😊文章背景
题目:Large language models for PHM: a review of optimization techniques and applications
期刊:Autonomous Intelligent Systems
检索情况:EI
作者:Tingyi Yu1, Junya Tang1, Qingyun Yu1* , Li Li1, Ying Liu2 and Raul Poler3
单位:同济大学电子与信息工程学院
发表年份:2025
DOI:10.1007/s43684-025-00100-5
网址:https://link.springer.com/10.1007/s43684-025-00100-5
📌 研究目标
总结LLM在预测与健康管理(PHM)中面临的挑战、关键技术、现状和未来发展方向。
✅ 研究结论
-
LLMs为PHM带来了革命性的"认知"能力,但直接应用效果不佳。
简要说明:LLMs的核心优势在于其强大的语言理解、推理和泛化能力,这超越了传统AI模型。这使它不仅能分析数据,还能理解维修手册、生成报告、进行人机对话。但将其直接用于工业PHM任务(如分析传感器数据)效果不好,必须经过专门优化和适配。
-
通过"量化"和"高效微调"技术,LLMs可以在工业界可行地部署。
简要说明 :文章的核心结论之一是,尽管LLMs庞大,但通过量化 技术可以大幅缩减其体积和计算需求,使其能在资源有限的工业硬件上运行。同时,通过**参数高效微调(PEFT)**技术,可以用较小的计算成本让LLMs快速学习特定工业领域的知识,而无需从头训练。
-
多模态能力是LLMs在PHM中发挥价值的关键。
简要说明 :工业PHM涉及的数据类型多样,包括文本(日志、手册)、图像(红外热成像、视觉检测)、时间序列(振动、温度传感器数据)等。文章强调,将LLMs扩展为多模态大模型(MM-LLMs),使其能同时理解和处理这些不同类型的数据,是实现全面智能运维的关键突破。
-
LLMs在PHM中已展现出三大有前景的应用方向:异常检测、故障诊断和智能问答。
简要说明 :文章总结了LLMs在PHM中的具体应用场景:
- 故障诊断:结合历史数据和知识进行推理,定位故障根本原因。
- 异常检测:利用其强大的模式识别能力发现数据中的异常。
- 智能问答(QA) :作为专家系统,为现场工人提供即时、准确的维修指导。其中,**检索增强生成(RAG)**技术被特别强调为解决LLMs知识过时和专业性不足的有效方法。
5.尽管潜力巨大,但可靠性、可解释性等挑战仍是未来研究的重点。
简要说明 :文章在结论中明确指出,将LLMs用于工业PHM仍面临严峻挑战。主要包括:模型的可靠性 和安全性 (在关键任务中不能出错)、可解释性 (让用户理解其决策过程)、数据隐私 以及持续学习(适应不断变化的工业环境)等。解决这些挑战是未来LLMs在工业界成功落地的关键。
📈 研究意义
🔮 未来研究方向
⭐收获与启发
一、引言怎么写
- 本文引言的结构:
- 确立背景与现状:机器学习在PHM领域中的应用;
- **指出当前技术的局限性:**机器学习和深度学习的痛点;
- **提出解决方案:**将LLM定位为解决上述局限性的理想候选者,并将其描述为一种可支持多种应用的"基础模型"新范式。
- 界定研究空白:尽管LLM潜力巨大,但其在PHM领域的应用仍处于探索阶段,缺乏系统性的方法论和全面的文献综述。
- **概述论文结构:**用一段话简要概括后续每一章(第2、3、4、5章)的核心内容。
- 写引言的"万能公式":
-
从大家熟悉的现状说起("我们都知道目前用的是A技术...")
-
但是,A技术有这些缺点...("然而,A技术无法解决X和Y问题...")
-
幸运的是,现在出现了一个新技术B("近年来,B技术的出现带来了转机,因为它具有Z优势...")
-
但是,关于B技术在我们这个领域的应用,还缺少研究("然而,如何将B技术具体应用于我们的领域,仍缺乏系统性的指导...")
-
因此,我写了这篇论文,它的结构是这样的...("本文旨在填补这一空白,第二章将讨论...,第三章将分析...")
