1. Redis 是什么?有哪些优缺点?
一、Redis 是什么?
标准回答
Redis(Remote Dictionary Server)是一个开源的、基于内存的高性能键值数据库 ,支持多种数据结构,常用于缓存、消息队列、排行榜、会话存储等场景。
它采用单线程 + IO 多路复用 模型,数据存储在内存中,并支持持久化到磁盘,保证数据安全。
补充细节(加分点):
- 开发语言:C 语言编写,性能极高
- 数据结构:支持 String、List、Set、Hash、ZSet、Bitmap、HyperLogLog、Geo 等
- 持久化:支持 RDB(快照)和 AOF(追加日志)两种方式
- 高可用:支持主从复制、哨兵模式、Cluster 集群
- 应用场景:缓存加速、分布式锁、限流、排行榜、延时队列、消息队列等
二、Redis 的优点
| 优点 | 说明 |
|---|---|
| 高性能 | 数据存储在内存中,读写速度可达 10万+ QPS,远高于传统关系型数据库 |
| 多数据结构 | 除了简单的 key-value,还支持丰富的数据结构,方便实现复杂业务逻辑 |
| 持久化支持 | RDB 和 AOF 两种持久化方式,既能保证性能又能保证数据安全 |
| 高可用与扩展性 | 支持主从复制、哨兵模式、Cluster 集群,方便水平扩展 |
| 原子性操作 | 单线程模型保证命令的原子性,不需要额外加锁 |
| 丰富的功能 | 发布订阅(Pub/Sub)、Lua 脚本、事务、Pipeline 等 |
三、Redis 的缺点
| 缺点 | 说明 | 解决思路 |
|---|---|---|
| 内存成本高 | 数据存储在内存中,成本比磁盘高 | 只缓存热点数据,使用内存压缩(ziplist、intset) |
| 数据易丢失 | 如果不开启持久化,宕机会丢失数据 | 开启 AOF(everysec)或混合持久化 |
| 单线程 CPU 瓶颈 | 单线程处理命令,CPU 成为瓶颈 | 多实例分片、Cluster 集群 |
| 不适合大数据量全量存储 | 内存限制,无法像 MySQL 那样存储 TB 级数据 | 作为缓存层,配合数据库使用 |
| 大 key/热 key 问题 | 大 key 会阻塞线程,热 key 会造成访问集中 | 拆分大 key、热点数据分片 |
四、面试回答示例(流畅版)
Redis 是一个开源的内存型键值数据库,采用单线程 + IO 多路复用模型,支持多种数据结构,并且可以通过 RDB 和 AOF 持久化到磁盘。它的优点是性能极高、支持丰富数据结构、持久化、高可用和原子性操作,常用于缓存、分布式锁、排行榜等场景。
缺点是内存成本高、可能丢失数据、单线程 CPU 瓶颈、不适合大规模全量存储,以及可能出现大 key/热 key 问题。
在实际业务中,我们通常会结合数据库,把 Redis 作为缓存层使用,同时开启 AOF everysec 保证数据安全。
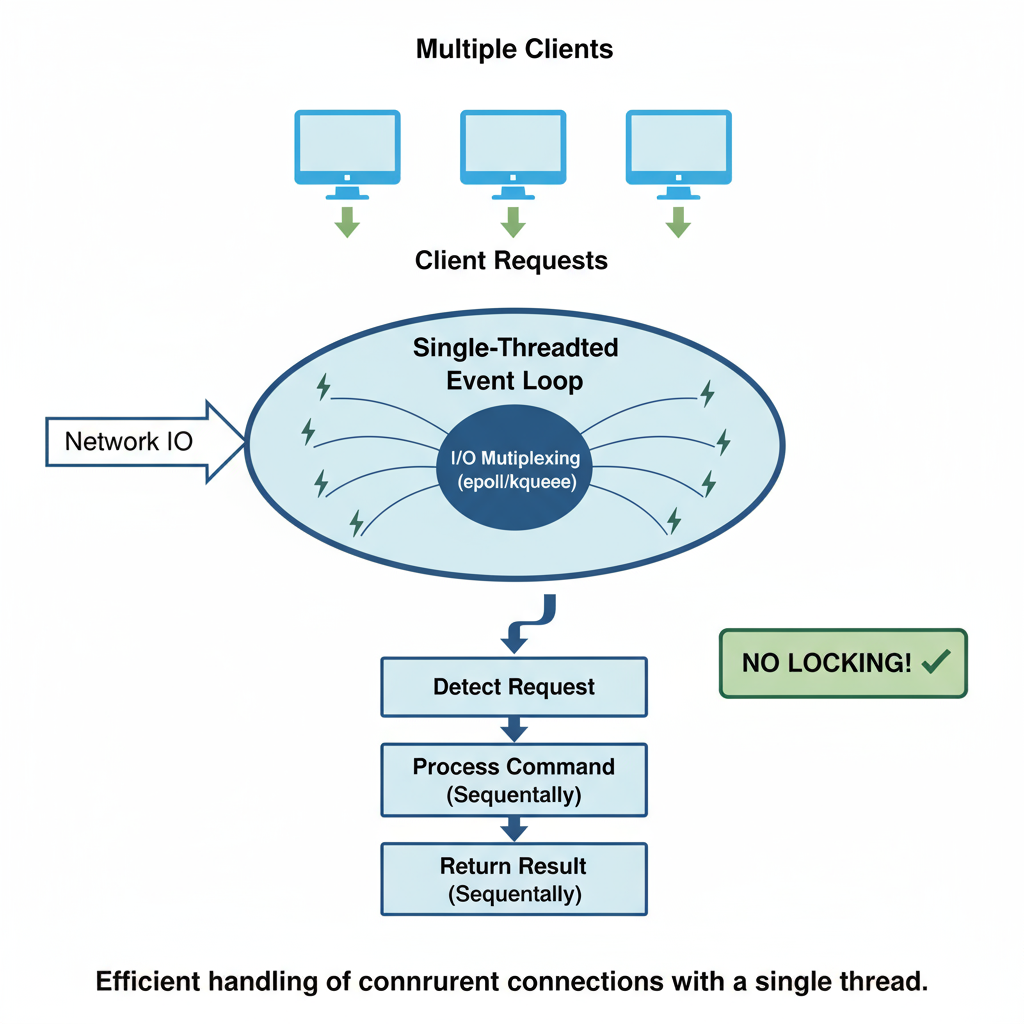
解答:Redis 的单线程 + IO 多路复用模型
1. 什么是单线程?
- 单线程 指的是 Redis 处理网络请求的核心模块(命令解析、执行、返回结果)只有一个线程来完成。
- 也就是说,Redis 一次只处理一个命令,不会同时执行多个命令。
- 这样做的好处:
- 避免多线程加锁开销(不需要考虑线程安全问题)
- 减少上下文切换(线程切换会消耗 CPU 时间)
- 代码实现简单,性能稳定
⚠️ 注意:
Redis 不是完全单线程,它在持久化(RDB/AOF 重写)、集群数据迁移 等场景会用到额外的子进程或线程,但核心命令执行是单线程。
2. 什么是 IO 多路复用?
- IO 多路复用 是一种高效处理多个网络连接的技术。
- Redis 使用 epoll(Linux)/ kqueue(BSD)/ select(通用) 来同时监听多个客户端连接。
- 它的作用是:一个线程就能同时管理成千上万个连接,而不是一个连接一个线程。
生活类比
想象你是一个餐厅服务员:
- 单线程:你一个人负责点菜、上菜、收钱(一次只做一件事)
- IO 多路复用 :你有一个呼叫器系统,可以同时监听 100 张桌子,一旦有桌子按铃,你就去处理那一桌的需求,而不是傻傻地一桌一桌轮流问。
3. Redis 的单线程 + IO 多路复用工作流程
- 监听所有客户端连接(通过 epoll/kqueue)
- 事件触发:某个连接有数据可读(客户端发来命令)或可写(可以返回结果)
- 事件放入队列:Redis 把这些事件放到事件队列中
- 单线程依次处理事件 :
- 读取命令
- 解析命令
- 执行命令(操作内存数据)
- 返回结果
- 继续监听,等待下一个事件
流程图(简化版)
复制代码
客户端1 ─┐ 客户端2 ─┼─> epoll 监听事件 ─> 事件队列 ─> 单线程依次处理 客户端3 ─┘
4. 为什么单线程还能很快?
- 内存操作:Redis 所有数据都在内存中,读写速度接近纳秒级
- 无锁竞争:单线程避免了多线程加锁的性能损耗
- IO 多路复用:一个线程就能同时处理成千上万个连接
- 高效数据结构:底层用 SDS、跳表、哈希表等优化结构
- 命令执行快:大部分命令时间复杂度低(O(1) 或 O(logN))
5. 面试回答示例
Redis 的核心命令执行是单线程的,这样可以避免多线程加锁和上下文切换的开销,保证命令的原子性。
它通过 IO 多路复用(epoll/kqueue)同时监听多个客户端连接,把有事件的连接放到事件队列中,然后单线程依次处理。
这种模型结合内存存储和高效数据结构,使得 Redis 即使是单线程,也能轻松处理每秒十万级的请求。
6. 补充加分点(面试官会喜欢)
- Redis 6.0 之后引入了多线程 IO(只用于网络读写,命令执行仍是单线程),进一步提升了高并发场景下的性能。
- 如果 CPU 成为瓶颈,可以通过多实例分片 或Cluster 集群来扩展。
2. Redis 支持哪些数据类型?使用场景分别是什么?
Redis 支持以下数据类型:
-
String
- 最基本的类型,二进制安全,可以存储字符串、数字、JSON 等
- 场景:缓存对象、计数器、分布式锁
- 案例 :
SET user:1001 '{"name":"Tom"}'
-
List
- 双向链表结构,可以从两端插入/弹出
- 场景:消息队列、任务列表
- 案例 :
LPUSH queue task1
-
Set
- 无序集合,元素唯一
- 场景:去重、标签系统
- 案例 :
SADD tags java python
-
Hash
- 类似 Map,适合存储对象的多个字段
- 场景:用户信息、配置项
- 案例 :
HSET user:1001 name Tom age 20
-
ZSet(Sorted Set)
- 有序集合,每个元素有一个分数(score)
- 场景:排行榜、延时任务
- 案例 :
ZADD rank 100 Tom
-
Bitmap
- 位图,适合存储布尔状态
- 场景:签到、活跃用户统计
- 案例 :
SETBIT sign:20250101 1001 1
-
HyperLogLog
- 基数统计,内存占用极小
- 场景:UV 统计
- 案例 :
PFADD uv 1001
-
Geo
- 地理位置存储与计算
- 场景:附近的人、地图服务
- 案例 :
GEOADD city 116.40 39.90 beijing
3. Redis 为什么这么快?
Redis 快的原因主要有:
- 内存存储:数据全部在内存中,访问速度接近 CPU 缓存速度
- 单线程模型:避免多线程锁竞争和上下文切换
- IO 多路复用:使用 epoll 处理大量连接
- 高效数据结构:SDS、ziplist、skiplist 等
- 优化的命令执行:命令解析和执行非常轻量
案例
在一次秒杀项目中,Redis 每秒处理了 10万+ 请求,而 MySQL 在同样场景下只能处理几千请求。
4. Redis 持久化方式有哪些?区别是什么?
(我们之前已经详细讲过 RDB 和 AOF,这里简述)
- RDB:定时快照,恢复快,可能丢数据
- AOF:记录写命令,数据安全,文件大,恢复慢
- 混合持久化:结合两者优点
5. Redis 过期策略有哪些?
Redis 过期策略:
- 定期删除:每隔一段时间随机抽取部分设置了过期时间的 key,检查是否过期并删除
- 惰性删除:访问 key 时才检查是否过期,过期则删除
- 内存淘汰:内存不足时,根据淘汰策略删除数据
1. 什么是 Redis 过期策略?
