你好,我是 Guide。
2026 届秋招陆续开奖公司的越来越多了,今天来看一家手机厂 OPPO。
前几天,已经分享了招银网络、中兴和小红书今年校招开奖的情况。其中,小红书的薪资最为炸裂,大白菜一年都能给到 51w+。不过,相对应的工作强度和压力也是真的难顶,确实很难有钱多又轻松的活!
OV (OPPO 和 Vivo)这几年发展真还可以的,这两家的高端机口碑都不错。本人也是最近入手了一款 Vivo 的上一代旗舰,拍照是真的不错啊!
根据网上已经爆出的薪资来看,下面是 OPPO 后端和算法(大模型)岗位今年已经开奖的薪资情况:
- 后端:(20~22)k * 15,深圳,白菜,
- 后端:(23~24k) * 15,深圳,SP
- 后端:(25~26k) * 15,深圳,SSP
- 算法(大模型):25.5k * 15,深圳,白菜
- 算法(大模型):27.5k * 15,深圳,SP
- 算法(大模型):29.5k * 15,深圳,SSP (部分高于 29.5 的需要特批)
每个月会有 1.2k 生活补贴,生活费是按照 8 % 缴纳。
对于后端面试来说,OPPO 的一面通常是一些常见八股的考察,难度不大。到了第二面,面试官一般会让你介绍自己的项目,然后对你的项目进行追问拷打。
下面是 OPPO 今年校招的后端一面面经,大家感受一下,是不是难度挺简单的。
Exception 跟 Error 有什么区别
在 Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable 类。Throwable 类有两个重要的子类:
Exception:程序本身可以处理的异常,可以通过catch来进行捕获。Exception又可以分为 Checked Exception (受检查异常,必须处理) 和 Unchecked Exception (不受检查异常,可以不处理)。Error:Error属于程序无法处理的错误 ,我们没办法通过不建议通过catch来进行捕获catch捕获 。例如 Java 虚拟机运行错误(Virtual MachineError)、虚拟机内存不够错误(OutOfMemoryError)、类定义错误(NoClassDefFoundError)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。
Checked Exception 和 Unchecked Exception 有什么区别?
Checked Exception 即 受检查异常 ,Java 代码在编译过程中,如果受检查异常没有被 catch或者throws 关键字处理的话,就没办法通过编译。
比如下面这段 IO 操作的代码:
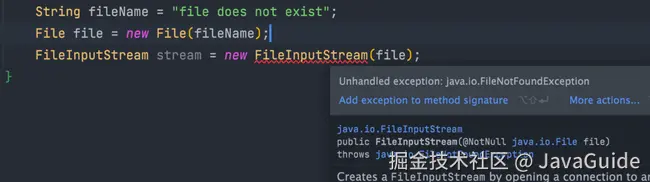
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常 。常见的受检查异常有:IO 相关的异常、ClassNotFoundException、SQLException...。
Unchecked Exception 即 不受检查异常 ,Java 代码在编译过程中 ,我们即使不处理不受检查异常也可以正常通过编译。
RuntimeException 及其子类都统称为非受检查异常,常见的有(建议记下来,日常开发中会经常用到):
NullPointerException(空指针错误)IllegalArgumentException(参数错误比如方法入参类型错误)NumberFormatException(字符串转换为数字格式错误,IllegalArgumentException的子类)ArrayIndexOutOfBoundsException(数组越界错误)ClassCastException(类型转换错误)ArithmeticException(算术错误)SecurityException(安全错误比如权限不够)UnsupportedOperationException(不支持的操作错误比如重复创建同一用户)- ......
你更倾向于使用 Checked Exception 还是 Unchecked Exception?
默认使用 Unchecked Exception,只在必要时才用 Checked Exception。
我们可以把 Unchecked Exception(比如 NullPointerException)看作是代码 Bug。对待 Bug,最好的方式是让它暴露出来然后去修复代码,而不是用 try-catch 去掩盖它。
一般来说,只在一种情况下使用 Checked Exception:当这个异常是业务逻辑的一部分,并且调用方必须处理它时。比如说,一个余额不足异常。这不是 bug,而是一个正常的业务分支,我需要用 Checked Exception 来强制调用者去处理这种情况,比如提示用户去充值。这样就能在保证关键业务逻辑完整性的同时,让代码尽可能保持简洁。
ClassNotFoundException 和 NoClassDefFoundError 的区别
ClassNotFoundException是 Exception,发生在使用反射等动态加载时找不到类,是可预期的,可以捕获处理。NoClassDefFoundError是 Error,是编译时存在的类,在运行时链接不到了(比如 jar 包缺失),是环境问题,导致 JVM 无法继续。
Java 的几种引用类型
无论是通过引用计数法判断对象引用数量,还是通过可达性分析法判断对象的引用链是否可达,判定对象的存活都与"引用"有关。
JDK1.2 之前,Java 中引用的定义很传统:如果 reference 类型的数据存储的数值代表的是另一块内存的起始地址,就称这块内存代表一个引用。
JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引用、软引用、弱引用、虚引用四种(引用强度逐渐减弱),强引用就是 Java 中普通的对象,而软引用、弱引用、虚引用在 JDK 中定义的类分别是 SoftReference、WeakReference、PhantomReference。
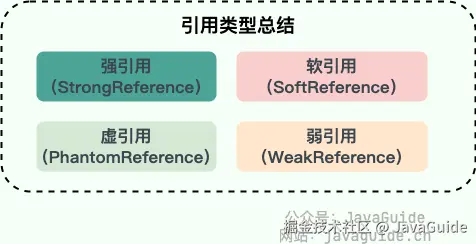
1.强引用(StrongReference)
强引用实际上就是程序代码中普遍存在的引用赋值,这是使用最普遍的引用,其代码如下
java
String strongReference = new String("abc");如果一个对象具有强引用,那就类似于必不可少的生活用品,垃圾回收器绝不会回收它。当内存空间不足,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
2.软引用(SoftReference)
如果一个对象只具有软引用,那就类似于可有可无的生活用品。软引用代码如下
java
// 软引用
String str = new String("abc");
SoftReference<String> softReference = new SoftReference<String>(str);如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,JAVA 虚拟机就会把这个软引用加入到与之关联的引用队列中。
3.弱引用(WeakReference)
如果一个对象只具有弱引用,那就类似于可有可无的生活用品。弱引用代码如下:
java
String str = new String("abc");
WeakReference<String> weakReference = new WeakReference<>(str);
str = null; //str变成软引用,可以被收集弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
4.虚引用(PhantomReference)
"虚引用"顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。虚引用代码如下:
java
String str = new String("abc");
ReferenceQueue queue = new ReferenceQueue();
// 创建虚引用,要求必须与一个引用队列关联
PhantomReference pr = new PhantomReference(str, queue);虚引用主要用来跟踪对象被垃圾回收的活动。
虚引用与软引用和弱引用的一个区别在于: 虚引用必须和引用队列(ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。程序如果发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。
特别注意,在程序设计中一般很少使用弱引用与虚引用,使用软引用的情况较多,这是因为软引用可以加速 JVM 对垃圾内存的回收速度,可以维护系统的运行安全,防止内存溢出(OutOfMemory)等问题的产生。
StringBuffer 的线程安全是如何实现的
StringBuffer 的线程安全是通过在它的大部分公开方法(如 length、 append、insert)上添加了synchronized关键字来实现的。
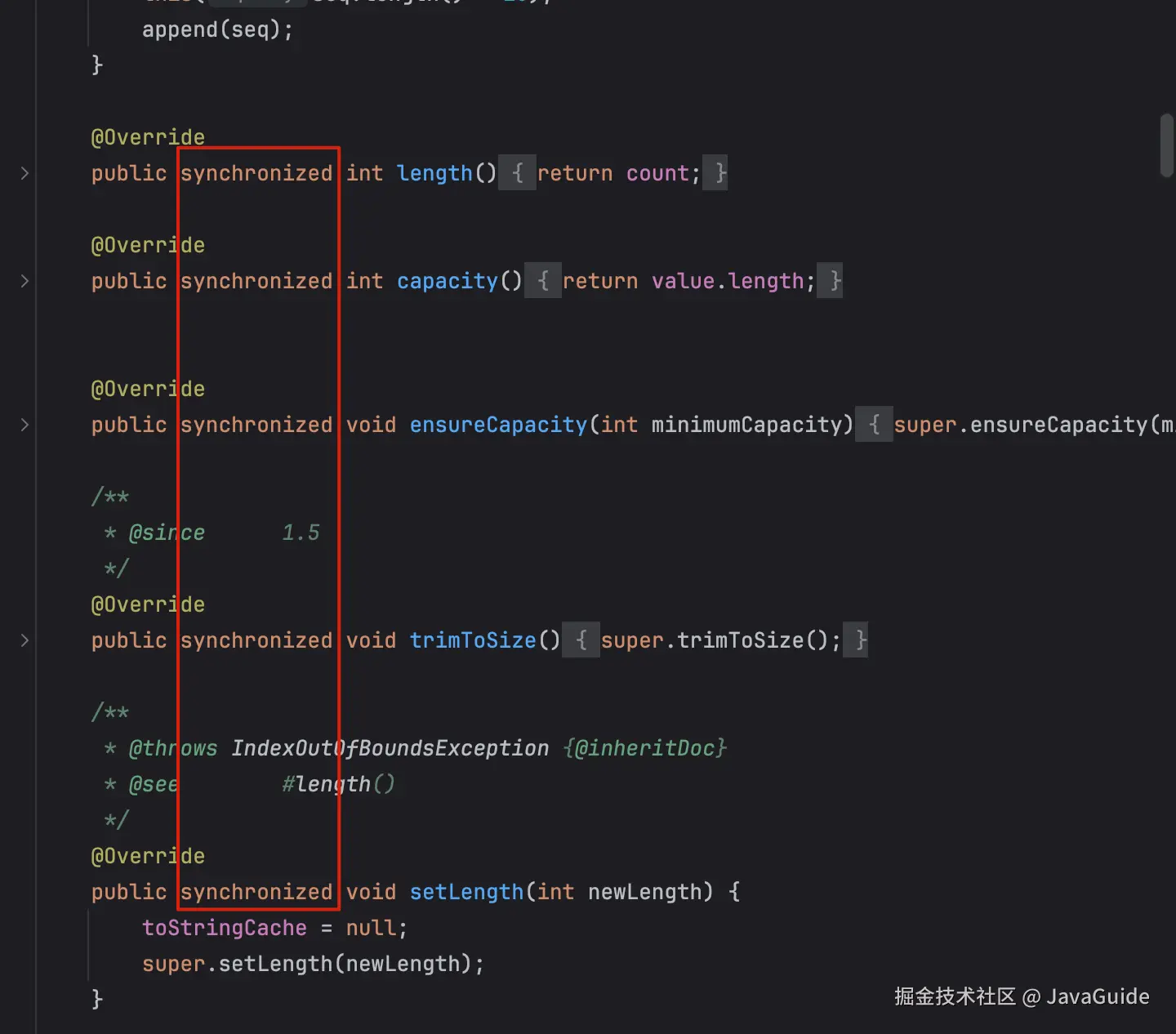
这意味着,任何时候只有一个线程能调用这些方法,因为它锁住了 StringBuffer 对象本身。
这也是它和 StringBuilder 最核心的区别。StringBuilder 没有这个锁,所以速度更快,但非线程安全。
更多 Java 基础知识点和面试题总结,可以阅读笔者写的这几篇文章:
- Java 基础常见面试题总结(上)(Java 语言的基本概念、语法、数据类型、变量、方法等)
- Java 基础常见面试题总结(中)(面向对象基础、字符串、对象的比较与拷贝等)
- Java 基础常见面试题总结(下)(异常、泛型、反射、SPI、序列化、注解等)
HashMap 为什么线程不安全?
HashMap 不是线程安全的。在多线程环境下对 HashMap 进行并发写操作,可能会导致两种主要问题:
- 数据丢失 :并发
put操作可能导致一个线程的写入被另一个线程覆盖。 - 无限循环 :在 JDK 7 及以前的版本中,并发扩容时,由于头插法可能导致链表形成环,从而在
get操作时引发无限循环,CPU 飙升至 100%。
数据丢失这个在 JDK1.7 和 JDK 1.8 中都存在,这里以 JDK 1.8 为例进行介绍。
JDK 1.8 后,在 HashMap 中,多个键值对可能会被分配到同一个桶(bucket),并以链表或红黑树的形式存储。多个线程对 HashMap 的 put 操作会导致线程不安全,具体来说会有数据覆盖的风险。
举个例子:
- 两个线程 1,2 同时进行 put 操作,并且发生了哈希冲突(hash 函数计算出的插入下标是相同的)。
- 不同的线程可能在不同的时间片获得 CPU 执行的机会,当前线程 1 执行完哈希冲突判断后,由于时间片耗尽挂起。线程 2 先完成了插入操作。
- 随后,线程 1 获得时间片,由于之前已经进行过 hash 碰撞的判断,所有此时会直接进行插入,这就导致线程 2 插入的数据被线程 1 覆盖了。
java
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// ...
// 判断是否出现 hash 碰撞
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素(处理hash冲突)
else {
// ...
}还有一种情况是这两个线程同时 put 操作导致 size 的值不正确,进而导致数据覆盖的问题:
- 线程 1 执行
if(++size > threshold)判断时,假设获得size的值为 10,由于时间片耗尽挂起。 - 线程 2 也执行
if(++size > threshold)判断,获得size的值也为 10,并将元素插入到该桶位中,并将size的值更新为 11。 - 随后,线程 1 获得时间片,它也将元素放入桶位中,并将 size 的值更新为 11。
- 线程 1、2 都执行了一次
put操作,但是size的值只增加了 1,也就导致实际上只有一个元素被添加到了HashMap中。
java
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
// ...
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}ConcurrentHashMap 如何实现线程安全的
JDK1.8 之前
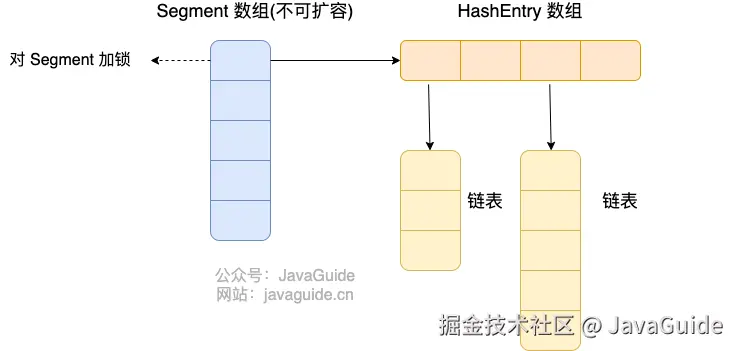
首先将数据分为一段一段(这个"段"就是 Segment)的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。
Segment 继承了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
java
static class Segment<K,V> extends ReentrantLock implements Serializable {
}一个 ConcurrentHashMap 里包含一个 Segment 数组,Segment 的个数一旦初始化就不能改变 。 Segment 数组的大小默认是 16,也就是说默认可以同时支持 16 个线程并发写。
Segment 的结构和 HashMap 类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。也就是说,对同一 Segment 的并发写入会被阻塞,不同 Segment 的写入是可以并发执行的。
JDK1.8 之后
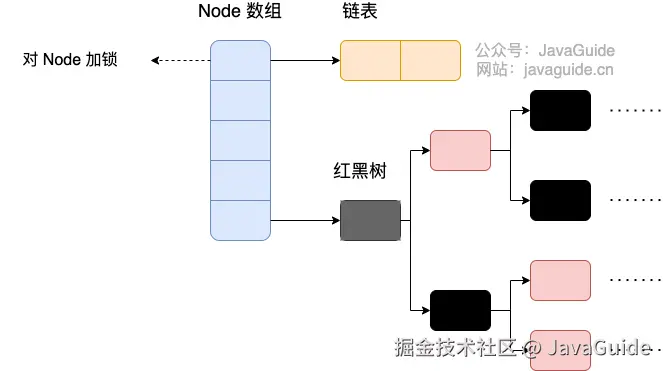
Java 8 几乎完全重写了 ConcurrentHashMap,代码量从原来 Java 7 中的 1000 多行,变成了现在的 6000 多行。
ConcurrentHashMap 取消了 Segment 分段锁,采用 Node + CAS + synchronized 来保证并发安全。数据结构跟 HashMap 1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))。
Java 8 中,锁粒度更细,synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,就不会影响其他 Node 的读写,效率大幅提升。
更多 Java 集合知识点和面试题总结,可以阅读笔者写的这几篇文章:
- Java 集合常见面试题总结(上)(Java 集合基础、
ArrayList、LinkedList、HashSet、ArrayDeque、PriorityQueue、BlockingQueue等) - Java 集合常见面试题总结(下)(
HashMap、ConcurrentHashMap等)
synchronized 是重量级锁吗?
在 Java 早期版本中,synchronized 属于 重量级锁 ,效率低下。这是因为监视器锁(monitor)是依赖于底层的操作系统的 Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高。
不过,在 Java 6 之后, synchronized 引入了大量的优化如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销,这些优化让 synchronized 锁的效率提升了很多。因此, synchronized 还是可以在实际项目中使用的,像 JDK 源码、很多开源框架都大量使用了 synchronized 。
关于偏向锁多补充一点:由于偏向锁增加了 JVM 的复杂性,同时也并没有为所有应用都带来性能提升。因此,在 JDK15 中,偏向锁被默认关闭(仍然可以使用 -XX:+UseBiasedLocking 启用偏向锁),在 JDK18 中,偏向锁已经被彻底废弃(无法通过命令行打开)。
synchronized 和 volatile 有什么区别?
synchronized 关键字和 volatile 关键字是两个互补的存在,而不是对立的存在!
volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好 。但是volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块 。volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。volatile关键字主要用于解决变量在多个线程之间的可见性,而synchronized关键字解决的是多个线程之间访问资源的同步性。
⭐推荐阅读: