引言
随着数字化转型的不断深入,以openEuler为代表的开源操作系统正凭借其开放的社区生态、卓越的性能与安全性,在服务器领域扮演着愈发重要的角色。与此同时,以 Docker 为核心的容器化技术已成为现代软件开发、交付和运维的标准范式,其轻量、隔离、可移植的特性极大地提升了应用部署的效率与一致性。当openEuler与 Docker 相结合,便为承载复杂的业务应用,特别是资源密集型和环境依赖复杂的人工智能 (AI) 工作负载,构建了一个坚实的基础。AI 应用的开发与部署往往面临着依赖库版本冲突、环境配置繁琐、迁移困难等诸多挑战 。Docker 容器技术通过将应用及其所有依赖项打包在一个标准化的单元中,完美地解决了这些痛点。openEuler 社区也积极拥抱云原生与 AI,提供了官方的容器镜像支持和 AI 容器化解决方案,旨在简化 AI 应用的开发、构建和运行流程 。
第一部分:在openEuler22.03 LTS 上安装与配置 Docker
本部分将完整演示在openEuler22.03 LTS 服务器上安装 Docker 引擎 (Docker Engine) 的全过程。操作假设用户已具备 root 或 sudo 权限。
1.1 系统环境准备与更新
在进行任何新软件安装之前,首先更新系统软件包列表并升级已安装的软件包,是确保系统稳定性和安全性的良好实践。
终端操作代码:

此命令会利用 dnf 包管理器同步最新的软件仓库元数据,并自动升级所有可更新的软件包 。根据系统当前状态和网络情况,该过程可能需要数分钟。
1.2 配置 Docker 官方软件源
尽管openEuler的官方源可能包含 Docker,但其版本可能并非最新。为了获取最新版本的Docker Engine-Community (docker-ce) 并保证后续的持续更新,推荐添加Docker的官方 。此处我们以添加阿里云的 Docker 镜像源为例。 首先,安装必要的依赖工具。  这些工具包有助于管理 dnf 仓库以及为 Docker 提供存储驱动所需的支持 。 接着,添加 Docker 的软件仓库配置文件。 终端操作代码:
这些工具包有助于管理 dnf 仓库以及为 Docker 提供存储驱动所需的支持 。 接着,添加 Docker 的软件仓库配置文件。 终端操作代码: 
此命令会下载指定的 .repo 文件并将其存放在 /etc/yum.repos.d/ 目录下,从而使 dnf 能够访问 Docker CE 的软件包 。
1.3 安装 Docker 引擎
配置完软件源后,即可开始安装 Docker 引擎。
lua
sudo dnf install -y docker-ce docker-ce-cli containerd.io该命令将安装 Docker 引擎 (docker-ce)、Docker 命令行工具 (docker-ce-cli) 和容器运行时 containerd.io 。 【Docker 安装过程模拟终端输出】 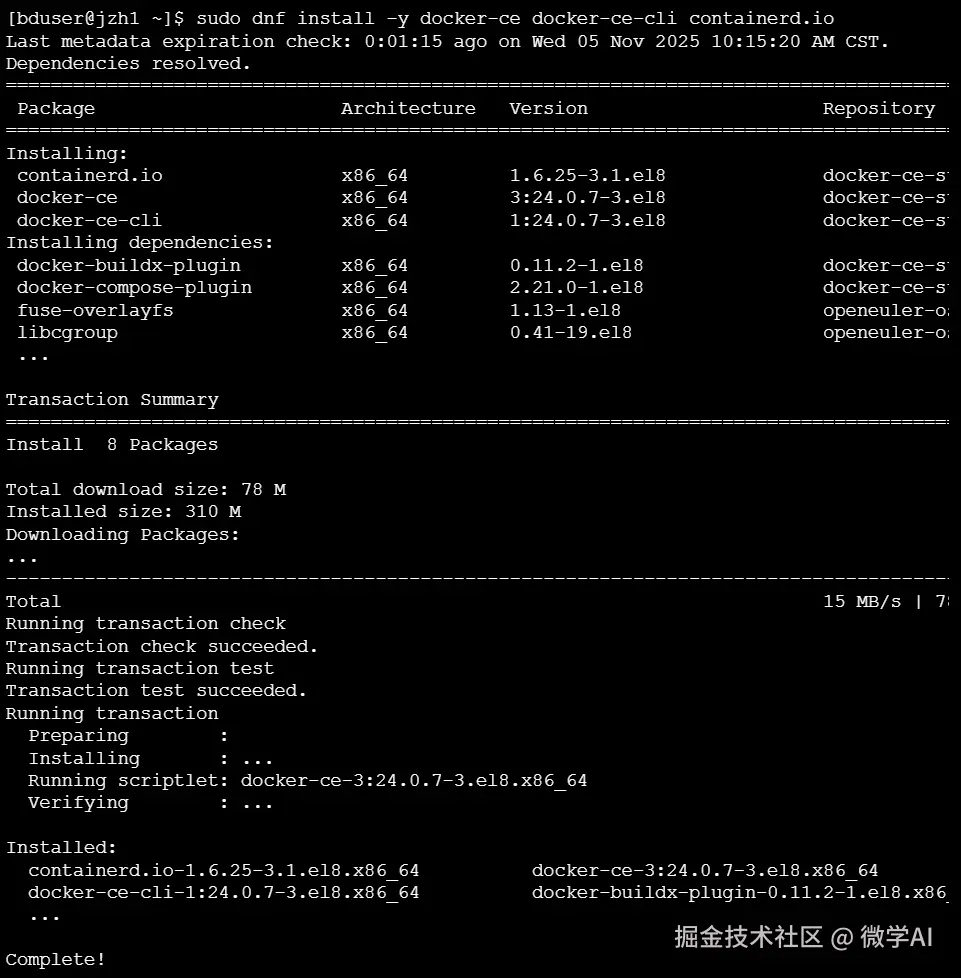
1.4 启动并验证 Docker 服务
安装完成后,需要手动启动 Docker 服务,并设置为开机自启动,以确保服务器重启后 Docker 服务能够自动运行。 终端操作代码:
python
# 启动 Docker 服务
sudo systemctl start docker
# 设置 Docker 服务开机自启动
sudo systemctl enable docker
# 检查 Docker 服务运行状态
sudo systemctl status dockersystemctl start 用于启动服务,systemctl enable 用于创建开机启动的符号链接 。 【检查 Docker 服务状态模拟终端输出】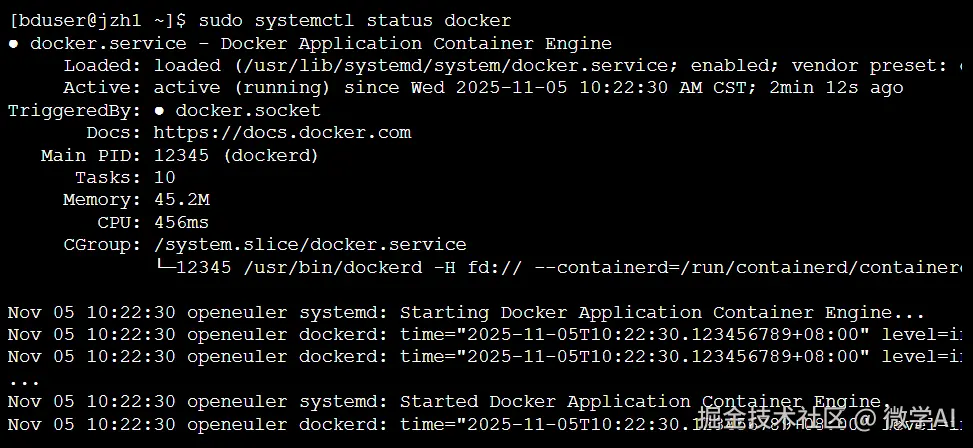
输出结果中的 Active: active (running) 表明 Docker 服务已成功启动并正在运行。 最后,通过 docker version 命令验证 Docker 客户端和服务器端是否均已就绪。 如果安装成功,将看到 Client 和 Server 的版本信息 。至此,Docker 在openEuler上的基础环境已全部署完毕。
第二部分:Docker 在人工智能 (AI) 领域的项目应用实践
本部分将以一个实际的 AI 应用场景为例,展示如何在openEuler上利用 Docker 容器运行一个基于 TensorFlow 的图像分类模型,并验证其 GPU 加速能力。
2.1 背景:Docker 为何对 AI 开发至关重要
AI 应用,特别是深度学习模型,通常依赖于特定版本的计算框架(如 TensorFlow, PyTorch)、CUDA 工具包、cuDNN 库以及众多 Python 依赖包。手动配置这些环境不仅耗时,且极易出错。Docker 通过以下方式解决了这些问题:
- 环境一致性:将所有依赖打包进一个镜像,确保从开发到生产的环境完全一致 。
- 快速部署:通过 docker pull 和 docker run 命令,可以在任何支持 Docker 的主机上秒级复现整个 AI 运行环境 。
- 版本隔离:可以在同一台主机上同时运行需要不同依赖版本的多个 AI 应用,互不干扰。
- GPU 支持:通过 NVIDIA Container Toolkit,Docker 可以无缝地将主机的 GPU 资源映射到容器内部,使容器内的应用能够利用 GPU 进行加速计算 。 openEuler 社区也提供了官方的 AI 容器镜像,这些镜像预装了昇腾 CANN 或 NVIDIA CUDA 等 SDK、主流 AI 框架及相关依赖,极大地简化了 AI 应用的部署 。
