📖 欢迎来到我的CSDN爬虫专栏!✨
🚀 在这里,我们将一起探索:
🔍 爬虫基础入门 → 零基础也能快速上手
🛠️ 实战案例解析 → 20+个经典网站爬取实战
⚡ 反爬应对策略 → 验证码/IP封禁/动态加载全破解
📊 数据存储方案 → MySQL/MongoDB/Excel多维度存储
🌐 框架深度应用 → Scrapy/Selenium/Playwright高阶技巧
💡 系列特色:
✅ 代码全注释 | 每行代码都有详细解释
✅ 即学即用 | 完整可运行代码+环境配置指南
✅ 持续更新 | 每周2-3篇技术干货不间断
✅ 疑难解答 | 评论区48小时内必回
🎯 适合人群:
👨💻 初入行的爬虫小白
👩🔧 遇到反爬瓶颈的进阶者
🧑🏫 需要数据采集的研究人员
🛡️ 重要声明:
📢 本专栏仅用于技术交流
⚠️ 禁止将技术用于非法用途
❤️ 倡导遵守Robots协议与相关法律法规
🎉 现在开始,让我们一起:
🔥 突破技术壁垒
🔑 掌握数据密钥
📈 实现能力跃迁
👇 快速入口:
💬 技术问题 → 评论区留言
📬 合作需求 → 私信联系
⭐ 资源下载 → 关注后获取
(本文持续更新中,建议收藏⭐+关注🔔)
⏰ 更新时间:2025年
🏷️ 标签:#爬虫 #Python #数据分析 #编程
✨ 期待与你共同成长,开启数据掘金之旅!
目录
一、题目
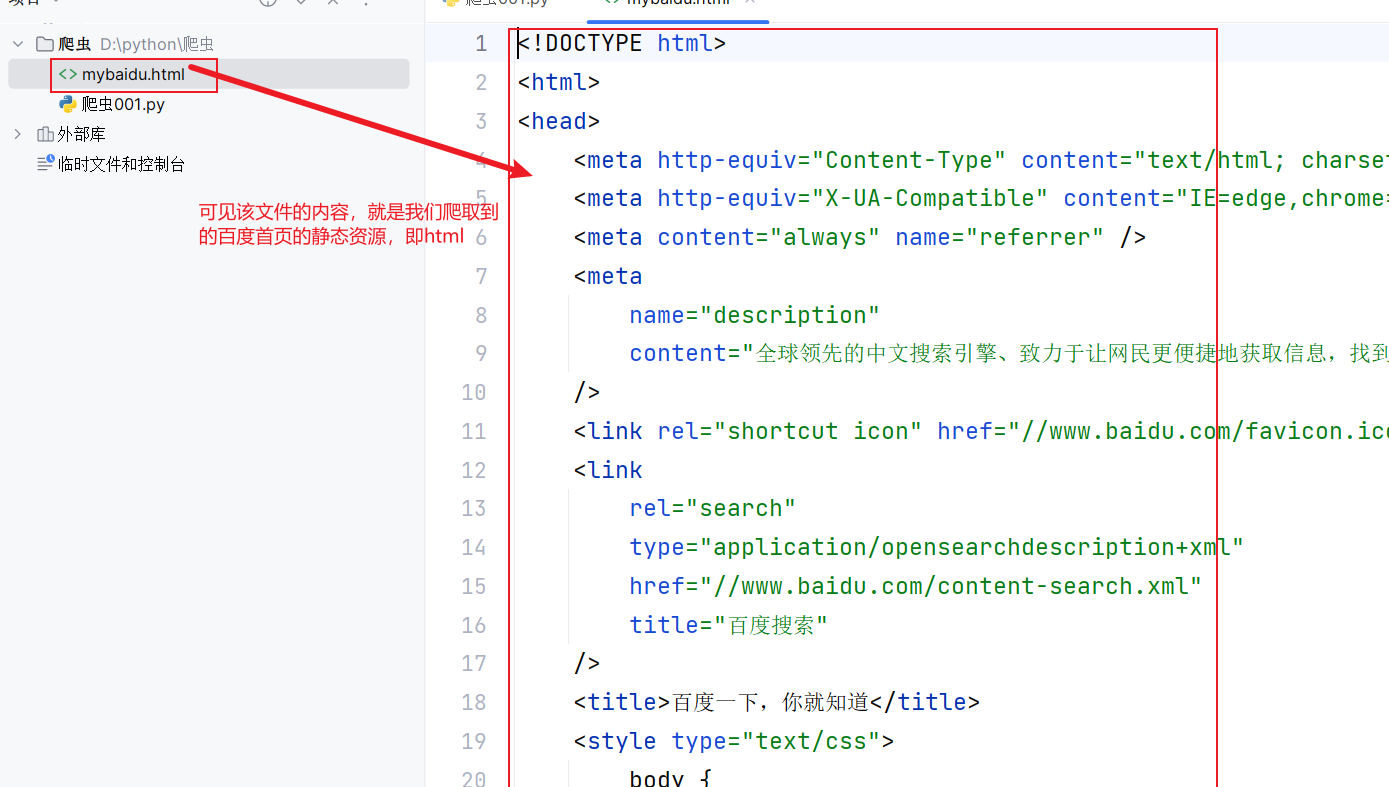
将百度首页的html,爬出来。
二、代码
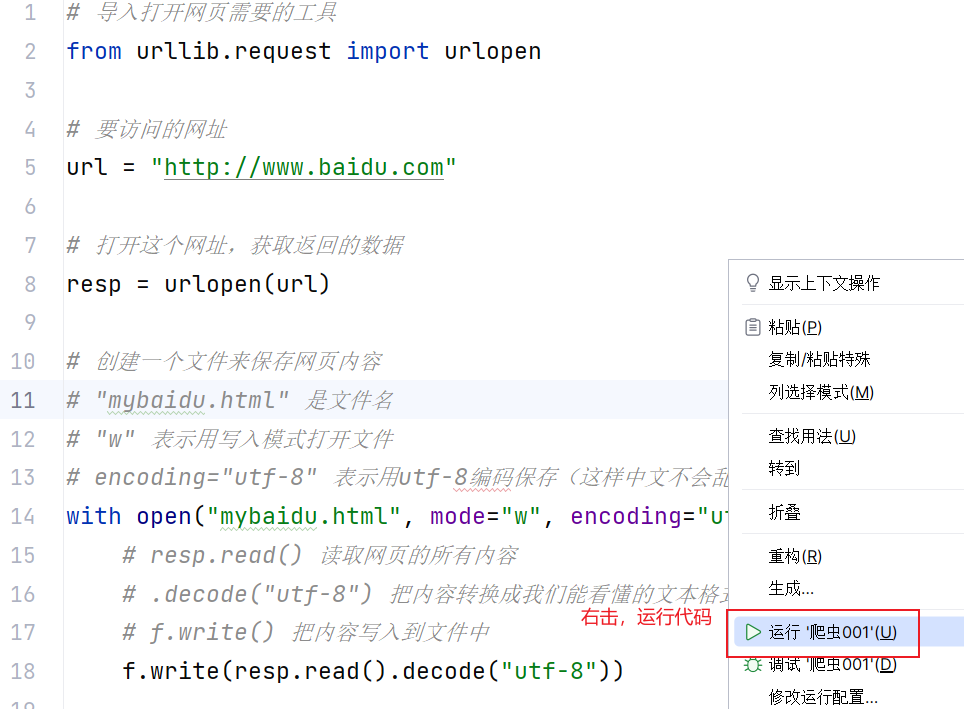
python
# 导入打开网页需要的工具
from urllib.request import urlopen
# 要访问的网址
url = "http://www.baidu.com"
# 打开这个网址,获取返回的数据
resp = urlopen(url)
# 创建一个文件来保存网页内容
# "mybaidu.html" 是文件名
# "w" 表示用写入模式打开文件
# encoding="utf-8" 表示用utf-8编码保存(这样中文不会乱码)
with open("mybaidu.html", mode="w", encoding="utf-8") as f:
# resp.read() 读取网页的所有内容
# .decode("utf-8") 把内容转换成我们能看懂的文本格式
# f.write() 把内容写入到文件中
f.write(resp.read().decode("utf-8"))
# 爬取完成,打印提示信息
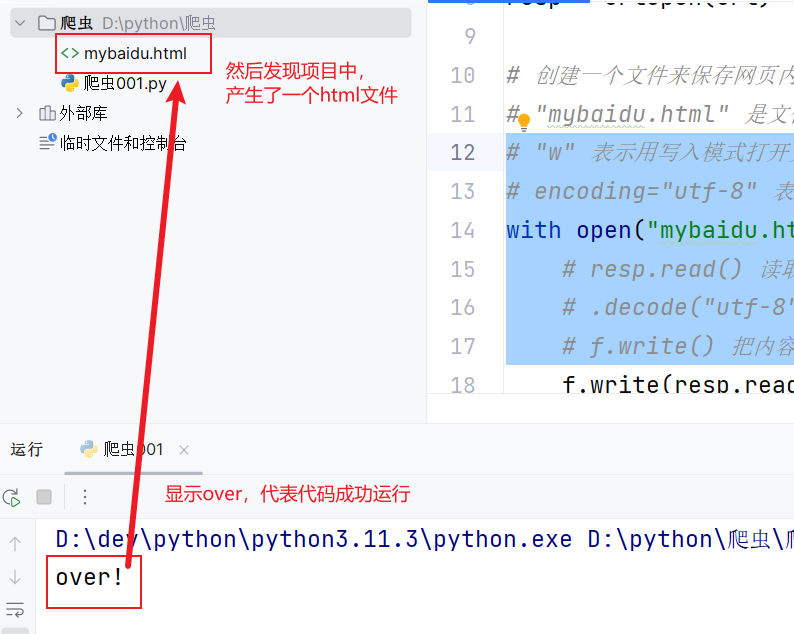
print("over!")三、效果展示

以上就是本篇文章的全部内容,喜欢的话可以留个免费的关注呦~~~