以下是 LangChain 官方博客文章《What is a Cognitive Architecture?》的中文翻译:
更新说明:多位读者指出,"认知架构"(cognitive architecture)这一术语在神经科学和计算认知科学领域拥有深厚的学术历史。根据维基百科的定义:"认知架构既指关于人类心智结构的理论,也指该理论的计算实现。"这一定义(以及相关研究和文献)比我在此试图提供的解释要全面得多。因此,本文应被理解为作者在过去一年中构建和协助构建大语言模型(LLM)驱动应用的经验,与该研究领域的映射,而非对"认知架构"的全面学术界定。
在过去六个月里,我频繁使用一个短语------"认知架构"(cognitive architecture),今后我可能还会继续使用它。这个术语最早是我从 Flo Crivello 那里听到的,所有功劳都归于他;我认为这是一个极其出色的表述。那么,我所说的"认知架构"究竟指什么?
我所说的"认知架构",指的是你的系统如何"思考"------换句话说,就是从用户输入出发,经过一系列代码、提示(prompt)和 LLM 调用,最终执行操作或生成响应的整个流程。
我喜欢用"认知"(cognitive)这个词,因为智能体系统(agentic systems)依赖 LLM 来推理"下一步该做什么"。
我也喜欢用"架构"(architecture)这个词,因为这些智能体系统仍然涉及大量类似传统系统架构的工程设计。
将自主性等级映射到认知架构
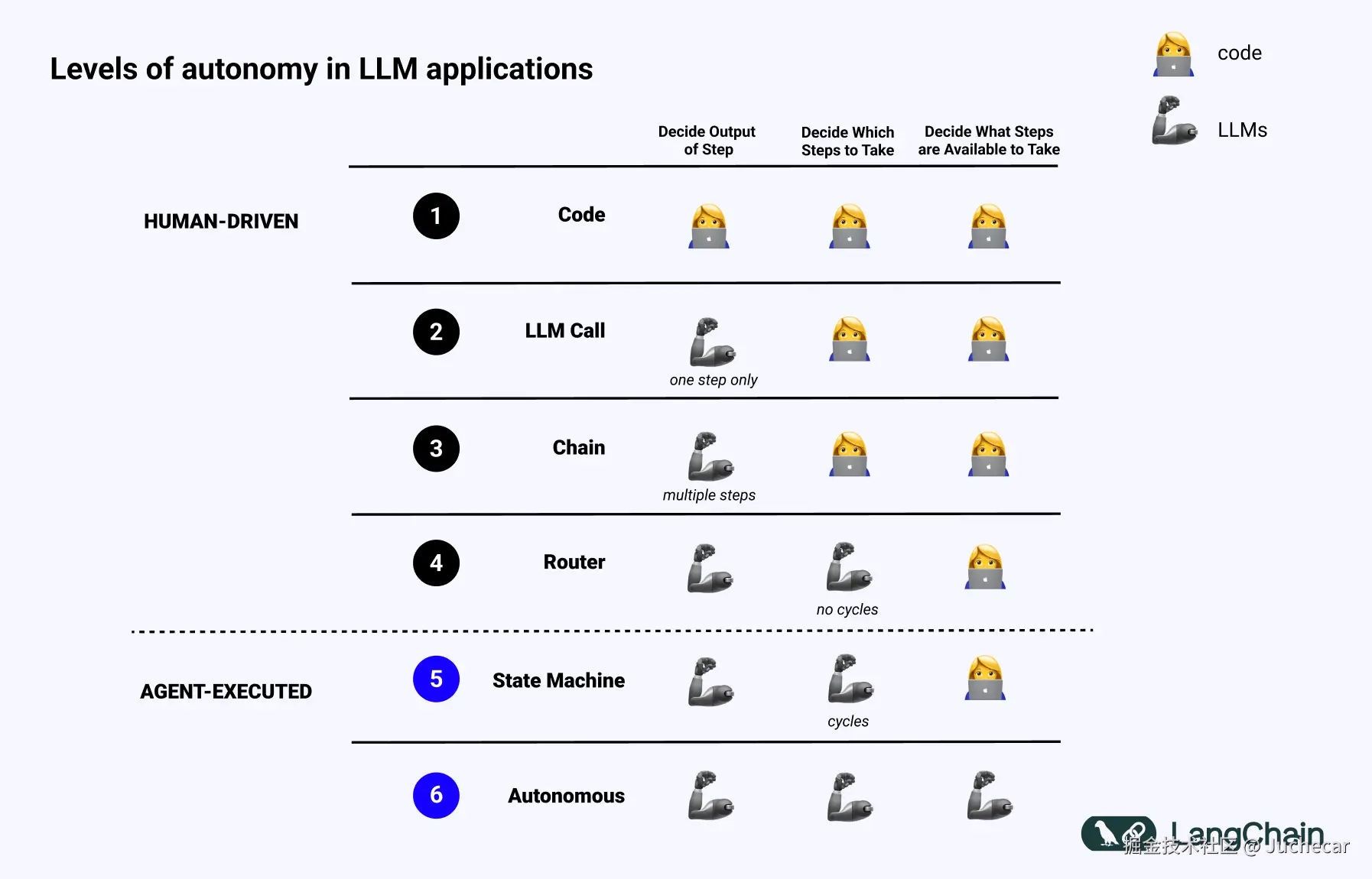
如果我们回顾这张幻灯片(最初来自我的 TED 演讲),其中展示了 LLM 应用的不同自主性等级,就能看到不同认知架构的实例:
-
纯代码(Hard-coded)
所有逻辑都是硬编码的。这甚至算不上真正的"认知架构"。
-
单次 LLM 调用
在 LLM 调用前后可能有一些数据预处理或后处理,但整个应用的核心就是一次 LLM 调用。简单的聊天机器人通常属于这一类。
-
LLM 调用链(Chain of LLM calls)
这种架构将问题拆解为多个步骤,或让每次调用服务于不同目的。更复杂的检索增强生成(RAG)流水线就属于此类:第一次调用生成搜索查询,第二次调用基于检索结果生成答案。
-
路由器(Router)
在此之前,你事先知道应用的所有执行步骤。而到了这一阶段,你不再预先确定流程------LLM 会动态决定采取哪些行动。这引入了更多随机性和不可预测性。
-
状态机(State Machine)
这是将 LLM 路由与循环结构结合起来的架构。由于加入了循环,系统理论上可以调用无限次数的 LLM,因此更加不可预测。
-
智能体(Agent) / 自主智能体(Autonomous Agent)
在状态机中,可执行的动作和后续流程仍然受到限制。而到了"自主智能体"阶段,这些限制被移除。系统自身开始决定:有哪些步骤可用、如何执行、甚至动态更新提示词、工具或底层代码来驱动自身行为。
如何选择认知架构?
当我提到"选择认知架构"时,指的是在上述几种架构中做出取舍。没有哪一种架构绝对优于其他------它们各自适用于不同任务。
在构建 LLM 应用时,你可能需要像调试提示词一样频繁地尝试不同的认知架构。我们开发 LangChain 和 LangGraph 的目标,正是为了支持这种灵活性。过去一年,我们的开发重点已转向构建底层、高度可控的编排框架(如 LCEL 和 LangGraph)。
这与早期 LangChain 的设计有所不同。早期我们更侧重于提供开箱即用、易于使用的"链"(chains),这对初学者非常友好,但难以定制和实验。在行业初期,这种设计非常合适;但随着领域成熟,其局限性迅速显现。
我为我们过去一年在提升 LangChain 和 LangGraph 的灵活性与可定制性方面所做的改进感到无比自豪。如果你之前只使用过 LangChain 的高层封装(high-level wrappers),建议你尝试一下底层组件------它们能让你真正掌控自己应用的"认知架构"。
实践建议:
- 如果你构建的是简单的调用链或检索流程,请使用 LangChain(Python / JavaScript)。
- 如果你需要更复杂的智能体工作流,请尝试 LangGraph(Python / JavaScript)。
原文链接:blog.langchain.com/what-is-a-c...
翻译仅供参考,关键术语保留英文以便对照。