Redis 允许给 key 设置过期时间(TTL, Time To Live) ,一旦过期,Redis 会删除这个 key。
但是,删除策略有多种,不同策略会影响性能和内存占用。
Redis 采用的是 "定期删除(Periodic Deletion)+ 惰性删除(Lazy Deletion)" 结合的方式,并在内存不足时配合内存淘汰策略(Memory Eviction Policy)。
2. 三种过期策略
① 定时删除(Scheduled Deletion / Timer-based Deletion)
- 给每个 key 设置一个定时器(Timer),到期立即删除。
- 优点:内存释放及时
- 缺点:需要大量定时器,CPU(Central Processing Unit)开销大,影响性能
- Redis 不采用这种方式,因为会严重影响性能。
② 定期删除(Periodic Deletion)
- Redis 每隔一段时间(默认 100ms,即 0.1 秒)随机抽取部分设置了过期时间的 key,检查是否过期,如果过期就删除。
- 优点:控制 CPU 占用,不会一次性扫描所有 key
- 缺点:可能有部分过期 key 没被及时删除,占用内存
执行细节:
- Redis 会从**过期字典(Expire Dictionary)**中随机取出 N 个 key(默认 20 个)
- 检查是否过期,过期则删除
- 如果过期比例超过 25%,继续循环检查,直到比例下降
③ 惰性删除(Lazy Deletion)
- 当客户端访问某个 key 时,Redis 会先检查它是否过期,如果过期就删除并返回空(null)。
- 优点:对 CPU 友好,不会主动扫描
- 缺点:如果过期 key 从未被访问,就会一直占用内存
3. Redis 实际使用的策略
Redis 采用 定期删除(Periodic Deletion)+ 惰性删除(Lazy Deletion) 结合:
- 定期删除:减少过期 key 堆积
- 惰性删除:保证访问到的 key 一定是有效的
4. 内存淘汰策略(Memory Eviction Policy)
如果定期删除和惰性删除都没及时清理,导致内存不足,Redis 会触发内存淘汰策略 (maxmemory-policy):
| 策略名称 | 全称(英文补全) | 说明 |
|---|---|---|
volatile-lru |
Volatile Least Recently Used | 从设置了过期时间的 key 中淘汰最近最少使用的 |
allkeys-lru |
All Keys Least Recently Used | 从所有 key 中淘汰最近最少使用的 |
volatile-ttl |
Volatile Time To Live | 从设置了过期时间的 key 中淘汰即将过期的 |
allkeys-random |
All Keys Random | 从所有 key 中随机淘汰 |
volatile-random |
Volatile Random | 从设置了过期时间的 key 中随机淘汰 |
noeviction |
No Eviction | 不淘汰,直接返回错误 |
5. 执行流程图
┌───────────────────┐ │ 设置 TTL (Time To Live) │ └─────────┬─────────┘ │ ┌──────────▼──────────┐ │ 定期删除 (Periodic Deletion) │ └──────────┬──────────┘ │ ┌──────────▼──────────┐ │ 客户端访问 key │ └──────────┬──────────┘ │ ┌──────────▼──────────┐ │ 惰性删除 (Lazy Deletion) │ └──────────┬──────────┘ │ ┌──────────▼──────────┐ │ 内存不足? │───否──> 结束 └──────────┬──────────┘ │是 ┌──────────▼──────────┐ │ 内存淘汰策略 (Memory Eviction Policy) │ └─────────────────────┘
6. 案例
场景 :
假设你有一个电商系统,用户浏览商品时会缓存商品详情,TTL 设置为 10 分钟。
- 定期删除(Periodic Deletion):Redis 每 100ms 随机抽查部分商品缓存,发现过期的就删除
- 惰性删除(Lazy Deletion):如果某个商品缓存过期了,但用户没访问,就不会立即删除;等用户访问时才删除
- 内存淘汰策略(Memory Eviction Policy):如果缓存太多,内存不足,就会根据 LRU(Least Recently Used)策略淘汰一些最久没访问的商品缓存
7. 面试回答示例(带英文全称)
Redis 的过期策略是 定期删除(Periodic Deletion)+ 惰性删除(Lazy Deletion) 结合使用。
定期删除会每隔一段时间随机抽取部分设置了 TTL(Time To Live)的 key 检查是否过期,减少过期 key 堆积;惰性删除是在访问 key 时才检查是否过期,保证访问到的数据一定有效。
如果这两种方式都没及时清理,导致内存不足,Redis 会根据
maxmemory-policy执行 内存淘汰策略(Memory Eviction Policy) ,比如 LRU(Least Recently Used)、TTL 优先等。这种组合策略在性能(Performance)和内存利用率(Memory Utilization)之间做了平衡。
6. Redis 常见的内存淘汰策略有哪些?
volatile-lru:从设置了过期时间的 key 中淘汰最近最少使用的allkeys-lru:从所有 key 中淘汰最近最少使用的volatile-ttl:从设置了过期时间的 key 中淘汰即将过期的allkeys-random:随机淘汰volatile-random:随机淘汰设置了过期时间的 keynoeviction:不淘汰,直接返回错误
7. Redis 分布式锁的实现原理?如何保证安全释放?
1. 为什么需要分布式锁?
在分布式系统(Distributed System)中,多个服务实例可能会同时访问或修改同一份数据(例如库存、订单),如果不加控制,就会出现并发冲突(Concurrency Conflict) 。
分布式锁的作用就是保证同一时间只有一个客户端(Client)能操作某个资源。
2. Redis 分布式锁的核心原理
Redis 分布式锁的实现依赖于 SET 命令的扩展参数:
bash
SET key value NX EX expire_time- NX (Set if Not Exists,全称:Only Set Key if it Does Not Exist)
保证只有在 key 不存在时才能成功设置(原子性加锁) - EX expire_time (Expire Time in Seconds,全称:Set Expiration Time in Seconds)
设置锁的过期时间,防止死锁 - value:锁的唯一标识(通常是 UUID,全称:Universally Unique Identifier),用来区分不同客户端的锁
加锁流程
- 客户端生成一个唯一标识(UUID)
- 执行
SET lock_key UUID NX EX 10(10 秒过期) - 如果返回
OK,表示加锁成功;否则锁已被其他客户端持有
3. 安全释放锁的关键问题
问题 1:锁过期后被其他客户端获取
如果客户端 A 持有锁,但执行时间过长,锁过期了,客户端 B 获取了锁。
此时如果 A 直接执行 DEL lock_key,就会误删 B 的锁。
解决方案 :
释放锁时必须先检查锁的 value 是否是自己设置的 UUID,只有匹配才删除。
问题 2:检查和删除不是原子操作
如果用两条命令:
bash
GET lock_key
DEL lock_key在 GET 和 DEL 之间可能会被其他客户端抢锁,导致误删。
解决方案 :
使用 Lua 脚本(Lua Script) 保证检查和删除的原子性(Atomicity)。
安全释放锁的 Lua 脚本
Lua
if redis.call("GET", KEYS[1]) == ARGV[1] then
return redis.call("DEL", KEYS[1])
else
return 0
endKEYS[1]:锁的 keyARGV[1]:锁的唯一标识(UUID)- 如果锁的 value 等于 UUID,则删除锁并返回 1;否则返回 0
4. RedLock 算法(更安全的分布式锁)
RedLock 是 Redis 作者提出的分布式锁算法,用于多节点环境,保证更高的安全性。
原理
- 在多个 Redis 节点(建议 5 个)上同时加锁
- 必须在半数以上节点加锁成功才算加锁成功
- 锁的有效时间 = 原始过期时间 - 获取锁的耗时
- 释放锁时在所有节点执行 Lua 脚本删除
优点 :即使部分节点宕机,也能保证锁的安全性
缺点:实现复杂,性能比单节点锁低
5. 案例:库存扣减
场景:秒杀活动中,多个服务实例同时扣减库存
实现步骤:
- 客户端生成 UUID
SET stock_lock UUID NX EX 5(5 秒过期)- 扣减库存(操作数据库或 Redis)
- 使用 Lua 脚本安全释放锁
- 如果加锁失败,说明有其他客户端在操作,直接返回"抢购失败"
6. 面试回答示例(带英文全称)
Redis 分布式锁依赖
SET key value NX EX expire_time命令,其中 NX(Only Set Key if it Does Not Exist)保证原子性加锁,EX(Expire Time in Seconds)设置过期时间防止死锁,value 通常是 UUID(Universally Unique Identifier)用来区分不同客户端的锁。为了安全释放锁,需要先检查锁的 value 是否是自己设置的 UUID,并且使用 Lua Script(Lua 脚本)保证检查和删除的原子性。
在多节点环境中,可以使用 RedLock 算法,在多个 Redis 节点上同时加锁,必须半数以上节点成功才算加锁成功,这样即使部分节点宕机也能保证锁的安全性。
这种方式在高并发场景(High Concurrency Scenario)下可以有效防止并发冲突(Concurrency Conflict)。
7. 加分点
- Redis 6.0 之后支持多线程 IO(Input/Output),但分布式锁的命令执行仍是单线程(Single-threaded Execution)
- 过期时间要根据业务执行时间设置,避免锁提前过期
- 可以配合
WATCH机制或SET PX(Expire Time in Milliseconds)使用毫秒级过期时间
8. Redis 如何实现延时队列?
1. 什么是延时队列(Delayed Queue)?
延时队列是一种消息队列(Message Queue, MQ) ,它的特点是消息不会立即被消费,而是延迟一段时间后才被处理 。
常见场景:
- 订单超时取消(例如 30 分钟未支付自动取消)
- 延迟发送通知
- 定时任务调度
2. Redis 实现延时队列的常见方式
方式 1:基于 Sorted Set(有序集合)
原理:
- 使用 Redis 的 ZSet(Sorted Set,有序集合) 存储任务
score存储任务的执行时间(时间戳,Timestamp)- 定时轮询(Polling)取出
score <= 当前时间的任务执行
实现步骤:
- 生产者(Producer) 添加任务:
bash
ZADD delay_queue 1672531200 "order:1001"这里 1672531200 是 Unix 时间戳(Unix Timestamp),表示任务执行时间
- 消费者(Consumer) 定时扫描:
bash
ZRANGEBYSCORE delay_queue 0 current_timestamp LIMIT 0 1取出到期任务,然后执行并删除:
bash
ZREM delay_queue "order:1001"优点:
- 实现简单
- 支持按时间排序
缺点:
- 需要轮询(Polling),会有一定延迟
- 如果任务量大,扫描可能有性能压力
方式 2:基于 List + 延时阻塞
原理:
- 使用
BRPOP(Blocking Right Pop)阻塞读取任务 - 生产者先
sleep(延迟)再LPUSH任务到队列
缺点:
- 延迟逻辑在生产者端,不是真正的延时队列
- 不适合精确调度
方式 3:基于 Stream(Redis 5.0+)
原理:
- 使用 Redis Stream(流数据结构) 存储任务
- 消费者按时间顺序读取
- 延迟逻辑由消费者控制(例如定时检查)
优点:
- 支持消费者组(Consumer Group)
- 消息可持久化
缺点:
- 实现复杂度比 ZSet 高
方式 4:基于 Key 过期事件(Keyspace Notifications)
原理:
- 给任务 key 设置过期时间(TTL, Time To Live)
- 开启 Redis 键空间通知(Keyspace Notifications)
- 当 key 过期时,Redis 会发布事件,消费者订阅该事件并处理任务
配置:
bash
CONFIG SET notify-keyspace-events ExE 表示 Keyevent 事件,x 表示过期事件(Expired Events)
优点:
- 无需轮询,实时触发
- 延迟精度高
缺点:
- 需要开启通知功能(有额外性能开销)
- 过期事件不是持久化的,Redis 重启可能丢失任务
3. 推荐方案
- 如果任务量大、需要排序 → ZSet
- 如果需要实时触发、任务量不大 → Keyspace Notifications
- 如果需要多消费者并行处理 → Stream
4. 案例:订单超时取消(ZSet 实现)
生产者(下单时):
bash
ZADD order_delay_queue 1735660800 "order:1001"这里 1735660800 是订单超时时间(Unix 时间戳)
消费者(定时任务,每秒执行一次):
bash
local now = os.time()
local orders = redis.call("ZRANGEBYSCORE", "order_delay_queue", 0, now, "LIMIT", 0, 10)
for _, order_id in ipairs(orders) do
-- 取消订单逻辑
redis.call("ZREM", "order_delay_queue", order_id)
end5. 面试回答示例(带英文全称)
Redis 实现延时队列(Delayed Queue)最常用的方法是基于 ZSet(Sorted Set,有序集合) ,将任务作为 member,执行时间作为 score(时间戳,Timestamp)。
生产者(Producer)使用
ZADD添加任务,消费者(Consumer)定时使用ZRANGEBYSCORE获取到期任务并处理,然后用ZREM删除任务。这种方式实现简单,支持按时间排序,但需要轮询(Polling)。
如果需要实时触发,可以使用 Redis 的 Keyspace Notifications(键空间通知)监听过期事件(Expired Events);如果需要多消费者并行处理,可以使用 Redis Stream(流数据结构)。
在订单超时取消等场景中,ZSet 方案是最常用的,因为它能高效管理大量延时任务。
6. 加分点
- ZSet 的时间复杂度:
ZADD和ZREM是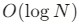 ,
,ZRANGEBYSCORE是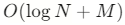 (M 为返回元素个数)
(M 为返回元素个数) - Keyspace Notifications 需要额外配置,且事件可能丢失
- Stream 支持持久化(Persistence)和消费者组(Consumer Group),适合高可靠场景
9. 详解解释Redis 如何实现秒杀系统?
1. 秒杀系统的特点
秒杀(Flash Sale)是电商高并发场景的典型案例,特点:
- 瞬时高并发(High Concurrency):可能在几秒内有几百万请求
- 库存有限(Limited Stock):先到先得
- 要求低延迟(Low Latency):用户体验要快
- 防止超卖(Overselling):库存不能卖超
Redis 因为是内存数据库(In-memory Database) ,读写速度极快,非常适合做秒杀的核心库存控制。
2. Redis 秒杀系统核心架构
架构流程
- 请求入口(API Gateway)
接收用户秒杀请求,做基础限流(Rate Limiting) - 用户资格校验(Eligibility Check)
检查用户是否有秒杀资格(登录状态、是否重复购买) - 库存预扣(Stock Pre-deduction)
使用 Redis 原子操作扣减库存 - 异步下单(Asynchronous Order Creation)
将成功的用户请求放入消息队列(Message Queue, MQ) - 订单系统(Order Service)
消费队列消息,生成订单并持久化到数据库(Database) - 支付系统(Payment Service)
完成支付,更新订单状态
3. Redis 实现库存扣减的关键方法
方法 1:原子递减(Atomic Decrement)
使用 DECR 或 DECRBY:
bash
DECR stock:product_1001- 如果结果 >= 0,表示扣减成功
- 如果结果 < 0,表示库存不足,需要回滚
缺点:可能出现超卖(多个请求同时扣减)
方法 2:Lua 脚本(Lua Script)保证原子性
Lua
local stock = redis.call("GET", KEYS[1])
if not stock then
return -1
end
if tonumber(stock) > 0 then
redis.call("DECR", KEYS[1])
return 1
else
return 0
endGET+DECR在 Lua 脚本中执行,保证原子性(Atomicity)- 返回 1 表示成功,0 表示库存不足
方法 3:List 队列(Queue-based Stock Control)
- 预先将库存数量的 token(令牌)放入 Redis List
- 用户秒杀时
LPOP一个 token - 如果返回值为空,表示库存已售完
优点 :天然防止超卖
缺点:库存量大时 List 占用内存多
4. 防止超卖的关键点
- 原子操作(Atomic Operation):Lua 脚本或队列方式
- 库存预扣(Pre-deduction):先扣库存再异步下单
- 幂等性(Idempotency):同一用户只能成功一次
- 分布式锁(Distributed Lock):防止并发修改同一订单
5. 防止超买 & 超卖的安全策略
| 问题 | 解决方案 |
|---|---|
| 超卖(Overselling) | Lua 脚本原子扣减库存 / List 队列 |
| 超买(Overbuying) | 用户资格校验(Set 存储已购买用户 ID) |
| 重复下单 | 使用 SETNX(Set if Not Exists)记录用户秒杀状态 |
| 恶意请求 | 限流(Rate Limiting)+ 验证码(CAPTCHA) |
| 数据一致性 | 异步下单 + 消息队列(Message Queue) |
6. 秒杀系统 Redis 关键数据结构
| 功能 | Redis 数据结构 | 说明 |
|---|---|---|
| 库存管理 | String | 存储库存数量,配合 Lua 脚本扣减 |
| 用户资格 | Set | 存储已秒杀成功的用户 ID |
| 请求队列 | List / Stream | 存储待处理的秒杀请求 |
| 分布式锁 | String + Lua Script | 保证订单处理的原子性 |
7. 案例:Redis + Lua 秒杀库存扣减
初始化库存:
bash
SET stock:product_1001 100Lua 脚本扣减库存:
Lua
local stock = redis.call("GET", KEYS[1])
if not stock then
return -1
end
if tonumber(stock) > 0 then
redis.call("DECR", KEYS[1])
return 1
else
return 0
end执行:
bash
EVAL "lua_script_here" 1 stock:product_10018. 面试回答示例(带英文全称)
Redis 在秒杀系统中主要用于库存控制(Stock Control)和高并发请求处理(High Concurrency Request Handling) 。
常用方法包括:
- 使用 Lua Script(Lua 脚本)保证库存扣减的原子性(Atomicity)
- 使用 List(列表)作为库存队列,天然防止超卖(Overselling)
- 使用 Set(集合)记录已秒杀成功的用户,防止重复购买(Duplicate Purchase)
- 配合分布式锁(Distributed Lock)和消息队列(Message Queue, MQ)实现异步下单,保证数据一致性(Data Consistency)
