一、项目背景与目标
在当前的智能客服和 AI 交互场景中, "数字人" 已成为提升用户体验的重要手段。我们团队开发了一款基于 UniApp + Vue3 的微信小程序,核心功能是通过语音或文字与 AI 进行健康咨询。
为了增强交互感与亲和力,我们引入了 SVGA 格式的 3D 数字人动画,并实现了:
- ✅ AI 回复通过 TTS 生成 PCM 音频流
- ✅ 音频边接收边播放(流式处理)
- ✅ 数字人"说话"动画与语音同步
- ✅ 语音结束自动切回待机动画
- ✅ 全程丝滑过渡,无动画突变或打断
在这里大家肯定会问:做数字人为什么不用three.js呢?在项目初期,我也尝试在微信小程序使用 three-platformize.js 通过加载GLB 3D模型的方式去实现,但是在实际场景中发现了以下几个问题:
- GLB 模型体积较大,在微信小程序中加载渲染会比较慢
- 在对模型进行灯光处理时和web端差别较大,难以达到和web端一致的效果
- 微信小程序渲染对模型要求较高
二、整体架构设计
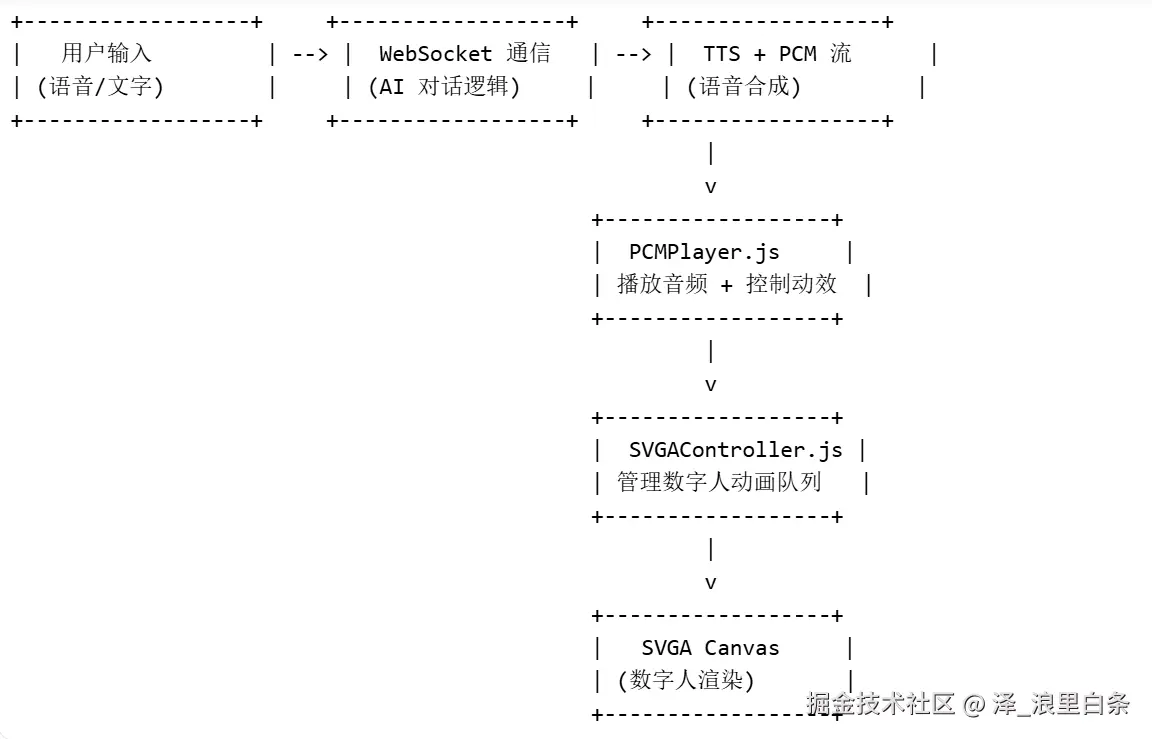
三、关键技术实现
1. SVGA 数字人动画控制:SVGAController.js
我基于svgaplayer-weapp.js封装了一个 SVGAController 类,用于管理动画的播放、暂停、队列执行与循环。其中动画执行使用startAnimationWithRange函数来执行指定范围的动画。
核心功能:
- 初始化加载 SVGA 文件
- 支持分段动画播放 (如
0-100帧为待机,229-428帧为说话) - 动画队列管理(先进先出)
- 默认动画循环(所有动画播完后自动循环默认动画)
js
// src/utils/SVGAController.js
class SVGAController {
constructor(canvasSelector) {
this.canvasSelector = canvasSelector;
this.player = null;
this.parser = null;
this.animationsQueue = [];
this.isPlaying = false;
this.defaultAnimation = null;
}
async init(svgaUrl) {
this.parser = new Parser();
this.player = new Player();
await this.player.setCanvas(this.canvasSelector);
const videoItem = await this.parser.load(svgaUrl);
await this.player.setVideoItem(videoItem);
}
addAnimation(startFrame, endFrame, durationSeconds, singleDuration) {
const repeatCount = Math.round(durationSeconds / singleDuration);
this.animationsQueue.push({ startFrame, endFrame, repeatCount });
if (!this.isPlaying) this._playNextAnimation();
}
async _playNextAnimation() {
if (this.animationsQueue.length === 0 && this.defaultAnimation) {
this.animationsQueue.push({...this.defaultAnimation});
}
const task = this.animationsQueue.shift();
// ... 逐帧播放 logic
}
}✅ 优势:解耦动画逻辑,支持动态添加,避免硬编码。
避坑:pauseAnimation() 导致 startAnimationWithRange 报错
在执行动画暂停后、执行动画停止后、当前有动画在执行,这三种情况下如果需要再次执行任何动画会报错,如下面这段代码:
js
this.player.pauseAnimation();
this.player.startAnimationWithRange(range, true);
// 报错信息为
TypeError: Cannot read property 'width' of undefined报错原因是pauseAnimation() 内部可能释放了 context,导致后续操作失败。因此我无法做到非常及时的切换模型动画,只能使每个动画段尽量的短,从而保证每个动画执行及时准确,当然这种过渡也是有好处的,我们的动画衔接会非常自然,不会突然变换。
2. PCM 音频流播放:PCMPlayer.js
AI 返回的 TTS 语音是 PCM 格式 的二进制流,我们需要边接收边播放。
核心挑战:
- PCM 数据是分段接收的
- 无法预知总时长
- 需要与 SVGA 动画同步
解决方案:
我们封装了 PCMPlayer 类,基于 wx.createWebAudioContext() 实现流式播放。
js
// src/utils/PCMPlayer.js
export class PCMPlayer {
constructor(config) {
this.context = null;
this.currentSource = null;
this.playQueue = [];
this.currentGroup = [];
this.isDestroyed = false;
this.groupSize = 22; // 接收22段音频流再合并播放
}
feed(data) {
if (data === 'stop') {
// 流结束
} else if (data === 'end') {
// 播放结束清理
} else if (data instanceof ArrayBuffer) {
this.currentGroup.push(data);
if (this.currentGroup.length >= this.groupSize) {
this._processCurrentGroup();
this.currentGroup = [];
}
if (!this.isPlaying) this._playNext();
}
}
_processCurrentGroup() {
const merged = this._concatPCM(this.currentGroup);
const audioBuffer = this._pcmToAudioBuffer(merged);
this.playQueue.push(audioBuffer);
}
_playNext() {
const buffer = this.playQueue.shift();
// 创建 sourceNode 并播放
}
}✅ 关键点:
- 使用
groupSize合并多段 PCM,减少AudioBuffer创建频率 - 根据每组的音频时间和动画时间按比例添加动画
- 最后一段动画播放完毕之后循环播放静默动画
3. 音画同步:语音播放时启动"说话"动画
这是最核心的交互体验。
实现逻辑:
| 阶段 | 行为 |
|---|---|
| 第一段 PCM 到达 | 启动 SVGA 说话动画 |
| 按组接收PCM音频流 | 接收groupSize段音频流之后合并播放 |
| 按比例添加动画 | 根据每组音频播放时间和模型说话动画时间按比例添加动画 |
| 当前动画循环播完 | 自动切回默认动画 |
避坑:每段 AudioBuffer 之间播放不流畅
在创建的AudioBuffer过多并且音频段过短的情况下会出现每段之间播放不流畅甚至出现爆音的情况,这也是为什么要合并多端PCM的原因了,合并之后播放的效果就好很多了。当然如果有小伙伴还有更好的播放机制可以一起交流讨论一下。
我们项目最开始的音频格式是OPUS音频流,但是微信小程序不支持对OPUS音频流的播放和解析所以要求后端同学把格式转换成了PCM,在音频格式这一块需要注意,不然就像我一样为了转换格式花了很多时间,最后还是没能实现。
四、经验总结与建议
| 问题 | 经验总结 |
|---|---|
| SVGA 动画卡顿 | 避免频繁强行切换,可合按比例添加动画 |
| 音频播放 | 使用 WebAudioContext 而非 audio 标签 |
| 内存泄漏 | destroy() 时清理 setInterval、WebSocket、WebAudioContext |
| 兼容性 | svgaplayer-weapp 在不同小程序平台表现不同,建议测试 |
| 合理的处理音频流 | 根据实际情况去调整自己的播放机制,避免出现卡顿和爆音 |
五、未来优化方向
- 支持多语言 TTS:根据用户语言切换语音与动画
- 优化语言播放机制:优化语言播放机制,能够及时流畅的播放音频流
- 表情同步:不同情绪对应不同 SVGA 动画
- 唇形同步 :更精细的口型匹配
- 离线包:缓存 SVGA 文件,提升加载速度
六、结语
通过本次开发,我们成功实现了 "AI 语音 + 数字人动画" 的深度融合,显著提升了小程序的交互体验。关键在于:
- 解耦设计:将音频、动画、通信逻辑分离
- 流式处理:PCM 边接收边播放
- 状态同步:通过标志位实现音画协同
- 避坑实践 :不用
pauseAnimation,改用stepToFrame
上述代码只是提供了思路,并不是完整的代码,如果有需要也可以联系我共同探讨。
希望本文能为正在开发数字人、语音交互类应用的开发者提供有价值的参考。