TL;DR
- 场景:在实时/近实时数仓中,需要低延迟写入 + 列式分析并行读。
- 结论:Kudu 以 RowSet 设计、Range/Hash 复合分区与 Raft 副本,兼顾吞吐与一致性。
- 产出:对比与架构要点梳理、常见故障速查与修复路径。


Kudu 对比
Kudu 和 HBase、HDFS 之间的对比: 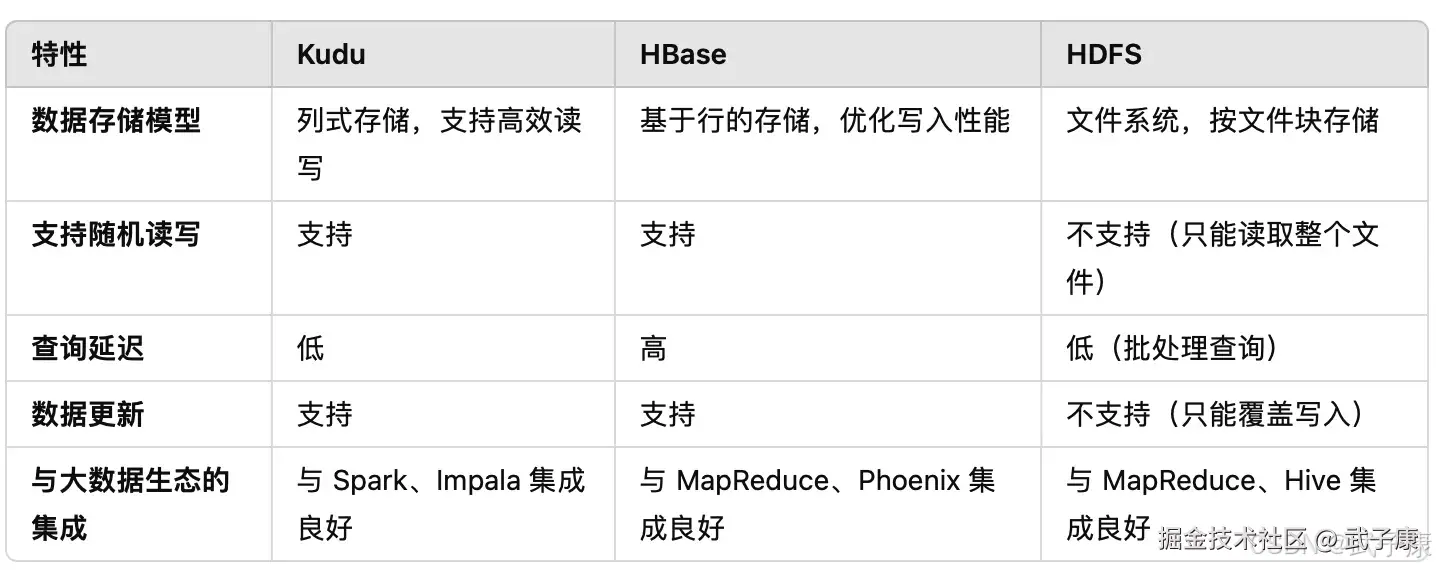
Kudu的架构
与HDFS和HBase相似,Kudu使用单个Master节点,用来管理集群的元数据,并且使用任意数量的TabletServer节点用来存储实际数据,可以部署多个Master节点来提高容错性。
Master
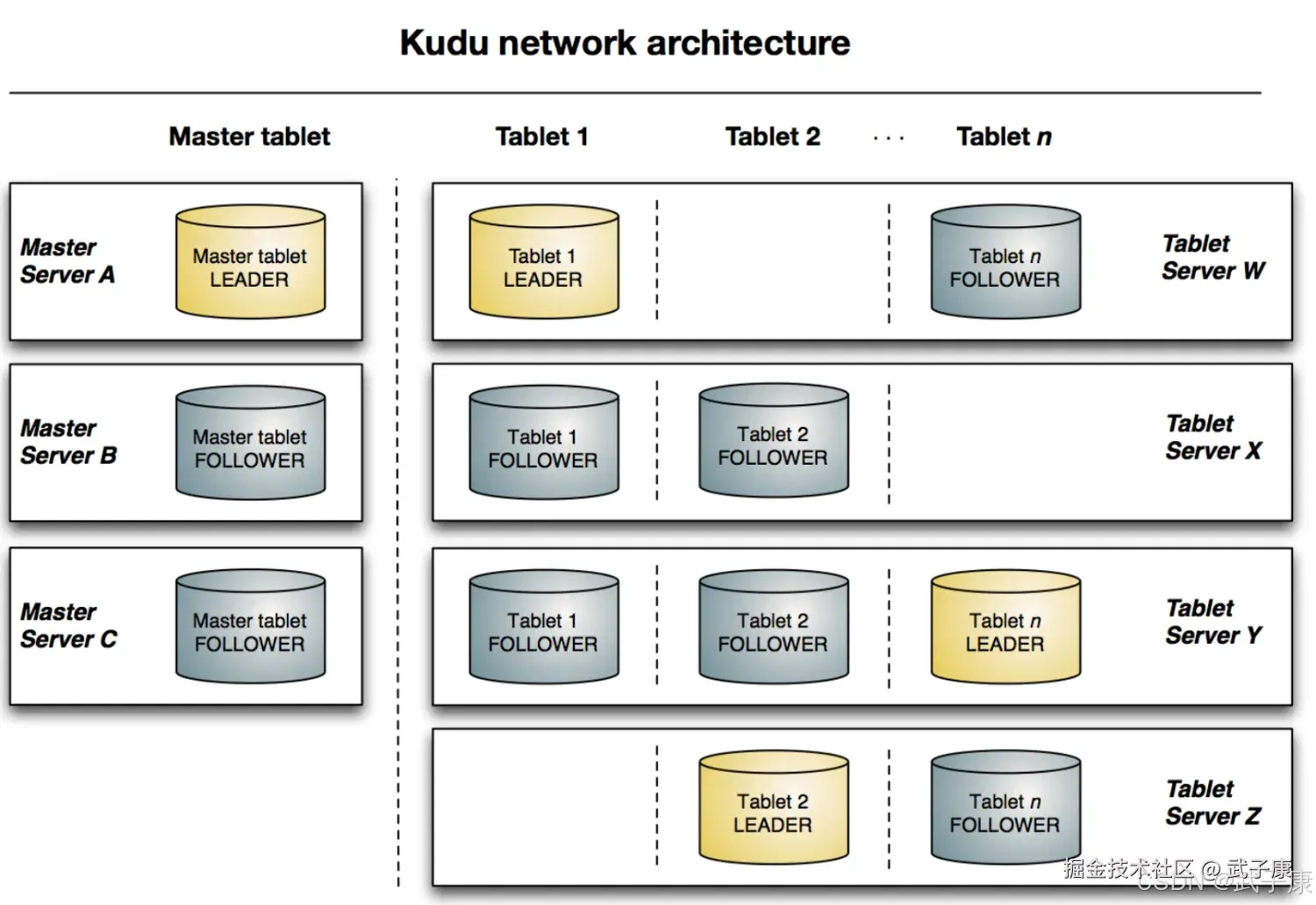
-
高可用与容错机制:Kudu 的高可用和容错能力基于其副本管理机制。每个 Tablet 都有多个副本,副本之间通过 Raft 协议进行同步:
-
Leader 选举:如果某个 Tablet 的 Leader 副本发生故障,系统会自动选举一个新的 Leader 来接管读写操作,确保服务不间断。 副本恢复:当某个 Tablet Server 节点发生故障,Master 节点会将失效的副本重新分配到其他健康的 Tablet Server 上,并同步数据。
Master
Kudu的Master节点负责整个集群的元数据管理和服务协调,它承担着如下的功能:
- 作为Catalog Manager,Master节点管理集群中所有Tablet和Schema及一些其他的元数据。
- 作为Cluster Coordinate,Master节点追踪着所有Server节点是否存活,并且当Server节点挂掉后协调数据重新分布。
- 作为TabletDirectory,Master跟踪每个Tablet的位置。
Catalog Manager
Kudu的Master节点会持有一个单Tablet的Table-CatalogTable,但是用户是不能直接访问的,Master将内部的Catalog信息写入Tablet,并且将整个Catalog的信息缓存到内存中。随着现在商用服务器上的内存越来越大,并且元数据信息占用空间其实并不大,所以Master不容易存在性能瓶颈,CatalogTable保存了所有Tablet的Schema的版本与Table的状态(创建、运行、删除等等)。
Cluster Coordination
Kudu集群中的每个Tablet Server都需要配置Master的主机名列表,在集群启动时,TabletServer会向Master注册,并发送所有Tablet信息。 TabletServer第一次向Master发送信息时会发送所有Tablet的全量信息,后续每次发送则只会发送增量信息,仅包含新创建、删除或修改Tablet的信息,作为ClusterCoordination,Master只是集群状态的观察者。对于TabletServer中Tablet的副本位置、Raft配置和Schema版本等信息的控制和修改由TabletServer自身完成。Master只要下达命令,TabletServer执行成功后会自动上报处理的结果。
