一、Flink部署
环境版本:
- Flink1.17.0
- hadoop2.7.6
- jdk1.8
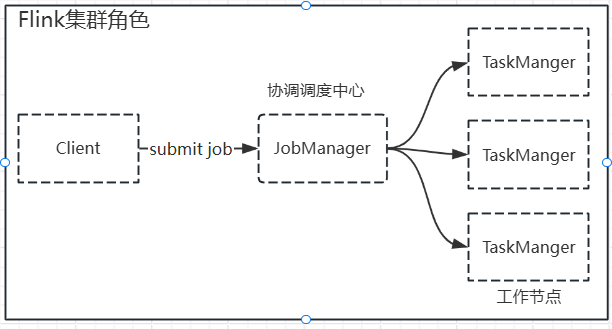
1.集群角色
- 客户端(client):代码由客户端获取并做转换,之后提交给jobmanager
- Jobmanager就是Flink集群里的"管理者",对作业进行中央调度管理;获取到客户端提交的任务后,进一步进行任务的拆分,将具体的执行逻辑分发给taskmaanger
- taskmanager,执行计算角色,数据的具体处理操作。
Flink支持不同的部署模式和资源平台。例如standalone模式、Yarn模式等,Job提交方式有Session模式、Per job模式、Application模式。
2.Flink集群部署
利用Flink部署包部署的集群是独立于第三方资源管理器的。
集群规格
| hb1 | hb2 | hb3 |
|---|---|---|
| jobmanager、taskmanager | taskmanager | taskmanager |
2.1集群配置
- 解压
shell
[jiang@hb1 ~]$ tar -zxvf flink-1.17.0-bin-scala_2.12.tgz /opt/module/- 修改conf/flink-conf.yaml
yml
# JobManager节点地址.
jobmanager.rpc.address: hb1
jobmanager.bind-host: 0.0.0.0
rest.address: hb1
rest.bind-address: 0.0.0.0
# TaskManager节点地址.需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
# 修改成taskmanager的主机地址,例如hb2节点改成hb2
taskmanager.host: hb1- 配置master文件conf/masters
shell
hb1- 配置conf/workers
shell
hb1
hb2
hb3- 启动flink集群
shell
[jiang@hb1 flink-1.17.0]$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hb1.
Starting taskexecutor daemon on host hb1.
Starting taskexecutor daemon on host hb2.
Starting taskexecutor daemon on host hb3.
[jiang@hb1 flink-1.17.0]$ jpsall
-------hb1---------