这种架构能在高并发场景下保证秒杀的公平性(Fairness)、一致性(Consistency)和高性能(High Performance)。
9. 加分点
- 可以用 Redis Cluster(集群) 扩展秒杀系统的并发能力
- 秒杀入口要做 限流(Rate Limiting),防止 Redis 被瞬时流量压垮
- 可以配合 延时队列(Delayed Queue) 处理未支付订单的库存回滚
10. Redis 如何实现排行榜功能?
1. 排行榜需求场景
排行榜是很多系统的常见功能,例如:
- 游戏积分榜(Game Score Leaderboard)
- 电商销量榜(Sales Ranking)
- 活动排名(Event Ranking)
特点:
- 按分数排序(Score Sorting)
- 支持实时更新(Real-time Update)
- 支持分页查询(Pagination Query)
- 支持获取某个用户的排名(Get User Rank)
2. Redis 排行榜的核心数据结构
Redis 使用 Sorted Set(有序集合) 来实现排行榜:
- Member:排行榜对象(例如用户 ID)
- Score:排序依据(例如积分、销量)
- Redis 会自动按
score从小到大排序(可以反向查询实现从大到小)
3. 核心命令(带英文全称)
| 功能 | 命令 | 全称(英文补全) | 说明 |
|---|---|---|---|
| 添加/更新分数 | ZADD |
Add Member to Sorted Set | 添加成员并设置分数(如果存在则更新分数) |
| 获取排名(升序) | ZRANK |
Get Rank of Member | 返回成员的排名(从 0 开始) |
| 获取排名(降序) | ZREVRANK |
Get Reverse Rank of Member | 返回成员的排名(从高分到低分) |
| 获取分数 | ZSCORE |
Get Score of Member | 返回成员的分数 |
| 获取前 N 名(升序) | ZRANGE |
Get Members by Rank Range | 按排名范围返回成员 |
| 获取前 N 名(降序) | ZREVRANGE |
Get Members by Reverse Rank Range | 按排名范围返回成员(高分优先) |
| 增加分数 | ZINCRBY |
Increment Score of Member | 给成员的分数增加指定值 |
| 删除成员 | ZREM |
Remove Member from Sorted Set | 删除排行榜中的成员 |
4. 基本实现流程
添加/更新分数
bash
ZADD game_leaderboard 1500 user:1001
ZADD game_leaderboard 2000 user:1002获取前 3 名(降序)
bash
ZREVRANGE game_leaderboard 0 2 WITHSCORES返回:
1) "user:1002" 2000 2) "user:1001" 1500
获取某个用户的排名
bash
ZREVRANK game_leaderboard user:1001返回:
1
表示第 2 名(因为排名从 0 开始)
5. 进阶玩法
① 分页查询排行榜
bash
ZREVRANGE game_leaderboard 0 9 WITHSCORES # 第 1 页
ZREVRANGE game_leaderboard 10 19 WITHSCORES # 第 2 页② 获取某个用户的分数
bash
ZSCORE game_leaderboard user:1001③ 增加用户分数
bash
ZINCRBY game_leaderboard 50 user:1001④ 删除用户
bash
ZREM game_leaderboard user:10016. 排行榜的优化策略
| 问题 | 解决方案 |
|---|---|
| 数据量大 | 使用 Redis Cluster(集群)分片存储 |
| 排名实时更新压力大 | 批量更新(Batch Update)或异步更新(Asynchronous Update) |
| 需要多维度排行榜 | 为每个维度建立一个 Sorted Set |
| 需要历史榜单 | 定期将当前榜单备份到新的 key(例如按日期命名) |
7. 案例:游戏积分排行榜
初始化数据:
bash
ZADD game_leaderboard 1500 user:1001
ZADD game_leaderboard 2000 user:1002
ZADD game_leaderboard 1800 user:1003获取前 2 名:
bash
ZREVRANGE game_leaderboard 0 1 WITHSCORES增加分数:
bash
ZINCRBY game_leaderboard 100 user:1003获取某个用户排名:
bash
ZREVRANK game_leaderboard user:10038. 面试回答示例(带英文全称)
Redis 排行榜功能通常使用 Sorted Set(有序集合) 实现,成员(Member)是排行榜对象,分数(Score)是排序依据。
通过
ZADD(Add Member to Sorted Set)添加或更新分数,ZREVRANGE(Get Members by Reverse Rank Range)获取前 N 名,ZREVRANK(Get Reverse Rank of Member)获取某个成员的排名,ZINCRBY(Increment Score of Member)增加分数。这种方式支持实时更新(Real-time Update)、分页查询(Pagination Query)和多维度排行榜(Multi-dimensional Leaderboard),在游戏积分榜、销量榜等场景中非常高效。
9. 加分点
- Sorted Set 的时间复杂度:
ZADD、ZREM、ZINCRBY是 �(log�)O(logN),ZRANGE是 �(log�+�)O(logN+M) - 可以用 Redis Pipeline(管道) 批量更新分数,减少网络开销
- 如果需要历史榜单,可以每天备份一个 Sorted Set
11. Redis 如何防止缓存穿透、缓存击穿、缓存雪崩?
1. 三个问题的区别
| 问题 | 定义 | 影响 |
|---|---|---|
| 缓存穿透(Cache Penetration) | 请求的数据在缓存(Cache)和数据库(Database)中都不存在,导致每次请求都直接访问数据库 | 数据库压力大,可能被恶意攻击 |
| 缓存击穿(Cache Breakdown) | 某个热点数据(Hot Data)在缓存中过期的瞬间,有大量并发请求直接访问数据库 | 瞬时数据库压力暴增 |
| 缓存雪崩(Cache Avalanche) | 大量缓存数据在同一时间集中失效,导致大量请求直接访问数据库 | 数据库和应用可能直接崩溃 |
2. 缓存穿透(Cache Penetration)
原因
- 请求的 key 在缓存和数据库中都不存在
- 恶意攻击:大量请求不存在的 key
解决方案
-
缓存空值(Cache Null Value)
- 当数据库返回空结果时,也在缓存中存一个空值,并设置较短的过期时间(TTL, Time To Live)
bashSET user:1001 "" EX 60- 下次请求直接返回空值,避免访问数据库
-
布隆过滤器(Bloom Filter)
-
在缓存前加一个布隆过滤器(Bloom Filter),存储所有可能存在的 key
-
如果布隆过滤器判断 key 不存在,直接拦截请求
-
常用命令(Redis Module: RedisBloom):
bashBF.ADD user_filter 1001 BF.EXISTS user_filter 1001
-
3. 缓存击穿(Cache Breakdown)
原因
- 热点数据(Hot Data)过期的瞬间,大量并发请求直接访问数据库
解决方案
-
互斥锁(Mutex Lock)
- 第一个请求发现缓存失效时,加锁(Distributed Lock)去加载数据
- 其他请求等待锁释放后再访问缓存
- Lua 脚本保证加锁和释放锁的原子性(Atomicity)
-
逻辑过期(Logical Expiration)
- 在缓存中存一个逻辑过期时间字段
- 即使逻辑过期,仍返回旧数据,同时异步更新缓存
XML{ "data": {...}, "expireTime": 1735660800 } -
热点数据永不过期(Never Expire Hot Data)
- 对热点数据设置超长 TTL 或不设置过期时间
- 通过异步任务定期更新数据
4. 缓存雪崩(Cache Avalanche)
原因
- 大量缓存数据在同一时间集中失效
- 可能是批量设置了相同的 TTL
解决方案
-
随机过期时间(Random TTL)
- 设置缓存时,在 TTL 基础上加一个随机值,避免同时失效
bashSET product:1001 "data" EX 3600+rand(0,600) -
多级缓存(Multi-level Cache)
- 本地缓存(Local Cache,例如 Caffeine)+ Redis 缓存
- Redis 挂掉时,本地缓存仍可提供部分数据
-
缓存预热(Cache Pre-warming)
- 系统启动或大促前提前加载热点数据到缓存
-
降级策略(Degrade Strategy)
- 当缓存不可用时,限制部分功能或返回默认数据
5. 三者对比总结
| 问题 | 触发条件 | 解决方案 |
|---|---|---|
| 缓存穿透(Cache Penetration) | 请求数据不存在 | 缓存空值 / 布隆过滤器 |
| 缓存击穿(Cache Breakdown) | 热点数据过期瞬间 | 互斥锁 / 逻辑过期 / 永不过期 |
| 缓存雪崩(Cache Avalanche) | 大量缓存同时失效 | 随机 TTL / 多级缓存 / 缓存预热 |
6. 面试回答示例(带英文全称)
Redis 在高并发场景下可能遇到三类缓存问题:
缓存穿透(Cache Penetration) :请求的数据在缓存和数据库中都不存在,解决方案包括缓存空值(Cache Null Value)和布隆过滤器(Bloom Filter)。
缓存击穿(Cache Breakdown) :热点数据过期瞬间大量并发请求直接访问数据库,解决方案包括互斥锁(Mutex Lock)、逻辑过期(Logical Expiration)和热点数据永不过期(Never Expire Hot Data)。
缓存雪崩(Cache Avalanche) :大量缓存同时失效导致数据库压力暴增,解决方案包括随机过期时间(Random TTL)、多级缓存(Multi-level Cache)和缓存预热(Cache Pre-warming)。这些策略结合使用,可以有效保证系统的高可用性(High Availability)和稳定性(Stability)。
7. 加分点
- 布隆过滤器的空间复杂度低,但有一定误判率(False Positive Rate)
- 逻辑过期适合对一致性要求不高的场景
- 多级缓存可以减少 Redis 故障带来的影响
12. Redis 主从复制的原理?
1. 主从复制的作用
Redis 主从复制是指**一个 Redis 节点(Master)将数据同步到一个或多个从节点(Slave)**的机制。
主要作用:
- 读写分离(Read-Write Separation):Master 负责写,从节点负责读,提升性能
- 数据冗余(Data Redundancy):防止单点故障(Single Point of Failure)
- 高可用(High Availability):配合哨兵(Sentinel)或集群(Cluster)实现自动故障转移
2. 主从复制的核心原理
2.1 复制类型
- 全量复制(Full Synchronization)
从节点第一次连接 Master 或复制中断后重新连接时,Master 会将所有数据发送给 Slave - 增量复制(Partial Synchronization)
从节点与 Master 保持连接时,只同步新增或修改的数据
2.2 复制流程
-
建立连接(Connection Establishment)
-
从节点执行:
bash复制代码
SLAVEOF master_ip master_port -
建立 TCP 连接(Transmission Control Protocol)
-
-
全量复制(Full Sync)
- Master 执行
BGSAVE(Background Save)生成 RDB 文件(Redis Database File) - 将 RDB 文件发送给 Slave
- Slave 清空旧数据,加载新的 RDB 数据
- Master 执行
-
增量复制(Incremental Sync)
- Master 将后续写操作记录到 复制缓冲区(Replication Buffer)
- 通过 命令传播(Command Propagation) 将写命令发送给 Slave
- Slave 执行这些命令,保持数据一致
3. 关键机制
3.1 PSYNC 命令(Partial Resynchronization)
- Redis 2.8 引入的命令,用于增量复制
- 参数:
- runid:Master 的运行 ID(Run Identifier)
- offset:复制偏移量(Replication Offset)
- 如果 Slave 的 runid 和 offset 与 Master 匹配,则执行增量复制,否则执行全量复制
3.2 复制偏移量(Replication Offset)
- Master 和 Slave 都维护一个偏移量,表示已复制的数据字节数
- 用于判断是否可以增量复制
3.3 复制积压缓冲区(Replication Backlog Buffer)
- 一个固定大小的环形缓冲区(Circular Buffer)
- 存储最近的写命令,用于增量复制
- 如果 Slave 断开时间过长,缓冲区数据被覆盖,就只能全量复制
4. 常见问题与优化
| 问题 | 原因 | 解决方案 |
|---|---|---|
| 全量复制耗时长 | 数据量大 | 增加带宽 / 使用增量复制 |
| 复制中断频繁 | 网络不稳定 | 调整 repl-timeout 参数 |
| Slave 延迟高 | Master 写入频繁 | 增加复制缓冲区大小 / 优化写入 |
| 数据不一致 | Slave 未及时同步 | 使用 WAIT 命令确保写入同步到指定数量的 Slave |
5. 面试回答示例(带英文全称)
Redis 主从复制(Master-Slave Replication)是通过 Master 节点将数据同步到一个或多个 Slave 节点来实现的。
复制分为全量复制(Full Synchronization)和增量复制(Partial Synchronization)。
全量复制时,Master 执行
BGSAVE生成 RDB(Redis Database File)文件并发送给 Slave,Slave 清空旧数据并加载新数据;增量复制时,Master 通过复制积压缓冲区(Replication Backlog Buffer)将写命令传播(Command Propagation)给 Slave。Redis 2.8 引入了
PSYNC(Partial Resynchronization)命令,通过 runid(Run Identifier)和 offset(Replication Offset)判断是否可以增量复制。主从复制的主要作用是读写分离(Read-Write Separation)、数据冗余(Data Redundancy)和高可用(High Availability)。
6. 加分点
- Redis 主从复制是异步复制(Asynchronous Replication),可能存在短暂数据延迟
- 可以使用
WAIT命令实现半同步复制(Semi-synchronous Replication) - 在高可用架构中,通常配合 Redis Sentinel(哨兵) 自动故障转移