-
二、三种深度学习模型各自擅长的领域:
- 自编码器AE:降噪、降维和异常检测
- 卷积神经网络(CNN):工业图像分析和周期性时间序列处理
- 循环神经网络(RNN):时间序列信号
三、微调:实际上是迁移学习的一个实例
- **微调的本质:**将一个在通用任务(源任务)上训练好的模型,通过少量数据迁移到特定任务(目标任务)上的过程。
- 根据需要选择合适的微调方法:
-
追求综合效果和通用性 :首选 LoRA 及其变体(如QLoRA)。
-
追求极致的轻量和简单 :可以考虑 Prompt Tuning 或 (IA)³。
-
面对复杂任务,要求高性能 :可以尝试 P-Tuning v2。
-
需要模型快速切换不同角色 :Adapter 方法很有优势。
-
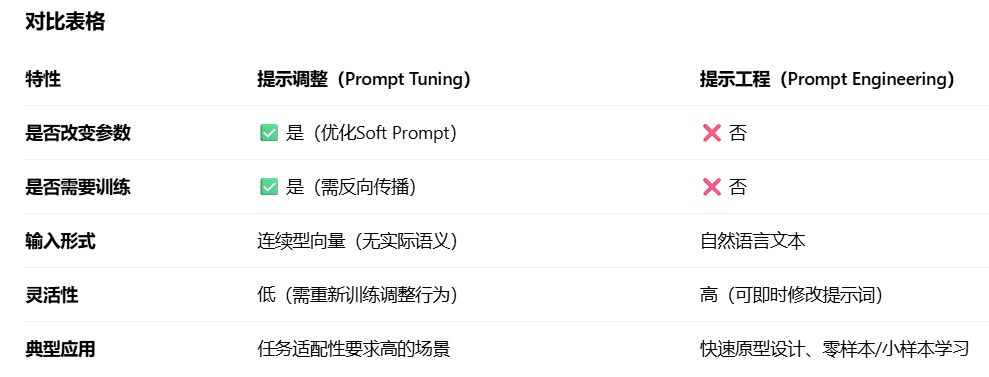
大模型LLM:最清晰解读提示工程(Prompt Engineering)-CSDN博客
- 提示工程≠提示微调 ,提示工程与提示调整的区别:
- 关键在于有没有改变模型内部参数;
- 从可解释性分类,提示可分为:
- 硬提示:提示工程生成;
- 软提示:提示调整生成。
📕专业名词
-
大型语言模型(LLM)
-
学术定义:一种基于海量文本数据训练的、拥有数十亿甚至更多参数的深度学习模型,能够理解、生成和处理自然语言。
-
外行解释:一个超级强大的"文本大脑",比如ChatGPT。它通过阅读互联网上的海量文本学会了人类的语言模式,可以聊天、写作和回答问题。
-
-
故障预测与健康管理(PHM)
-
学术定义:一个专注于评估设备健康状况、预测故障发生时间及管理设备可靠性的工程领域。
-
外行解释:给机器做"全身体检和健康管理"。目标是像医生一样,通过检查机器的"体温"(温度)、"心跳"(振动)等数据,来预测它什么时候会"生病"(故障),并提前安排"治疗"(维修)。
-
第二章:架构与部署
-
Transformer 架构
-
学术定义:一种主要基于自注意力机制的深度学习模型架构,是现代LLM的基石。
-
外行解释 :建造"AI大脑"的标准蓝图。就像盖房子有标准的设计图纸一样,几乎所有的大语言模型都基于这个核心设计。
-
-
量化
-
学术定义:通过降低模型权重的数值精度(如从32位浮点数降至8位或4位整数)来减小模型体积和加速推理的技术。
-
外行解释:给AI模型"减肥"或"压缩"。就像把一张超高清的RAW格式照片转成JPEG格式,文件变小了,虽然在电脑上放大看细节有损失,但用手机浏览效果几乎没差别,而且传输和打开速度快多了。
-
-
KV缓存
-
学术定义:在生成式模型中,缓存先前计算过的键值对以加速后续自回归生成过程的技术。
-
外行解释:AI的"短期记忆便签"。当它和你聊天时,会把之前对话的要点记在便签上,这样在说下一句话时就不用重新回忆整个对话,从而回答得更快。
-
-
FlashAttention
-
学术定义:一种优化注意力计算过程的算法,通过减少GPU内存访问次数来显著提升计算速度和效率。
-
外行解释:一种更聪明的"工作方法"。就像一个有经验的厨师在做菜前会把所有食材和厨具有序地放在手边,避免来回跑冰箱和橱柜,从而极大地提高做菜效率。
-
第三章:微调与多模态
-
参数高效微调(PEFT)
-
学术定义:一类微调技术,其目标是仅更新或引入一小部分额外参数来适配下游任务,而非调整整个模型的参数。
-
外行解释 :给"AI大脑"报一个短期速成班。比如这个大脑本来是个通才,现在你想让它成为医疗专家。PEFT不是让它重新上学(那样成本极高),而是给它一本薄薄的《医学速成手册》,只学习新知识,就能快速变身专家。
-
-
LORA(低秩适应)
-
学术定义:一种流行的PEFT方法,通过向模型注入低秩矩阵来模拟参数更新,从而高效适配新任务。
-
外行解释:给AI模型穿上一件"技能马甲"。这件薄薄的马甲上写满了特定任务(如医疗诊断)的窍门。模型穿上马甲就获得了新技能,脱掉马甲又变回原来的自己,非常灵活。
-
-
多模态大语言模型(MM-LLM)
-
学术定义:能够理解和处理多种类型信息(如文本、图像、音频)的大语言模型。
-
外行解释:一个"耳聪目明"的AI大脑。它不仅会读文字,还能"看"懂图片、"听"懂声音,并把这些信息结合起来理解世界。比如,你给它一张设备故障的图片,它能描述出哪里坏了以及可能的原因。
-
第四章:应用
-
异常检测
-
学术定义:识别数据中与预期模式显著偏离的实例或模式的过程。
-
外行解释:AI"警报系统"。它持续监控机器的数据,一旦发现某个数据(如振动幅度)变得"不正常",就像烟雾报警器闻到烟味一样,立即发出警报。
-
-
故障诊断
-
学术定义:在检测到异常后,确定故障的根本原因、位置和类型的过程。
-
外行解释:AI"医生"进行诊断。警报响了之后,AI会分析各种数据,像老医生一样判断:"是轴承磨损了,而不是电机缺油",找出问题的根源。
-
-
检索增强生成(RAG)
-
学术定义:一种将外部知识库与LLM相结合的技术,通过在生成答案前从知识库中检索相关信息来提高回答的准确性和时效性。
-
外行解释:让AI学会"查资料再回答"。当工人问一个专业问题时,AI不会只凭自己的记忆回答,而是会先去翻阅最新的维修手册、历史记录等"参考资料",然后结合资料给出最准确的答案,避免胡说八道。
-