40101 StandaloneSessionClusterEntrypoint
40693 Jps
40473 TaskManagerRunner
-------hb2---------
27794 TaskManagerRunner
27980 Jps
-------hb3---------
45718 TaskManagerRunner
45878 Jps
[jiang@hb1 flink-1.17.0]$- Dashboard访问
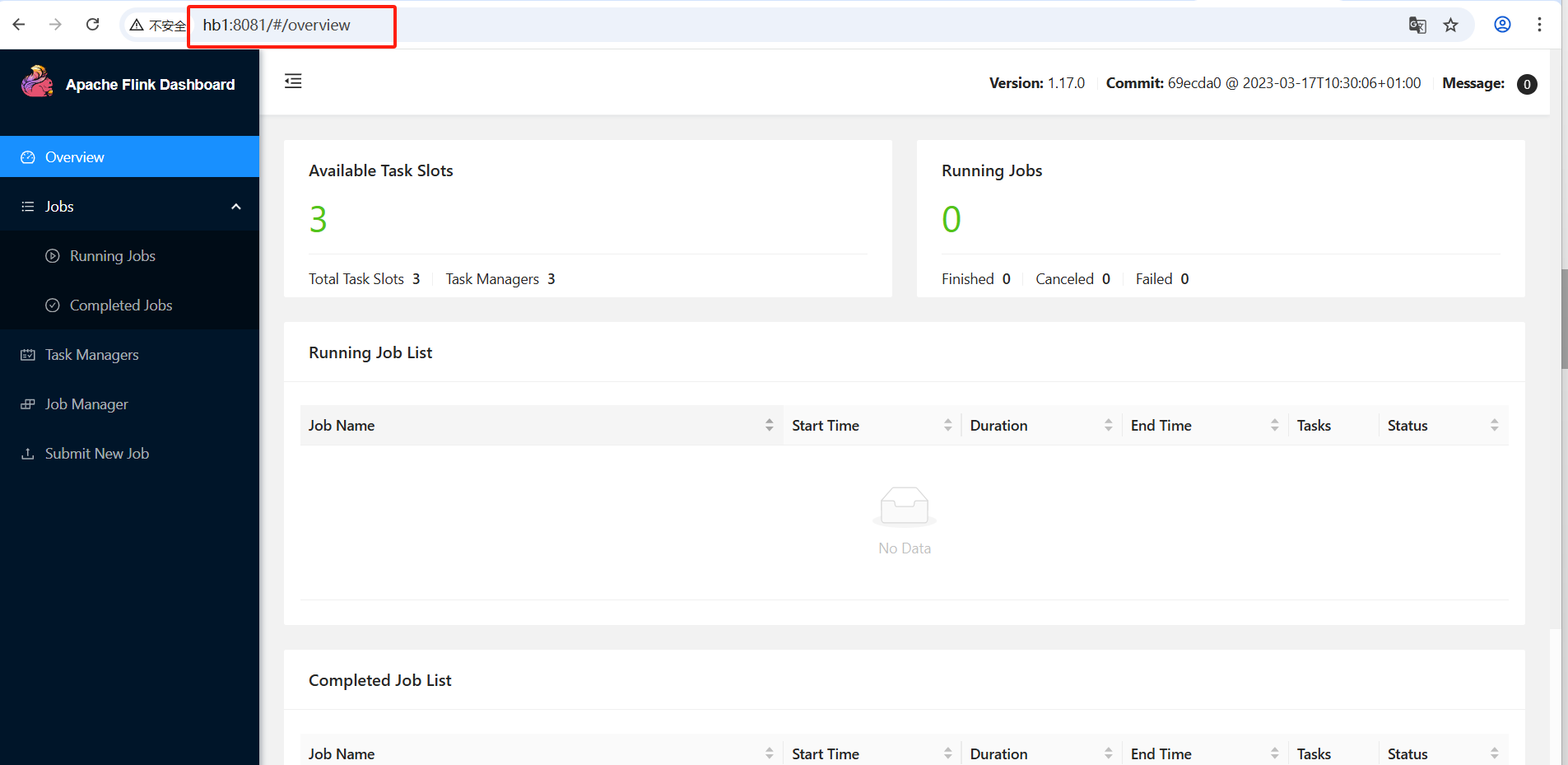
可以看到可用的slot是3,3个taskmanager每个taskmanager提供一个slot。
slot参数可以修改 taskmanager.numberOfTaskSlots
2.2作业提交测试
1.准备Flink执行jar包。(后续会从0-1编写)
shell
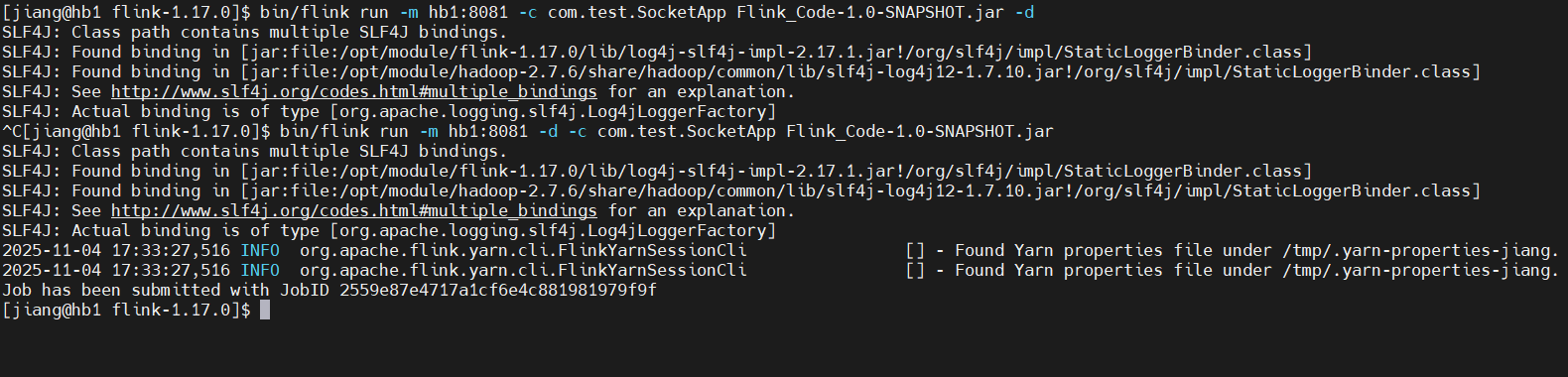
bin/flink run -m hb1:8081 -d -c com.test.SocketApp Flink_Code-1.0-SNAPSHOT.jar-m 指定集群
-c 指定主类
-d 分离模式,客户端提交完成后断开
执行日志
2.dashboard观察作业执行情况
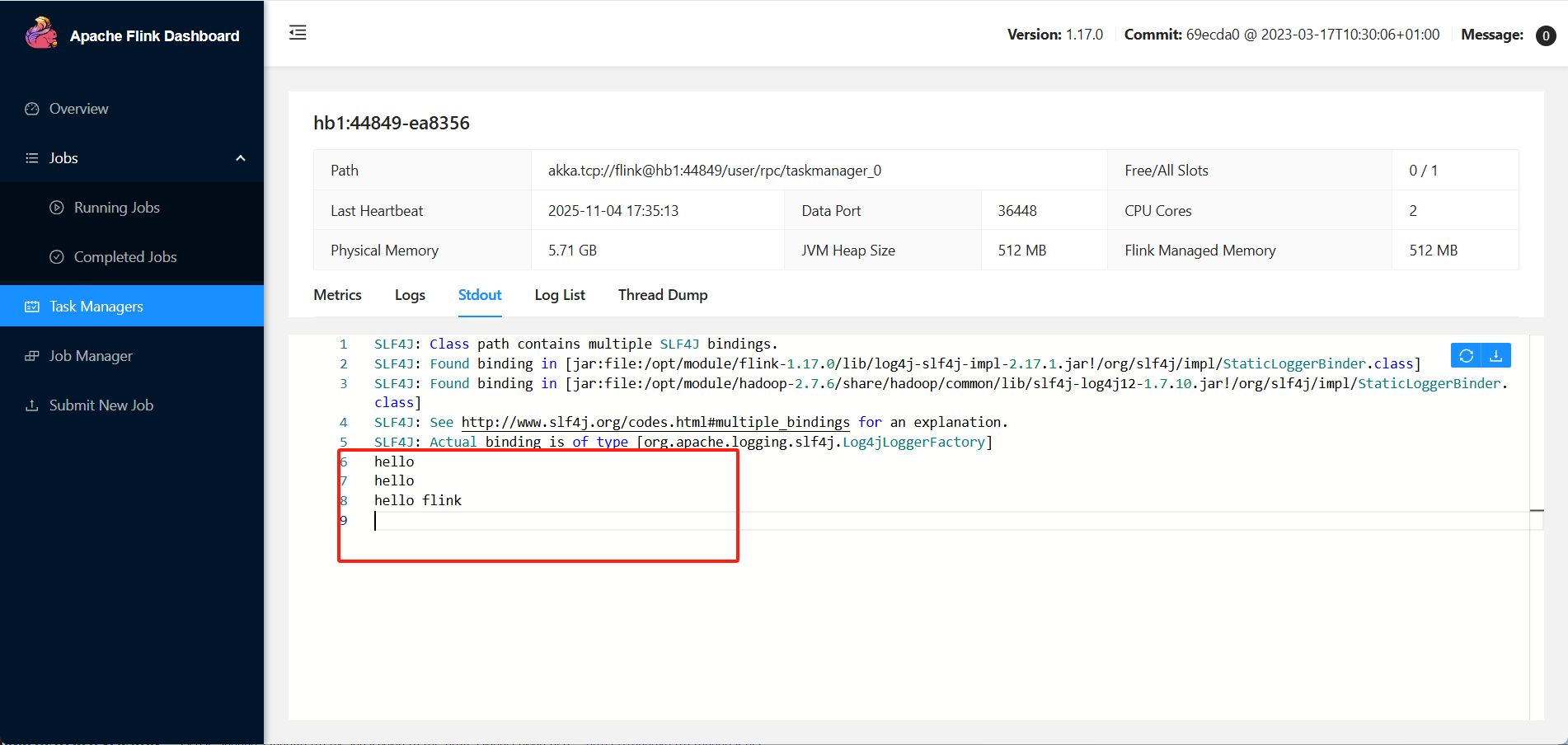
使用flink部署包部署的集群是standalone模式,提交作业是会话模式。
3.作业部署模式
3.1会话模式
Session Mode
- 集群生命周期:先启动集群再提交任务,首先启动一个运行的Flink集群(会话集群),然后将多个Flink作业提交到集群上执行,所有作业执行完成后,集群仍然继续运行,等待新的作业提交
- 资源隔离:资源共享,所有提交到该集群的作业共享该会话集群的资源(TaskManager、JobManager)
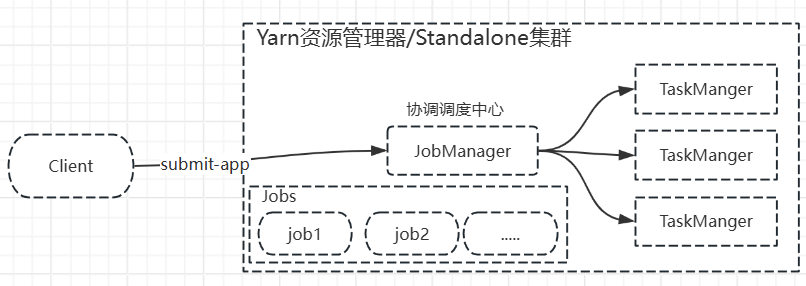
执行流程:
- 启动一个Flink会话集群(一般利用standalone或yarn资源管理器)bin/start-cluster.sh在独立部署模式下,bin/flink run -m yarn-cluster -d在Yarn资源管理器上
- 客户端将作业的Jar和依赖上传到集群的Jobmanager
- jobmanager接收到作业后向资源管理器申请作业运行所需的资源Slot
- Taskmanager提供slot来运行作业
- 作业运行完成后slot资源会释放,但是taskmanager和jobmanager进行继续运行不会停止
优缺点:
-
优点
- 资源复用、启动快,不需要为每个作业都启动集群,作业提交速度快,适合需要频繁提交短时间作业的场景