13. Redis 哨兵模式的原理?
一、Redis 哨兵模式原理
哨兵模式(Sentinel) 是 Redis 官方提供的 高可用(HA)解决方案 ,主要用于 监控主从架构中的主节点状态 ,并在主节点故障时自动完成 故障转移(Failover)。
核心功能
-
监控(Monitoring)
哨兵会不断检查主节点和从节点是否正常工作。
-
通知(Notification)
当节点出现故障时,哨兵会通知其他应用或管理员。
-
自动故障转移(Automatic Failover)
如果主节点不可用,哨兵会将某个从节点提升为新的主节点,并让其他从节点开始复制新的主节点。
-
配置提供者(Configuration Provider)
客户端可以通过哨兵获取当前主节点的地址,实现自动连接。
二、工作原理流程
- 部署多个哨兵节点(建议至少 3 个,保证选举的多数派机制)。
- 哨兵通过 心跳检测(PING)监控 Redis 主从节点。
- 当某个哨兵发现主节点不可达,会标记为 主观下线(Subjectively Down)。
- 多个哨兵通过 投票机制 达成一致,标记为 客观下线(Objectively Down)。
- 选举出一个哨兵作为 Leader ,执行故障转移:
- 从剩余的从节点中选出一个最新数据的节点作为新主节点。
- 让其他从节点开始复制新主节点。
- 客户端通过哨兵 API 获取新的主节点地址,继续工作。
三、应用场景
- 高可用保障:避免单点故障导致服务不可用。
- 自动化运维:减少人工干预,提升系统稳定性。
- 动态主节点发现:客户端无需硬编码主节点地址。
四、Java 案例(使用 Jedis 连接哨兵模式)
java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisSentinelPool;
import java.util.HashSet;
import java.util.Set;
public class RedisSentinelDemo {
public static void main(String[] args) {
// 哨兵节点集合
Set<String> sentinels = new HashSet<>();
sentinels.add("192.168.1.101:26379");
sentinels.add("192.168.1.102:26379");
sentinels.add("192.168.1.103:26379");
// masterName 必须与 sentinel 配置文件中的一致
String masterName = "mymaster";
// 创建 JedisSentinelPool
JedisSentinelPool pool = new JedisSentinelPool(masterName, sentinels);
try (Jedis jedis = pool.getResource()) {
jedis.set("key1", "Hello Sentinel");
String value = jedis.get("key1");
System.out.println("从主节点读取到的值: " + value);
}
pool.close();
}
}说明:
JedisSentinelPool会自动通过哨兵获取当前主节点地址。- 当主节点发生故障转移时,客户端无需修改代码,连接会自动切换到新的主节点。
五、部署建议
哨兵节点数量 :至少 3 个,保证选举的多数派机制。
主从节点数量 :至少 1 主 2 从,提升数据安全性。
网络延迟:哨兵与 Redis 节点之间的网络必须稳定,否则容易误判。
✅ 总结:
Redis 哨兵模式是一个 轻量级、高可用 的解决方案,适合中小型系统的主从架构自动化管理。如果你的业务需要更强的水平扩展能力,可以考虑 Redis Cluster。
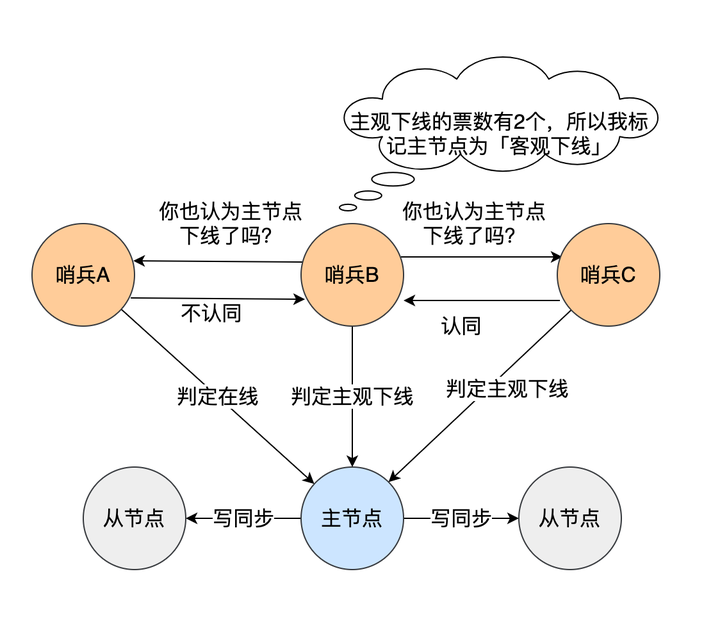
1. Redis 主节点不可用时,从节点提升为新主节点的实现过程
当 Redis 主节点(Master)发生故障时,哨兵集群会按照以下步骤完成故障转移:
步骤 1:主观下线(SDown)
- 每个哨兵节点会定期向主节点发送 PING 心跳包。
- 如果在配置的
down-after-milliseconds时间内没有收到合法回复,该哨兵会认为主节点 主观不可用(SDown)。 - 这是单个哨兵的判断,还不能触发故障转移。
步骤 2:客观下线(ODown)
- 多个哨兵节点之间会进行通信(通过
pub/sub频道)。 - 如果超过一半的哨兵节点都认为主节点不可用,则达成共识,标记为 客观不可用(ODown)。
- 达成 ODown 后,进入 Leader 选举阶段。
步骤 3:选举 Leader 哨兵
- 所有哨兵节点会使用 Raft 算法 (早期版本是类似于 Bully 算法)进行投票选举一个 Leader 哨兵。
- 只有 Leader 哨兵有权执行故障转移操作,避免多个哨兵同时切换导致混乱。
步骤 4:选择新的主节点
Leader 哨兵会根据以下规则选择一个从节点(Slave)提升为新的主节点:
- 优先级(priority) :Redis 从节点有
slave-priority配置,数值越小优先级越高。 - 复制偏移量(replication offset):数据同步进度越接近主节点的从节点优先。
- 运行 ID(RunID):作为最后的比较条件。
步骤 5:执行故障转移
- Leader 哨兵向被选中的从节点发送
SLAVEOF NO ONE命令,使其成为新的主节点。 - 通知其他从节点执行
SLAVEOF <new_master_ip> <port>,开始复制新的主节点。 - 更新哨兵集群的配置,让客户端通过哨兵查询到新的主节点地址。
2. 哨兵是否是集群?Leader 如何选举?
哨兵是分布式系统
- 哨兵本身也是一个 分布式集群 ,多个哨兵节点之间通过 Gossip 协议 交换监控信息。
- 建议部署 奇数个哨兵节点(如 3、5 个),保证投票时能形成多数派。
Leader 选举过程
- 当主节点 ODown 时,所有哨兵进入选举阶段。
- 每个哨兵会随机生成一个投票轮次(epoch),并向其他哨兵发送 Leader 申请。
- 哨兵之间通过 Raft 算法投票:
- 如果某个哨兵获得多数票(超过半数),它成为 Leader。
- 如果投票失败(票数不足),会重新发起选举。
- Leader 哨兵负责执行故障转移,其他哨兵只负责监控和同步信息。
3. 流程图(文字版)
bash
[哨兵监控主节点] → [SDown: 单哨兵判断不可用] → [ODown: 多哨兵达成共识]
→ [选举 Leader 哨兵] → [Leader 选择最佳从节点] → [提升为新主节点]
→ [其他从节点开始复制新主节点] → [客户端通过哨兵获取新主节点地址]✅ 总结关键点:
- SDown 是单哨兵的主观判断,ODown 是多数哨兵的客观判断。
- 哨兵集群使用 Raft 投票 选出 Leader,只有 Leader 执行故障转移。
- 新主节点选择基于 优先级、数据同步进度、RunID。
- 故障转移完成后,客户端无需改代码,哨兵会返回新的主节点地址。
14. Redis Cluster 集群的原理?
一、Redis Cluster 概述
Redis Cluster 是 Redis 官方提供的 分布式部署方案,主要解决:
- 数据分片(Sharding):将数据分布到多个节点,突破单机内存限制。
- 高可用(HA):支持主从复制和自动故障转移。
- 去中心化:没有单点故障的中心节点,所有节点平等。
二、架构组成
一个 Redis Cluster 至少需要 6 个节点(3 个主节点 + 3 个从节点):
- 主节点(Master):负责存储数据和处理读写请求。
- 从节点(Slave):复制主节点数据,主节点故障时可提升为新主节点。
三、数据分片原理
1. 槽(Slot)机制
- Redis Cluster 将整个键空间分为 16384 个槽(Slot)。
- 每个主节点负责一部分槽,例如:
- Master1:槽 0 ~ 5460
- Master2:槽 5461 ~ 10922
- Master3:槽 10923 ~ 16383
2. 哈希计算
-
Redis Cluster 使用 CRC16 算法 对键进行哈希计算:
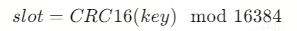
-
根据计算出的槽号,定位到对应的主节点。
3. 数据路由
- 客户端可以直接连接任意节点,节点会返回 MOVED 或 ASK 重定向信息,让客户端去正确的节点访问数据。
- 为了减少重定向,客户端通常会使用 Cluster-aware 客户端(如 JedisCluster、Lettuce)。
四、节点通信原理
1. Gossip 协议
- Redis Cluster 节点之间通过 Gossip 协议交换状态信息(类似哨兵)。
- 每个节点定期向其他节点发送 PING ,并接收 PONG 回复。
- Gossip 消息包含:
- 节点 ID
- 节点角色(主/从)
- 槽分配信息
- 节点状态(在线/下线)
2. 集群元数据
- 每个节点都保存整个集群的槽分配表和节点信息。
- 当槽迁移或节点变化时,所有节点会同步更新元数据。
五、故障转移原理
1. 主观下线(PFail)
- 某个节点在一定时间内没有响应,会被标记为 主观下线。
2. 客观下线(Fail)
- 多个节点通过 Gossip 协议确认某节点不可用,标记为 客观下线。
3. 自动故障转移
- 如果下线的是主节点:
- 其从节点会发起 Leader 选举。
- 获得多数票的从节点执行
SLAVEOF NO ONE,成为新主节点。 - 更新槽分配表,通知集群其他节点。
六、优缺点
优点:
- 水平扩展能力强,支持海量数据。
- 高可用,自动故障转移。
- 去中心化,节点平等。
缺点:
- 不支持多键跨槽事务(除非使用
hash tag)。 - 部署和运维复杂度高。
- 节点间网络延迟可能影响性能。
七、工作流程(文字版)
[客户端发送命令] ↓ [节点计算槽号: CRC16(key) % 16384] ↓ [定位主节点] ↓ [主节点执行读写] ↓ [节点间Gossip同步状态] ↓ [主节点故障 → PFail → Fail] ↓ [从节点选举Leader → 提升为新主节点] ↓ [槽分配表更新 → 客户端重定向]
✅ 总结关键点:
- 16384 槽是 Redis Cluster 数据分片的核心。
- CRC16 哈希保证键分布均匀。
- Gossip 协议让节点共享状态信息。
- 主从复制 + 自动故障转移保证高可用。
15. Redis 单线程为什么还能这么快?CPU 瓶颈怎么解决?
一、Redis 单线程为什么还能这么快?
很多人一听"单线程"就觉得性能差,其实 Redis 的单线程指的是 网络请求处理线程 是单线程的,并不是整个 Redis 进程只有一个线程。
Redis 之所以快,主要有 4 大原因:
1. 纯内存操作
- Redis 所有数据都存储在内存中,读写速度接近 纳秒级。
- 内存访问速度比磁盘快几个数量级(内存访问约 100ns,SSD 约 100μs,机械硬盘约 10ms)。
2. 高效的数据结构
- Redis 内部大量使用 优化过的 C 语言数据结构 :
- SDS(简单动态字符串):比 C 字符串更安全高效。
- 压缩列表(ziplist):节省内存,提高缓存命中率。
- 跳表(skiplist):有序集合的底层实现,查询效率高。
- 哈希表(dict):O(1) 查找和插入。
- 这些数据结构都是为高性能而设计的,减少 CPU 指令数。
3. 单线程避免了多线程的锁竞争
- 多线程需要加锁来保证数据一致性,会带来 上下文切换 和 锁竞争 的开销。
- Redis 单线程处理请求,天然避免了锁竞争问题,没有加锁开销,执行路径短。
4. I/O 多路复用(epoll/kqueue)
- Redis 使用 I/O 多路复用机制(Linux 下是 epoll,BSD 下是 kqueue)。
- 可以同时监听多个 socket 连接,非阻塞地处理请求。
- 事件循环(event loop)模型:
- 监听多个客户端连接。
- 有事件就回调对应的处理函数。
- 一次循环处理尽可能多的请求。
💡 一句话总结 :
Redis 快的核心是 内存存储 + 高效数据结构 + 无锁单线程 + I/O 多路复用,而不是靠多线程堆性能。
二、Redis 单线程的 CPU 瓶颈
虽然 Redis 单线程很快,但它的性能瓶颈确实可能出现在 CPU 上,尤其是以下场景:
-
大 key 操作
- 例如
lrange mylist 0 1000000,一次性返回大量数据,会占用 CPU 做序列化和网络传输。
- 例如
-
复杂命令
SORT、SUNION、ZINTERSTORE等需要大量计算的命令,会阻塞事件循环。
-
持久化开销
- RDB/AOF 持久化时,数据序列化和写磁盘会占用 CPU。
-
网络传输瓶颈
- 单线程处理网络 I/O,如果数据包很大,CPU 会花很多时间在序列化/反序列化上。
三、CPU 瓶颈的解决方案
1. 多实例部署
- 在同一台机器上启动多个 Redis 实例,每个实例绑定不同 CPU 核心。
- 例如 8 核 CPU,可以跑 4~6 个 Redis 实例,分摊压力。
- 配合 客户端分片 或 代理层(Twemproxy、Codis) 实现数据分布。
2. 使用 Redis Cluster
- 将数据分片到多个节点,每个节点单线程处理自己的槽(slot)。
- 这样可以利用多台机器的 CPU 核心,水平扩展性能。
3. 避免大 key 和 O(N) 命令
- 拆分大 key,例如一个 list 过大时拆成多个 list。
- 避免一次性返回大量数据,使用分页(SCAN、SSCAN、ZSCAN)。
- 对于计算量大的操作,考虑在业务层处理,而不是 Redis 里直接计算。
4. 异步化耗时操作
- Redis 4.0 引入了 异步删除 (
UNLINK、FLUSHDB ASYNC),避免删除大 key 阻塞主线程。 - Redis 6.0 引入了 多线程 I/O,虽然命令执行仍是单线程,但网络读写可以多线程并行,减少 I/O 阻塞。
5. 持久化优化
- RDB 持久化可以放到从节点执行,减少主节点 CPU 压力。
- AOF 可以使用
appendfsync everysec模式,减少 fsync 调用频率。
四、面试回答模板(简洁版)
面试官问:Redis 是单线程的,为什么还这么快?CPU 瓶颈怎么解决?
