在日常开发中,API 调度任务的稳定性至关重要。无论是定时数据同步、服务健康检查还是业务自动化,一旦 API 执行异常,往往会引发连锁反应。最近接触到的SpringBoot-API-Scheduler项目,通过 "断言验证 + 警报通知" 的组合功能,完美解决了 API 调度中的监控痛点。今天就从实战角度,聊聊这两个功能如何帮我们构建 API 监控闭环。
➡️开源项目 :https://github.com/moshowgame/springboot-api-scheduler,里面有更详细的配置文档和示例,动手试试,让你的 API 调度更可控!
为什么需要断言验证?单次执行的 "健康码"
在 API 调度场景中,我们常遇到这样的问题:任务明明执行了,却因为响应不符合预期(比如状态码 500、关键字段缺失)导致后续流程失败。传统的日志记录只能告诉你 "执行过",却不能告诉你 "执行对了"。
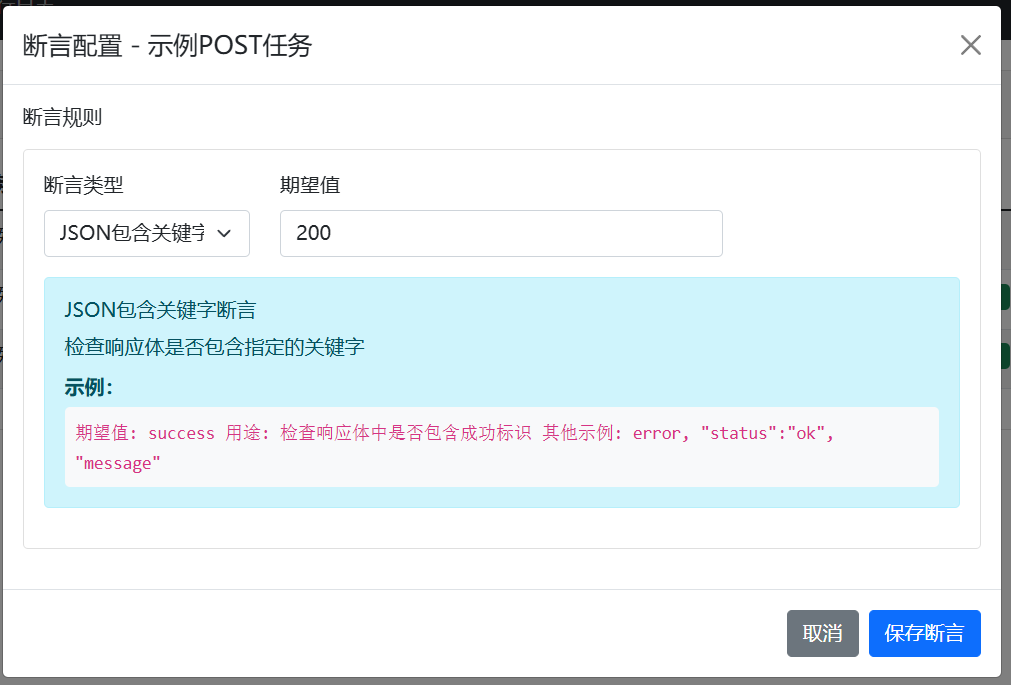
SpringBoot-API-Scheduler的断言验证功能 ,就是给单次 API 执行贴 "健康码" 的工具。它的核心价值在于:用规则定义 "什么是正常响应",并自动判断执行结果是否符合预期。
实战中常用的 3 种断言规则
-
HTTP 状态码断言
:最基础也最常用,比如要求响应状态码必须为 200
-
JSON 关键字断言
:检查响应体中是否包含关键业务字段(如
"status":"success") -
JSON 路径断言
:通过 JSONPath 表达式精准验证字段值(如
$.data.total > 100)
