摘要
本文系统性地介绍了BERT模型的核心机制与应用。首先,文章阐述了BERT的预训练方法,重点是其核心任务------掩码语言模型,通过预测被掩盖的词汇使模型学习上下文信息,并提及了"下一句预测"任务的局限性及改进方案。其次,文章详细展示了将预训练BERT适配到四大下游任务的范式:文本分类、序列标注、句子对分类以及机器阅读理解,其通用模式是在BERT顶部添加一个简单的任务特定层进行微调。最后,文章探讨了BERT成功的关键在于其能根据上下文生成动态的词向量以区分多义词,但也通过实验指出,BERT的强大表现可能部分源于其强大的模式匹配能力,而非真正理解了深层语义。
Abstract
This article provides a systematic overview of the BERT model's core mechanisms and applications. It begins by explaining BERT's pre-training methodology, focusing on its central task---the Masked Language Model (MLM), which learns contextual information by predicting masked words, and discusses the limitations of the "Next Sentence Prediction" task and its improvements. Subsequently, the article details the paradigm for adapting the pre-trained BERT to four major downstream tasks: text classification, sequence labeling, sentence-pair classification, and machine reading comprehension. The common approach involves adding a simple task-specific layer on top of BERT for fine-tuning. Finally, the article explores the key to BERT's success, which lies in its ability to generate dynamic word vectors based on context to disambiguate words. However, it also points out through experiments that BERT's powerful performance may partly stem from its robust pattern recognition capability rather than a genuine understanding of deep semantics.
目录
[1 BERT训练](#1 BERT训练)
[2 BERT任务](#2 BERT任务)
[3 为什么BERT会成功](#3 为什么BERT会成功)
[4 总结](#4 总结)
1 BERT训练
BERT模型在预训练阶段会采用掩码语言模型(Masked Language Model, MLM)的训练流程。其核心思想是通过人为地"破坏"输入文本,然后训练模型来还原被掩盖的部分,从而让模型学习到深层的语言理解能力。如下图所示。
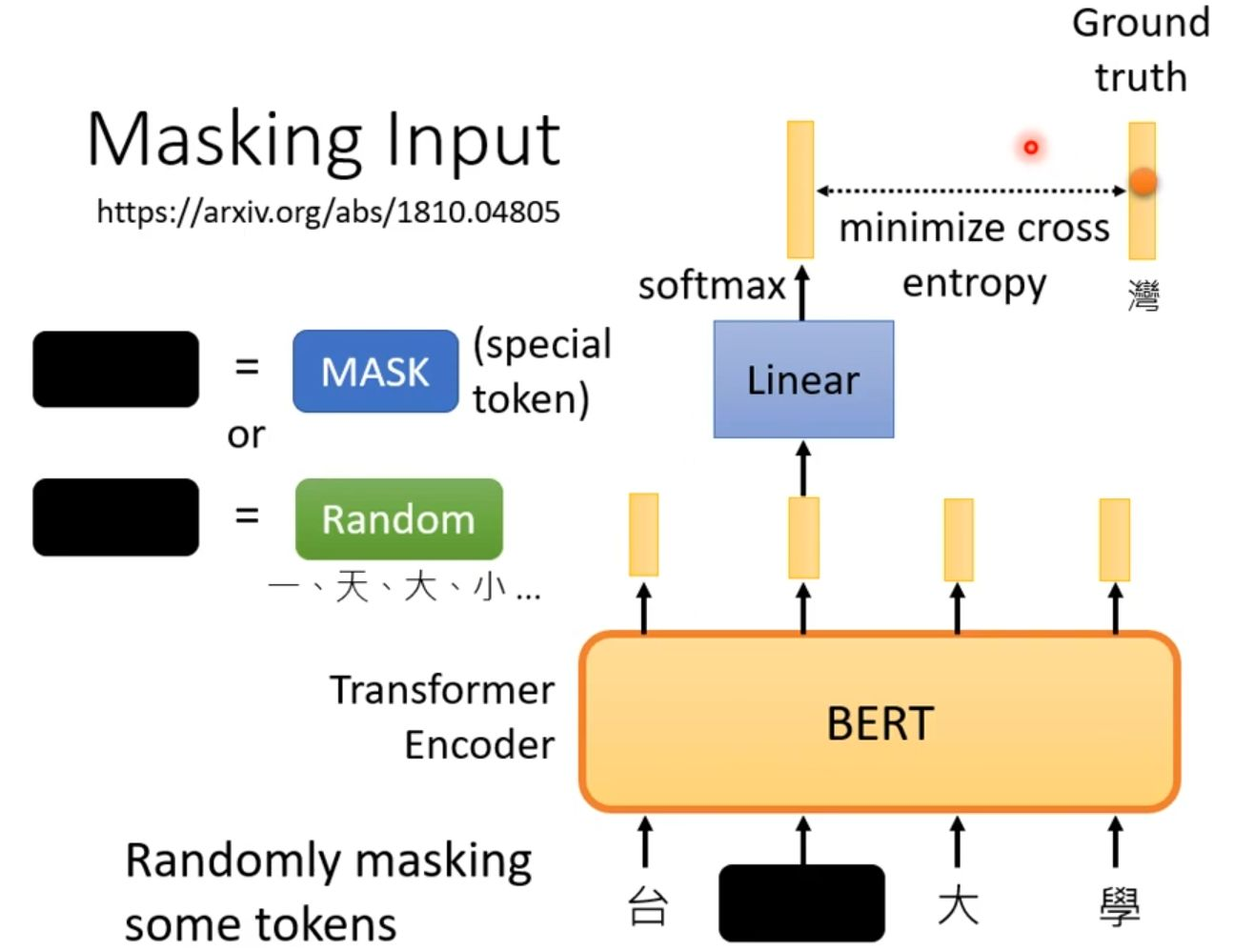
一是直接替换为特殊的[MASK]标记,二是替换为另一个随机词元,以此增加训练的难度和鲁棒性。
这个被部分掩盖的序列随后被送入BERT模型中进行处理。模型需要根据上下文信息来推断被掩盖位置原本应该是什么词。为了完成这个预测任务,BERT顶部的输出会先经过一个线性层(Linear),再进入一个Softmax层,从而在整个词表上产生一个概率分布,预测最可能是哪个词。最后,在流程的右侧,模型对掩盖位置的预测结果(如预测"大"、"學"等)会与真实的标签(Ground Truth,例如"灣"字)进行比较,并通过计算交叉熵损失来评估预测的误差。
整个训练过程就是通过不断最小化这个损失,来驱动BERT模型参数更新,最终使其学会根据上下文准确推断缺失信息,从而获得强大的语言表征能力。
研究人员还用了"下一句话"作为训练,但是效果并不是很好。移除NSP任务并仅使用掩码语言模型进行训练,模型性能反而有所提升。作为改进,ALBERT模型采用了"句子顺序预测"作为替代任务,该任务要求模型判断两个句子的顺序是否被互换。

2 BERT任务
其中,首先的任务是文本分类。
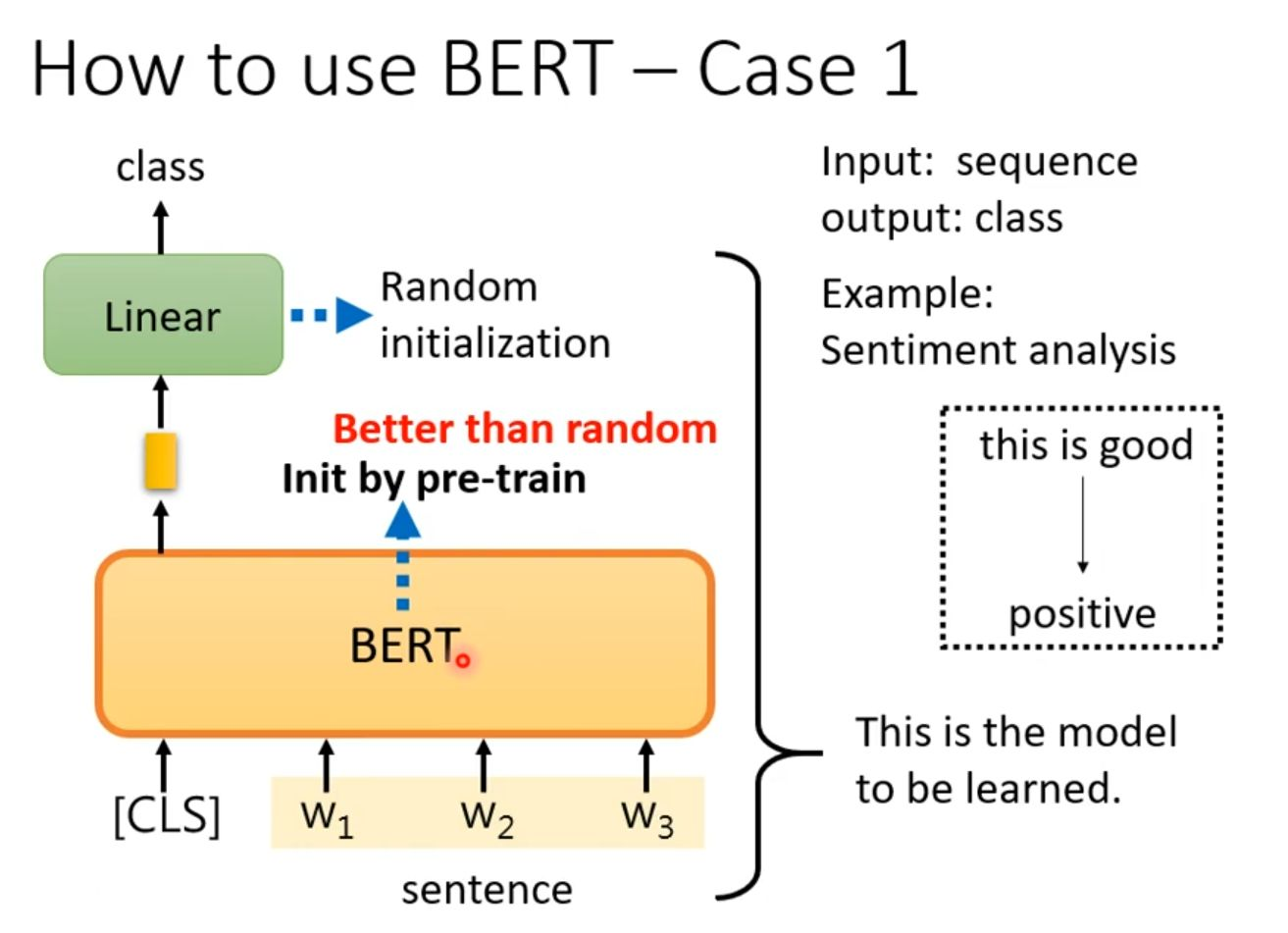
输入句子"this is good"首先被转化为词元序列,并在开头添加了特殊的CLS分类标识符,然后整体输入到的BERT模型中。BERT模型在这里充当了一个强大的特征提取器,其标注"Better than random Init by pre-train"强调了使用在海量数据上预训练好的参数进行初始化,远比随机初始化更能提供高质量的文本表征基础。
冻结或微调BERT的底层参数,并在其顶部接入一个简单的可训练分类网络,从而快速高效地适配到各种具体的文本分类场景。
然后是序列标注任务。
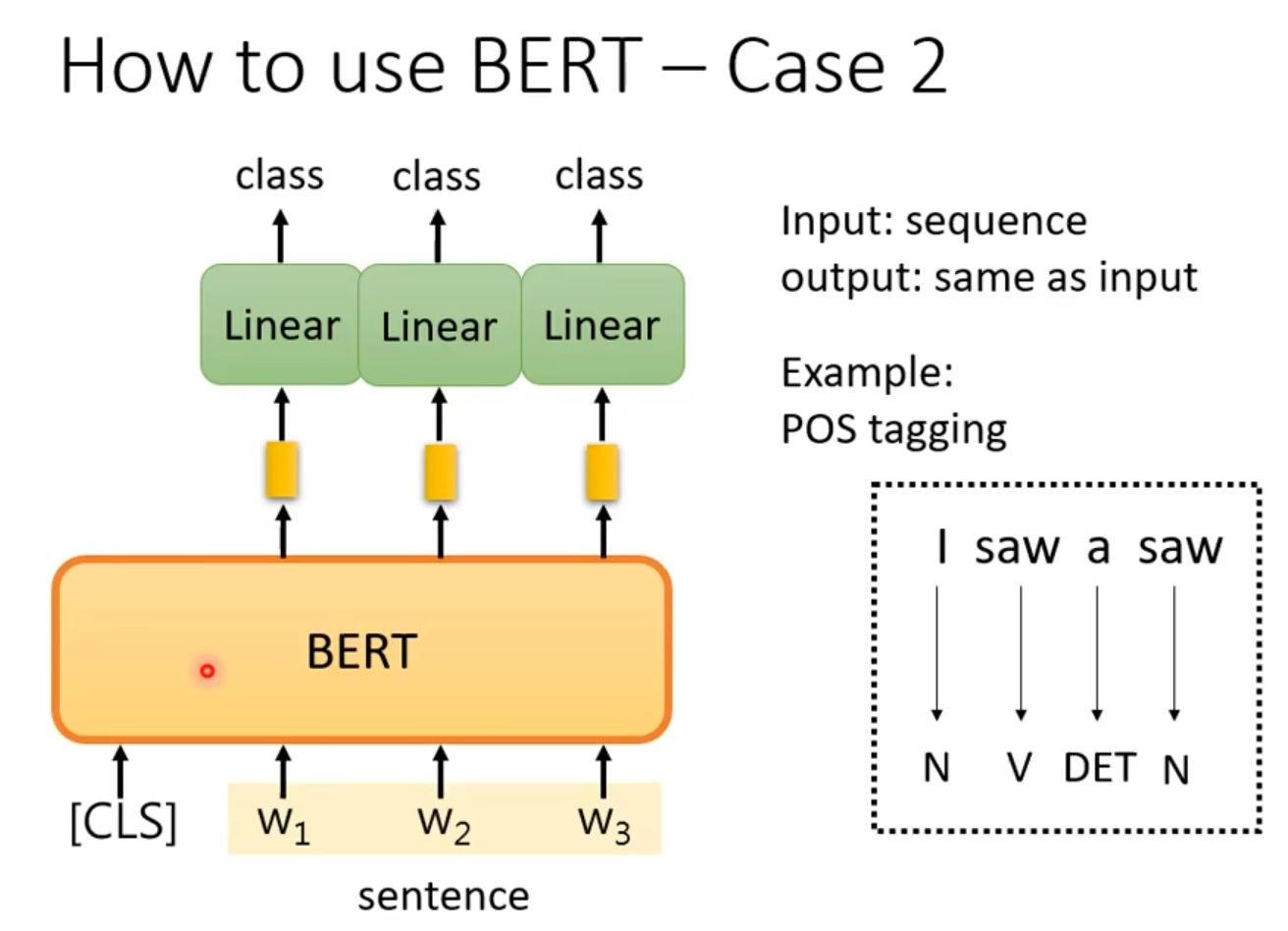
每个词元对应的输出向量被送入其各自的线性分类层,由该分类器判断该词元所属的特定标签。
第三个是对两个句子进行分类。
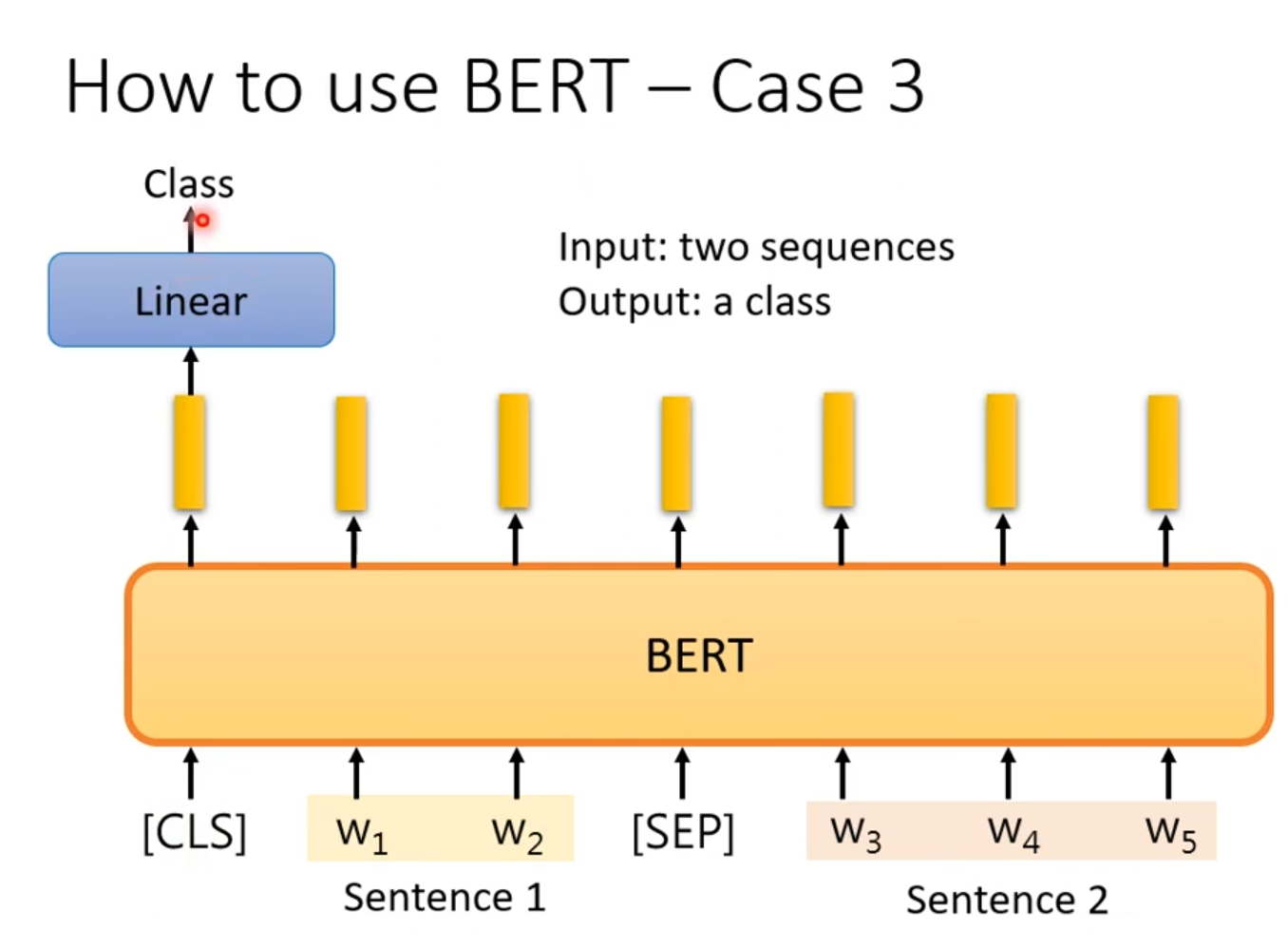
它们被拼接成一个序列,中间用特殊的SEP标记分隔,开头则加上CLS标记。这个完整的序列被送入BERT模型。BERT模型会为序列中的每个词元生成上下文相关的向量表示。其中,位于序列开头的CLS标记的输出向量被视为对整个输入对(即两个句子)的聚合语义表征。
最后,这个CLS向量被送入一个顶部的线性分类器。分类器基于这个富含两个句子信息的向量,判断它们之间的关系,并输出一个具体的类别标签。
最后第四个是机器阅读理解或抽取式问答任务。
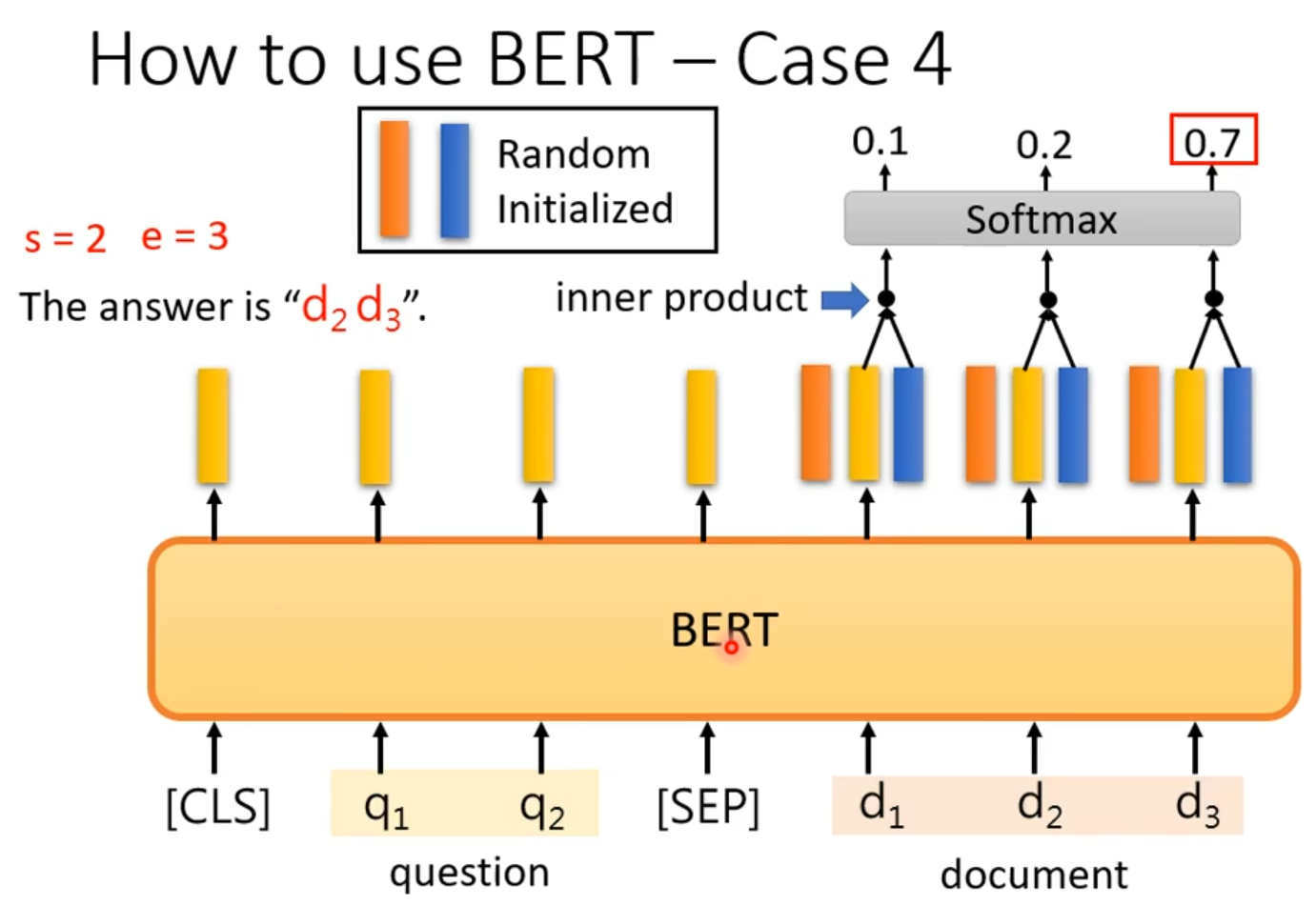
BERT模型处理整个输入序列后,会为文档中的每个词元生成一个输出向量。为了定位答案,图中引入了两个随机初始化的可训练向量。其中,向量与所有文档词元的输出向量进行内积运算,再通过Softmax层,得到每个词元作为答案起始位置(s)的概率分布。
3 为什么BERT会成功
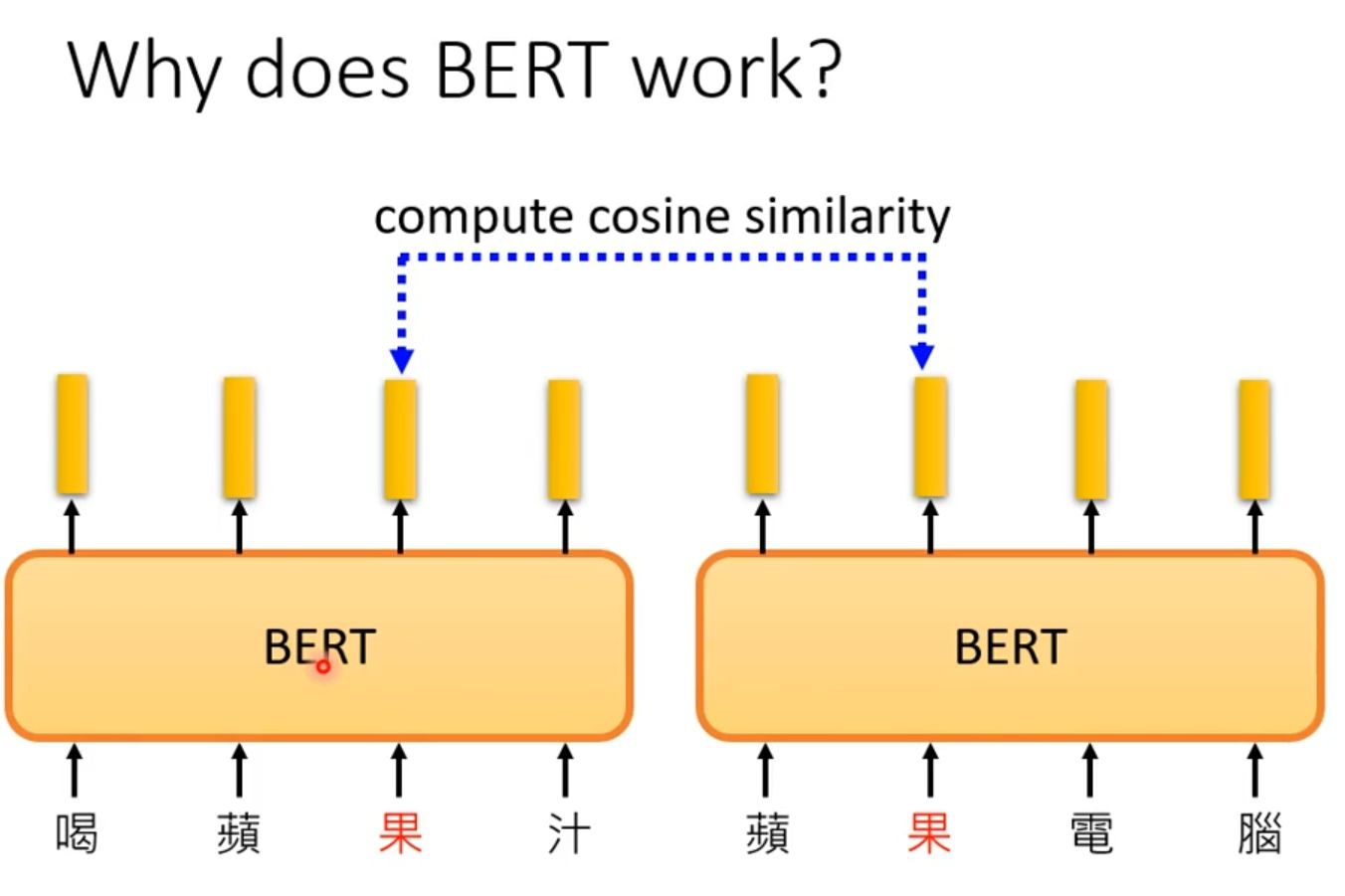
同一个汉字"果"在"喝蘋果汁"和"蘋果電腦"这两个不同的上下文语境中,经过BERT模型处理后,会生成两个不同的特征向量。计算这两个向量的余弦相似度,结果会显示出较低的相似性,这证明BERT成功地将"水果"的"果"和"苹果公司"的"果"区分开来,捕捉到了词汇的多义性。
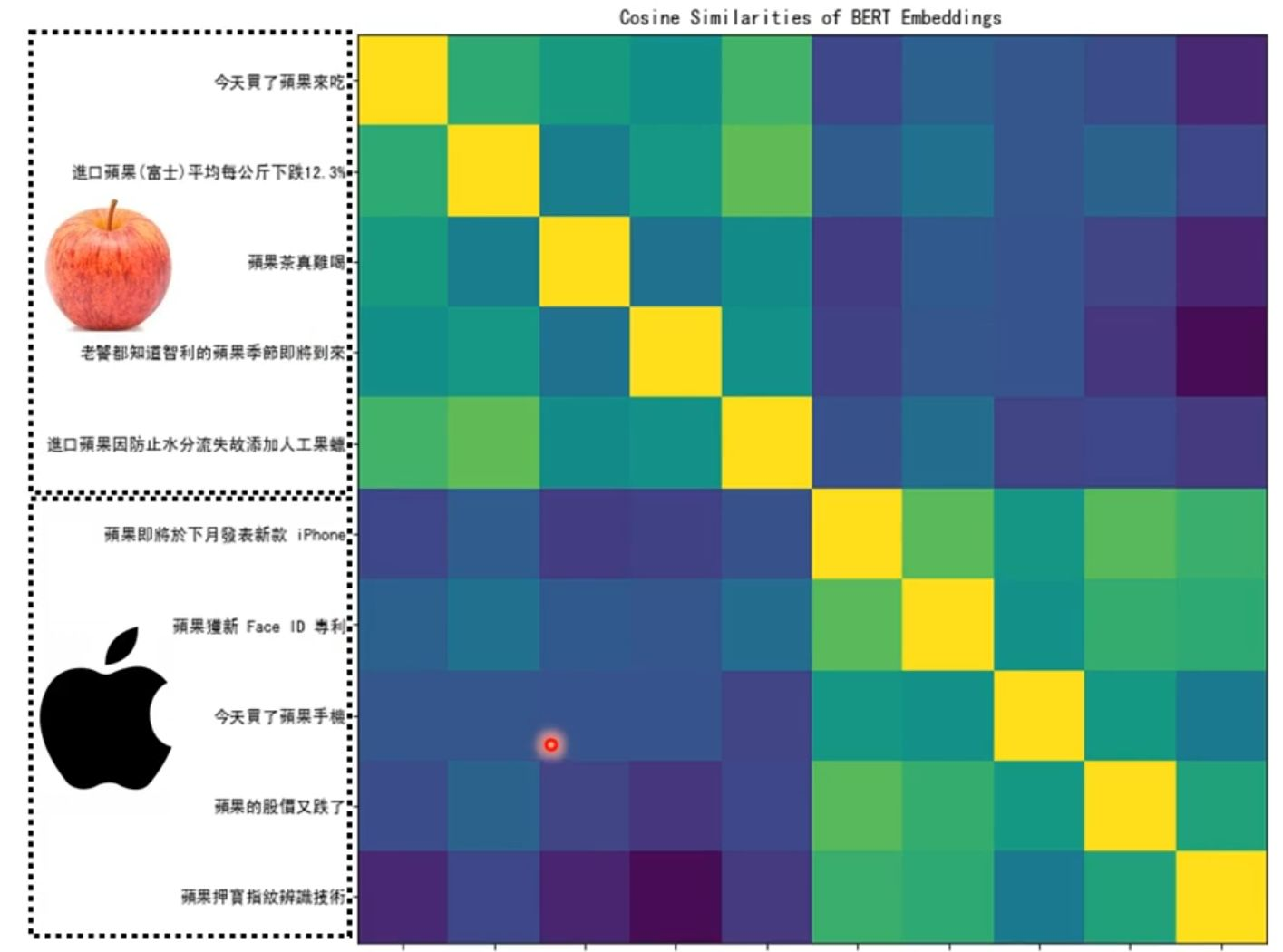
BERT不仅能在单个实例中区分词义,还能在大量文本中系统性地将相同含义的词汇聚类,形成一致的语义空间。
看起来BERT好像懂了语义,但事实是并非如此。BERT连无语义的都能分类很好。
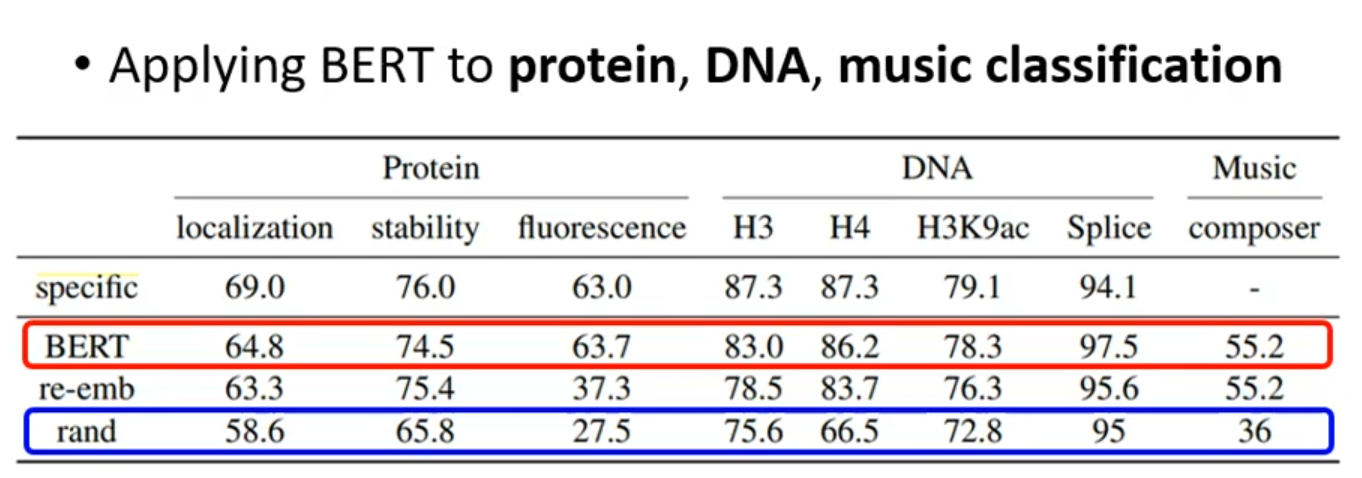
可以看出BERT分类效果比较好。
4 总结
BERT是一个通过预训练-微调范式解决多种NLP任务的强大框架。其成功基石是MLM预训练任务,这让模型学会了深度的上下文感知能力。而在应用时,只需在预训练好的BERT模型上添加一个轻量的任务层进行微调,即可高效地适配到分类、标注、问答等具体场景。需要认识到,BERT的优势是强大的上下文词义区分能力,但其工作原理更偏向于复杂的模式匹配,而非真正的语义理解。