文章目录
- 一、正则表达式(简版)
-
- [1.1 限定符](#1.1 限定符)
- [1.2 或:| 运算符](#1.2 或:| 运算符)
- [1.3 字符类](#1.3 字符类)
- [1.4 元字符](#1.4 元字符)
- [1.4 贪婪与懒惰匹配](#1.4 贪婪与懒惰匹配)
- [1.5 总结](#1.5 总结)
- [1.6 其他教程](#1.6 其他教程)
- 二、正则表达式(详细版)
-
- [2.1 正则表达式的作用](#2.1 正则表达式的作用)
- [2.2 基本语法---基本匹配规则](#2.2 基本语法---基本匹配规则)
- [2.3 位置和边界匹配](#2.3 位置和边界匹配)
- [2.4 量词](#2.4 量词)
- [2.5 分组和引用](#2.5 分组和引用)
- [2.6 前瞻和后顾](#2.6 前瞻和后顾)
学习视频:
https://www.bilibili.com/video/BV1da4y1p7iZ/?spm_id_from=333.337.search-card.all.click
一、正则表达式(简版)
- 在线测试工具:https://regex101.com/
1.1 限定符
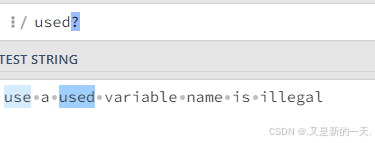
?:代表?前面的字符需要出现0次或者1次。也就是说?前面的字符可有可无。
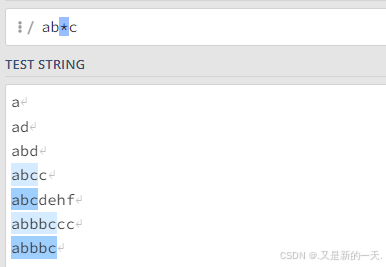
*:匹配0个或者多个字符,如下:ab*c:意思是b*的b可以有0个或者多个字符。即a和c之间只能出现0个或者多个b