配置步骤(3 分钟上手)
-
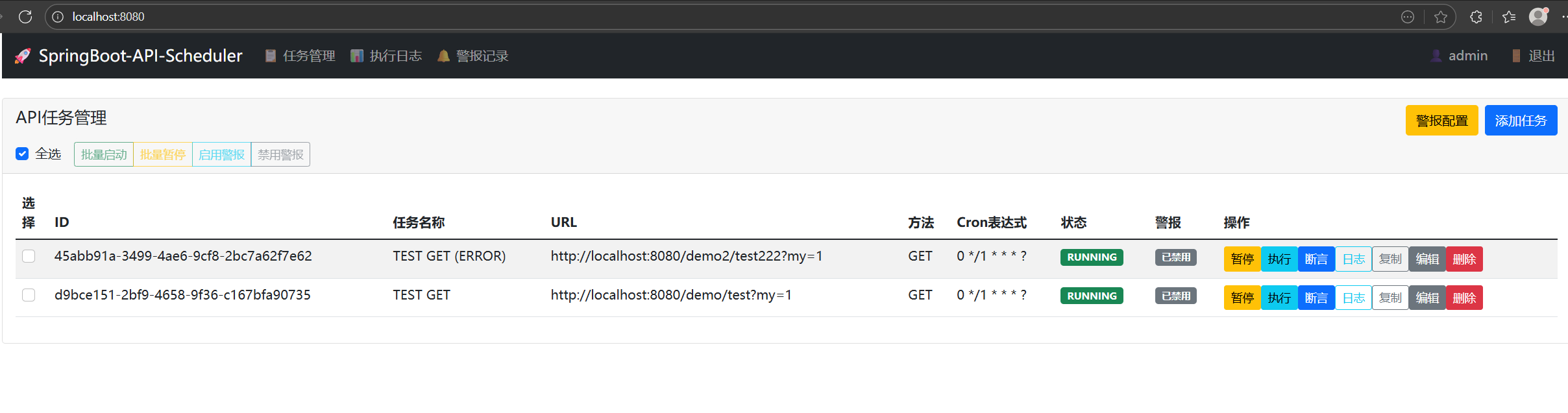
进入任务管理页面,找到目标任务点击 "断言" 按钮
-
选择断言类型,填写期望值(比如状态码填 200)
-
保存配置后,任务每次执行都会自动进行断言校验
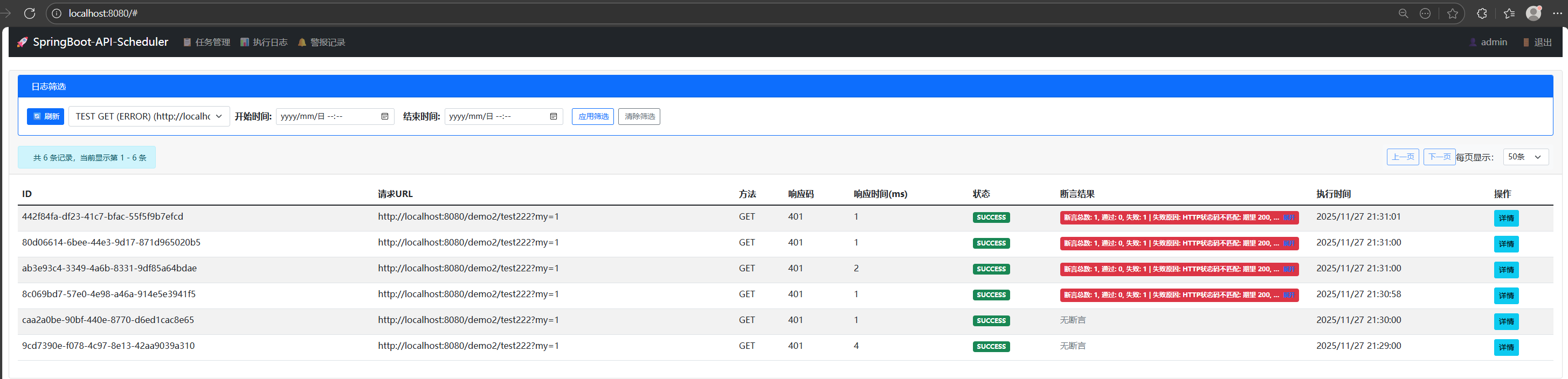
断言结果会实时显示在日志中,一眼就能区分 "执行成功但结果异常" 的情况,避免问题被隐藏。
从单次验证到批量监控:警报功能的实战价值
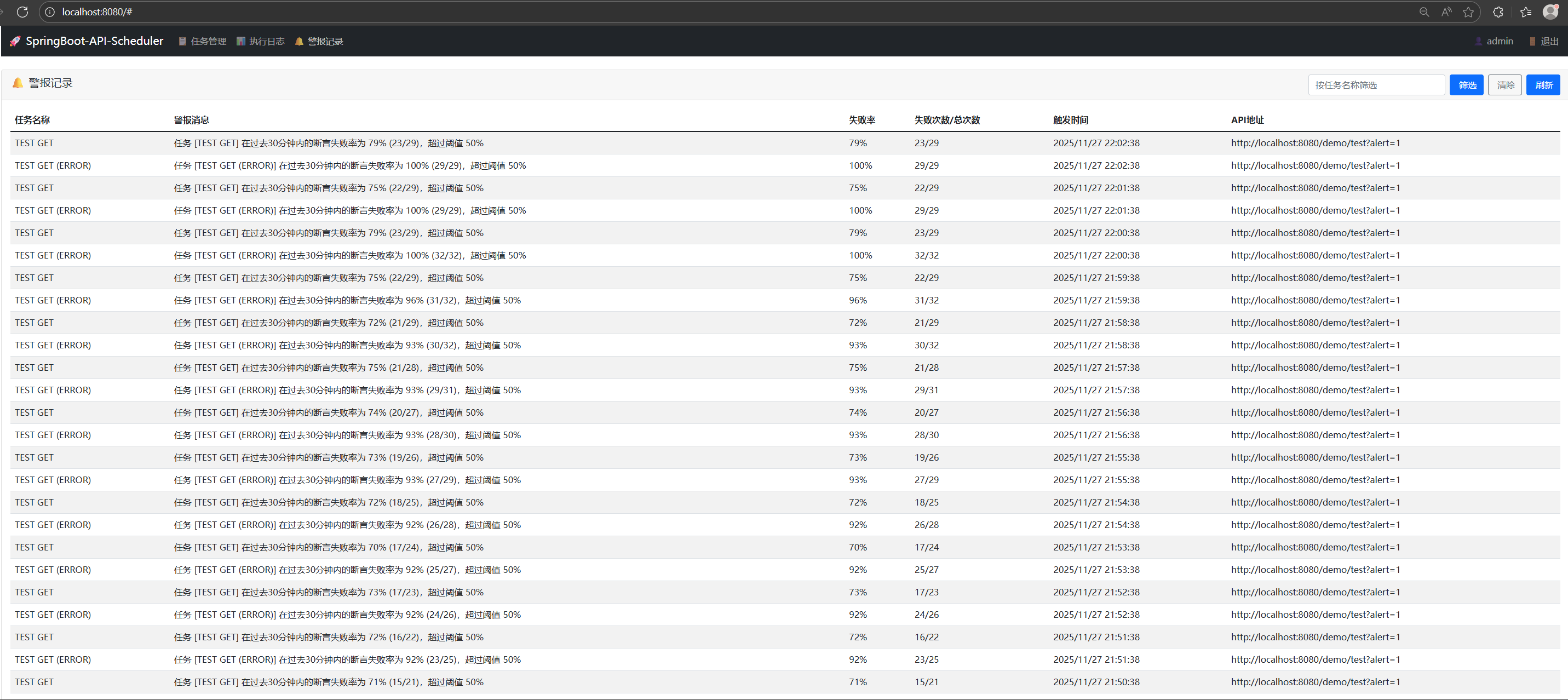
断言解决了 "单次执行是否正常" 的问题,但在实际场景中,我们更关注 "一段时间内的整体稳定性"。比如:某 API 偶尔失败是网络波动,但 30 分钟内失败率超 50%,很可能是服务出了问题。

2025 年 11 月 27 日上线的Alert 警报功能,正是为了应对这种场景。它不是单次失败就告警,而是通过 "失败率阈值 + 时间窗口" 的组合策略,智能判断是否需要通知,避免 "告警风暴"。
警报功能的核心逻辑
-
周期性检查
:系统每小时自动扫描所有启用警报的任务
-
失败率计算
:统计 "时间窗口" 内(如 30 分钟)的断言失败次数占比
-
阈值触发
:当失败率超过设定值(如 50%),立即向指定 API 发送通知
-
全量记录
:所有警报事件自动存档,支持后续分析复盘
实战配置关键参数
-
失败率阈值
:根据业务容忍度设置,核心 API 建议 10%-30%,非核心可放宽至 50%
-
时间窗口
:与任务执行频率匹配(如每 5 分钟执行一次的任务,窗口设 30 分钟更合理)