你可以这样答:
Redis 快主要有四个原因:
- 纯内存操作,速度接近纳秒级。
- 高效数据结构,如 SDS、跳表、哈希表等。
- 单线程无锁,避免了多线程的锁竞争和上下文切换。
- I/O 多路复用,一次循环处理多个连接。
CPU 瓶颈主要出现在大 key、复杂命令、持久化和网络传输上。
解决方案包括:
- 多实例部署,绑定不同 CPU 核心。
- 使用 Redis Cluster 分布数据。
- 避免大 key 和 O(N) 命令,分页处理。
- 使用异步删除和 Redis 6.0 多线程 I/O。
- 持久化放到从节点,降低主节点压力。
✅ 总结 :
Redis 单线程快的本质是 减少 CPU 上下文切换 + 内存高效访问 + 数据结构优化 + I/O 多路复用 。
CPU 瓶颈可以通过 多实例、多节点、命令优化、异步化 来解决。
直观展示 Redis 单线程指的是网络请求处理线程单线程
流程图描述:
-
Redis 进程启动
- 包含多个功能线程(如持久化线程、异步删除线程、I/O 线程等)。
-
网络请求处理线程(单线程)
- 负责接收客户端请求、解析命令、执行命令、返回结果。
- 使用 I/O 多路复用(epoll/kqueue)监听多个连接。
- 在事件循环中一次处理一个命令,避免锁竞争。
-
其他辅助线程(多线程)
- 持久化线程:执行 RDB/AOF 保存到磁盘。
- 异步删除线程 :执行
UNLINK、FLUSHDB ASYNC等耗时删除。 - I/O 线程(Redis 6.0+):负责网络数据的读写,减少主线程阻塞。
-
数据流
- 客户端请求 → 网络请求处理线程(单线程) → 执行命令 → 返回结果
- 持久化、异步删除等耗时任务由其他线程并行处理,不阻塞主线程。
Redis I/O 多路复用工作原理 的流程图
流程图内容描述
-
客户端连接阶段
- 多个客户端(C1、C2、C3...)通过 TCP 连接到 Redis 服务器。
-
事件监听阶段
- Redis 主线程使用 epoll/kqueue/select 等 I/O 多路复用机制,同时监听多个 socket。
- 这些 socket 可能有不同的事件:
- 可读事件(客户端发来命令)
- 可写事件(可以向客户端返回数据)
-
事件循环阶段
- 主线程进入 事件循环(event loop) :
- 调用
epoll_wait()等系统调用,等待事件发生。 - 一旦有事件发生,返回事件列表。
- 按顺序处理每个事件(读取命令 → 执行命令 → 写回结果)。
- 调用
- 主线程进入 事件循环(event loop) :
-
命令执行阶段
- 命令执行是单线程的,避免了锁竞争。
- 如果是耗时操作(如持久化、异步删除),会交给后台线程处理。
-
返回结果阶段
- 主线程将结果写入 socket 缓冲区,等待下一次可写事件触发时发送给客户端。
我帮你画的图会这样呈现:
[多个客户端连接] ↓ [epoll/kqueue 监听所有 socket] ↓ [事件循环 event loop] ↓ [有事件发生 → 读取命令] ↓ [单线程执行命令] ↓ [写回结果给客户端]
要我现在帮你画出这个 I/O 多路复用原理图 吗?这样你面试时直接用图解释,面试官会觉得你既懂原理又能表达清楚。
16. Redis 内存占用如何优化?
一、为什么 Redis 内存占用会高?
Redis 是 内存数据库,所有数据都存储在内存中,内存占用高的原因主要有:
-
数据本身占用
- 存储的 key 和 value 本身的大小。
-
数据结构额外开销
- Redis 的数据结构(SDS、哈希表、跳表等)会有额外的元数据开销。
-
内存碎片
- 内存分配器(jemalloc)会导致实际占用比数据本身大。
-
持久化缓冲区
- AOF 重写、RDB 生成时会有额外内存占用。
-
复制缓冲区
- 主从复制时,主节点会为从节点保留复制积压缓冲区(默认 1MB)。
-
过期键未及时清理
- Redis 采用惰性删除 + 定期删除,过期数据可能暂时占用内存。
二、Redis 内存优化方法
我按 数据层面、结构层面、配置层面 三个维度来讲。
1. 数据层面优化
-
减少 key 的长度
- Key 太长会浪费内存,例如
user:1001:name可以改成u:1001:n。
- Key 太长会浪费内存,例如
-
减少 value 的冗余
- 存储 JSON 时可以压缩(如 MessagePack、Protobuf)。
-
删除无用数据
- 定期清理不再使用的 key,避免"僵尸数据"占用内存。
2. 数据结构层面优化
-
使用合适的数据结构
-
小数据量的 hash/list/set/zset 可以用 压缩编码(ziplist/hashtable/intset)。
-
例如:
bashhash-max-ziplist-entries 512 hash-max-ziplist-value 64 list-max-ziplist-size -2 set-max-intset-entries 512 zset-max-ziplist-entries 128 zset-max-ziplist-value 64这些配置可以让小集合用紧凑结构存储,减少内存开销。
-
-
合并小 key
-
把多个相关字段放到一个 hash 里,而不是多个独立 key。
-
例如:
bash# 不推荐 set user:1:name "Tom" set user:1:age 18 # 推荐 hmset user:1 name "Tom" age 18
-
3. 配置层面优化
-
开启内存淘汰策略
maxmemory+maxmemory-policy(如 allkeys-lru、volatile-lru)。
-
压缩 RDB 文件
rdbcompression yes(默认开启)。
-
AOF 重写优化
- 调整
auto-aof-rewrite-percentage和auto-aof-rewrite-min-size,减少重写频率。
- 调整
-
合理设置复制缓冲区
repl-backlog-size根据业务调整,避免过大。
4. 内存分配器优化
-
Redis 默认使用 jemalloc,它会导致内存碎片率上升。
-
监控:
bashinfo memory关注:
used_memory(实际数据占用)used_memory_rss(操作系统分配的内存)mem_fragmentation_ratio(碎片率,>1.5 需关注)
-
优化:
- 升级 jemalloc 版本(新版本碎片率更低)。
- 定期重启实例释放碎片(业务低峰期)。
5. 过期键清理优化
- Redis 过期键采用 惰性删除 + 定期删除 :
- 惰性删除:访问时发现过期才删除。
- 定期删除:定时随机抽样删除部分过期键。
- 如果过期键很多,可以:
- 调整
hz参数(提高定期任务频率)。 - 手动批量删除(低峰期执行)。
- 调整
三、面试答题模板(简洁版)
面试官问:Redis 内存占用高,怎么优化?
你可以这样答:
Redis 内存占用主要来自数据本身、数据结构开销、内存碎片、持久化缓冲区和复制缓冲区。
优化方法可以从三方面入手:
- 数据层面:缩短 key/value 长度,压缩存储格式,删除无用数据。
- 数据结构层面:使用压缩编码(ziplist/intset),合并小 key,减少元数据开销。
- 配置层面 :设置
maxmemory和淘汰策略,优化 RDB/AOF 配置,合理调整复制缓冲区大小。另外,要监控
mem_fragmentation_ratio,碎片率过高时可升级 jemalloc 或重启实例释放内存。
✅ 总结 :
Redis 内存优化的核心是 减少存储体积 + 降低结构开销 + 控制内存生命周期 。
面试时最好能结合 info memory 的实际输出 来分析,这样更有说服力。
17. Redis 大 key 问题怎么处理?
一、什么是 Redis 大 key?
大 key 指的是 单个 key 的 value 数据量非常大,可能是:
- 字符串类型:value 很长(几 MB 甚至几十 MB)。
- 集合类型:list、set、zset、hash 中元素数量非常多(几十万甚至百万级)。
- 嵌套结构:一个 hash 里存了大量字段,或者一个 list 里有海量元素。
二、为什么大 key 是个问题?
1. 阻塞主线程
Redis 的命令执行是单线程的,大 key 的读写、删除、迁移都会占用主线程很长时间,导致其他请求延迟甚至超时。
2. 网络传输压力
一次性返回大 key 会占用大量带宽,客户端和服务端的序列化/反序列化也会消耗 CPU。
3. 内存碎片
大 key 删除后,内存分配器可能无法立即回收,导致碎片率升高。
4. 集群迁移困难
在 Redis Cluster 中,大 key 所在的槽迁移会非常慢,因为迁移是按 key 粒度进行的。
5. 持久化文件膨胀
RDB/AOF 持久化时,大 key 会让文件体积暴增,加载和恢复时间变长。
三、如何排查大 key?
1. 使用 redis-cli
bash
# 查看某个 key 的大小(字符串类型)
strlen mykey
# 查看集合类型的元素数量
llen mylist
scard myset
zcard myzset
hlen myhash2. 使用 --bigkeys 扫描
bash
redis-cli --bigkeys- 会按类型扫描并输出最大 key 的大小。
- 缺点:会全量扫描,可能影响线上性能。
3. 使用 SCAN 命令
bash
SCAN 0 COUNT 1000- 分批扫描,避免阻塞。
- 配合
TYPE和长度命令(如LLEN)判断是否为大 key。
4. 使用监控工具
- Redis 官方
redis-benchmark不适合查大 key,但可以用 Redis Exporter + Prometheus + Grafana 监控 key 大小分布。
四、处理大 key 的方法
1. 拆分大 key
- 字符串类型:按业务逻辑拆成多个小 key,例如按日期分片。
- 集合类型 :将一个大集合拆成多个小集合,例如
set:user:1001:part1、set:user:1001:part2。
2. 分页读取
-
避免一次性取出全部数据,使用分页命令:
bash# 分批读取 list LRANGE mylist 0 99 LRANGE mylist 100 199 # 分批读取 set SSCAN myset 0 COUNT 100
3. 异步删除
-
Redis 4.0+ 支持异步删除:
bashUNLINK mybigkey -
异步删除不会阻塞主线程,适合删除大 key。
4. 业务层优化
- 不在 Redis 存储超大对象,改用文件存储(如 OSS、S3)+ Redis 存储索引。
- 对于排行榜、日志等数据,定期归档到冷存储。
5. 集群迁移优化
- 在迁移前先拆分大 key,减少迁移时间。
- 或者在低峰期迁移,避免影响业务。
五、面试答题模板(简洁版)
面试官问:Redis 大 key 问题怎么处理?
你可以这样答:
大 key 是指单个 key 的 value 数据量很大,可能导致主线程阻塞、网络传输慢、内存碎片、集群迁移困难和持久化文件膨胀。
排查方法包括:
redis-cli --bigkeys全量扫描。SCAN分批扫描。- 结合
LLEN、SCARD等命令查看集合大小。处理方法:
- 拆分大 key,按业务逻辑分片。
- 分页读取,避免一次性取出全部数据。
- 异步删除 (
UNLINK)减少阻塞。- 业务层优化,超大对象放到文件存储。
- 集群迁移前先拆分,减少迁移时间。
核心原则是:避免在 Redis 存储超大对象,控制单 key 的数据量。
✅ 总结 :
Redis 大 key 的本质问题是 单线程阻塞 + 内存管理压力 ,优化的关键是 拆分、分页、异步化、业务层替代 。
面试时如果能结合线上案例(比如一次删除大 key 导致 Redis 卡死),会更有说服力。
18. Redis 热 key 问题怎么处理?
一、什么是 Redis 热 key?
热 key 指的是某个 key 被频繁访问(读或写),访问量远高于其他 key,导致该 key 成为性能瓶颈。
常见场景:
- 秒杀活动中某个商品库存 key。
- 热门视频播放量 key。
- 热门排行榜 key。
- 高频缓存数据(如首页配置)。
二、为什么热 key 是个问题?
1. 单线程压力集中
Redis 单线程处理命令,如果大量请求集中到一个 key,会让该 key 的操作占用主线程时间,影响其他请求。
2. 网络带宽瓶颈
热 key 的返回数据量大时,会占用大量带宽,导致其他请求延迟。
3. 集群节点负载不均
在 Redis Cluster 中,热 key 所在的槽会被分配到某个节点,导致该节点压力过大,而其他节点空闲。
4. 缓存雪崩风险
如果热 key 过期或被删除,瞬间大量请求会直接打到数据库,造成雪崩。
三、如何排查热 key?
1. Redis 自带命令
bash
# 查看当前最频繁访问的 key
redis-cli monitor- 缺点:
MONITOR会输出所有命令,性能开销大,不适合线上长时间运行。
2. 使用 Redis 热 key采样
bash
redis-cli --hotkeys- 会随机采样 key 的访问频率,找出访问量高的 key。
3. 使用 SCAN + OBJECT
bash
SCAN 0 COUNT 1000
OBJECT freq mykeyOBJECT freq可以查看 key 的访问频率(Redis 4.0+)。
4. 监控工具
- 使用 Redis Exporter + Prometheus + Grafana 监控 key 访问量分布。
- 或者在业务层埋点统计 key 的访问次数。
四、处理热 key 的方法
1. 业务层分摊访问
-
多副本缓存 :将热 key 的数据复制到多个不同的 key,客户端随机访问其中一个。
bashset hotkey:1 value set hotkey:2 value set hotkey:3 value -
客户端负载均衡:在应用层做随机或轮询访问,分摊压力。
2. 使用本地缓存
- 在应用服务器上使用 本地缓存(如 Guava Cache、Caffeine、Ehcache) 或 内存变量 存储热 key 数据,减少 Redis 访问。
- 适合数据更新频率低的场景。
3. 多级缓存架构
- 本地缓存 + Redis 缓存 + 数据库 :
- 先查本地缓存。
- 本地缓存 miss 再查 Redis。
- Redis miss 再查数据库。
- 可以显著降低 Redis 热 key 的访问压力。
4. Redis Cluster 热 key迁移
- 如果是集群模式,可以将热 key 拆分成多个 key,分布到不同节点。
- 或者使用 代理层(Twemproxy、Codis) 做数据分片。
5. 热 key预热
- 在系统启动或活动开始前,将热 key 数据提前加载到缓存,避免瞬间高并发直接打数据库。
6. 限流与降级
- 对热 key 的访问做限流,防止瞬间流量过大。
- 当 Redis 压力过大时,返回降级数据(如旧数据或默认值)。
五、面试答题模板(简洁版)
面试官问:Redis 热 key 问题怎么处理?
你可以这样答:
热 key 是指某个 key 被频繁访问,导致单线程压力集中、网络瓶颈、集群节点负载不均和缓存雪崩风险。
排查方法包括:
redis-cli --hotkeys采样。MONITOR查看实时访问。OBJECT freq查看访问频率。- 监控工具统计访问量。
处理方法:
- 业务层分摊访问:多副本缓存,客户端负载均衡。
- 本地缓存:减少 Redis 访问。
- 多级缓存架构:本地缓存 + Redis + DB。
- 集群迁移:拆分热 key 分布到不同节点。
- 预热与限流:提前加载数据,防止雪崩。
核心原则是:分散访问压力,减少 Redis 单点瓶颈。
✅ 总结 :
Redis 热 key 的本质问题是 访问集中导致单线程或单节点过载 ,优化的关键是 分摊访问、增加缓存层、限流降级 。
面试时如果能结合线上案例(比如秒杀活动热 key 导致 Redis 节点 CPU 100%),会更有说服力。
限流 和 降级 的案例
一、限流(Rate Limiting)
1. 目的
防止瞬间高并发请求压垮系统(包括 Redis、数据库、服务接口)。
2. 常见实现方式
- 固定窗口限流(Fixed Window):按时间窗口统计请求数,超过限制直接拒绝。
- 滑动窗口限流(Sliding Window):更精细地统计时间段内的请求数。
- 令牌桶(Token Bucket):按速率生成令牌,请求需要令牌才能执行。
- 漏桶(Leaky Bucket):按固定速率处理请求,多余的请求排队或丢弃。
二、降级(Degrade/Fallback)
1. 目的
当系统压力过大或依赖服务不可用时,返回简化版数据 或默认值,保证核心功能可用。
2. 常见实现方式
- 静态数据降级:直接返回预设的静态数据。
- 缓存数据降级:返回上一次缓存的旧数据。
- 部分功能关闭:关闭非核心功能,保留核心功能。
- 快速失败:直接返回错误提示,避免长时间等待。
三、Java 限流 + 降级 案例
下面给你一个 基于 Redis + Java 的限流和降级示例,适合分布式环境(多台应用服务器共享限流状态)。
代码示例
java
import redis.clients.jedis.Jedis;
public class RedisRateLimiter {
private Jedis jedis;
private String key;
private int limit; // 每秒最大请求数
private int expire; // key过期时间(秒)
public RedisRateLimiter(String redisHost, String key, int limit, int expire) {
this.jedis = new Jedis(redisHost);
this.key = key;
this.limit = limit;
this.expire = expire;
}
public boolean tryAcquire() {
long count = jedis.incr(key);
if (count == 1) {
jedis.expire(key, expire);
}
return count <= limit;
}
public String getDataWithDegrade() {
if (!tryAcquire()) {
// 降级处理:返回默认数据
return "系统繁忙,请稍后再试(降级数据)";
}
// 正常业务逻辑
return "正常返回的数据";
}
public static void main(String[] args) {
RedisRateLimiter limiter = new RedisRateLimiter("127.0.0.1", "hotkey:limit", 5, 1);
for (int i = 0; i < 10; i++) {
String result = limiter.getDataWithDegrade();
System.out.println("请求 " + (i + 1) + " -> " + result);
}
}
}代码说明
-
限流逻辑:
- 使用
INCR统计当前秒的请求数。 - 第一次访问时设置过期时间(
expire)。 - 如果请求数超过
limit,直接拒绝。
- 使用
-
降级逻辑:
- 当限流拒绝时,返回降级数据(这里是一个简单提示)。
- 也可以返回缓存的旧数据或静态数据。
-
运行效果:
- 每秒最多允许 5 次请求。
- 超过限制的请求会返回降级提示。
四、面试答题模板
限流是为了防止瞬间高并发压垮系统,常用固定窗口、滑动窗口、令牌桶等算法。
降级是在系统压力过大或依赖不可用时,返回简化版数据或默认值,保证核心功能可用。
在分布式环境中,可以用 Redis 记录请求计数实现限流,并在超限时返回降级数据。
例如我用 Redis
INCR+EXPIRE做固定窗口限流,超限时返回缓存的旧数据或提示信息。
✅ 总结 :
限流和降级是 保护系统稳定性 的关键手段,限流控制流量,降级保证可用性。
在 Redis 热 key 场景下,这两者配合使用,可以有效防止雪崩。
19. Redis Pipeline 是什么?有什么作用?
一、Redis Pipeline 是什么?
Pipeline(管道) 是 Redis 提供的一种 批量发送命令 的机制。
它的核心思想是:一次性将多个命令打包发送到 Redis 服务器,减少网络往返次数(RTT)。
普通模式 vs Pipeline 模式
- 普通模式:每次发送一个命令 → 等待 Redis 执行 → 返回结果 → 再发送下一个命令。
- Pipeline 模式:一次性发送多个命令 → Redis 执行完毕 → 一次性返回所有结果。
二、Pipeline 的作用
1. 减少网络延迟
- Redis 是单线程的,命令执行速度很快,但网络传输存在延迟。
- 如果每个命令都要等待响应,延迟会被放大。
- Pipeline 可以一次性发送多个命令,减少 RTT(Round Trip Time)。
2. 提高吞吐量
- 批量发送命令可以让 Redis 更高效地处理请求,提升 QPS。
3. 批量操作数据
- 适合批量写入、批量读取等场景。
三、使用场景
-
批量写入数据
- 例如一次性插入 10 万条数据到 Redis。
-
批量读取数据
- 例如一次性获取多个 key 的值。
-
数据迁移
- 从一个 Redis 实例迁移数据到另一个实例时。
-
初始化缓存
- 系统启动时批量加载数据到 Redis。
四、Pipeline 使用示例
Java Jedis 示例
java
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
public class RedisPipelineDemo {
public static void main(String[] args) {
Jedis jedis = new Jedis("127.0.0.1", 6379);
Pipeline pipeline = jedis.pipelined();
// 批量写入
for (int i = 1; i <= 5; i++) {
pipeline.set("key" + i, "value" + i);
}
// 批量读取
for (int i = 1; i <= 5; i++) {
pipeline.get("key" + i);
}
// 执行所有命令
pipeline.sync();
jedis.close();
}
}五、注意事项
-
Pipeline 不保证原子性
- 它只是批量发送命令,不会像事务(MULTI/EXEC)那样保证原子性。
-
内存占用
- Pipeline 会在客户端和服务器端缓存所有命令和结果,如果批量数据太大,可能会占用大量内存。
-
错误处理
- 如果某个命令出错,Pipeline 不会中断执行,错误会在结果中体现。
-
适合批量场景
- 对于单条命令,Pipeline 没有优势,反而增加复杂度。
六、面试答题模板(简洁版)
面试官问:Redis Pipeline 是什么?有什么作用?
你可以这样答:
Redis Pipeline 是一种批量发送命令的机制,可以一次性将多个命令发送到 Redis,减少网络往返次数(RTT),提高吞吐量。
它的作用主要是:
- 减少网络延迟:一次性发送多个命令,降低延迟。
- 提高吞吐量:批量处理请求,提升 QPS。
- 适合批量场景:批量写入、批量读取、数据迁移、缓存预热等。
注意 Pipeline 不保证原子性,批量数据过大可能导致内存占用高。
✅ 总结 :
Pipeline 的本质是 减少网络交互次数 ,适合批量操作场景,但不适合需要原子性的业务逻辑。
面试时最好能结合 普通模式 vs Pipeline 模式的性能对比 来回答,这样更有说服力。
20. Redis 事务(MULTI/EXEC)和 Lua 脚本的区别?
一、Redis 事务(MULTI/EXEC)原理
1. 基本流程
Redis 事务通过 MULTI / EXEC / DISCARD / WATCH 命令实现:
- MULTI:开启事务,进入事务队列模式。
- 命令入队:事务中的命令不会立即执行,而是进入队列。
- EXEC:一次性按顺序执行队列中的命令。
- DISCARD:取消事务。
- WATCH:乐观锁机制,监控某些 key,如果在事务执行前这些 key 被修改,则事务取消。
2. 特性
- 非原子性:Redis 事务保证队列中的命令按顺序执行,但如果中途某条命令出错,其他命令仍会继续执行。
- 单线程执行:事务中的命令在 EXEC 时一次性执行,期间不会被其他命令插入。
- 乐观锁:通过 WATCH 实现类似 CAS(Compare And Swap)的机制。
二、Lua 脚本原理
1. 基本流程
Redis 内置了 Lua 解释器(基于 EVAL 命令),可以在服务器端执行 Lua 脚本:
- 客户端发送 Lua 脚本到 Redis。
- Redis 在单线程中执行整个脚本。
- 脚本中的所有 Redis 命令一次性执行,且原子性保证。
2. 特性
- 原子性:Lua 脚本在 Redis 中是一个整体执行的,不会被其他命令打断。
- 减少网络开销:多个命令在服务器端执行,不需要多次网络往返。
- 灵活性:可以在脚本中写逻辑(循环、条件判断等),比事务更灵活。
- 可缓存 :脚本可以用
SCRIPT LOAD预加载,减少传输开销。
三、事务 vs Lua 脚本 对比表
| 特性 | Redis 事务(MULTI/EXEC) | Lua 脚本(EVAL) |
|---|---|---|
| 原子性 | 不保证(命令逐条执行,错误不回滚) | 保证(脚本整体原子执行) |
| 执行位置 | 客户端命令入队,Redis 执行 | Redis 服务器端执行 |
| 网络开销 | 多次网络往返(MULTI、命令、EXEC) | 一次网络往返 |
| 逻辑能力 | 只能顺序执行命令,无条件判断 | 可写复杂逻辑(if、for、计算等) |
| 性能 | 批量执行但有网络延迟 | 更高效(一次性执行) |
| 适用场景 | 简单批量命令执行 | 复杂业务逻辑、需要原子性 |
四、使用场景
事务适用场景
- 批量执行多个命令,但不需要严格原子性。
- 需要乐观锁控制(WATCH)。
- 例如:批量更新库存、批量写入日志。
Lua 脚本适用场景
- 需要严格原子性。
- 需要在 Redis 端执行复杂逻辑。
- 例如:秒杀扣库存(判断库存 > 0 再扣减)、排行榜更新、分布式锁释放。
五、注意事项
-
事务不回滚
- 如果事务中某条命令出错,其他命令仍会执行。
-
Lua 脚本执行时间
- Redis 是单线程的,长时间执行的 Lua 脚本会阻塞其他请求。
-
脚本安全
- Lua 脚本中不要写死耗时操作,避免阻塞 Redis。
-
调试难度
- Lua 脚本调试比事务复杂,需要在本地测试好再上线。
六、面试答题模板(简洁版)
面试官问:Redis 事务和 Lua 脚本有什么区别?
你可以这样答:
Redis 事务(MULTI/EXEC)是将多个命令入队后一次性执行,保证命令顺序但不保证原子性,支持 WATCH 实现乐观锁。
Lua 脚本(EVAL)是在 Redis 服务器端一次性执行多个命令,保证原子性,并且可以写复杂逻辑,减少网络往返。
区别主要在:
- 原子性:事务不保证,Lua 保证。
- 执行位置:事务命令入队,Lua 在服务器端执行。
- 逻辑能力:事务只能顺序执行,Lua 可写条件判断和循环。
- 性能:Lua 更高效,适合复杂原子操作。
场景上,事务适合简单批量命令,Lua 适合需要原子性和复杂逻辑的场景,比如秒杀扣库存。
✅ 总结 :
事务是 批量执行命令的机制 ,Lua 脚本是 在 Redis 端执行逻辑的工具 。
如果需要原子性和复杂逻辑,选 Lua;如果只是简单批量执行且不需要原子性,选事务。
21. Redis 如何做限流?
一、为什么用 Redis 做限流?
- 高性能:Redis 单线程执行速度快,QPS 可达十万级。
- 分布式共享状态:多台应用服务器可以共享限流计数。
- 数据结构丰富:支持计数、时间窗口、队列等多种限流实现方式。
- 原子性:Redis 的单线程命令执行保证了限流操作的原子性。
二、常见限流算法
1. 固定窗口(Fixed Window)
- 按固定时间窗口统计请求数,超过限制直接拒绝。
- 简单易实现,但可能在窗口边界出现突发流量。
2. 滑动窗口(Sliding Window)
- 记录每次请求的时间戳,统计最近一段时间的请求数。
- 边界流量更平滑,但实现稍复杂。
3. 令牌桶(Token Bucket)
- 按固定速率生成令牌,请求需要令牌才能执行。
- 支持突发流量,但有最大容量限制。
4. 漏桶(Leaky Bucket)
- 按固定速率处理请求,多余的请求排队或丢弃。
- 流量更稳定,但不支持突发流量。
三、Redis 限流实现方式
1. 固定窗口限流(INCR + EXPIRE)
bash
# 每秒最多 5 次请求
INCR user:123:limit
EXPIRE user:123:limit 1- 第一次访问时设置过期时间。
- 超过限制直接拒绝。
2. 滑动窗口限流(ZSET)
bash
# 记录请求时间戳
ZADD user:123:requests <timestamp> <timestamp>
# 删除过期时间戳
ZREMRANGEBYSCORE user:123:requests 0 <timestamp - window>
# 统计窗口内请求数
ZCOUNT user:123:requests <timestamp - window> <timestamp>- 适合更精细的限流控制。
3. 令牌桶限流(Lua 脚本)
- Redis 端执行 Lua 脚本,保证原子性:
Lua
local key = KEYS[1]
local rate = tonumber(ARGV[1]) -- 每秒生成令牌数
local capacity = tonumber(ARGV[2]) -- 桶容量
local now = tonumber(ARGV[3]) -- 当前时间戳(秒)
local requested = tonumber(ARGV[4]) -- 请求令牌数
local fill_time = capacity / rate
local ttl = math.floor(fill_time * 2)
local last_tokens = tonumber(redis.call("get", key) or capacity)
local last_refreshed = tonumber(redis.call("get", key..":ts") or now)
local delta = math.max(0, now - last_refreshed) * rate
local tokens = math.min(capacity, last_tokens + delta)
local allowed = tokens >= requested
local new_tokens = tokens
if allowed then
new_tokens = tokens - requested
end
redis.call("setex", key, ttl, new_tokens)
redis.call("setex", key..":ts", ttl, now)
return allowed四、Java 固定窗口限流示例
java
import redis.clients.jedis.Jedis;
public class RedisFixedWindowLimiter {
private Jedis jedis;
private String key;
private int limit;
private int expireSeconds;
public RedisFixedWindowLimiter(String redisHost, String key, int limit, int expireSeconds) {
this.jedis = new Jedis(redisHost);
this.key = key;
this.limit = limit;
this.expireSeconds = expireSeconds;
}
public boolean tryAcquire() {
long count = jedis.incr(key);
if (count == 1) {
jedis.expire(key, expireSeconds);
}
return count <= limit;
}
public static void main(String[] args) {
RedisFixedWindowLimiter limiter = new RedisFixedWindowLimiter("127.0.0.1", "api:limit", 5, 1);
for (int i = 0; i < 10; i++) {
System.out.println("请求 " + (i + 1) + " -> " + (limiter.tryAcquire() ? "允许" : "拒绝"));
}
}
}五、注意事项
-
选择合适的算法
- 固定窗口简单,但边界可能有突发流量。
- 滑动窗口更平滑,但实现复杂。
- 令牌桶适合突发流量。
-
原子性
- 多步操作建议用 Lua 脚本保证原子性。
-
性能
- 限流操作要尽量轻量,避免复杂计算阻塞 Redis。
-
分布式环境
- Redis 限流天然支持多节点共享状态,适合分布式应用。
六、面试答题模板(简洁版)
Redis 限流常用固定窗口、滑动窗口、令牌桶等算法。
固定窗口用
INCR + EXPIRE实现,简单高效;滑动窗口用ZSET存时间戳,统计窗口内请求数;令牌桶用 Lua 脚本保证原子性,支持突发流量。Redis 限流的优势是高性能、分布式共享状态和原子性,适合高并发场景。
场景上,接口防刷用固定窗口,秒杀抢购用令牌桶,API 调用频率控制用滑动窗口。
✅ 总结 :
Redis 限流的核心是 利用 Redis 高性能和原子性 来记录和判断请求频率,选择合适的算法可以在不同业务场景下平衡性能和精度。
22. Redis 如何处理持久化文件损坏?
一、Redis 持久化文件类型
Redis 有两种持久化方式:
- RDB(快照)文件 :周期性将内存数据快照保存到磁盘(
dump.rdb)。 - AOF(Append Only File)文件 :记录每个写命令,重启时重放命令恢复数据(
appendonly.aof)。
二、持久化文件损坏的常见原因
-
磁盘故障
- 磁盘坏块、文件系统损坏导致文件不可读。
-
写入中断
- Redis 在写 RDB/AOF 时进程崩溃或机器断电,导致文件不完整。
-
软件 Bug
- Redis 版本 Bug 导致持久化文件格式错误。
-
人为误操作
- 手动编辑持久化文件或错误替换文件。
三、损坏的检测方法
1. RDB 文件检测
bash
redis-check-rdb /path/to/dump.rdb- 如果文件损坏,会提示错误位置。
2. AOF 文件检测
bash
redis-check-aof /path/to/appendonly.aof- 会检查 AOF 文件格式是否正确。
3. Redis 启动日志
-
如果持久化文件损坏,Redis 启动时会在日志中提示:
bashShort read or EOF reading RDB file或
bashAOF file is not valid
四、修复方案
1. 修复 RDB 文件
- 使用
redis-check-rdb修复:
bash
redis-check-rdb --fix /path/to/dump.rdb- 如果无法修复,可以尝试:
- 从备份恢复。
- 删除损坏的 RDB 文件,让 Redis 启动时加载空数据。
2. 修复 AOF 文件
- 使用
redis-check-aof修复:
bash
redis-check-aof --fix /path/to/appendonly.aof- 修复过程会截断损坏部分,保留可用数据。
3. 从备份恢复
- 如果有定期备份(RDB/AOF),直接替换损坏文件。
4. 数据迁移
- 如果文件无法修复,但 Redis 还能启动,可以:
- 启动 Redis。
- 使用
redis-cli --rdb或SCAN导出数据。 - 重新导入到新实例。
五、预防措施
-
开启 AOF + RDB 双持久化
- 即使一个文件损坏,另一个还能恢复数据。
-
定期备份
- 使用
cron定时复制 RDB/AOF 文件到安全位置。
- 使用
-
使用磁盘 RAID / SSD
- 提高磁盘可靠性。
-
启用 AOF fsync everysec
- 减少数据丢失风险。
-
监控持久化文件大小和写入状态
- 发现异常及时处理。
六、面试答题模板(简洁版)
Redis 持久化文件损坏可能是磁盘故障、写入中断、软件 Bug 或人为误操作导致的。
检测方法:
redis-check-rdb检查 RDB 文件。redis-check-aof检查 AOF 文件。- 查看 Redis 启动日志。 修复方法:
- 用
redis-check-rdb --fix或redis-check-aof --fix修复。- 从备份恢复。
- 启动 Redis 导出数据再导入新实例。 预防措施:
- 开启 AOF + RDB 双持久化。
- 定期备份。
- 使用可靠磁盘和 fsync everysec。 核心原则是:检测 → 修复 → 恢复 → 预防。
✅ 总结 :
Redis 持久化文件损坏并不可怕,关键是要有 检测工具 和 备份策略 ,并且在生产环境中建议开启 双持久化 以提高容灾能力。
23. Redis 4.0 混合持久化的原理?
一、背景
在 Redis 4.0 之前,持久化主要有两种方式:
- RDB(快照):启动快,文件小,但可能丢失最近一次快照后的数据。
- AOF(Append Only File):数据更安全(可秒级持久化),但文件大,重放速度慢。
问题:
- 如果只用 AOF,文件很大,重启时需要重放大量命令,恢复速度慢。
- 如果只用 RDB,恢复快,但可能丢失最近几秒的数据。
二、混合持久化的原理
混合持久化 就是在 AOF 重写(Rewrite) 时,将 RDB 快照数据 和 增量 AOF 命令 混合写入一个新的 AOF 文件。
核心流程
- AOF 重写开始 :
- Redis fork 一个子进程。
- 写入 RDB 快照部分 :
- 子进程先将当前内存数据以 RDB 格式写入新的 AOF 文件开头。
- 写入增量 AOF 命令部分 :
- 在 RDB 快照之后,继续写入从重写开始到结束期间的写命令(AOF 格式)。
- 替换旧 AOF 文件 :
- 新的混合文件替换旧的 AOF 文件。
三、文件结构
混合持久化的 AOF 文件结构:
[ RDB 格式数据 ] + [ AOF 格式增量命令 ]
- 前半部分:RDB 二进制快照(恢复速度快)。
- 后半部分:AOF 文本命令(保证数据完整性)。
四、优缺点
优点
- 启动速度快:前半部分是 RDB 格式,加载速度比纯 AOF 快很多。
- 数据更完整:后半部分的 AOF 命令保证了最近数据不丢失。
- 文件更小:比纯 AOF 文件小,因为大部分数据用压缩的 RDB 格式存储。
缺点
- 文件格式更复杂:不是纯 RDB,也不是纯 AOF,调试和手动解析更麻烦。
- 兼容性问题:老版本 Redis 不支持混合持久化文件。
五、开启方式
在 redis.conf 中开启:
aof-use-rdb-preamble yes
- 默认是
no,开启后会在 AOF 重写时使用混合持久化。
六、注意事项
-
只影响 AOF 重写
- 混合持久化只在 AOF 重写时生效,不影响普通 AOF 追加写。
-
恢复过程
- Redis 启动时先加载 RDB 部分,再重放 AOF 部分。
-
版本兼容
- 混合持久化文件只能在 Redis 4.0+ 使用,低版本无法识别。
-
备份策略
- 备份时要备份整个混合 AOF 文件,不要只备份 RDB 部分。
七、面试答题模板(简洁版)
Redis 4.0 引入了混合持久化(Hybrid Persistence),在 AOF 重写时将 RDB 快照和增量 AOF 命令混合写入一个新的 AOF 文件。
原理是:
- fork 子进程。
- 先写 RDB 格式的内存快照到新 AOF 文件。
- 再写重写期间的增量 AOF 命令。
- 替换旧 AOF 文件。 优点:
- 启动速度快(加载 RDB 部分)。
- 数据更完整(AOF 部分保证最近数据)。
- 文件更小。 缺点:
- 文件格式复杂。
- 老版本不兼容。 开启方式:
aof-use-rdb-preamble yes。
✅ 总结 :