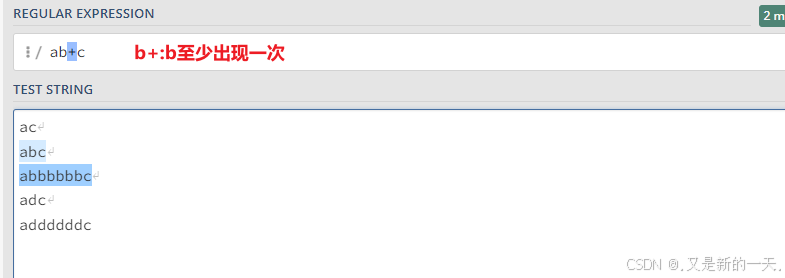
+:匹配出现一次以上的字符,如下:第一个ac没有被成功匹配,因为b至少出现一次
{}:指定字符出现的次数或者允许我们输入一个范围:
比如指定某个字符:b出现6次:b{6}
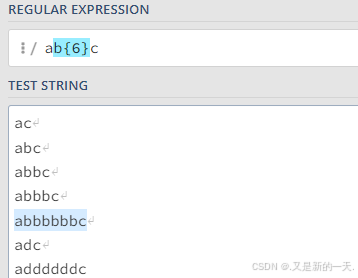
比如我们希望字符b出现的次数为2到6之间(闭区间):b{2,6}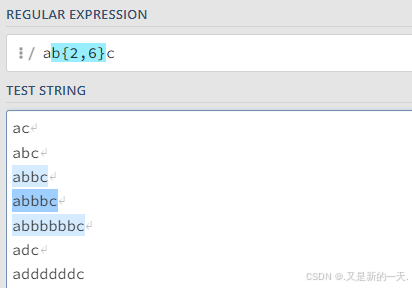
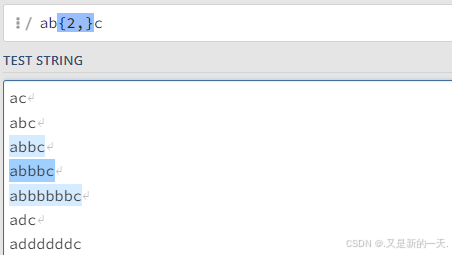
如果希望字符b出现的次数为两次以上(闭区间):可以直接省略这个6,也就是b{2,}
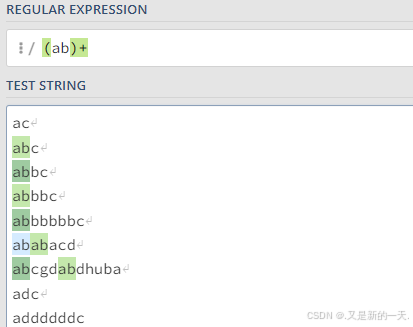
(...) +用于匹配 "括号里的内容作为一个整体,连续重复 1 次或多次"。

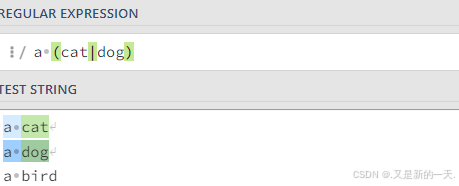
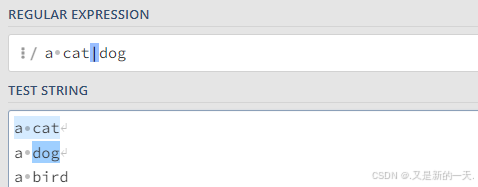
1.2 或:| 运算符
- 取或,二者均会被选中
1.3 字符类
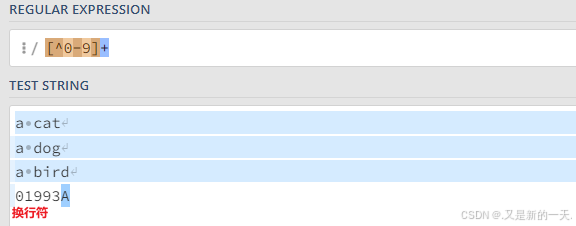
[]:比如我们想要匹配由abc这几个字母构成的单词,可以写作[abc]+。方括号里面的内容代表要求匹配的字符只能取自它们。另外我们可以在[]里面指定它们的范围,比如[a-z]代表所有的小写字符,[a-zA-Z]代表所有的英文字符,[a-zA-Z0-9]代表所有的英文字符和数字^:非:比如[^]:代表要求匹配除了^后面列出的[以外]的字符。举例:[^0-9]代表所有的非数字字符(包括换行符)
1.4 元字符
- 元字符定义:正则表达式中其实为我们预先定义好了一系列常用的字符类型,比如数字、空白符、单词开头、单词结尾等等。正则表达式当中的大多数元字符都以反斜杠开头
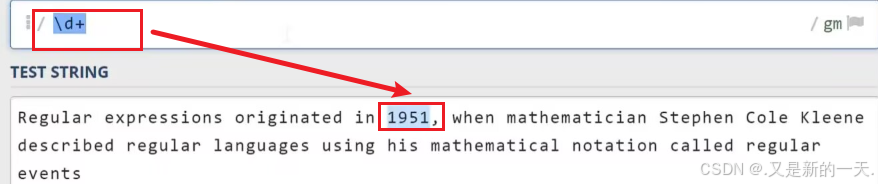
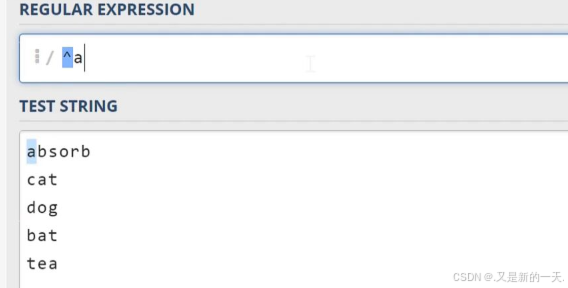
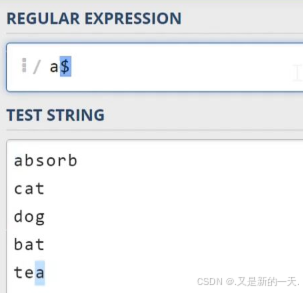
\d:数字字符:等同于之前写的[0-9]\w代表单词字符,也就是所有的英文字符数字加上下划线\s代表空白符,它同时包含Tab字符(制表符)以及换行符\D:代表非数字符号\W:非单词字符\S:非空白字符.代表任意字符,但不包含换行符^:匹配行首:比如^a只会去匹配行首的a$;匹配行尾:比如a$只会匹配行尾的a- 实操举例:
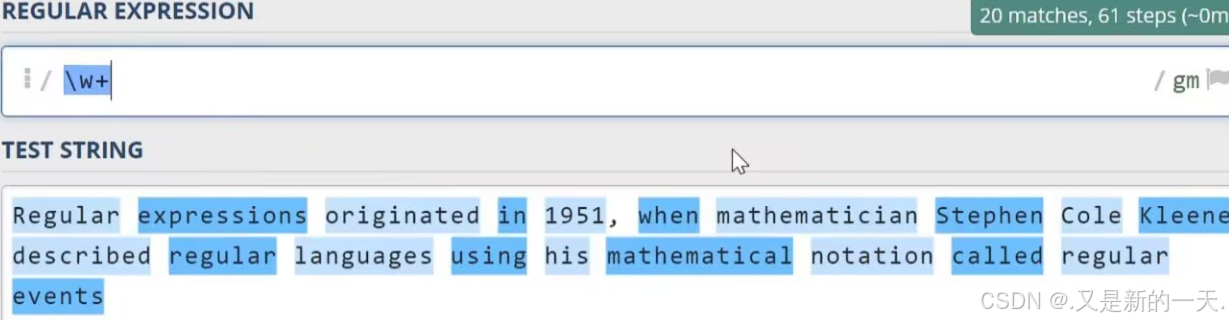
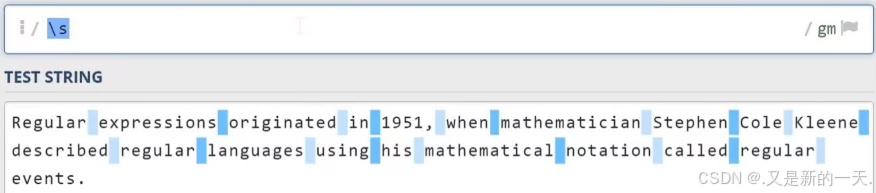
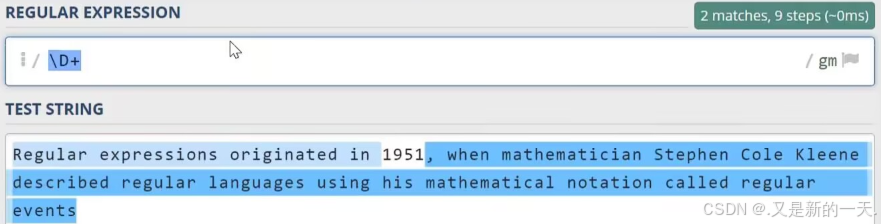
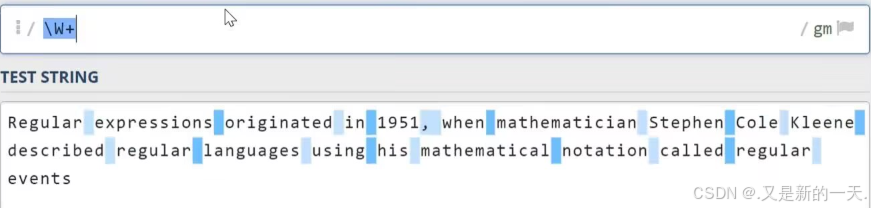
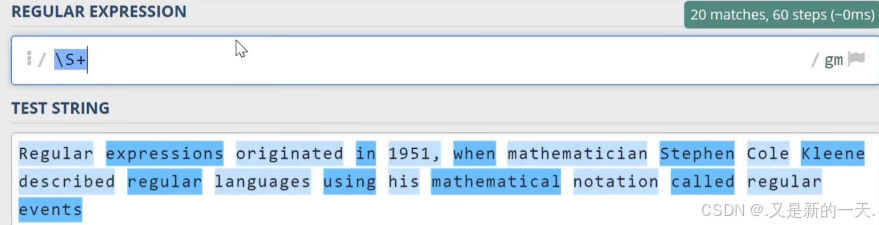