-
通知 API
:建议配置能转发至邮件 / 企业微信的接口,比如用
{"taskName":"${taskName}","failureRate":"${failureRate}"}作为请求体,变量会自动填充实际数据
避坑指南
-
警报未触发?先检查任务是否启用警报,再确认时间窗口内有执行记录
-
通知 API 收不到消息?排查 URL 正确性、请求头格式(尤其是 Content-Type)
-
告警太频繁?可提高阈值或扩大时间窗口,避免短时波动误触发
两者协同:构建 API 监控的完整闭环
断言验证和警报功能不是孤立的,而是形成了 "即时检查 - 批量分析 - 异常通知" 的闭环:
-
断言负责 "微观监控",确保每一次执行都符合预期
-
警报负责 "宏观监控",捕捉一段时间内的趋势性异常
-
配合完整的日志记录,既能定位单次失败原因,也能分析长期稳定性问题
如果你正在寻找轻量级的 API 调度监控方案,SpringBoot-API-Scheduler的这两个功能值得一试。无需复杂配置,开箱即用,特别适合中小团队或非核心业务的 API 监控场景。
➡️开源项目 :https://github.com/moshowgame/springboot-api-scheduler,里面有更详细的配置文档和示例,动手试试,让你的 API 调度更可控!
Powered by Moshow 郑锴 🚀 | Might the holy code be with you !
👉 公众号「软件开发大百科」🌟 | CSDN传送门:https://zhengkai.blog.csdn.net/