- 简单直观,管理和维护一个集群
-
缺点
- 资源隔离性差,多个作业共享资源,可能会因异常作业导致taskmanager异常重启而影响到其他作业
- 资源竞争,作业之间会因资源不足等待资源释放,极端情况作业会一直等待
3.2单作业模式
Per-job Mode
单作业模式是为了解决会话模式资源共享、资源抢占的。
集群生命周期:一个作业,一个集群。每提交一次作业,Flink会为其专门启动一个集群,当作业运行执行完成时,整个集群的资源会被释放。
资源隔离:完美隔离,每个作业拥有独立的JobManager和TaskManager,作业之间不会相互受到干扰。
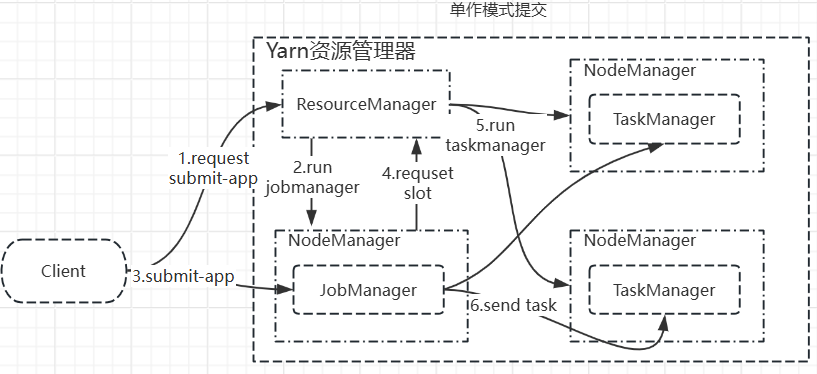
注意:图中有很多组件(AppMaster、Container等)并未绘制,只是为了描述单作业模式大概的流程,注意区分。
执行流程:
- 客户端提交作业,bin/flink run -m yarn-cluster -d 在yarn上,yarn资源调度管理器会识别这是一个per-job模式
- 资源管理器首先会分配容器启动一个该作业专属的jobmanager
- 该jobmanager与client通信,接收客户端提交的作业(业务逻辑以及依赖)
- 通过解析客户端提交的作业,得到所需的资源后再向资源管理器申请资源所需的taskmanager(slot资源)
- 资源管理器分配作业所需资源并启动taskmanager
- jobmanager再将作业执行的操作分发给taskmanager进行处理
- 作业运行完成后,taskmanager和jobmanager资源释放
优缺点:
- 优点
- 优秀的资源隔离,作业之间互不干扰,一个作业失败不会影响到其他作业
- 资源按需分配,每个作业能够获取到运行所需的资源,避免了资源竞争
- 缺点
- 集群启动开销大,每个作业启动独立的集群,启动延迟较高
- 对资源管理器压力大,作业高峰时存在频繁的资源分配和资源销毁的动作,给资源管理器带来巨大的压力
使用场景:一般用于生产环境,有较高稳定性和资源隔离性的要求。
3.3应用模式
application Mode
集群生命周期:一个应用,一个集群。这里的应用通常指的是1个或多个作业组成的应用程序的jar包。集群是为这个应用jar专门启动,应用执行完成后,集群资源释放。
资源隔离:应用级别隔离。不同的应用运行环境是隔离的
与单作业模式和会话模式的核心区别:在会话和单作业模式下,main方法是在客户端执行的,然后由客户端下载作业依赖解析生成作业执行图(JobGraph)然后提交给JobManager。而应用模式客户端只需要将依赖和作业jar提交给jobmanager,由jobmanager解析生成作业执行图(JobGraph)。
执行流程:
- 客户端提交应用(指定Application mode)
- 资源管理器为应用启动专门的集群,首先启动Jobmanager
- 客户端将应用jar和所有依赖提交到该Jobmanager
- Jobmanager端执行:Jobmanager进程调用应用的main方法,生成JobGraph,意味着依赖和解析发生在集群内部,而非客户端。
- 集群执行该应用的所有作业
- 应用执行结束,集群资源释放
优缺点:
- 优点
- 解耦客户端,客户端只需要提交应用jar和依赖即可断开连接,极大的降低了客户端资源消耗和网络带宽的需求
- 拥有单作业资源隔离的优点
- 缺点
- 如果同一个应用被多次提交,会启动多个独立的集群(后面说明)
使用场景:客户端资源有限制或者Rest API进行作业部署的场景。
4.Yarn运行模式
YARN上部署的过程是:客户端把Flink应用提交给Yarn的ResourceManager,Yarn的ResourceManager会向Yarn的NodeManager申请容器。在这些容器上,Flink会部署JobManager和TaskManager的实例,从而启动集群。Flink会根据运行在JobManger上的作业所需要的Slot数量动态分配TaskManager资源。
这个过程在3.2单作业模式模式的执行过程以及描述的比较清楚。
4.1相关配置
将Flink作业提交到Hadoop集群的Yarn资源管理运行,需要进行相关配置才能实现。
环境要求:hadoop
具体配置
1)添加Hadoop环境变量/etc/profile或~/.bash_profile
shell
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_CLASSPATH=`hadoop classpath`2)启动hadoop集群
shell
start-dfs.sh
start-yarn.sh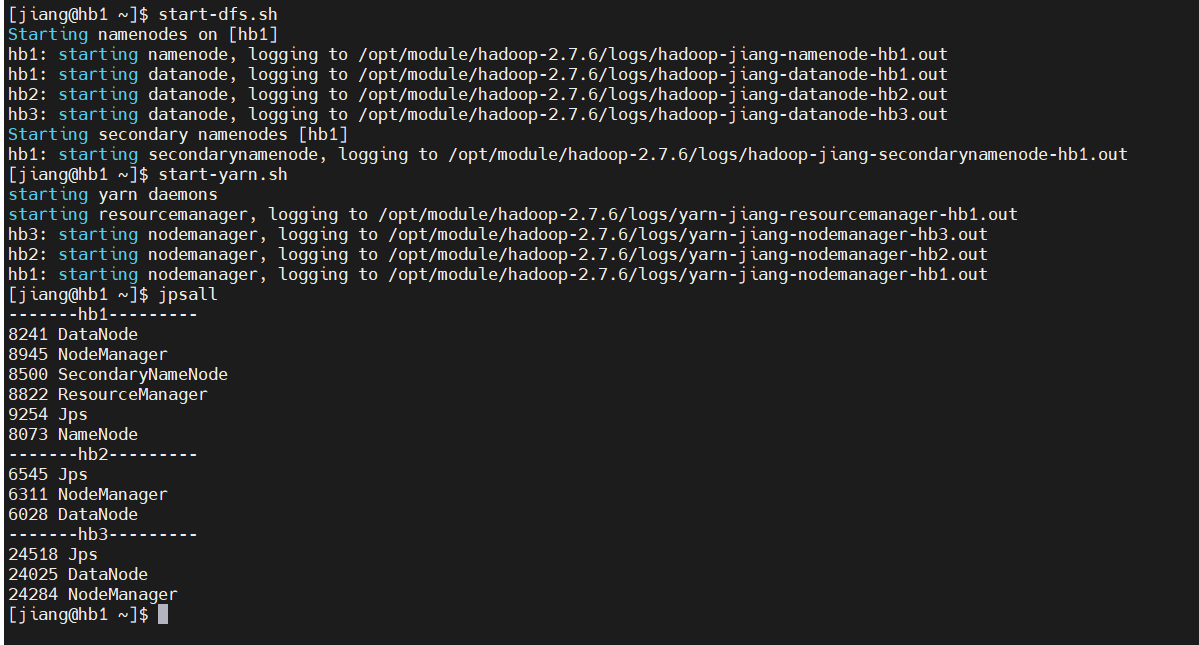
4.2 单作业模式提交
单作业模式提交依赖于第三方,本节利用Yarn资源管理器来进行单作业模式提交,从而运行Flink集群
- 提交命令
shell
bin/flink run -m yarn-cluster -yqu default -ynm flink-socket-test -ys 2 -ytm 2048 -yjm 2048 -d -c com.test.SocketApp Flink_Code-1.0-SNAPSHOT.jar参数解释:
-
-d 分离模式,任务提交完成之后,客户端断开
-
-m 指定提交模式yarn-cluster
-
-yq 指定提交yarn队列名称
-
-ynm 指定作业名称
-