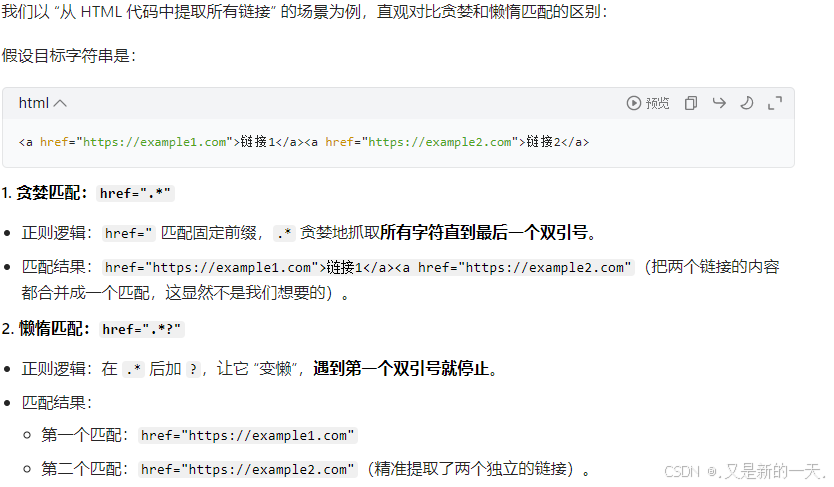
1.4 贪婪与懒惰匹配
- 之前的
*+{}在匹配字符串的时候,默认会去匹配尽可能多的字符---贪婪匹配 - 贪婪匹配切换成懒惰匹配的方法:添加
?等限制范围的,包括但不局限于?
1.5 总结
- 正则表达式总结:

1.6 其他教程
- 正则表达式 30 分钟入门教程 作者: deerchao
https://deerchao.cn/tutorials/regex/regex.htm - Regex tutorial --- A quick cheatsheet by examples (英文) 作者: Jonny Fox
https://medium.com/factory-mind/regex-tutorial-a-simple-cheatsheet-by-examples-649dc1c3f285 - Regular Expressions Tutorial (英文)
https://www.regular-expressions.info/tutorial.html
二、正则表达式(详细版)
2.1 正则表达式的作用
- 正则表达式可以非常精确的描述你想要匹配的字符组合,从而使得文本处理更加高效和灵活。
2.2 基本语法---基本匹配规则
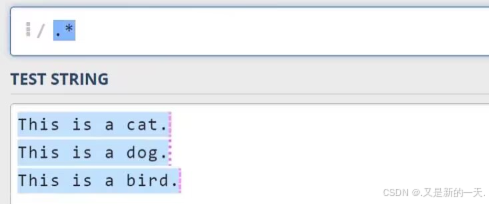
.:表示除了换行符之外的任意一个 字符。.可以放在任意的位置,如果只想匹配.,那么需要加上转义字符:\.
