摘要
该模块旨在连接多类型数据源(数据库、文件、API 等),通过灵活的抽取策略(全量 / 增量)获取数据,经处理后以主动推送或被动拉取方式供给上层应用。核心采用分层架构(数据源接入层、抽取策略层、数据处理层、输出推送层、任务调度与管理层),辅以配置中心、监控告警、容错机制保障可靠性,并支持插件化扩展与分布式部署,实现 "多源适配、灵活抽取、多样推送、可控可靠" 的目标。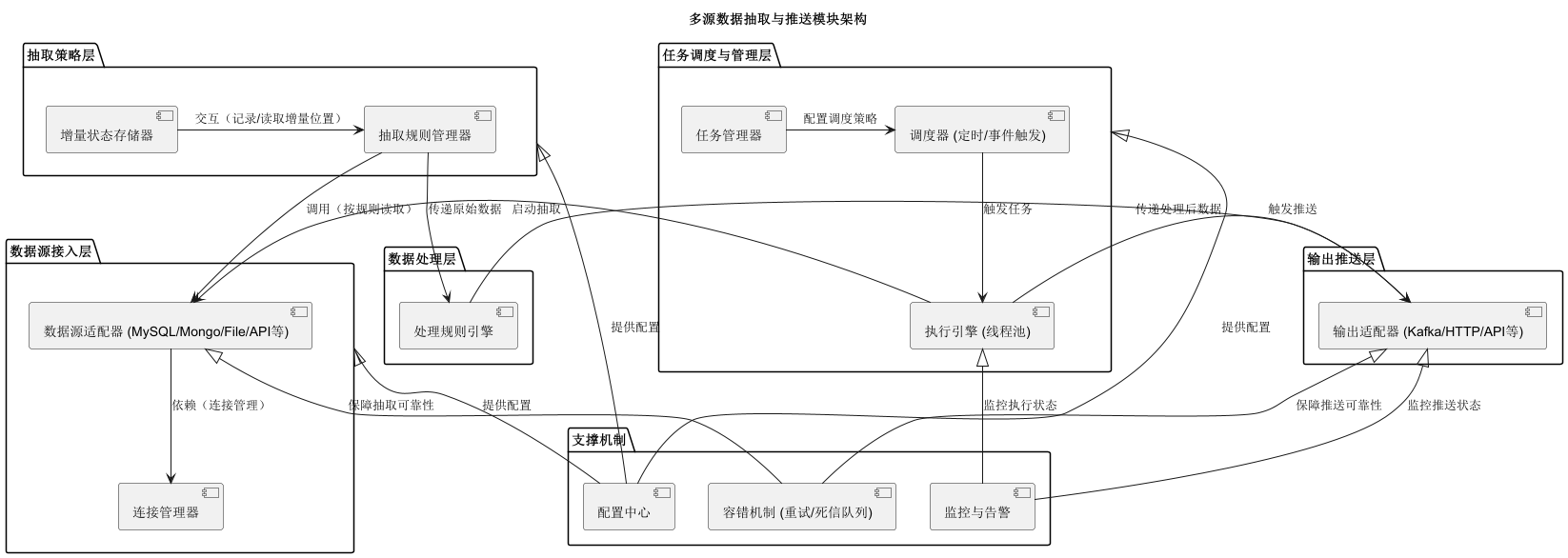
设计一个连接多数据源、支持灵活数据推送的数据抽取模块,核心要解决多源适配、抽取策略灵活、推送方式多样、可靠可控四大问题。以下从架构分层、核心组件、关键机制、扩展设计四个维度展开,提供可落地的方案:
一、架构分层设计(自下而上)
采用分层解耦思想,每层专注单一职责,通过接口定义边界,便于扩展和维护。
1. 数据源接入层(最底层)
目标 :屏蔽不同数据源的协议差异,提供统一的 "数据读取接口"。核心能力:适配关系型数据库、非关系型数据库、文件、API、消息队列等各类数据源。
-
组件:
- 数据源适配器(Adapter):为每种数据源实现专属适配器,如
MySQLAdapter(JDBC + binlog 解析)、MongoAdapter(MongoDB 驱动)、FileAdapter(CSV/JSON 解析)、ApiAdapter(HTTP/HTTPS 客户端)、KafkaAdapter(消费者)等。 - 连接管理器:统一管理数据源连接(创建、复用、销毁),处理认证(账号密码加密存储)、超时重试,避免连接泄露。
- 数据源适配器(Adapter):为每种数据源实现专属适配器,如
-
接口定义 :所有适配器实现
DataSource接口,包含核心方法:java
运行
public interface DataSource { boolean connect(DataSourceConfig config); // 连接数据源 void disconnect(); // 断开连接 Stream<Map<String, Object>> read(ExtractRule rule); // 按规则读取数据(返回流式结果,避免内存溢出) }
2. 抽取策略层(核心层)
目标 :根据业务需求选择全量 / 增量抽取方式,确保数据完整性和效率。核心能力:支持多样化的抽取规则,解决 "抽什么、怎么抽" 的问题。
-
抽取类型:
- 全量抽取:一次性读取数据源所有符合条件的数据(适合初始化、小量数据)。
- 增量抽取:仅读取新增 / 变更数据(适合常态同步),依赖三种增量标识:
- 时间戳(如
update_time > last_extract_time); - 自增 ID(如
id > last_max_id); - 日志解析(如 MySQL binlog、Mongo Oplog,适合实时性要求高的场景)。
- 时间戳(如
-
核心组件:
- 抽取规则管理器:存储抽取规则(如过滤条件
where status = 1、字段映射{源字段: 目标字段}),支持通过配置中心动态更新。 - 增量状态存储器:记录每个任务的上次抽取位置(如
task_id -> last_time/last_id/binlog_pos),用 Redis 或数据库实现,确保断点续传。
- 抽取规则管理器:存储抽取规则(如过滤条件
3. 数据处理层(可选但推荐)
目标 :将抽取的原始数据转换为上层应用可直接使用的 "干净数据"。核心能力:标准化格式、清洗脏数据,减少上层应用的处理成本。
-
处理动作:
- 格式转换:统一为 JSON/Protobuf 等格式(如将 MySQL 的
datetime转为时间戳,Mongo 的ObjectId转为字符串)。 - 清洗:去重(基于唯一键
id)、过滤(剔除null值或无效数据)、补全(缺失字段用默认值填充)。 - enrichment(可选):关联外部数据补充字段(如通过 IP 查询地域)。
- 格式转换:统一为 JSON/Protobuf 等格式(如将 MySQL 的
-
组件:处理规则引擎(如用 Groovy 脚本配置处理逻辑,支持动态生效)。
4. 输出推送层(最上层)
目标 :支持多种推送方式,满足上层应用 "按需获取" 或 "实时接收" 的需求。核心能力:适配不同的输出目标,灵活控制推送时机和方式。
-
推送方式:
- 主动推送:模块主动将数据发送给目标,如:
- 消息队列(Kafka/RabbitMQ):适合高吞吐场景,应用订阅消费;
- HTTP 回调:推送到应用的 API 接口(支持重试机制);
- WebSocket:适合实时展示场景(如监控面板)。
- 被动拉取:应用主动查询数据,如:
- 数据服务 API:提供 REST 接口(支持分页、过滤参数);
- 临时存储:将数据暂存到 Redis/MinIO,应用按需读取。
- 主动推送:模块主动将数据发送给目标,如:
-
组件 :输出适配器(如
KafkaOutputAdapter、HttpOutputAdapter),实现DataOutput接口,包含push(Stream<Map<String, Object>> data)方法。
5. 任务调度与管理层(跨层协调)
目标 :统筹抽取任务的全生命周期,确保按预期执行。核心能力:任务配置、调度、监控、容错。
- 核心组件 :
- 任务管理器:维护任务元信息(数据源、抽取规则、输出目标、调度策略),支持任务的创建 / 启动 / 暂停 / 删除。
- 调度器:基于 CRON 表达式(定时,如每小时一次)或事件触发(如文件新增、API 回调)启动任务,分布式场景可用 XXL-Job/Elastic-Job。
- 执行引擎:用线程池管理任务执行,控制并发(避免压垮数据源),记录执行状态(成功 / 失败 / 运行中)。
二、关键支撑机制
1. 配置中心
集中管理所有动态配置,避免硬编码,支持通过 UI 界面或 API 修改:
- 数据源配置:连接串、账号密码(AES 加密存储)、超时时间;
- 任务配置:抽取规则(字段、过滤条件)、增量标识、调度频率、输出目标;
- 系统配置:线程池大小、重试次数、缓冲区容量。
2. 监控与告警
- 指标收集:任务成功率、单任务耗时、抽取数据量、输出延迟等(用 Prometheus 采集);
- 日志记录:详细记录抽取过程(错误栈、数据量)、用户操作(谁修改了任务);
- 告警触发:任务失败、超时、数据量突增 / 突减时,通过邮件 / 钉钉 / 短信通知管理员。
3. 容错与可靠性
- 重试机制:抽取 / 推送失败时,按配置的重试次数(如 3 次)和间隔(如 10s)重试;
- 死信队列:多次重试失败的数据存入死信队列,支持人工干预后重发;
- 幂等性保障:输出层通过唯一标识(如
task_id + data_id)去重,避免重复推送。
三、扩展设计(应对未来需求)
- 插件化适配器:通过 SPI 机制加载自定义适配器(如新增 Oracle 数据源、MQTT 输出),无需修改核心代码;
- 分布式部署:任务分片执行(如按 ID 范围拆分大表抽取),用 ZooKeeper 协调节点,避免单点故障;
- 数据压缩与序列化:大量数据传输时,用 gzip 压缩 + Protobuf 序列化(比 JSON 节省 50%+ 带宽);
- 元数据管理:记录数据源表结构、数据血缘(来源 -> 目标),支持数据资产盘点。
四、示例流程
- 配置任务 :用户在配置中心添加任务:"从 MySQL 的
order表,每 10 分钟增量抽取update_time > 上次时间的数据,过滤status=1的订单,推送到 Kafka 的order_sync主题"; - 任务执行 :调度器触发任务,执行引擎分配线程,
MySQLAdapter连接数据库,按增量规则读取数据; - 数据处理 :转换层将
create_time转为时间戳,过滤无效订单; - 推送数据 :
KafkaOutputAdapter将处理后的数据发送到 Kafka,同时更新增量状态(记录本次最大update_time); - 监控反馈:监控面板更新任务成功率和数据量,若推送失败则触发重试 + 告警。
通过以上设计,模块可实现 "多源接入无感知、抽取策略可配置、推送方式灵活选、运行状态可监控",满足上层应用对数据的多样化需求。