-ys 指定作业taskmanager的slot数量
-
-ytm 指定taskmanager内存大小
-
-yjm指定jobmanager内存大小
2)在yarn界面观察是否提交上去
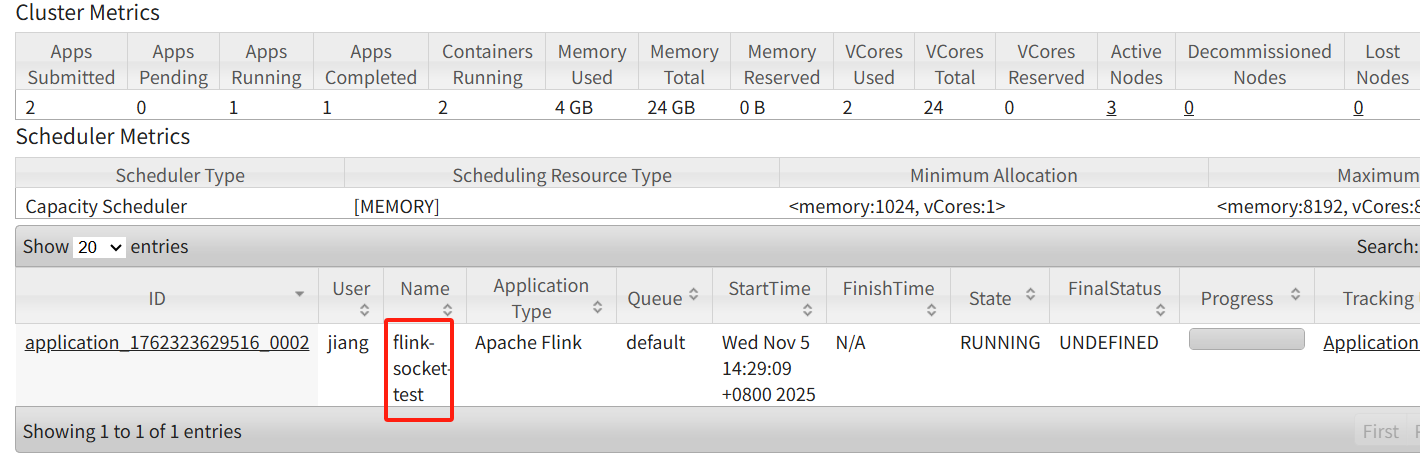
Name就是在命令提交的时候指定的-jnm
3)查看flink dashboard任务
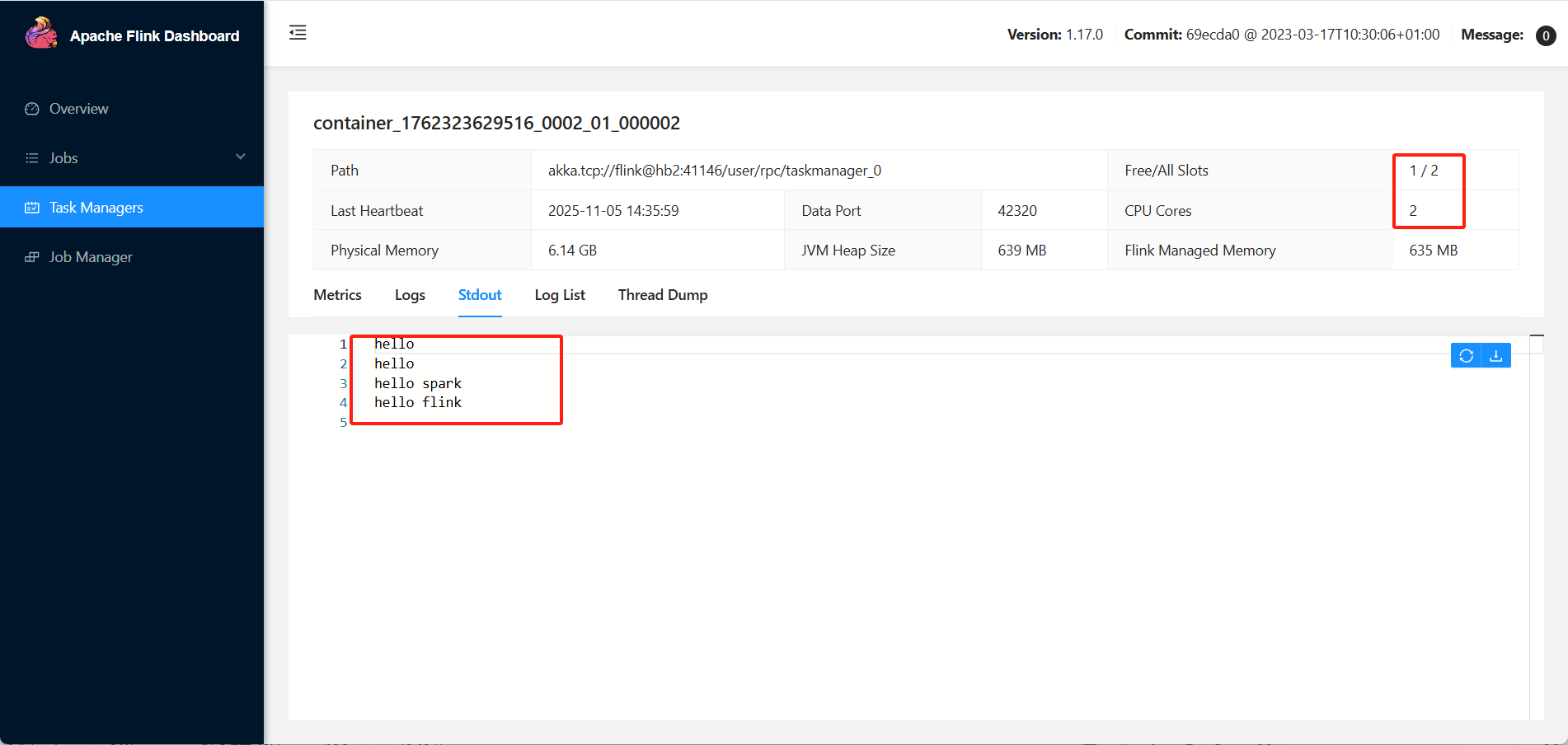
从上图可以看到,总共有两个slot,但是作业里面只使用了1个slot,因为代码里面指定了并行度=1。后续会说明并行度的优先级。
4)取消作业或停止作业
shell
#通过flink命令取消作业
bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_1762323629516_0002
#通过yarn的命令直接停止
yarn application -kill application_1762323629516_0002当执行完命令后,该flink集群就会停止,资源释放归还给ResourceManager
4.3会话模式提交
会话模式Session,在Flink集群部署章节中,作业提交测试就是会话模式,首先启动一个集群,再提交作业到该集群进行运行。但是yarn-Session与独立模式还是有所不同,yarn-session是向ResouorceManager申请容器,NodeManager创建容器后启动JobManager服务,等待客户端提交作业
1)启动yarn-session
shell
bin/yarn-session.sh -d -nm session-name -qu default -tm 1024 -jm 1024 -s 2参数解释:
- -d 分离模式,如果你不想让Flink YARN客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session也可以后台运行
- -jm,配置jobmanager内存大小
- -nm,配置yarn-session该集群的应用名称
- -qu,指定提交队列名称
- tm,指定taskmanager内存大小
Yarn-session模式会根据需要动态的分配taskmanager数量
2)提交作业
执行以下命令将该任务提交到已经开启的Yarn-Session中运行
shell
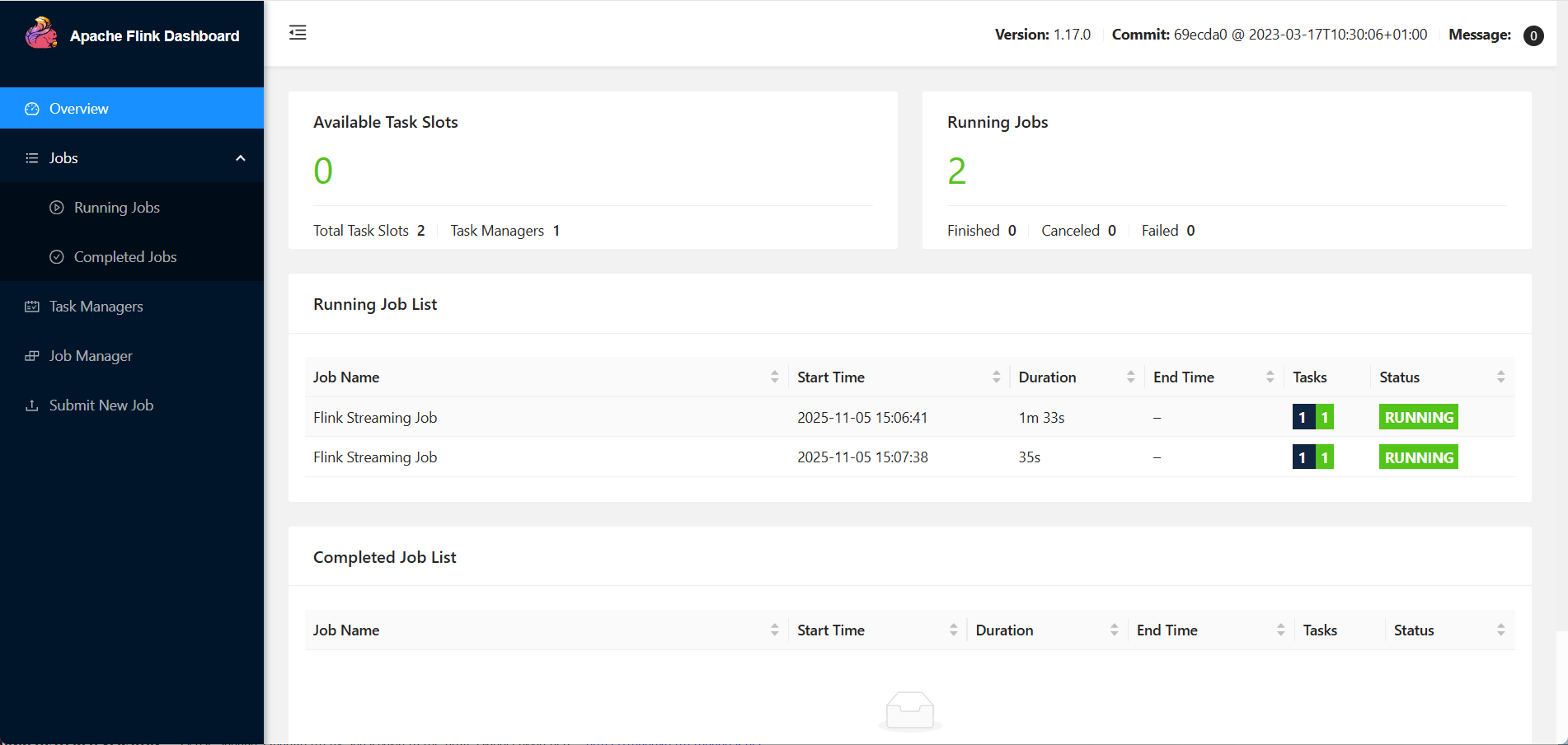
bin/flink run -d -c com.test.SocketApp Flink_Code-1.0-SNAPSHOT.jar3)查看flink dashboard
一共提交了两个作业,共用当前session资源
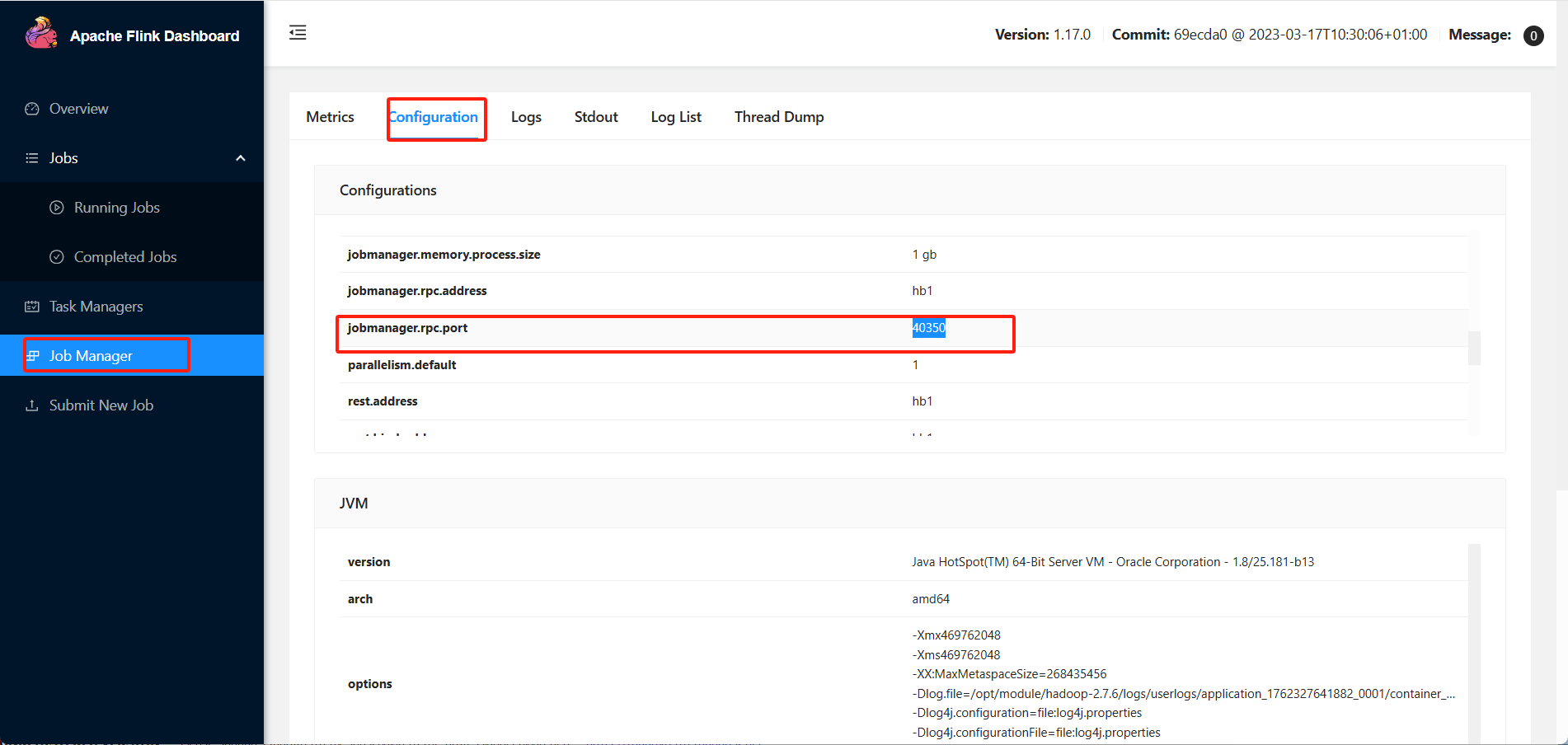
客户端也可以查询jobmanager地址,提交的时候通过-m指定jobmanager进行作业提交,通过dashboard下jobmanager的configuration可以找到。
shell
bin/flink run -m hb1 -d -c com.test.SocketApp Flink_Code-1.0-SNAPSHOT.jar4.4 应用模式提交
应用模式提交跟单作业模式类似,只是传递参数不一样。
shell
bin/flink run-application -t yarn-application -d -c com.test.SocketApp Flink_Code-1.0-SNAPSHOT.jar参数解释
- -d 分离模式
- -c 指定运行主类
- -t 指定部署目标模式 yarn-application
查看yarn dashboard
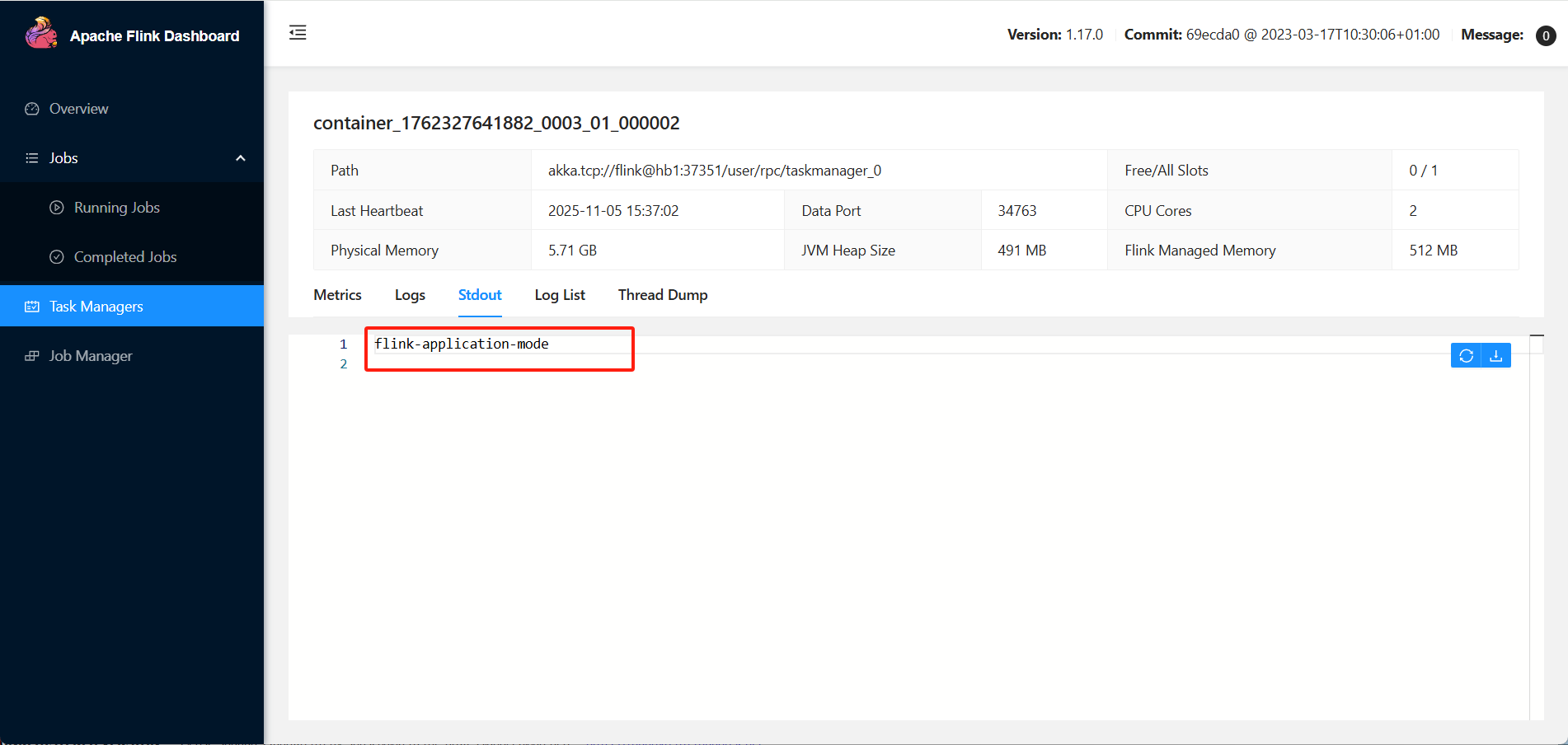
应用模型运行时不依赖于客户端解析作业的逻辑执行图,而是jobmanager运行main进行解析,那么客户端的作用往往就是上传依赖和作业的jar包,在flink提交的设计中,在指定目标运行jar时,可以直接指定hdfs路径,从而减轻客户端上传作业jar包的过程。
1)上传Jar到HDFS路径
shell
#创建flink依赖存储路径
[jiang@hb1 flink-1.17.0]$ hdfs dfs -mkdir -p /flink/remote_lib
[jiang@hb1 flink-1.17.0]$ hdfs dfs -put lib/ /flink/remote_lib
[jiang@hb1 flink-1.17.0]$ hdfs dfs -put plugins/ /flink/remote_lib
#创建运行jar存储路径
[jiang@hb1 flink-1.17.0]$ hdfs dfs -mkdir -p /flink/jars
[jiang@hb1 flink-1.17.0]$ hdfs dfs -put Flink_Code-1.0-SNAPSHOT.jar /flink/jars2)提交作业
shell
bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://hb1:9000/flink/remote_lib" -c com.test.SocketApp hdfs://hb1:9000/flink/jars/Flink_Code-1.0-SNAPSHOT.jar这种方式就比较轻量级了。
日志如下:
shell
[jiang@hb1 flink-1.17.0]$ bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://hb1:9000/flink/remote_lib" -c com.test.SocketApp hdfs://hb1:9000/flink/jars/Flink_Code-1.0-SNAPSHOT.jar
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flink-1.17.0/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-2.7.6/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
2025-11-05 15:58:53,567 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-jiang.
2025-11-05 15:58:53,567 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-jiang.
2025-11-05 15:58:53,778 WARN org.apache.flink.yarn.configuration.YarnLogConfigUtil [] - The configuration directory ('/opt/module/flink-1.17.0/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2025-11-05 15:58:53,884 INFO org.apache.hadoop.yarn.client.RMProxy [] - Connecting to ResourceManager at hb1/192.168.100.131:8032
2025-11-05 15:58:54,066 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2025-11-05 15:58:54,187 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured JobManager memory is 1600 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 448 MB may not be used by Flink.
2025-11-05 15:58:54,187 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - The configured TaskManager memory is 1728 MB. YARN will allocate 2048 MB to make up an integer multiple of its minimum allocation memory (1024 MB, configured via 'yarn.scheduler.minimum-allocation-mb'). The extra 320 MB may not be used by Flink.
2025-11-05 15:58:54,187 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cluster specification: ClusterSpecification{masterMemoryMB=1600, taskManagerMemoryMB=1728, slotsPerTaskManager=1}
2025-11-05 15:58:55,070 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cannot use kerberos delegation token manager, no valid kerberos credentials provided.
2025-11-05 15:58:55,081 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1762327641882_0005
2025-11-05 15:58:55,174 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1762327641882_0005
2025-11-05 15:58:55,174 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2025-11-05 15:58:55,182 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2025-11-05 15:59:06,307 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2025-11-05 15:59:06,308 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hb3:41495 of application 'application_1762327641882_0005'.
[jiang@hb1 flink-1.17.0]$以上是个人理解,如有问题可沟通