比如:
.放在末尾:at.会匹配以at开头的末尾加上任意一个字符的内容:如ata,atb,atc等
.放在开头:.at:会匹配所有的以任意一个字符开头并且以at结尾的字符串,如:bat,cat
.放在中间:a.t:会匹配所有的a和t之间只有一个字符的字符串,如:abt,act[]:使用单个字符: 如果并不想要匹配所有的字符,只想要匹配指定的几个字符的话,可以使用[]来表示一个字符(只往后匹配一个字符) 集合------比如:想找到at后面跟着一个c或者e或者s的字符串的话,就可以在at后面加上一个方括号:at[ce],就会匹配atc/ate/ats.在[]里面也可以加上一些数字或者其他字符[]:使用-来表示范围: 比如[a-z]表示从a到z的所有的小写字母。at[a-z]:可以匹配比如:ata,atz[]中还可以加上数字:比如at[1-3],就可以匹配到如at1/at2/at3[]中还可以加上^表示取反:比如at[^1-3],就可以匹配到不是如at1/at2/at3这种,而是at4/at5/at6这种- 注意:
^只有在方括号内部才表示取反,在方括号外面的话就表示匹配每一行的开头 - 预定义的字符类:
\d表示数字,作用和0-9是一样的:at\d等价于at[0-9]
\D表示非数字,不匹配数字
\w:表示字母,数字或者下划线
\W:表示非字母,数字或者下划线之外的字符
\s:表示空白字符:也就是空格或者Tab等等
\S:表示非空白字符:也就是除了空格或者Tab之外的部分
2.3 位置和边界匹配
^:匹配每一行的开头:比如^a只会去匹配行首的a$;匹配每一行的结尾:比如a$只会匹配行尾的a\b:表示单词的边界:比如我们输入一个in的话就会找到下面所有的in,但是包括了在单词中间的in,也包括了在单词结尾或者开头的in,当然还有独立的in。
如果只想匹配在单词开头的in的话,就可以在in的前面加上一个\b:\bin:这样就只有以in开头的部分被高亮显示了,原来在单词中间或者是末尾的in就没有被匹配到。同样的,如果想要匹配在单词结果的in的话,就可以在in的后面加上一个\b:in\b,这样就只有以in结尾的部分被高亮显示了,当然如果想要匹配独立的in这个单词的话,就可以在in的前后都加上一个\b,这样就只有独立的in被匹配了,而其他中间开头或者结尾的in就都没有被匹配到\B:匹配非单词边界,比如刚才的两个小写\b都换成\B的话,那么就只有在单词中间的in被匹配到了,而开头结尾或者独立的in就都没有被匹配到
2.4 量词
- 定义说明:量词就是用来表示重复次数的
+:表示前面的字符重复了一次或者多次。比如我们想要匹配a后面有一个或者多个t的字符串,就可以在t后面加上一个加号:at+*:表示前面的字符出现了0次或者多次{}:指定重复的次数,精确的次数。比如只想匹配a后面有3个t这样的字符串的话,就可以在t后面加上一个花括号,然后在里面加上一个3就可以了:at{3}{}:还可以使用逗号分隔开的两个数字来表示一个范围。比如想要匹配3到5个t的话:at{3,5}.把后面的5省略的话:at{3,}就表示至少重复了3次以上- 贪婪模式:正则表达式默认是贪婪匹配的,也就是会匹配尽可能多的字符,直到不满足条件为止
- 非贪婪模式:有的时候并不需要匹配尽可能多的字符 ,只需要满足最小的匹配条件就可以了,这个时候就可以在量词的后面加上一个
?.比如:at{3,}?这样只要匹配到了3个t就会停止匹配,不再继续匹配下去
2.5 分组和引用
-
说明:2.1-2.4部分已经可以满足我们日常的大部分需求了,但是有的时候还是避免不了偶尔会遇到一些更复杂的情况,需要用到一些更高级的功能,比如分组和捕获。
-
分组可以将多个字符作为一个整体来处理。
举例一:
如果我们想要匹配at重复了多次,也就是多个atat连在一起这样的情况,那么直接在t后面加上星号是不行的,因为这样只能匹配到字母t重复了多次的情况,那这个时候就可以把前面的at两边加上一对小括号:
(at)*,将at作为整体来处理,后面加的这个*表示这个整体重复了多少次。同样的,如果只想匹配at重复了3次的情况:(at){3},那么就只有重复3次的情况才会被匹配到。这就是最简单的分组的用法举例二:
比如现在要匹配pattern这个单词,但是不管它的首字母p是大写还是小写,都需要匹配到,那么有一种方法就是:可以使用
[]里面同时加上大写和小写字母p,然后再加上单词剩余的部分:[Pp]attern,或者在两个单词之间加上一个竖线,也可以达到同样的效果:[Pattern|pattern] -
分组还有一个重要的作用:捕获。使用
()创建一个分组之后,我们也可以捕获匹配到这个分组的内容,在后续的处理中也可以引用或者提取这部分内容。 -
非捕获分组:
?:形式 -
引用:比如我们想要匹配一个单词,这个单词的第一个字母和最后一个字母必须是相同的,如alibaba或者tencent但是google和baidu就不满足这个条件,这个时候就可以使用分组和引用来实现。实现:
\b([a-zA-Z])([a-zA-Z]*)\1\b
2.6 前瞻和后顾
-
简介:前瞻和后顾是一种特殊的匹配方式,按照是否匹配还可以分为正向前瞻和负向前瞻以及正向后顾和负向后顾。简单来说就是它可以让我们匹配到某些字符前面(前瞻)或者后面(后顾)的内容,但是并不包括这些字符本身。
-
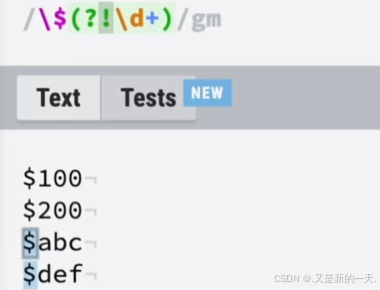
?=:正向前瞻:比如我们只想匹配数字前面的$符号,如下:可以看到现在就只有数字金额前面的符号被匹配到了,而字母变量前面的符号就没有被匹配到。

-
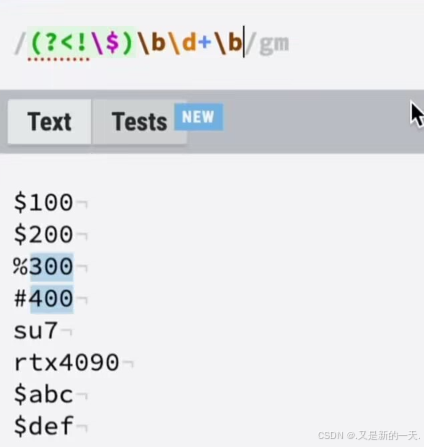
?!:负向前瞻:也就是当后面的内容不是数字金额的时候,才会匹配到前面的$符号
-
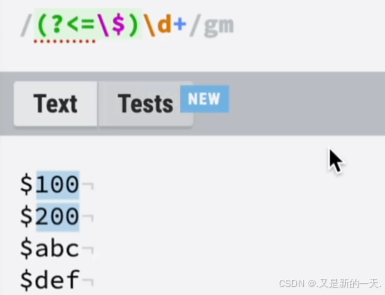
?<=:正向后顾---当前面的内容是某些字符的时候,才匹配到后面的内容--匹配后面的内容比如想匹配
$符号后面的数字金额,这时候就可以使用正向后顾来实现
-
?<!负向后顾:当前面的内容不是某些字符的时候,才匹配到后面的内容
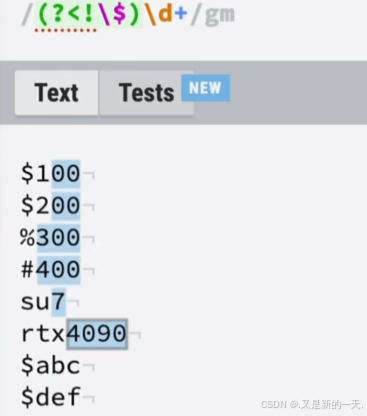
如果想要排除这两种情况的话: