文章目录
- [一 连续状态空间下的强化学习](#一 连续状态空间下的强化学习)
- [二 深度强化学习:神经网络与Q-Learning的结合](#二 深度强化学习:神经网络与Q-Learning的结合)
-
- [2.1 案例研究:月球登陆器 (Lunar Lander)](#2.1 案例研究:月球登陆器 (Lunar Lander))
- [2.2 使用神经网络近似Q函数 (DQN)](#2.2 使用神经网络近似Q函数 (DQN))
- [2.3 学习过程:将强化学习问题转化为监督学习](#2.3 学习过程:将强化学习问题转化为监督学习)
- [2.4 学习算法:经验回放 (Experience Replay)](#2.4 学习算法:经验回放 (Experience Replay))
- [2.5 改进的神经网络架构与实现](#2.5 改进的神经网络架构与实现)
- [2.6 核心挑战:探索与利用的平衡](#2.6 核心挑战:探索与利用的平衡)
- [2.7 训练细节:Mini-batch 梯度下降](#2.7 训练细节:Mini-batch 梯度下降)
- [2.8 训练细节:软更新 (Soft Update)](#2.8 训练细节:软更新 (Soft Update))
- [2.9 强化学习的局限性](#2.9 强化学习的局限性)
视频链接
吴恩达机器学习p137-144
一 连续状态空间下的强化学习
在上一篇文章中,我们使用火星车的例子介绍了强化学习。在该示例中,环境的状态空间(State Space)是离散的(Discrete) ,即智能体只能处于有限的、可数的几个状态之一(例如6个位置)。然而,现实世界中绝大多数有意义的强化学习问题,其状态空间都是连续的(Continuous)。

-
离散状态 (Discrete State):状态的数量是有限且可数的。例如火星车的6个位置,我们可以用一个简单的表格来存储每个状态的信息。
-
连续状态 (Continuous State) :状态由一组可以取任意实数值的变量来描述,因此理论上存在无限多个可能的状态。例如,要精确描述一辆卡车的状态
s,我们需要一个状态向量,其中可能包含:x,y: 卡车在二维平面上的坐标。θ: 卡车的朝向角度。ẋ,ẏ: 卡车在x和y方向上的速度。θ̇: 卡车的角速度(角度的变化率)。
由于这些量都是实数,因此状态s可以在一个高维的连续空间中取任何值。

- 自动驾驶直升机案例 :这是一个典型的、高维度的连续状态空间问题。要完全描述直升机的飞行状态
s,需要一个包含12个或更多维度变量的向量,例如三维空间坐标(x, y, z)、三个姿态角(滚转φ、俯仰θ、偏航ω)以及这六个量各自的时间导数(即线速度和角速度)。
在状态空间是连续的或者维度非常高的情况下,我们之前为每个状态都存储一个Q值的表格方法(Tabular Q-learning)变得完全不可行。我们不可能创建一个包含无限多行的表格。因此,我们需要一个能够处理连续输入并能对未见过的状态进行泛化的函数近似器。这自然而然地将我们引向了神经网络。
二 深度强化学习:神经网络与Q-Learning的结合
当我们将深度学习(特别是神经网络)作为函数近似器,与强化学习的框架结合起来,以解决具有复杂、高维或连续状态空间的问题时,这个强大的领域就被称为深度强化学习(Deep Reinforcement Learning)。
2.1 案例研究:月球登陆器 (Lunar Lander)
我们将通过一个经典且直观的RL问题------月球登陆器(Lunar Lander)------来详细讲解深度Q学习(Deep Q-Learning, DQN)的完整原理和实现细节。
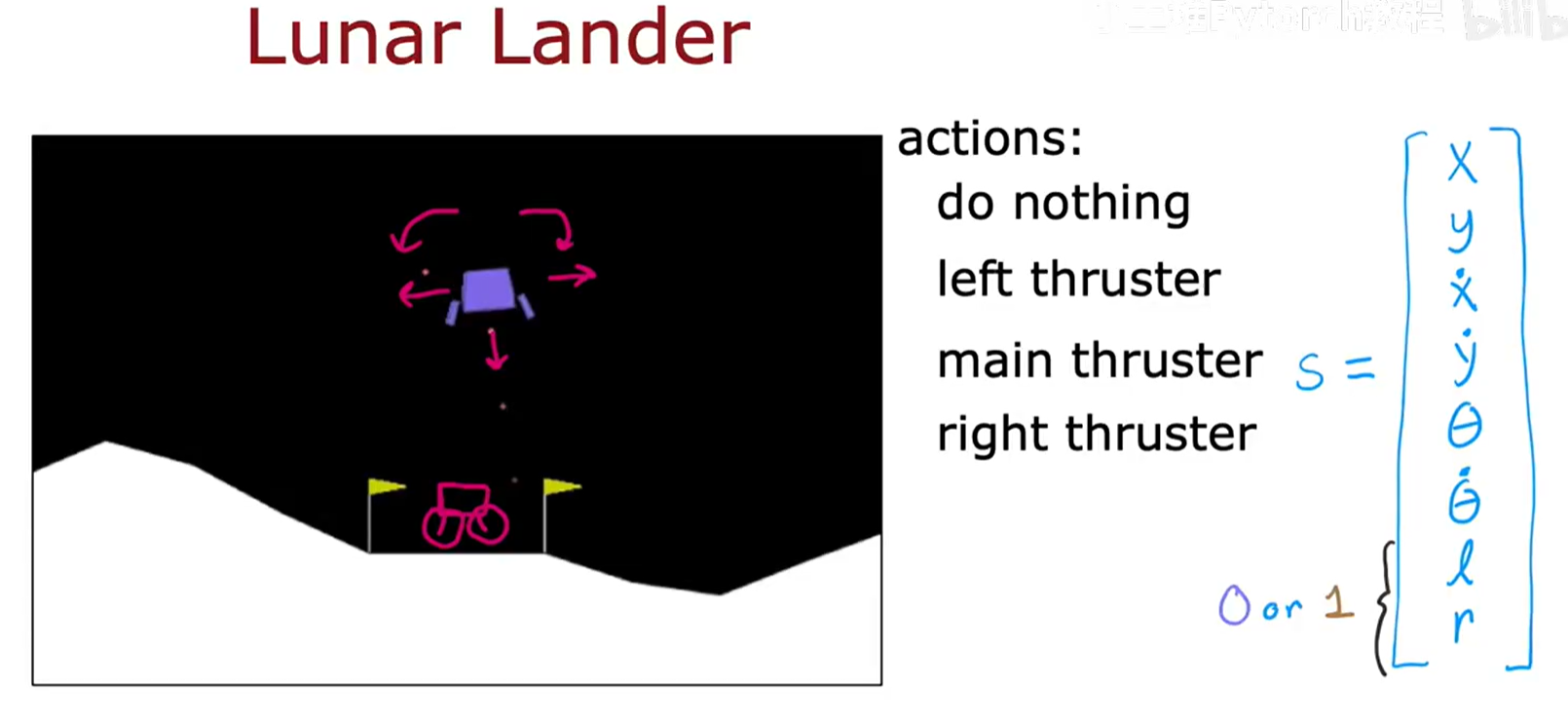
环境定义 (Environment Definition):
- 目标:操控一个登陆器,使其安全、平稳地降落在两面黄色旗帜之间的着陆平台上。
- 状态
s: 登陆器的状态由一个8维的连续向量精确描述,包括:(x, y): 登陆器质心的二维坐标。(ẋ, ẏ): 登陆器质心的二维速度。θ: 登陆器的角度(姿态)。θ̇: 登陆器的角速度。l,r: 两个布尔值(0或1),分别表示左腿或右腿是否与地面接触。
- 行动
a: 智能体有4个离散的行动可以选择:- 什么都不做 (do nothing / coast)
- 启动左侧的侧向推进器 (fire left thruster)
- 启动主推进器 (fire main thruster)
- 启动右侧的侧向推进器 (fire right thruster)
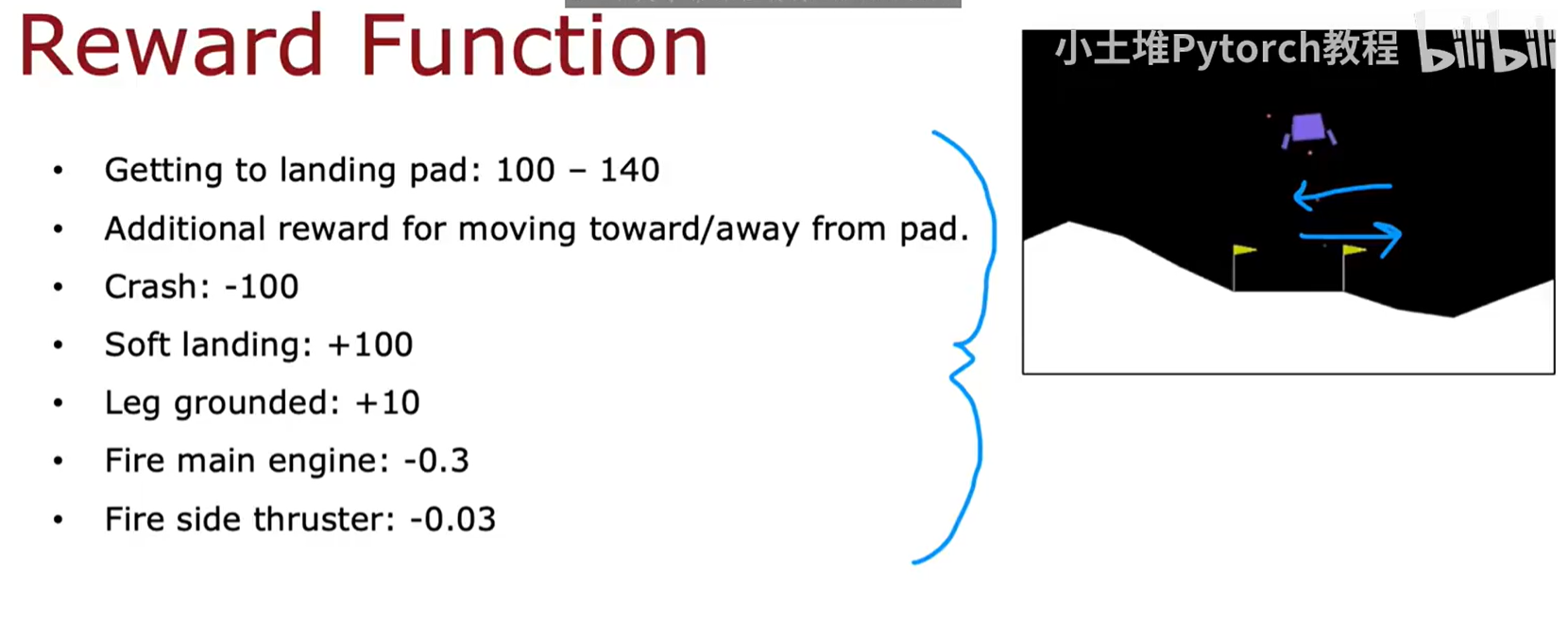
奖励函数 (Reward Function) :
奖励函数的设计是强化学习应用工程中的关键。它通过数值信号来引导智能体学习期望的行为。对于月球登陆器,一个精心设计的奖励函数如下:
- 主要目标奖励与惩罚 :
- 成功降落 : 成功到达着陆平台会获得
+100到+140分的大量奖励。奖励的多少取决于降落的速度和平稳性。 - 坠毁 : 如果登陆器坠毁,会受到
-100分的重罚。 - 平稳软着陆 : 如果登陆器最终静止在平台上,会额外获得
+100分。
- 成功降落 : 成功到达着陆平台会获得
- 过程引导与燃料消耗惩罚 :
- 接近奖励: 向着陆平台移动会持续获得小的正奖励,而远离则会受到小的负奖励。这提供了一个密集信号,引导智能体朝正确方向飞行。
- 触地奖励 : 每条腿接触地面,奖励
+10分。 - 燃料惩罚 : 为了鼓励智能体节省燃料,每次使用推进器都会受到惩罚。使用主推进器惩罚
-0.3分,使用侧推进器惩罚-0.03分。
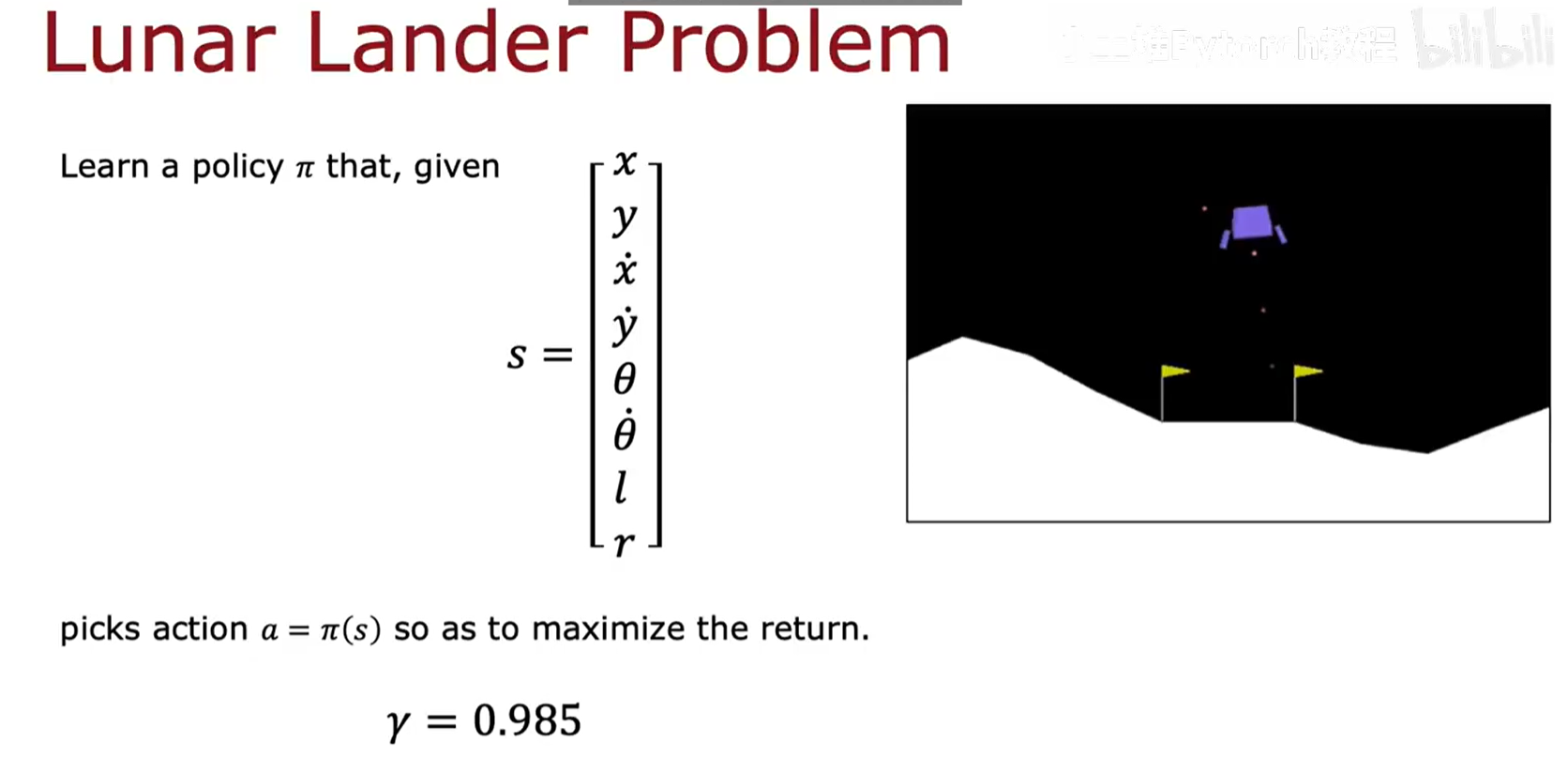
学习目标 (Learning Goal) :
我们的最终目标是学习一个策略 π。这个策略接收当前8维的状态向量s作为输入,然后输出一个最合适的行动a = π(s)。选择这个行动的依据是,它能够最大化未来的累积折扣回报(Return) 。在这个问题中,折扣因子 γ 被设定为一个较高的值,如 0.985。这表明智能体需要具备"远见",它必须权衡短期内的燃料消耗和姿态调整,以实现最终安全着陆的长期目标。
2.2 使用神经网络近似Q函数 (DQN)
由于状态 s 是连续的,我们训练一个神经网络 来近似 Q(s, a) 函数。这个网络被称为DQN(Deep Q-Network)。
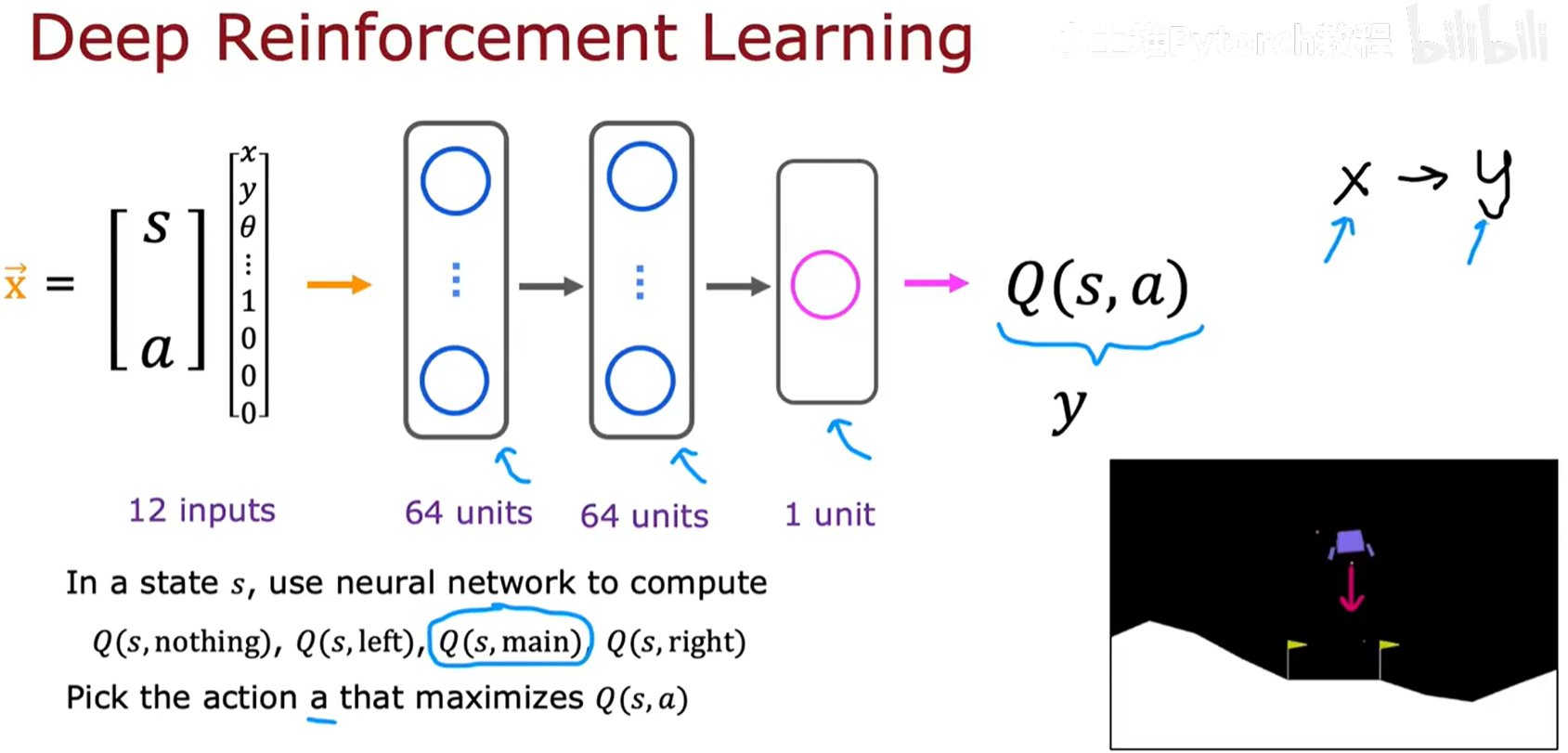
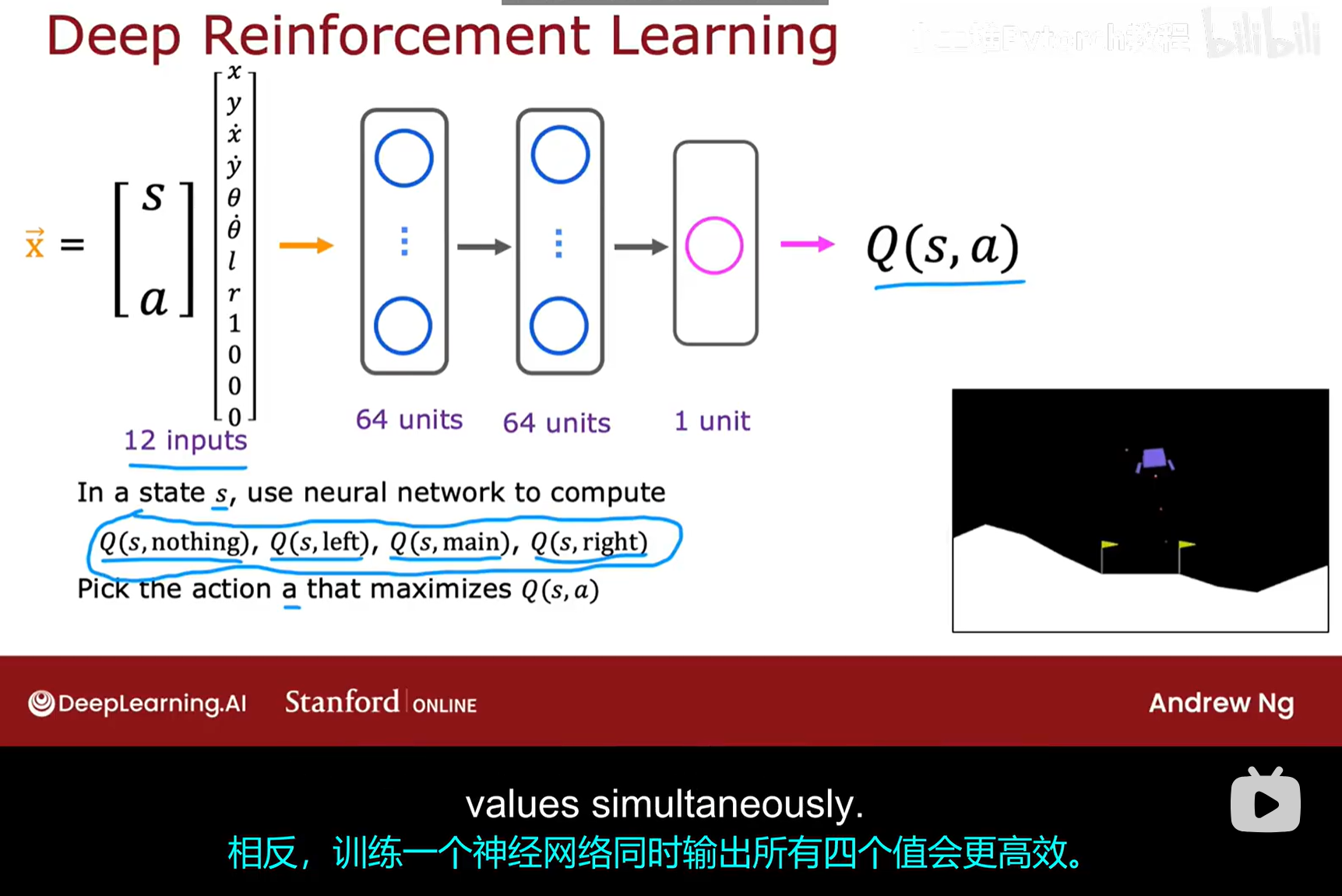
方法一:将 (状态, 行动) 作为输入
- 网络输入
x:将状态s和行动a拼接(concatenate 成一个大的向量,作为神经网络的单一输入。- 状态
s是一个8维的连续向量。 - 行动
a是一个离散的量(4种可能),我们可以使用**独热编码(one-hot encoding)**将其转换为一个4维的二元向量。例如,[0, 1, 0, 0]代表"启动左侧推进器"。 - 拼接后,输入向量
x的总维度为8 + 4 = 12维。
- 状态
- 网络结构:一个典型的结构可以是:输入层(12) -> 隐藏层(64) -> 隐藏层(64) -> 输出层(1)。
- 网络输出
y:网络只有一个输出单元,其输出的单个数值就是对Q(s, a)的近似值。 - 决策过程的缺陷 :
- 在某个给定的状态
s,为了决定采取哪个行动,我们需要分别计算所有可能行动的Q值:Q(s, nothing),Q(s, left),Q(s, main),Q(s, right)。 - 这意味着,我们需要构建四个 不同的输入向量,并将它们分别送入神经网络进行四次独立的前向传播计算。
- 最后,比较这四个输出的Q值,选择最大的那个所对应的行动
a。
这个过程在计算上是相当低效的。
- 在某个给定的状态
2.3 学习过程:将强化学习问题转化为监督学习
Q-Learning的本质是让我们的Q函数估计值 Q(s, a) 不断地去逼近贝尔曼方程所定义的目标值。这个过程可以被巧妙地重新构建为一个监督学习问题。

回顾贝尔曼方程 : Q(s, a) = R(s') + γ * max_a' Q(s', a')
构建监督学习训练集:
-
收集数据 :首先,让智能体与环境(月球登陆器)进行交互,收集大量的经验元组(experience tuples)
(s, a, R(s'), s')。这个元组记录了一次完整的状态转移:在状态s,采取行动a,得到了奖励R(s'),并最终转移到了新状态s'。 -
构建训练样本
(x, y):- 输入
x:x = (s, a),即我们在经验元组中记录的状态-行动对。 - 目标输出
y(Target Value) :y = R(s') + γ * max_a' Q(s', a')- 这个
y值是根据贝尔曼方程计算出的"目标Q值",我们希望我们的网络对输入x的预测能够逼近这个y。 R(s')和s'这两个值直接从我们收集的经验元组中获得。max_a' Q(s', a')这一项,需要用我们当前 的神经网络,来计算新状态s'下所有可能行动a'的Q值,然后取其中的最大值。
- 这个
- 输入
-
训练网络 :我们现在有了一批
(x, y)训练样本。我们的目标就是训练神经网络f_w,B(x),使其输出尽可能地接近目标y。这变成了一个标准的监督学习回归问题,我们可以使用均方误差(Mean Squared Error 作为损失函数,并通过梯度下降来更新网络的权重w和偏置B。
2.4 学习算法:经验回放 (Experience Replay)

综合起来,一个带有经验回放机制的完整深度Q学习算法流程如下:
- 初始化 :随机初始化一个神经网络
Q,作为我们对Q(s, a)的初始猜测。 - 初始化经验回放缓冲区 (Replay Buffer):创建一个固定大小的内存区域(例如,能存储最近的10,000个经验元组)。
- 主循环 (Repeat) :
a. 与环境交互 : 智能体根据某种策略(后面会讲)在月球登陆器环境中选择并执行一个行动a,从环境中获得一个经验元组(s, a, R(s'), s')。
b. 存储经验 : 将这个新的经验元组存入Replay Buffer 。如果缓冲区满了,就遵循"先进先出"的原则,覆盖掉最旧的那个经验。
c. 训练神经网络 :
i. 从Replay Buffer中随机采样 一个小批量(mini-batch 的经验元组(例如1000个)。
ii. 对于这个mini-batch中的每一个元组,使用贝尔曼方程构建其对应的训练样本(x, y)。
iii. 使用这个包含1000个样本的mini-batch,通过梯度下降更新神经网络的参数,使其预测值Q_new(s, a)逼近目标y。
d. 更新Q网络 : 将训练好的新网络Q_new的参数,更新到主Q网络Q中(具体更新方式稍后讨论)。
经验回放的关键作用:
- 打破数据相关性:智能体连续收集的经验是高度相关的(例如,连续几帧的画面非常相似),直接用这些按顺序排列的数据进行训练会导致网络不稳定且难以收敛。从缓冲区中随机采样,可以彻底打乱数据的时间顺序,使得训练样本更接近于独立同分布,这对于基于梯度下降的优化至关重要。
- 提高数据利用率:每一个宝贵的经验元组都可能被多次采样和用于训练,而不是用一次就丢弃,这极大地提高了数据的使用效率,尤其是在与环境交互成本较高时。
2.5 改进的神经网络架构与实现
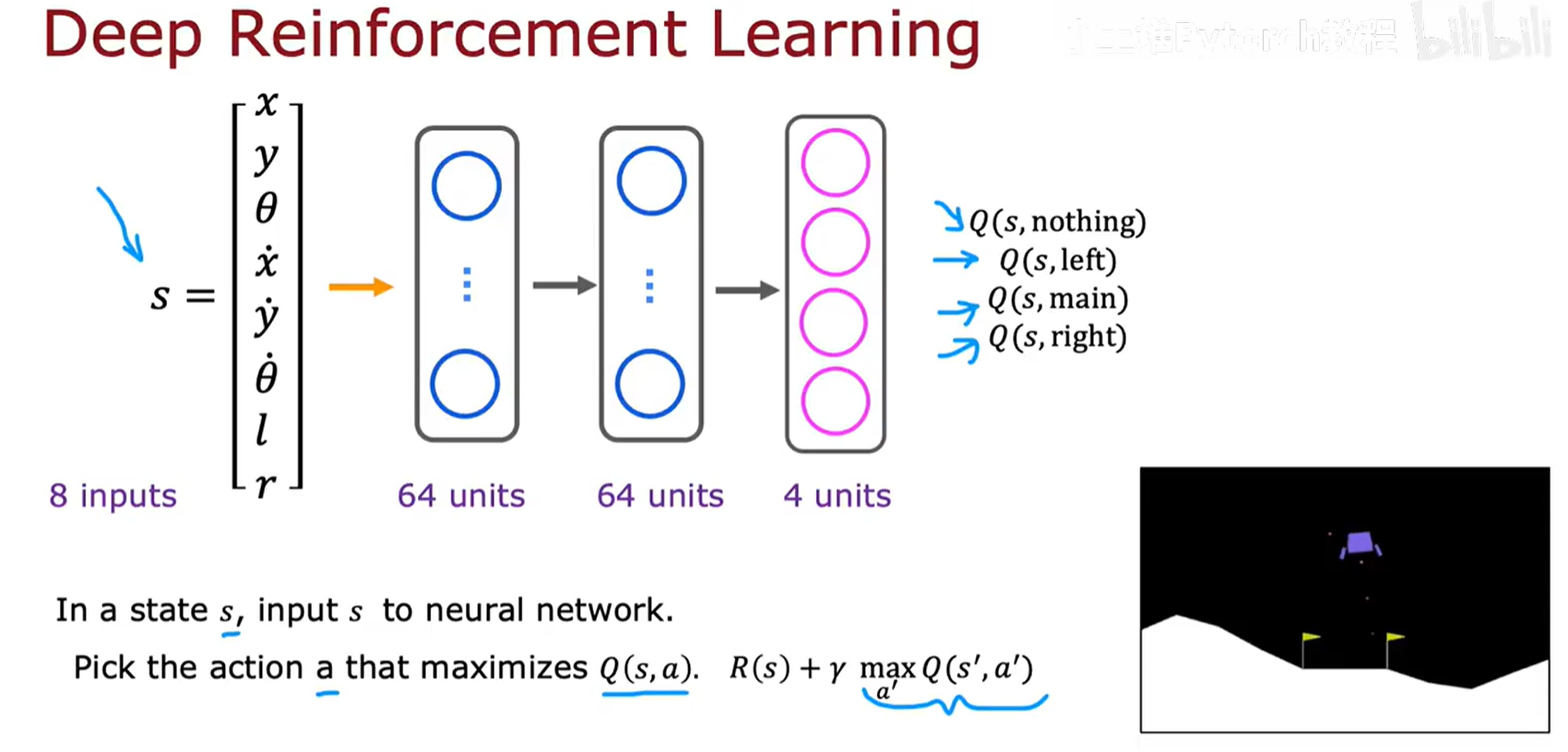
前面那种需要为每个行动都进行一次前向传播的网络结构,效率太低。一个更高效、更常用的架构是:
- 网络输入
x:只输入状态s(一个8维向量)。 - 网络输出
y:网络的输出层有4个 神经元,分别对应4个可能的行动。这4个神经元的输出值,直接、并行地给出了Q(s, nothing),Q(s, left),Q(s, main),Q(s, right)的估计值。 - 巨大优势 :这种架构只需要一次 前向传播,就可以同时计算出当前状态下所有行动的Q值,极大地提高了决策和训练的效率。在决策时,我们只需对这4个输出值取
argmax即可找到最优行动。
2.6 核心挑战:探索与利用的平衡


在算法的第3.a步,智能体需要"采取行动"。但此时我们的Q网络还在学习中,其对Q值的估计可能非常不准确。那么,应该如何选择行动呢?这里存在一个经典的困境:
- 利用 (Exploitation) :完全相信当前的Q网络,选择那个它认为能最大化
Q(s, a)的行动。这样做的好处是能立即获得当前看来最高的回报,但如果Q网络的认知是错误的,智能体可能会陷入一个局部最优解,永远发现不了真正更好的策略。 - 探索 (Exploration):不理会当前的Q网络,完全随机地选择一个行动。这样做的好处是有机会发现新的、更好的状态-行动路径,从而修正Q网络的错误认知,但代价是可能会执行一些明显很差的行动,导致短期回报降低。
ε-贪心策略 (Epsilon-Greedy Policy) 是一种在"探索"与"利用"之间进行权衡的经典实用方法:
- 设定一个小的概率
ε(epsilon),例如ε=0.05。 - 行动选择规则 :
- 以
1 - ε的概率(例如95%),选择利用(Greedy) ,即执行当前Q网络认为最优的行动a = argmax_a' Q(s, a')。 - 以
ε的概率(例如5%),选择探索(Exploration),即在所有可能的行动中完全随机地选择一个。
- 以
- 策略退火(Annealing) :一个更优化的策略是让
ε的值随着训练的进行而衰减。在训练初期,当Q网络还很"无知"时,设定一个较高的ε值(例如1.0,即完全随机探索),以鼓励智能体广泛地探索环境。随着训练的进行,Q网络变得越来越可靠,我们就可以逐渐减小ε值(例如线性地衰减到0.01),使得智能体从初期的广泛探索,平滑地过渡到后期的稳定利用,最终收敛到最优策略。
2.7 训练细节:Mini-batch 梯度下降

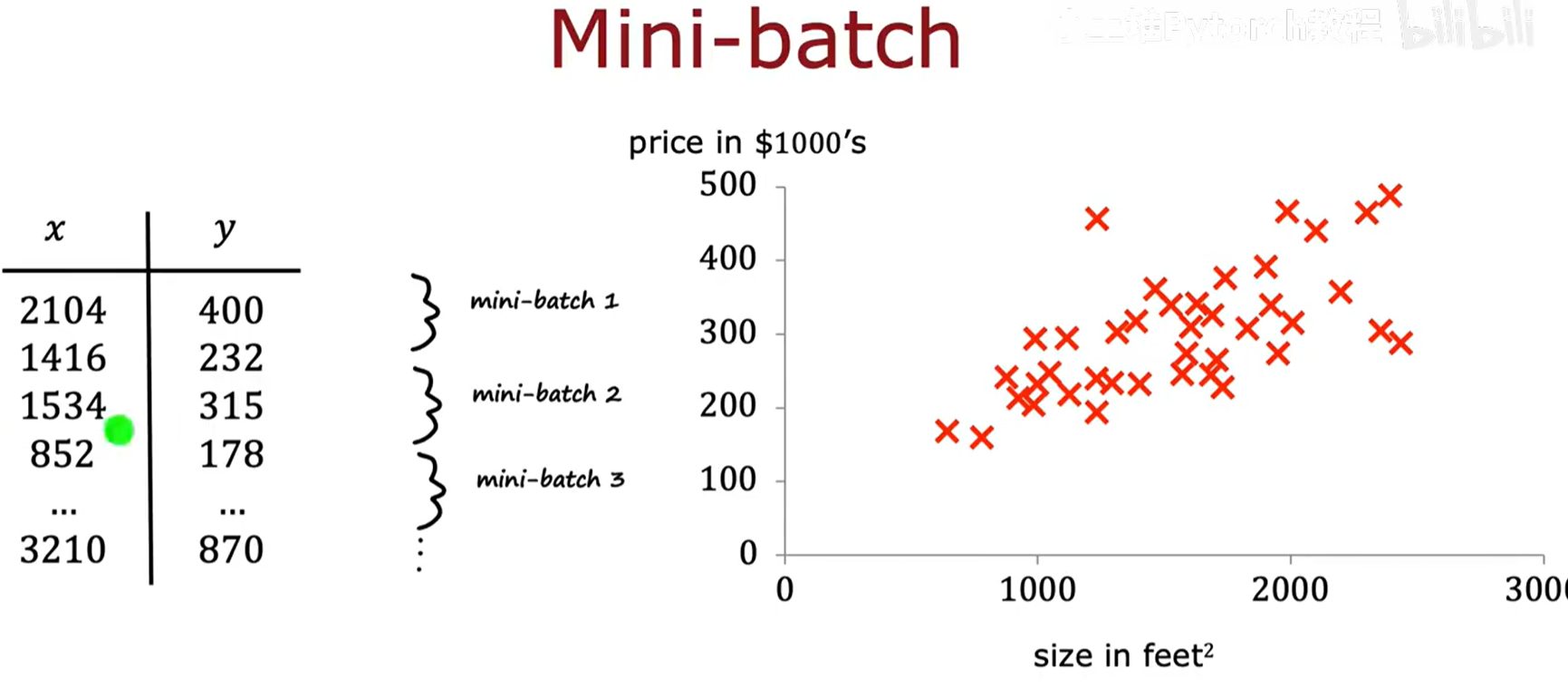
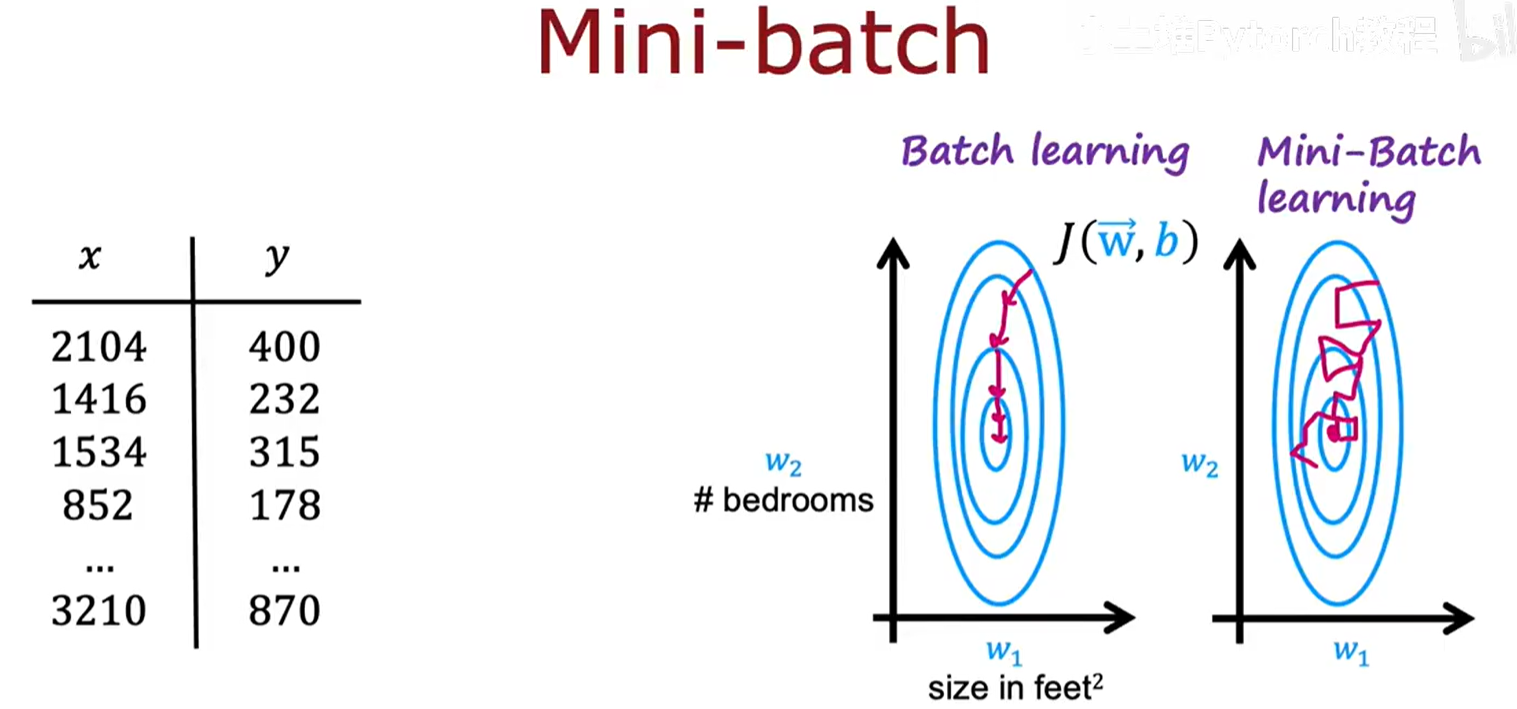
在训练神经网络时,如果我们的Replay Buffer非常大(例如存储了100万个经验元组),在每次更新参数时都计算整个缓冲区的梯度(批梯度下降, Batch Gradient Descent)是完全不可行的。
- Mini-batch 梯度下降 :
- 我们将大的Replay Buffer看作是训练集,从中随机抽取一个小的批次(mini-batch) ,例如
m'=1000个样本。 - 在每一次参数更新的迭代中,我们只在这个mini-batch上计算平均梯度并据此更新网络参数。
- 优势 :
- 效率:每次迭代的计算量与整个数据集的大小无关,非常高效。
- 收敛性:虽然每次更新的方向带有一定的随机性(噪声),不如批梯度下降那么精确,但大量的、快速的更新使得总体上能更快地向最优解收敛。梯度中的噪声在某种程度上还能帮助算法跳出局部最小值。
- 在DQN的学习算法中(步骤3.c.i),从Replay Buffer中随机采样一批数据进行训练,这正是在应用Mini-batch梯度下降的核心思想。
- 我们将大的Replay Buffer看作是训练集,从中随机抽取一个小的批次(mini-batch) ,例如
2.8 训练细节:软更新 (Soft Update)


在DQN算法流程的第3.d步,我们提到"更新Q网络"。一个朴素的想法是,每训练完一个mini-batch,就将训练得到的新网络 Q_new 的参数 W_new, B_new,直接、完整地复制给主网络 Q(Set Q = Q_new)。这种"硬更新"有时会导致训练过程不稳定,因为目标y值的计算依赖于Q网络本身,当Q网络频繁剧烈变动时,目标y也会剧烈摆动,使得学习过程难以收敛。
一种更先进、能显著提升稳定性的技术是软更新(Soft Update) ,它通常与目标网络(Target Network的概念结合使用:
- 我们会维护两个网络:一个是在线网络
Q_online(参数为W, B),它在每个mini-batch上都进行训练;另一个是目标网络Q_target(参数为W_target, B_target),它专门用于计算贝尔曼方程中的目标y,即y = R(s') + γ * max_a' Q_target(s', a')。 - 在软更新中,我们不直接复制参数,而是在每个训练步之后,进行一次微小的、加权平均式的更新:
W_target = τ * W_online + (1 - τ) * W_targetB_target = τ * B_online + (1 - τ) * B_target
τ(tau)是一个非常小的数,例如0.01或0.001。这意味着每次只将在线网络参数的1%"融合"到目标网络中,而保留99%的旧参数。这使得目标网络的变化非常缓慢和平滑,为在线网络的学习提供了一个极其稳定的"锚点",从而大大增加了训练的稳定性。
2.9 强化学习的局限性

尽管深度强化学习在游戏、模拟等领域取得了惊人的、超越人类的成就,但在将其应用于现实世界时,也面临着一些重要的挑战和局限性:
- 模拟与现实的鸿沟 (Sim-to-Real Gap):在完美的、可重复的模拟器中让RL算法工作,通常远比在充满噪声、延迟和不可预测性的真实物理机器人上要容易得多。将模拟器中训练好的策略成功迁移到现实世界是一个活跃的研究领域。
- 应用范围相对较窄:目前,强化学习在工业界成功部署的应用数量,远少于监督学习和无监督学习。它通常需要大量的交互数据(有时是数百万次尝试),并且对环境建模和奖励函数设计非常敏感。
- 巨大的未来潜力:尽管存在挑战,强化学习仍然是人工智能领域最令人兴奋和最具前瞻性的研究方向之一。它被认为是解决更通用的决策智能、实现通用人工智能(AGI)等终极问题的关键路径,其未来的应用潜力是无限的。