混合持久化是 结合 RDB 启动快 和 AOF 数据完整 的一种优化方案,非常适合对启动速度和数据安全都有要求的场景,比如高并发的缓存服务、秒杀系统等。
24. Redis 内部数据结构有哪些?
一、背景
Redis 对外提供了 5 大数据类型:
- String(字符串)
- List(列表)
- Hash(哈希)
- Set(集合)
- ZSet(有序集合)
但在 内部实现 中,这些数据类型并不是直接用一种结构存储,而是根据数据量大小、元素类型等条件,选择不同的 底层数据结构 来优化性能和内存。
二、Redis 内部 5 大底层数据结构
1. SDS(Simple Dynamic String)
-
Redis 自己实现的动态字符串结构,替代 C 语言的
char*。 -
结构:
cppstruct sdshdr { int len; // 已使用长度 int free; // 剩余可用空间 char buf[]; // 实际存储数据 };c复制代码
struct sdshdr { int len; // 已使用长度 int free; // 剩余可用空间 char buf[]; // 实际存储数据 }; -
优点 :
- O(1) 获取字符串长度(
len字段)。 - 二进制安全(可存储
\0)。 - 减少内存分配次数(预分配策略)。
- O(1) 获取字符串长度(
2. LinkedList(双向链表)
- 用于存储 List 类型的大量元素(非压缩列表)。
- 特点:
-
双向链表,支持从两端快速插入/删除。
-
节点结构:
c复制代码
struct listNode { struct listNode *prev; struct listNode *next; void *value; };
-
3. Dict(哈希表)
- 用于实现 Hash 类型、键空间(keyspace)等。
- 采用 链地址法 解决哈希冲突。
- 支持 渐进式 rehash,避免一次性扩容阻塞。
4. Ziplist(压缩列表)
- 连续内存块存储多个元素,节省内存。
- 用于:
- 小型 List
- 小型 Hash
- 小型 ZSet
- 特点:
- 节省内存,但插入/删除需要移动内存,性能较差。
- 适合元素少且数据短的场景。
5. SkipList(跳表)
- 用于实现 ZSet(有序集合)。
- 特点:
- 多层索引结构,支持 O(logN) 查找、插入、删除。
- 适合范围查询(
ZRANGEBYSCORE)。
三、对象类型与底层数据结构映射
Redis 会根据数据量和元素大小,动态选择底层结构(编码方式):
| Redis 类型 | 编码方式(底层结构) | 触发条件 |
|---|---|---|
| String | int | 内容是整数且可用 long 表示 |
| embstr | 长度 ≤ 39 字节的字符串 | |
| raw | 长度 > 39 字节的字符串 | |
| List | ziplist | 元素个数 ≤ 512 且每个元素 ≤ 64 字节 |
| linkedlist | 超过 ziplist 限制 | |
| Hash | ziplist | field ≤ 512 且每个 field/value ≤ 64 字节 |
| hashtable | 超过 ziplist 限制 | |
| Set | intset | 元素全是整数且个数 ≤ 512 |
| hashtable | 超过 intset 限制 | |
| ZSet | ziplist | 元素个数 ≤ 128 且成员长度 ≤ 64 字节 |
| skiplist + dict | 超过 ziplist 限制 |
四、对象编码转换
- Redis 会在运行时根据数据变化自动转换编码。
- 例如:
- 一个小 Hash(ziplist 编码)不断增加字段 → 自动转为 hashtable 编码。
- 一个小 List(ziplist 编码)插入大元素 → 自动转为 linkedlist 编码。
五、内存优化建议
- 小数据用压缩结构
- 小 List/Hash/ZSet 用 ziplist 节省内存。
- 避免频繁编码转换
- 一次性插入大量数据,避免多次触发转换。
- 整数集合优化
- Set 全是整数时用 intset 节省内存。
六、面试答题模板(简洁版)
Redis 对外有 5 大数据类型,但底层用多种数据结构实现:
- SDS:动态字符串,O(1) 获取长度,二进制安全。
- LinkedList:双向链表,支持快速插入删除。
- Dict:哈希表,支持渐进式 rehash。
- Ziplist:压缩列表,节省内存,适合小数据。
- SkipList :跳表,支持有序集合和范围查询。 Redis 会根据数据量和元素大小自动选择编码,例如小 Hash 用 ziplist,大 Hash 用 hashtable。
这种设计既保证了性能,又优化了内存使用。
✅ 总结 :
Redis 内部数据结构是它高性能和高内存利用率的核心原因,理解这些结构有助于我们在业务中做出更优的存储设计。
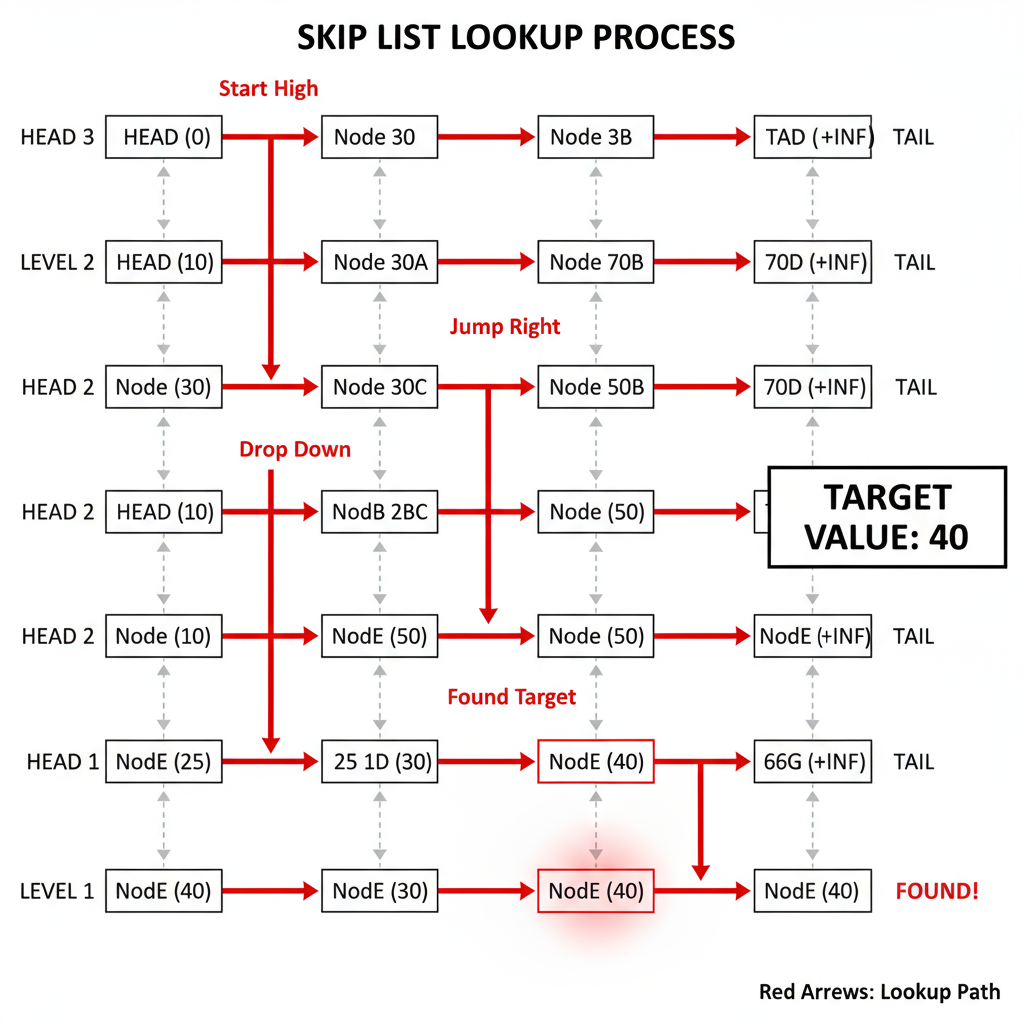
介绍一下 跳表(Skip List)
1. 定义
跳表是一种 有序链表的多层索引结构 ,用来提高查找、插入、删除的效率。
它的目标是用链表的方式实现类似 二分查找 的速度。
2. 核心思想
- 普通有序链表查找需要从头到尾遍历,时间复杂度是 O(n)。
- 跳表在链表上加了多层"跳跃索引",可以一次跨越多个节点。
- 这样查找时可以先在高层快速跳过大段数据,再在低层精确定位,平均时间复杂度 O(log n)。
3. 结构示意
Level 3: 1 --------- 9 --------- 20 Level 2: 1 ---- 5 ---- 9 ---- 15 ---- 20 Level 1: 1 - 2 - 3 - 5 - 7 - 9 - 12 - 15 - 18 - 20
- Level 1 是完整的有序链表。
- Level 2、Level 3 是抽取出来的部分节点,作为索引层。
- 查找时先从最高层开始,逐层向下。
4. 特点
- 查找、插入、删除 平均时间复杂度:O(log n)。
- 实现简单,比平衡树(如红黑树)更容易编码。
- 有序性:跳表天然支持范围查询,非常适合 Redis 的有序集合(ZSet)。
5. Redis 中的应用
- Redis 用跳表实现 ZSet(有序集合) 的范围查询功能,比如:
ZRANGEBYSCOREZREVRANGE
✅ 一句话总结 :
跳表就是在有序链表上加多层索引,让查找像二分查找一样快,同时保持链表的简单结构。
图示内容描述
-
整体结构
- 图中有三层:
- Level 3(最高层索引)
- Level 2(中间层索引)
- Level 1(底层完整链表)
- 每个节点用方框表示,节点之间用横线连接,表示链表的
next指针。 - 垂直方向用竖线连接同一个值在不同层的节点,表示"向下"指针。
- 图中有三层:
-
查找目标
- 目标值:15
- 起点:Level 3 的第一个节点(值为 1)。
-
查找过程箭头
- 第一步:从 Level 3 的 1 向右跳到 9(因为 20 太大,停在 9)。
- 第二步:从 9 向下到 Level 2 的 9。
- 第三步:在 Level 2 从 9 向右跳到 15(找到目标)。
- 箭头颜色:
- 水平箭头:表示"向右查找"。
- 垂直箭头:表示"向下到下一层"。
-
节点标注
- 每个节点上方标注它的值(如 1、5、9、15、20)。
- 目标节点(15)用红色高亮,表示查找成功。
流程总结
- 从最高层开始,向右走直到下一个节点值大于目标值。
- 向下走到下一层,继续向右查找。
- 重复这个过程,直到在底层找到目标值。
25. Redis 如何实现消息队列?
一、背景
消息队列的核心功能:
- 生产者:发送消息
- 消费者:接收消息
- 保证顺序:消息按发送顺序消费
- 保证可靠性:消息不丢失
Redis 虽然不是专业 MQ(如 Kafka、RabbitMQ),但它的 高性能、简单部署 让它在很多轻量场景下被用作消息队列。
二、Redis 实现消息队列的三种方式
1. 基于 List(阻塞队列)
- 使用
LPUSH/RPUSH生产消息。 - 使用
LPOP/RPOP消费消息。 - 使用
BLPOP/BRPOP阻塞等待消息(避免轮询)。
原理:
- List 是双端链表,插入和弹出都是 O(1)。
- 阻塞版本可以让消费者在没有消息时挂起,直到有新消息。
优点:
- 简单易用。
- 保证消息顺序。
- 支持阻塞消费。
缺点:
- 消息一旦被消费就删除,无法重复消费。
- 不支持多消费者共享同一条消息(除非自己实现广播)。
2. 基于 Pub/Sub(发布订阅)
- 使用
PUBLISH发送消息。 - 使用
SUBSCRIBE/PSUBSCRIBE接收消息。
原理:
- Redis 内部维护一个订阅表,生产者发布消息时,所有订阅该频道的消费者都会收到。
优点:
- 支持广播(多消费者同时收到)。
- 实时性高。
缺点:
- 消息不持久化,消费者离线期间的消息会丢失。
- 无法回溯历史消息。
3. 基于 Stream(Redis 5.0+)
- 使用
XADD添加消息。 - 使用
XREAD/XREADGROUP消费消息。 - 支持消费者组(Consumer Group)。
原理:
- Stream 是持久化的消息日志,类似 Kafka。
- 每条消息有唯一 ID。
- 消费者组可以让多个消费者共享队列,并且每条消息只被一个消费者处理。
优点:
- 消息持久化,可回溯。
- 支持多消费者组。
- 支持确认机制(ACK),保证消息至少被处理一次。
缺点:
- 相比 List/PubSub,API 更复杂。
- 内存占用更高。
三、场景选择建议
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 简单任务队列 | List + BLPOP | 简单、顺序、阻塞消费 |
| 实时广播 | Pub/Sub | 多消费者同时收到消息 |
| 持久化、高可靠 | Stream | 支持回溯、ACK、消费者组 |
四、面试答题模板(简洁版)
Redis 可以用三种方式实现消息队列:
- List:用 LPUSH/BRPOP 实现阻塞队列,简单高效,适合单消费者场景。
- Pub/Sub:用 PUBLISH/SUBSCRIBE 实现发布订阅,适合实时广播,但不持久化。
- Stream:Redis 5.0 引入的持久化消息队列,支持消费者组、ACK、回溯,适合高可靠场景。 场景选择:
- 简单任务队列 → List
- 实时广播 → Pub/Sub
- 高可靠、可回溯 → Stream
✅ 总结 :
Redis 实现消息队列的方式很多,List 适合简单任务,Pub/Sub 适合实时广播,Stream 适合高可靠场景。选型时要根据 是否需要持久化、是否多消费者、是否需要回溯 来决定。
26. Redis 如何保证高可用和数据一致性?
一、背景
Redis 是内存数据库,单节点可能会因为:
- 宕机(硬件/软件故障)
- 网络分区(网络抖动)
- 升级维护(人工操作)
而导致服务不可用或数据丢失。
因此需要 高可用(HA) 来保证服务持续运行,并且要考虑 数据一致性,避免主从数据不一致导致业务异常。
二、Redis 高可用方案
1. 主从复制(Replication)
- 原理:一个主节点(Master)负责写操作,多个从节点(Slave)复制主节点数据。
- 作用 :
- 读写分离(从节点分担读压力)。
- 主节点故障时可手动切换到从节点。
- 缺点 :
- 主从切换需要人工或额外组件。
- 主从复制是异步的,可能丢失数据。
2. Sentinel(哨兵模式)
- 原理 :
- 部署多个 Sentinel 节点监控主节点。
- 主节点宕机时,Sentinel 自动选举一个从节点为新主节点,并通知客户端。
- 优点 :
- 自动故障转移(Failover)。
- 无需人工干预。
- 缺点 :
- 切换期间可能丢失数据(异步复制延迟)。
- 需要至少 3 个 Sentinel 节点保证选举可靠性。
3. Redis Cluster(集群模式)
- 原理 :
- 数据分片存储在多个主节点(Master)上,每个主节点有从节点(Slave)做备份。
- 使用 哈希槽(Hash Slot) 分配数据(16384 个槽)。
- 节点间通过 Gossip 协议交换状态。
- 优点 :
- 水平扩展(分布式存储)。
- 自动故障转移。
- 缺点 :
- 只能使用部分命令(不支持跨槽事务)。
- 数据一致性依然是异步复制。
三、Redis 数据一致性机制
1. 异步复制
- 默认主从复制是异步的,主节点写成功后立即返回,不等待从节点确认。
- 优点:性能高。
- 缺点:主节点宕机可能丢失最近写入的数据。
2. 半同步复制(WAIT 命令)
-
客户端写入后,可以用:
bashWAIT numreplicas timeout等待至少
numreplicas个从节点确认写入。 -
优点:减少数据丢失风险。
-
缺点:增加写延迟。
3. 持久化(RDB / AOF)
- RDB:定期快照,启动快,但可能丢失最近一次快照后的数据。
- AOF :追加写日志,可配置
appendfsync always/everysec/no控制刷盘频率。 - 高可用场景下,持久化可以减少主从同时宕机时的数据丢失。
4. 网络分区与脑裂(Split-Brain)处理
- 问题:主节点与从节点网络断开,Sentinel 可能错误地将从节点提升为主节点,导致两个主节点同时写入。
- 解决 :
- 配置
min-slaves-to-write和min-slaves-max-lag限制主节点在失去多数从节点时拒绝写入。 - 在 Redis Cluster 中,使用多数派(quorum)机制避免脑裂。
- 配置
四、常见问题
- 主从延迟:高并发写入时,从节点可能落后主节点几百毫秒到几秒。
- 数据丢失:主节点宕机前的最后几条写入可能没同步到从节点。
- 脑裂:网络分区导致多个主节点同时写入,数据冲突。
五、场景建议
| 场景 | 推荐方案 | 说明 |
|---|---|---|
| 单机高可用 | 主从 + Sentinel | 自动故障转移 |
| 高并发读写 | Cluster | 分片扩展,读写分离 |
| 数据安全优先 | 半同步复制 + AOF everysec | 减少数据丢失 |
| 跨机房容灾 | 异地多活 + 双向复制 | 需额外冲突解决机制 |
六、面试答题模板(简洁版)
Redis 高可用主要通过 主从复制、Sentinel、Cluster 实现:
- 主从复制:读写分离,提供备份。
- Sentinel:监控主节点,自动故障转移。
- Cluster:分片存储,自动容错。 数据一致性方面:
- 默认是异步复制,可能丢数据。
- 可用
WAIT命令实现半同步复制。- 持久化(RDB/AOF)减少宕机数据丢失。
- 配置
min-slaves-to-write避免脑裂。 选型时要根据业务对 可用性、性能、一致性 的要求做权衡。
✅ 总结 :
Redis 高可用依赖 多副本 + 自动故障转移 ,数据一致性依赖 复制机制 + 持久化 + 网络分区保护 。在设计时必须权衡 性能、可用性、一致性(CAP 原则)。