随着大模型的普及,AI也渐渐走进人们的日常生活中。相信朋友们都有使用AI解决问题的经历,但是你是否也遇到过这种情况:同样是用ChatGPT,有人能让它像专业顾问一样输出清晰报告,而你却只能得到一堆模糊的回答?很多人第一次用ChatGPT都以为它全能,但当你真正想让它帮你写方案、分析数据时,结果往往不尽如人意。实际上,差距往往不在AI本身,而在你给出的"提示词"。这正是提示词工程要解决的核心问题------如何把模糊的想法,翻译成AI能真正理解并执行的指令。
上篇文章中,我们引出并介绍了AI Agent的概念,理论上,AI Agent可以"自主决策,执行任务"。但在实践中,很多Agent会显现出一种现象--聪明但不听话。在复杂的workflow中,不是理解错目标,就是执行错方向。其根本原因之一,就是Agent的背后的模型需要**"提示词"** 来理解任务。如果提示词设计得不好,智能体的能力就会被严重限制。实际上,提示词工程 ,RAG (检索增强生成),FT(模型微调)是三种非常关键的模型优化手段,各自具备不同的特点,但提示词工程无需在模型参数层面进行调整,成本最低也相对简单。
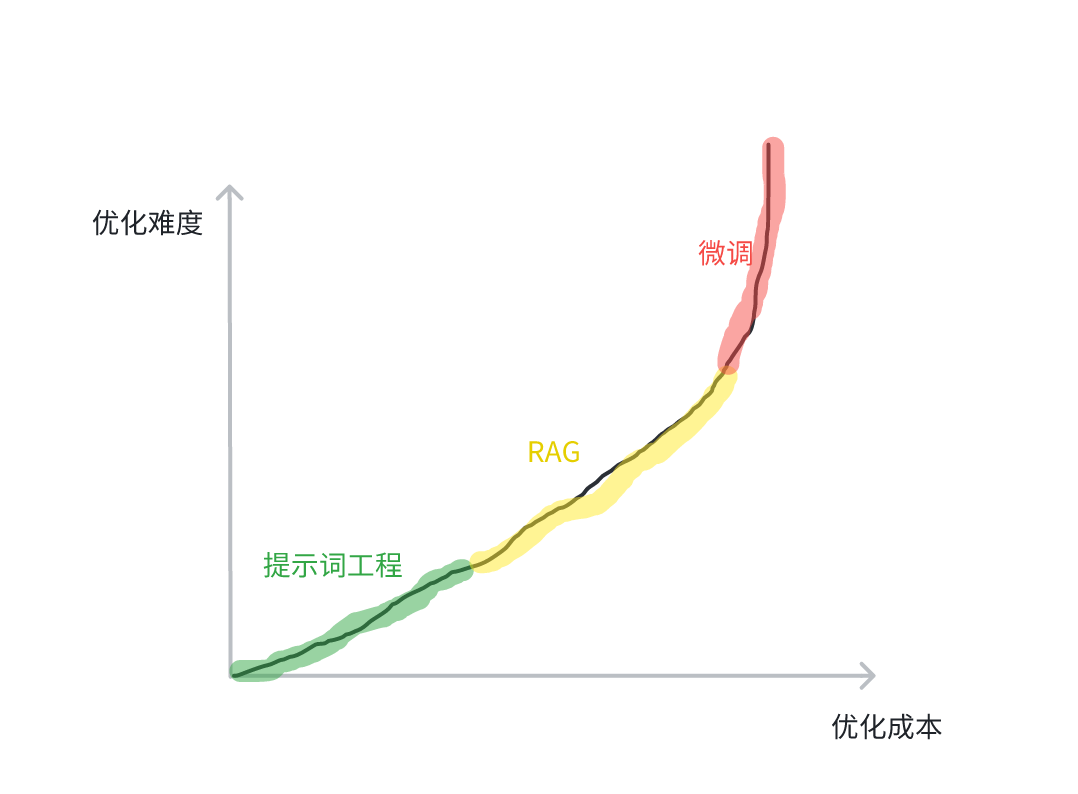
通过这些现象,相信朋友们也能够意识到合理设计提示词的关键性了。提示词是工具,而提示词工程则是一种合理利用工具的方法论。那么今天我们就来了解一下提示词工程的相关知识~
一.与AI沟通的艺术--提示词工程
提示词(Prompt)的概念很简单,就是用户在使用大模型时向其提供的输入,引导模型生成特定格式或特定类型的输出。提示词的形式是多样的,可能是一个问题,若干关键词,还有可能是上下文信息。提示词本质上仍属于自然语言(NL)的范畴。
在实践中,精良的提示词一般包含以下要素。实际上,并不是所有设计精良的提示词都必须具备下面的要素,我们应依照具体问题具体分析,不过下面这些要素是我们进行提示词优化需要考虑的Point.我们以"假如你(大模型)是一个系统架构师,给你(大模型)一篇后端技术文档(Word),帮我概括出里面技术选型的要点,并总结成表格"的示例向大家进行介绍。
·指示与案例:用户让大模型做的事情,以及一些案例提示(让模型学习),在示例中是"帮我概括出里面技术选型的要点"。
·上下文:主要是外部信息和背景,在示例中是"假如你是一个系统架构师"。
·输入数据:用户向大模型提供的输入,在示例中是"后端技术文档"。
·输出提示(规范):用户提出的对模型输出的期望或规范,在示例中是"总结成表格"。
这四个要素就是提示词的组成维度, 属于结构层 的概念。这四个维度决定了AI要做什么,基于什么,输入是什么,输出长什么样。常见的提示词工程分为直接提示,链式提示,生成类提示,图谱提示,集成式提示。接下来我将分别对这五类提示词工程进行介绍:
第一种方式是直接提示 --最基础且直观的方式。给模型一句明确、简洁的任务指令,不拆解任务一步到位。所以我们需要明确指令 ,输入 与输出格式 ,而且给出必要的上下文。这种方式适合任务结构简单、目标明确、逻辑路径不复杂的场景。
其次是链式提示 ,本质上是对任务进行了拆解,可以看作"多轮提示+中间加工 "。其关注LLM内部逻辑,比如说思维链,多模态思维链,思维树等。并会始终关注过程中的逻辑自洽,并进行反思(reflexion)。关键就在于**将任务合理拆解为多个可执行的子任务,**每一步提示明确其输入是什么、期望输出是什么,且输出要可作为下一步的输入。这种方式适合任务较为复杂、需要中间结果校验或多步逻辑的情况。
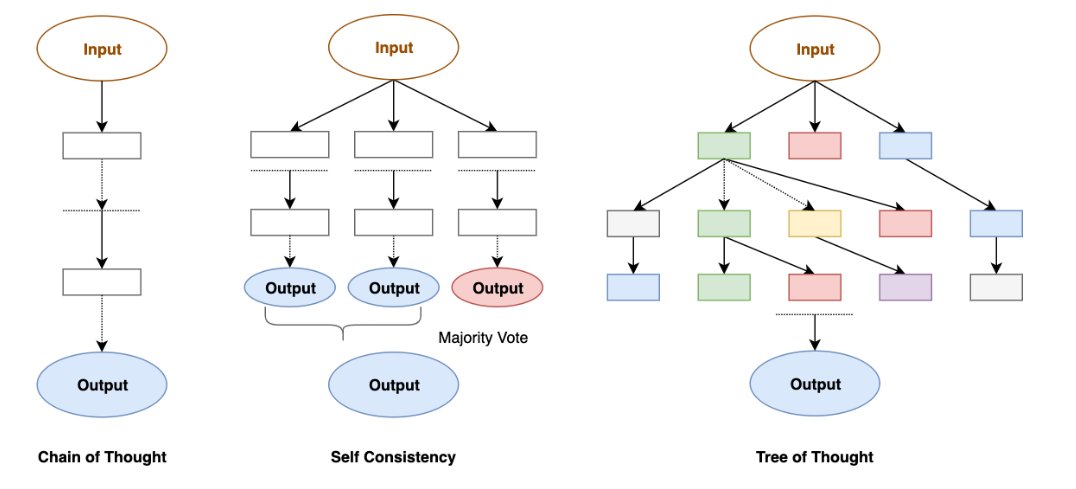
在直接提示中,我们给模型的指令一般是让模型完成一个十分具体的任务,如果约束十分严格,模型并没有太多自由发挥的空间。在生成类提示 中,任务更多的是"让模型自由生成 "或者"让模型帮我们生成结构/内容/知识",而不仅仅是简单完成一个指令。其任务边界较宽,适合创造性的任务。
接下来是图谱提示 。其和链式提示方式非常相似,也非常关注LLM的内部逻辑。其在提示词设计中引入"知识图谱 "或"关系网络 "结构,使模型基于结构化知识或图谱关系进行推理或生成为主。知识图谱( KG)是一种用"节点 + 关系"来表达世界知识的结构化表示方式,常见形式是个三元组,比如说**(马斯克,创立,特斯拉)**。这样机器就能以"图"的形式来理解世界,而不只是文字。这种提示方法的关键就是明确知识图谱的结构,节点之间的关系。这种方式适合需要结构化知识、复杂推理、关系分析的场景。
最后一种提示方式是集成式提示 。其核心特征是让多个提示协同工作,而不是单一提示一次性完成任务。一种方式是让LLM与通过外部资源进行交互,解决较为复杂的问题,比如通过RAG,Function Calling等。还有一种是组合前面我们提到的几种提示方式,从而得到更稳健、更高质量的输出。
实际上,我曾经陷入过一个误区,粗浅地认为提示词工程只停留在用户层面,由用户来根据自己的需求不断地组织语言供大模型理解,不关开发者的事。但实际上在AI Agent开发中,这样的想法就大错特错了。在AI Agent开发中,模型的"人格"和"行为"是不稳定的,就像一个没有固定工作职责的闲散人员。而用户的输入往往是动态并与任务强相关的,这样可能会导致模型的输出逻辑,风格,语气都不相同。而且假如给模型输入一些不法操作,假如模型在系统层面没有约束而去真的照做,那安全隐患不言而喻。在实际AI Agent开发中,提示词不仅由结构决定,还需考虑其在系统中的"角色"。于是我们引入用户提示词 和系统提示词 的概念,属于角色层 的概念。系统提示词一般由Agent应用开发工程师编写,在系统层面进行约束,告诉大模型"你是一个什么样的人";而用户提示词旨在告诉模型"你需要做的事情"。假如没有系统提示词,那么AI Agent就像一个不熟悉业务的实习生,确实能够完成简单的工作,但是无法保证稳定和安全。实际上,用户提示词和系统提示词在功能上是等价的 。系统提示词存在的意义并不是"提供额外能力",而是解耦上下文职责。从另一层面来讲,系统提示词的存在也加强了AI应用的易用性,降低了用户提示词的编写难度,提升了用户的使用体验。
在工程实践中,如LangChain,Eino等框架提供了提示词模板 。提示词模板并非模型的原生特性,而是由框架提供的。其规范提示结构,支持变量替换将用户提示词与系统提示词进行整合 ,抽象出提示工程逻辑方便复用。让提示词工程真正进入模块化,可维护的阶段。提示词模板功能由其 Prompt 组件(位于 eino/components/prompt 包)提供,核心接口是**ChatTemplate** 。这个接口定义了一个 Format(ctx context.Context, vs map[string]any, opts ...Option) ([]*schema.Message, error) 方法,用于将变量注入模板、构造最终的消息列表 。Eino 内置三种模板格式内置三种模板化方式:FString (python的字符串格式化方式),GoTemplate (go语言的模板方式),Jinja2(适用于更复杂的场景)。这里我给出一个小demo朋友们可以进行参考。
Go
template := prompt.FromMessages(
schema.FString,
schema.SystemMessage("你是一个{role},你的任务是{task},请参考之前对话历史回答问题"),
schema.MessagesPlaceholder("history", false),
schema.UserMessage("{question}"),
)相信通过上面的介绍,朋友们对提示词工程在结构层和角色层上建立了基本的认知。那么接下来的话题可能是非技术类同学们比较感兴趣的,那就是优化提示词的策略 。首先是零/一/少样本提示(Zero-/One-/Few-Shot) ,这实际上是一种"样本驱动 "的策略,在提示里放入 0、1 或若干对「输入→输出」示例,帮助模型学会我们需要的任务模式。当任务规则不复杂但需要模型模仿特定格式或风格时,使用这种策略是很合适的。第二种策略是思维链(COT), 让模型在给出结论前显式写出中间推理步骤(思考过程)。一般我们需要在系统提示词或示例中给出**"演示性"CoT** (few-shot CoT),示范如何拆步,对复杂任务,限制单步长度避免"跳跃式"推理。第三种方式是自一致(self-consistency) ,不是让模型只输出一次,而是多次独立生成思维链/结论,然后对所有候选取"众数"或通过投票/打分选出最稳健答案 。在多次采样时用temperature 或 top-k 控制生成多样性,当任务具有多种解法或模型单次输出不稳定(例如复杂推理、开放式问答)时适合采用这个策略。最后一种方式是反思提示(Reflexion),由模型先生成初稿,然后对初稿进行审查、修正或补充,尤其在追求严谨性输出的场景下非常适用。
2024年后,OpenAI-o1的诞生,宣告了在传统大语言模型的基础上,衍生出推理模型 。其在生成内容之前,先会在内部形成思维链(COT) ,进行显式或隐式的推理,然后根据推理内容进行回答。其重点并非"语言生成",而是"逻辑推演 + 结构化思考 "。推理模型的兴起,也对提示词工程有潜移默化的影响,提示词工程的重点逐渐从**"教它怎么回答"** ,到让模型**"知道要推理什么"** 。推理模型能主动规划步骤,但如果提示词没有明确边界,它可能"过度推理"或走偏。所以提示词工程需要指定思维边界,提供结构模板 。推理模型需要记住之前的推理链、理解问题的语境、动态整合外部知识,也就是说其强依赖上下文,那我们该如何管理和优化这些上下文呢?于是一个新的工程概念被引出了--上下文工程(Context Engineering)!
二.与AI共创的环境设计--上下文工程
在早期的对话系统中,我们总是强调"如何写好提示词"。指令要明确、角色要清晰、输入要完整等,这些方面的要点我们在前文已经介绍过了。但当我们进入推理模型时代,一个新的问题出现了:模型的表现不再仅仅取决于单条提示,而取决于它所拥有的上下文 。换句话说,AI 不只是根据一句话回答问题,而是根据"它眼中看到的世界"来思考。而这个"世界"------正是由上下文工程 设计出来的。提示词教会模型"该如何思考",而上下文工程则让它"有条件地思考"。 提示词工程解决的是语言如何表达意图 的问题,而上下文工程解决的是知识如何被组织与理解 的问题。上下文工程,简单来说,就是如何让模型在合适的语境中工作。它关注的不只是提示词,而是整个输入环境的构建与管理。Andrej Karpathy认为LLM就像一个新型操作系统,LLM如同CPU,其上下文窗口如同RAM,作为模型的工作内存。正如操作系统管理RAM一样,我们可以将"上下文工程"视为扮演类似的角色。
在一次 AI 交互中,"上下文"可能包括:用户的历史对话与意图,当前任务目标与约束,外部知识库或工具信息,系统角色设定与推理历史等。上下文决定了模型能"看到什么";提示词决定了模型"要做什么"。因此,上下文工程是提示词工程的延伸与升维------从单点指令,走向语境编排。
首先,对于上下文管理而言,输入的内容是一门大学问。模型需要的信息越准确、越相关,它的输出就越可靠。这就要求我们对上下文进行筛选与压缩 ,例如利用向量检索(embedding) 找到最相关的知识片段,或者在多轮对话中保留关键事实、丢弃无关细节。其次,随着推理模型具备多轮思考与反思能力,上下文不再是静态的。它像记忆一样,需要被动态更新。上下文工程的任务之一,就是设计模型的"记忆策略":哪些内容要被长期保留?哪些只在当前任务有效?这又会涉及到 memory、state management、甚至外部数据库(如向量存储)的使用。
上下文工程作为一个新兴的工程概念,同样也存在很多挑战。首先是上下文的窗口限制 :
即使模型支持 128K tokens,也无法无限制地加载信息。如何取舍、抽象和压缩,是核心问题。其次是语义一致性 :不同来源的上下文信息往往存在冲突。模型需要一种"语境优先级"来判断谁更可信。最后是动态管理:随着推理任务进展,上下文应能实时更新------这正是 Agent 框架中"Memory 模块"的核心功能。
结语
无论是提示词工程 还是上下文工程 ,它们的核心目标都是让人工智能"更好地理解人类的意图"。前者教会模型如何被指令驱动 ,后者让模型在合适的语境中思考。提示词是显性的沟通方式,而上下文是隐性的语义土壤------两者相辅相成,缺一不可。随着推理模型、智能体(AI Agent)和多模态系统的发展,提示词工程正在从"编写指令的技巧"转向"语境设计的系统工程"。未来,我们作为 AI 应用开发者,不仅需要会写出精准的 Prompt,更需要有构建出丰富、有层次的 Context的能力,让模型思考的不只是词句,而是世界本身。有不当之处还请多多批评指正,我们一起成长!