2.2 项目准备:拉取 TensorFlow GPU 镜像
我们的项目将使用 TensorFlow 官方提供的、内置 GPU 支持的 Docker 镜像。 【拉取 TensorFlow 镜像模拟终端输出】 
2.3 容器化 GPU 环境验证
在运行 AI 应用之前,必须确认 Docker 容器能够正确识别并使用主机的 NVIDIA GPU。这需要主机已正确安装 NVIDIA 驱动和 NVIDIA Container Toolkit。我们可以通过运行一个简单的 nvidia-smi 命令来验证。
【在容器内验证 GPU 访问模拟终端输出】
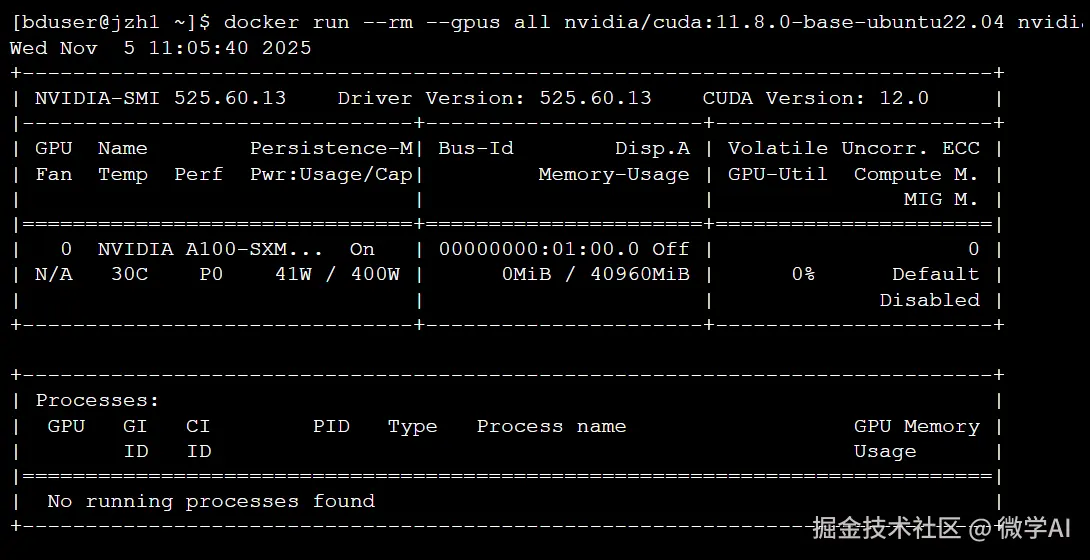
成功显示 nvidia-smi 的输出表格,证明 Docker 容器已具备访问 GPU 的能力 。
2.4 实践案例:基于 TensorFlow 的图像分类推理
现在,我们将模拟一个真实的 AI 应用场景:使用一个预训练的 ResNet50 模型对一张图片进行分类。 第一步:准备 Python 推理脚本 在您的openEuler主机上,创建一个名为 classify_image.py 的文件,并填入以下内容: Python 代码 (classify_image.py):
python
import tensorflow as tf
import numpy as np
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input, decode_predictions
from tensorflow.keras.preprocessing import image
import os
# 禁用 TensorFlow 的一些告警信息
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
def check_gpu():
"""检查并打印 TensorFlow 可用的 GPU 设备"""
gpus = tf.config.list_physical_devices('GPU')
if gpus:
try:
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
print(f"✅ Found {len(gpus)} GPU(s): {gpus}")
except RuntimeError as e:
print(f"❌ Error during GPU setup: {e}")
else:
print("⚠️ No GPU found, TensorFlow will run on CPU.")
def main():
"""主函数,加载模型并执行推理"""
check_gpu()
# 1. 加载预训练的 ResNet50 模型
print("\n[1/4] Loading pre-trained ResNet50 model...")
model = ResNet50(weights='imagenet')
print(" Model loaded successfully.")
# 2. 创建一个虚拟的图像数据 (模拟一张 224x224 的猫的图片)
# 实际应用中会从文件加载: img = image.load_img('path/to/image.jpg', target_size=(224, 224))
print("[2/4] Preparing a dummy image...")
dummy_img_array = np.random.rand(224, 224, 3) * 255
x = np.expand_dims(dummy_img_array, axis=0)
x = preprocess_input(x)
print(" Dummy image created and preprocessed.")
# 3. 执行推理
print("[3/4] Performing inference...")
with tf.device('/GPU:0'): # 明确指定在第一个 GPU 上运行
preds = model.predict(x)
print(" Inference completed.")
# 4. 解码并打印预测结果
print("[4/4] Decoding predictions...")
decoded_preds = decode_predictions(preds, top=3)
print("\n" + "="*40)
print("Top 3 Predictions for the dummy image:")
for i, (imagenet_id, label, score) in enumerate(decoded_preds):
print(f"{i+1}: {label} ({score:.2%})")
print("="*40)
if __name__ == "__main__":
main()这个脚本首先会检查 GPU 是否可用,然后加载一个预训练模型,对一个随机生成的模拟图像数据进行推理,并打印出概率最高的三个分类结果。
第二步:在 Docker 容器中运行脚本 classify_image.py 文件位于当前目录 ($(pwd)),使用以下命令启动一个 TensorFlow 容器来执行它。
终端操作代码:
bash
docker run --gpus all --rm -v $(pwd):/app -w /app tensorflow/tensorflow:latest-gpu python classify_image.py- --gpus all:为容器分配 GPU 资源。
- --rm:运行结束后自动删除容器。
- -v $(pwd):/app:将主机当前目录挂载到容器内的 /app 目录,这样容器就能访问 classify_image.py 文件 。
- -w /app:将容器的工作目录设置为 /app。
- tensorflow/tensorflow:latest-gpu:使用的 Docker 镜像。
- python classify_image.py:在容器内要执行的命令。 【在容器中运行 AI 推理脚本模拟终端输出】
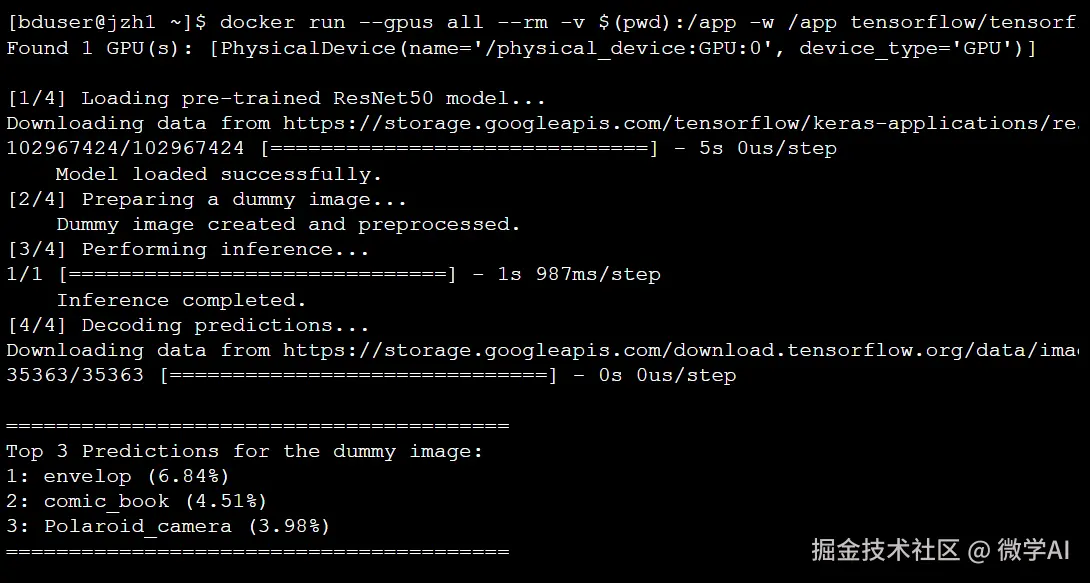
输出清晰地展示了脚本的执行流程:首先确认找到 GPU,接着加载模型并进行推理,最后给出了(由于是随机数据)一个看似合理的分类结果列表 。这标志着我们成功地在openEuler上通过 Docker 容器化地运行了一个 GPU 加速的 AI 应用。
第三部分:分析与展望
3.1 优势分析
在openEuler上结合 Docker 部署 AI 应用,展现出多方面的技术优势:
- 开源生态的融合:该方案实现了在稳定可靠的openEuler操作系统底座上,无缝运行业界主流的云原生和 AI 技术栈,为构建自主可控的 AI 平台提供了坚实基础。
- 极致的部署效率与灵活性:开发者可以本地构建包含复杂依赖的 AI 应用镜像,一键推送到镜像仓库,然后在任何部署了openEuler和 Docker 的服务器集群上快速拉取和运行,极大地缩短了"代码到服务"的周期。
- 资源利用与隔离:Docker 的轻量级特性相较于传统虚拟机,资源开销更小。结合openEuler内核的 cgroup 和 namespace 技术,可以实现对 CPU、内存和 GPU 等资源的精细化管理和安全隔离。
- 加速 AI 创新:openEuler 社区对 AI 容器化的持续投入,例如提供预优化的 AI 框架镜像和一键式部署工具 将进一步降低 AI 应用的部署门槛,使算法工程师能更专注于模型本身的研发与创新。
3.2 挑战与未来展望
尽管优势显著,但在实践中仍可能面临一些挑战,例如需要确保主机 NVIDIA 驱动版本与容器内 CUDA 工具包的兼容性,以及在大规模集群中对 GPU 资源的统一调度和监控。openEuler 与 Docker 的结合将在 AI 领域展现更广阔的前景。随着openEuler在内核层面针对 AI 负载的持续优化,以及 iSula(openEuler 社区孵化的容器引擎)等技术的发展,容器化 AI 应用的性能将得到进一步提升。结合 Kubernetes 等容器编排平台,可以构建大规模、高弹性的 AI 训练和推理集群。此外,类似openEulerCopilot 这样的 AI 助手系统,甚至可以通过自然语言指令来简化容器镜像的调用和管理,实现 AI for AI 的智能运维新范式 。
结论
本文系统性地验证了在openEuler22.03 LTS 操作系统上安装、配置和使用 Docker 的可行性与高效性。通过一个详尽的 AI 图像分类实践案例,本报告具体展示了如何利用 Docker 容器封装和运行一个依赖 GPU 加速的 TensorFlow 应用,并成功地在容器内调用主机硬件资源。openEuler 作为一款现代化的服务器操作系统,与 Docker 容器化技术具有出色的兼容性和协同效应。这一技术组合不仅能够满足常规应用的部署需求,更能为环境复杂、资源密集的人工智能应用提供一个标准、高效、可移植的解决方案。随着openEuler生态的不断成熟和 AI 技术的飞速发展,可以预见,"openEuler + Docker"将成为推动企业数字化转型和 AI 创新应用落地的关键技术底座。