Tablet Directory
因为Master上缓存了集群的元数据,所以Client读写数据的时候,肯定是要通过Master才能获取到Tablet的位置灯信息,但是如果每次读写都要通过Master节点的话,那Master就会成为这个集群的瓶颈,所以Client会在本地缓存一份它需要访问的Tablet的位置信息,这样就不用每次都从Master读取了。因为Tablet的信息也可能会发生改变(比如掉线或者宕机),所以当Tablet的值发生变化的时候,Client会收到通知,然后再从Master重新拉取一份新的。
Table
在数据存储方面,Kudu选择完全由自己实现,而没有借助于已有的开源方案,Tablet存储主要想实现的目标为:
- 快速的列扫描
- 低延迟的随机读写
- 一致性的性能
RowSets
在Apache Kudu的存储架构中,Tablet被进一步细分为更小的存储单元,称为RowSets。这些RowSets根据存储介质的不同分为两种类型:
-
MemRowSets:
- 完全驻留在内存中的数据结构
- 采用基于B树的实现方式
- 主要负责存储最新插入的数据
- 使用高效的并发控制机制支持高吞吐量写入
-
DiskRowSets:
- 混合使用内存和磁盘的存储结构
- 由MemRowSet经过Flush操作转化而来
- 采用列式存储格式(CFile)保存在磁盘上
- 包含Bloom Filter和主键索引等辅助结构
存储管理机制具有以下特点:
- 数据唯一性保证:任何未被逻辑删除的行数据都严格只存在于一个RowSet中
- MemRowSet生命周期:
- 每个Tablet始终只维护一个活跃的MemRowSet
- 后台的Flush线程会按照配置的时间间隔(默认1秒)或大小阈值触发数据持久化
- Flush完成后,系统会原子性地创建新的空MemRowSet继续接收新数据
Flush操作的关键特性:
- 非阻塞式设计:采用Copy-on-Write技术确保Flush过程中不影响客户端读写
- 并行处理:一个大MemRowSet会被拆分成多个DiskRowSet以提高并行度
- 数据转换:原始行数据会被转换为列式存储格式,并生成相应的索引结构
这种架构设计使得Kudu能够:
- 实现高达每秒数万行的写入吞吐
- 保持毫秒级的查询延迟
- 支持在线的Schema变更
- 提供持续稳定的性能表现
MemRowSets
MemRowSets是一个可以被并发访问并进行优化的B-Tree,主要是基于MassTree来设计的,但存在几点不同:
- Kudu并不支持直接删除操作,由于使用了MVCC,所以在Kudu中删除操作其实是插入一条标志着删除的数据,这样就可以推迟删除操作。
- 类似删除操作,Kudu也不支持原地更新操作
- 将Tree的Leaf链接起来,就像B+Tree,这一步关键的操作可以明显的提升Scan操作的性能。
- 没有实现字典树(trie树),而是只用了单个Tree,因为Kudu并不适用于极高的随机读写的场景。 与Kudu中其他模块中的数据结构不同,MemRowSet中的数据使用行存储,因为数据都在内存中,所以性能也是可以接受的,而且Kudu在MemRowSet中的数据结构进行了一定的优化。
DiskRowSet
当MemRowSet被Flush到磁盘后,就变成了DiskRowSet,当MemRowSet被Flush硬盘的时候,每32M就会形成一个新的DiskRowSet,这主要是为了保证每个DiskRowSet不会太大,便于后续的增量Compaction操作。Kudu通过将数据氛围BaseData和DeltaData,来实现数据的更新操作。Kudu会将数据按列存储,数据被切分多个Page,并使用B-Tree进行索引。除了用户写入数据,Kudu还会将主键索引存入一个列中,并且提供布隆过滤器来进行高效的查找。
Compaction
为了提供查询性能,Kudu会定期进行Compaction操作,合并DeltaData与BaseData,对标记了删除的数据进行删除,并且会合并一些DiskRowSet。
分区
选择分区策略需要理解数据模型和标的预期工作负载:
- 对于写量大的工作负载,重要的是要设计分区,使写分散在各个Tablet上,以避免单个Tablet超载。
- 对于涉及许多短扫描的工作负载(其中联系远程服务器的开销占主导地位),如果扫描的所有数据都位于同一块Tablet上,则可以提高性能。
理解这些基本的权衡是设计有效分区模式的核心。 没有默认分在创建表时,Kudu不提供默认的分区策略。建议预期具有繁重读写工作负载的新表至少拥有与Tablet服务器相同的Tablet。 和需要分布式存储系统一样,Kudu的Tablet是水平分区的,BigTable只提供了Range分区,Cassandra只提供Hash分区,而Kudu同时提供了这两种分区方式,使分区较为灵活。 当用户创建了一个Table时,可以同时指定Table的PartitionSchema,PartitionSchema会将primary key映射为Partition key。一个PartitionSchema 包括0到多个Hash-Partitioning规则和一个Range-Partitioning规则,通过灵活的组合各种Partition规则,用户可以创造适用于自己业务场景分区方式。
Kudu 支持两种分区策略:范围分区(Range Partitioning) 和 哈希分区(Hash Partitioning)。
范围分区
范围分区基于主键范围划分 Tablet。用户可以通过设置分区键的范围,手动或自动地将数据分布到不同的 Tablet 上。例如,按时间戳划分数据表可以将不同时间段的数据分配到不同的分区。
哈希分区
哈希分区通过对主键进行哈希运算,将数据均匀分布到不同的 Tablet 中。哈希分区适用于那些查询中没有明显范围条件的场景,如主键查询或随机访问场景。
查询与写入流程
写入流程
- 客户端将数据写入 Tablet Server 时,首先被写入到 MemRowSet 中。
- MemRowSet 达到一定容量后,数据会通过后台线程刷入磁盘(DiskRowSet)。
- 刷盘过程中,Tablet Server 会将数据同步到其他副本,以保证数据的一致性。
查询流程
- 客户端查询数据时,查询请求首先发送到 Master 节点,Master 节点根据请求的主键范围定位到相应的 Tablet Server。
- Tablet Server 从磁盘中的 DiskRowSet 中读取对应列的数据,返回给客户端。
- 如果查询只涉及部分列,Kudu 只读取涉及的列数据,利用列式存储的优势提高查询效率。
Tablet 和 Raft 共识协议
Kudu 的数据被切分为多个Tablet,每个 Tablet 是表的一部分,类似于水平分片(Horizontal Partitioning)。 每个 Tablet 通过主键范围进行划分,确保数据均匀分布在不同的 Tablet Server 上。
为了保证数据的可靠性和一致性,Kudu 使用了 Raft 共识协议 来进行副本管理。每个 Tablet 通常有多个副本(默认是三个),这些副本通过
Raft 协议保证
- 数据一致性:在任意时刻,只有一个副本可以作为主副本(Leader),其他副本为跟随者(Follower)。所有的写入操作必须先写入 Leader,然后通过 Raft 协议同步到 Follower,确保数据一致性。
- 故障容错:如果 Leader 副本发生故障,系统会自动通过 Raft 协议选举一个新的 Leader,保证系统的高可用性。
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 写入偶发超时/重试 | 分区热点或 Tablet 过少 | 观察写入分布、Tablet Server 写队列与 RPC 指标 | 增加 Hash 分区桶数或引入多级分区,均衡写入。 |
| Scan 抖动、缓存命中率低 | 大扫描驱逐热点页 | 关注 Block Cache 命中率/驱逐率 | 1.18.0 评估"分段 LRU Block Cache(实验)",或扩大缓存/分层 Scan。 |
| Tablet 频繁选主/短暂不可写 | Raft 多数派不可用或网络抖动 | 查看副本健康、心跳与超时 | 恢复副本/网络,必要时降副本到可用多数并重建副本。 |
| Leader 写成功但读不一致 | 读到落后 Follower 或延迟可见 | 对比 Leader/Follower 日志与 MVCC 水位 | 读走 Leader/启用一致性读,确认多数派提交点。 |
| 表容量/Region 不均衡 | 仅 Range 分区导致倾斜 | 查看分区键基数与时间序写入 | 引入 Hash 维度或时间滚动 Range;定期补分区。 |
| Flush 频繁影响尾延迟 | MemRowSet 过小或写入爆发 | 监控 Flush 频率、磁盘 IO、队列 | 调整 Flush 阈值与 WAL/IO 并发;评估硬件带宽。 |
| 客户端元数据查询放大 | 频繁查询 Master 定位 Tablet | 客户端缓存命中与失效率 | 提高客户端 Tablet 位置信息缓存时效;排查 Tablet 迁移频率。 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈 🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础! 🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解 🔗 大数据模块直达链接