(def [a b c] (range 10))
(print a " " b " " c) # prints 0 1 2
(def {:x x} @{:x (+ 1 2)})
(print x) # prints 3
(def [y {:x x}] @[:hi @{:x (+ 1 2)}])
(print y x) # prints hi3
在全局作用域中, def 也可以给符号添加元数据和文档。在非全局作用域,元数据会被忽略。
lisp复制代码
(def mydef :private 3) # Adds the :private key to the metadata table.
(def mydef2 :private "A docstring" 4) # Add a docstring
# The metadata will be ignored here because mydef is
# not accessible outside of the do form.
(do
(def mydef :private 3)
(+ mydef 1))
(var name meta... value)
与 def 类似,除了绑定可以修改,其他都与 def 一样。
lisp复制代码
(var a 1)
(defn printa [] (print a))
(printa) # prints 1
(++ a)
(printa) # prints 2
(set a :hi)
(printa) # prints hi
💡
可变与不可变?它们的本质到底是什么?
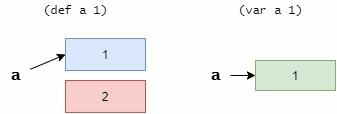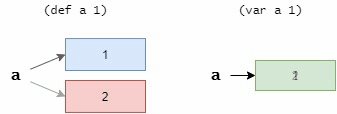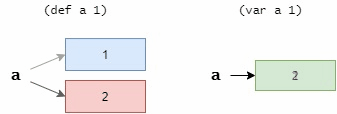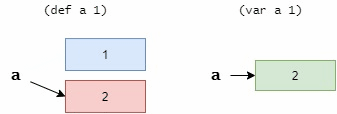
def 和 var 的区别可以理解为指针与变量的区别。 def 就是指针,更换绑定就是让他指向不同的地址,但是每次指向的内存区域都不能修改。 var 就是变量,可以修改它对应的内存的内容。
(fn []) # The simplest function literal. Takes no arguments and returns nil.
(fn [x] x) # The identity function
(fn identity [x] x) # The name will make stacktraces nicer
(fn [] 1 2 3 4 5) # A function that returns 5
(fn [x y] (+ x y)) # A function that adds its two arguments.
(fn [& args] (length args)) # A variadic function that counts its arguments.
# A function that doesn't strictly check the number of arguments.
# Extra arguments are ignored.
(fn [w x y z &] (tuple w w x x y y z z))
# For improved debugging, name with symbol or keyword
(fn alice [] :smile)
(fn :bob [] :sit)
(do body...)
执行一系列表达式并返回最后一个表达式的结果。它也会引入一个新的词法作用域。
lisp复制代码
(do 1 2 3 4) # Evaluates to 4
# Prints 1, 2 and 3, then evaluates to (print 3), which is nil
(do (print 1) (print 2) (print 3))
# Prints 1
(do
(def a 1)
(print a))
# a is not defined here, so fails
a
(quote 1) # evaluates to 1
(quote hi) # evaluates to the symbol hi
(quote quote) # evaluates to the symbol quote
'(1 2 3) # Evaluates to a tuple (1 2 3)
'(print 1 2 3) # Evaluates to a tuple (print 1 2 3)
if 语句只有在必要时才会求值 when-true 或 when-false 表达式,他是惰性求值的,因此不能是函数或宏。
条件表达式只有 nil 或 false 被认为是假,其他值都是真。
when-true 或 when-false 表达式会在一个新的词法作用域下求值。
lisp复制代码
(if true 10) # evaluates to 10
(if false 10) # evaluates to nil
(if true (print 1) (print 2)) # prints 1 but not 2
(if 0 (print 1) (print 2)) # prints 1
(if nil (print 1) (print 2)) # prints 2
(if @[] (print 1) (print 2)) # prints 1
(splice x)
splice 可以将数组或元组的内容提取到外面,从而脱去数据结构的包装(也就是把数据结构的衣服给脱了)。它只在两个地方有效,做为函数调用的参数或用于词法构造器,或者做为 unquote 表达式的参数。其他情况下直接返回参数 x 。它的语法糖是在表达式前加上一个分号。 splice 不能嵌套,除非做为 unquote 的参数。
在函数调用中, splice 会将 x 的内容插入函数列表。
lisp复制代码
(+ 1 2 3) # evaluates to 6
(+ @[1 2 3]) # bad
(+ (splice @[1 2 3])) # also evaluates to 6
(+ ;@[1 2 3]) # Same as above
(+ ;(range 100)) # Sum the first 100 natural numbers
(+ ;(range 100) 1000) # Sum the first 100 natural numbers and 1000
[;(range 100)] # First 100 integers in a tuple instead of an array.
(def ;[a 10]) # this will not work as def is a special form.