方便,我们提供一个布尔值变量 convert_space_to_plus 由使用者设置,如果想让空格变成 + 号的话,则让其为 true 即可!
cpp
// URL编码,避免URL中资源路径与查询字符串中的特殊字符与HTTP请求中特殊字符产生歧义
static std::string url_encode(const std::string& url, bool convert_space_to_plus)
{
std::string ret;
for(int i = 0; i < url.size(); ++i)
{
// 数字、字母以及不编码的字符直接尾插即可
if(url[i] == '.' || url[i] == '-' || url[i] == '_' || url[i] == '~' || isalnum(url[i]))
ret += url[i];
else if(url[i] == ' ' && convert_space_to_plus == true) // 如果为空格并且要求转化为+而不是编码的话,则直接尾插+即可
ret += '+';
else
{
// 剩下的就是要编码的符号了!
// 下面直接使用 snprintf() 函数,格式化然后存放到tmp中,最后再尾插到ret即可
char tmp[4] = { 0 };
snprintf(tmp, 4, "%%%02X", url[i]); // %%表示输出真实的%,%02X表示输出占2位,不够位的话补充前置0的大写十六进制数
ret += tmp;
}
}
return ret;
} 测试代码:
cpp
#include "httpserver.hpp"
int main()
{
std::cout << Util::url_encode("c++", false) << std::endl;
std::cout << Util::url_encode("c ", true) << std::endl;
std::cout << Util::url_encode("c ", false) << std::endl;
std::cout << Util::url_encode("/login/user=lirendada & id = 2", true) << std::endl;
std::cout << Util::url_encode("/login/user=lirendada & id = 2", false) << std::endl;
return 0;
}
// 执行结果:
[liren@VM-8-7-centos http]$ ./main
c%2B%2B
c++
c%20%20
%2Flogin%2Fuser%3Dlirendada+%26+id+%3D+2
%2Flogin%2Fuser%3Dlirendada%20%26%20id%20%3D%2025、URL解码 url_decode()
解码比编码其实要简单一些,就是遇到 % 号然后对其后面两个十六进制位进行转化后变成十进制位即可,其中第一个数字左移 4 位(也就是乘以 16 )然后加上第二个数字,比如 %2b 变成 (2<<4)+11 = 43。
其中将十六进制转化为十进制的功能函数提炼出来,单独作为一个模块 hex_to_dec()。
cpp
// URL解码
static std::string url_decode(const std::string& url, bool convert_plus_to_space)
{
// 即遇到了%号则将紧随其后的2个字符转换为数字,第一个数字左移4位(也就是乘以16)然后加上第二个数字,比如%2b -> 2<<4+11 = 43
std::string ret;
for(int i = 0; i < url.size(); ++i)
{
// 对于+号的特殊处理
if(url[i] == '+' && convert_plus_to_space == true)
{
ret += ' ';
continue;
}
if(url[i] == '%' && (i + 2) < url.size())
{
int n1 = hex_to_dec(url[i + 1]);
int n2 = hex_to_dec(url[i + 2]);
ret += (char)((n1 << 4) + n2);
i += 2;
continue;
}
// 剩下的就是不需要解码的
ret += url[i];
}
return ret;
}
// 十六进制转十进制的功能函数
static int hex_to_dec(char c)
{
if(c >= '0' && c <= '9')
return c - '0';
else if(c >= 'a' && c <= 'z')
return c - 'a' + 10;
else if(c >= 'A' && c <= 'Z')
return c - 'A' + 10;
return -1;
} 测试代码:
cpp
#include "httpserver.hpp"
int main()
{
std::cout << Util::url_decode("c++", true) << std::endl;
std::cout << Util::url_decode("c++", false) << std::endl << std::endl;
std::cout << Util::url_decode("c%20%20", true) << std::endl;
std::cout << Util::url_decode("c%20%20", false) << std::endl << std::endl;
std::cout << Util::url_decode("%2Flogin%2Fuser%3Dlirendada+%26+id+%3D+2", false) << std::endl;
std::cout << Util::url_decode("%2Flogin%2Fuser%3Dlirendada%20%26%20id%20%3D%202", false) << std::endl;
return 0;
}
// 执行结果:
[liren@VM-8-7-centos http]$ ./main
c
c++
c
c
/login/user=lirendada+&+id+=+2
/login/user=lirendada & id = 26、状态码对应信息 && 请求资源格式
对应这两个文件,其实可以直接从网上找到,这里我们将其作为全局变量放到哈希表中使用即可!
cpp
// 状态码对应信息的哈希表
std::unordered_map<int, std::string> status_msg = {
{100, "Continue"},
{101, "Switching Protocol"},
{102, "Processing"},
{103, "Early Hints"},
{200, "OK"},
{201, "Created"},
{202, "Accepted"},
{203, "Non-Authoritative Information"},
{204, "No Content"},
{205, "Reset Content"},
{206, "Partial Content"},
{207, "Multi-Status"},
{208, "Already Reported"},
{226, "IM Used"},
{300, "Multiple Choice"},
{301, "Moved Permanently"},
{302, "Found"},
{303, "See Other"},
{304, "Not Modified"},
{305, "Use Proxy"},
{306, "unused"},
{307, "Temporary Redirect"},
{308, "Permanent Redirect"},
{400, "Bad Request"},
{401, "Unauthorized"},
{402, "Payment Required"},
{403, "Forbidden"},
{404, "Not Found"},
{405, "Method Not Allowed"},
{406, "Not Acceptable"},
{407, "Proxy Authentication Required"},
{408, "Request Timeout"},
{409, "Conflict"},
{410, "Gone"},
{411, "Length Required"},
{412, "Precondition Failed"},
{413, "Payload Too Large"},
{414, "URI Too Long"},
{415, "Unsupported Media Type"},
{416, "Range Not Satisfiable"},
{417, "Expectation Failed"},
{418, "I'm a teapot"},
{421, "Misdirected Request"},
{422, "Unprocessable Entity"},
{423, "Locked"},
{424, "Failed Dependency"},
{425, "Too Early"},
{426, "Upgrade Required"},
{428, "Precondition Required"},
{429, "Too Many Requests"},
{431, "Request Header Fields Too Large"},
{451, "Unavailable For Legal Reasons"},
{501, "Not Implemented"},
{502, "Bad Gateway"},
{503, "Service Unavailable"},
{504, "Gateway Timeout"},
{505, "HTTP Version Not Supported"},
{506, "Variant Also Negotiates"},
{507, "Insufficient Storage"},
{508, "Loop Detected"},
{510, "Not Extended"},
{511, "Network Authentication Required"}
};
// 文件后缀对应资源格式的哈希表
std::unordered_map<std::string, std::string> mime_msg = {
{".aac", "audio/aac"},
{".abw", "application/x-abiword"},
{".arc", "application/x-freearc"},
{".avi", "video/x-msvideo"},
{".azw", "application/vnd.amazon.ebook"},
{".bin", "application/octet-stream"},
{".bmp", "image/bmp"},
{".bz", "application/x-bzip"},
{".bz2", "application/x-bzip2"},
{".csh", "application/x-csh"},
{".css", "text/css"},
{".csv", "text/csv"},
{".doc", "application/msword"},
{".docx", "application/vnd.openxmlformats-officedocument.wordprocessingml.document"},
{".eot", "application/vnd.ms-fontobject"},
{".epub", "application/epub+zip"},
{".gif", "image/gif"},
{".htm", "text/html"},
{".html", "text/html"},
{".ico", "image/vnd.microsoft.icon"},
{".ics", "text/calendar"},
{".jar", "application/java-archive"},
{".jpeg", "image/jpeg"},
{".jpg", "image/jpeg"},
{".js", "text/javascript"},
{".json", "application/json"},
{".jsonld", "application/ld+json"},
{".mid", "audio/midi"},
{".midi", "audio/x-midi"},
{".mjs", "text/javascript"},
{".mp3", "audio/mpeg"},
{".mpeg", "video/mpeg"},
{".mpkg", "application/vnd.apple.installer+xml"},
{".odp", "application/vnd.oasis.opendocument.presentation"},
{".ods", "application/vnd.oasis.opendocument.spreadsheet"},
{".odt", "application/vnd.oasis.opendocument.text"},
{".oga", "audio/ogg"},
{".ogv", "video/ogg"},
{".ogx", "application/ogg"},
{".otf", "font/otf"},
{".png", "image/png"},
{".pdf", "application/pdf"},
{".ppt", "application/vnd.ms-powerpoint"},
{".pptx", "application/vnd.openxmlformats-officedocument.presentationml.presentation"},
{".rar", "application/x-rar-compressed"},
{".rtf", "application/rtf"},
{".sh", "application/x-sh"},
{".svg", "image/svg+xml"},
{".swf", "application/x-shockwave-flash"},
{".tar", "application/x-tar"},
{".tif", "image/tiff"},
{".tiff", "image/tiff"},
{".ttf", "font/ttf"},
{".txt", "text/plain"},
{".vsd", "application/vnd.visio"},
{".wav", "audio/wav"},
{".weba", "audio/webm"},
{".webm", "video/webm"},
{".webp", "image/webp"},
{".woff", "font/woff"},
{".woff2", "font/woff2"},
{".xhtml", "application/xhtml+xml"},
{".xls", "application/vnd.ms-excel"},
{".xlsx", "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"},
{".xml", "application/xml"},
{".xul", "application/vnd.mozilla.xul+xml"},
{".zip", "application/zip"},
{".3gp", "video/3gpp"},
{".3g2", "video/3gpp2"},
{".7z", "application/x-7z-compressed"}
}; 有个这两个哈希表之后,我们的工具函数实现起来就非常的简单了,就是哈希表的基本操作,如下所示:
cpp
// 通过HTTP状态码获取描述信息
static std::string get_information_from_status(int status)
{
auto it = status_msg.find(status);
if(it == status_msg.end())
return "unknown status";
return status_msg[status];
}
// 根据文件后缀名获取mime(即想要请求的文件格式)
static std::string get_mime_from_suffix(const std::string& filename)
{
// 先获取后缀名
size_t pos = filename.find_last_of('.');
if(pos == std::string::npos)
return "application/octet-stream"; // 错误或者没找到的话返回一个二进制流的格式
std::string suffix = filename.substr(pos);
// 再判断存不存在
auto it = mime_msg.find(suffix);
if(it == mime_msg.end())
return "application/octet-stream"; // 错误或者没找到的话返回一个二进制流的格式
return mime_msg[suffix];
}7、判断文件是否为一个目录/普通文件
如果我们直接用字符串操作去判断的话不太好搞,我们可以使用 stat() 函数,获取文件的属性,然后通过其中的 st_mode 也就是文件的类型,辅助两个宏,一个是 S_ISDIR ,另一个是 S_ISREG,分别判断是否为目录和普通文件类型即可!
cpp
// 判断一个文件是否是目录
static bool is_directory(const std::string& filename)
{
// 通过stat函数获取文件的属性,然后通过S_ISDIR来判断其中的文件类型是否为目录即可
struct stat buf = { 0 };
int ret = stat(filename.c_str(), &buf);
if(ret == -1)
return false;
return S_ISDIR(buf.st_mode);
}
// 判断一个文件是否是一个普通文件
static bool is_regular_file(const std::string& filename)
{
// 通过stat函数获取文件的属性,然后通过S_ISREG来判断其中的文件类型是否为目录即可
struct stat buf = { 0 };
int ret = stat(filename.c_str(), &buf);
if(ret == -1)
return false;
return S_ISREG(buf.st_mode);
}8、判断一个HTTP资源路径是否有效
判断路径是否有效,其实只需要判断一下该路径是否非法访问当前根目录以外的资源即可!
我们可以以斜杆 / 为分割字符,进行字符串分割,此时分割出多少个子串,就相当于进入了多少层目录,但是因为有 .. 的存在,我们就需要遍历判断一下这些子串有多少个 .. ,然后用一个变量 level 记录当前的层数大小,遇到 .. 则让 level-- ,表示退出该层目录;如果不是的话则让 level++ 表示进入了一层目录!然后只要 判断 level 是否小于零即可,如果小于零说明访问到了根目录以外的内容,是不合法的,直接返回错误即可!
cpp
// 判断一个HTTP资源路径是否有效
// /index.html --- 前边的/叫做相对根目录,映射的是某个服务器上的子目录
// 想表达的意思就是,客户端只能请求相对根目录中的资源,其他地方的资源都不予理会
// 而/../login --- 这个路径中的..会让路径的查找跑到相对根目录之外,这是不合理的,不安全的
static bool is_path_valid(const std::string& path)
{
// 1. 以斜杆/为分割字符,进行字符串分割
std::vector<std::string> substr;
split(path, "/", &substr);
// 2. 然后遍历每个子串
int level = 0; // 表示当前的层数
for(int i = 0; i < substr.size(); ++i)
{
if(substr[i] == "..")
{
level--;
if(level < 0)
return false; // 如果小于0说明访问到了根目录以外的内容,是不合法的,直接false
}
else
level++; // 如果不是..的话,那么有多少个子串,就相当于进入了多少个目录,则让level++即可
}
return true;
}