前言
storm的单个搭建以及集群搭建在csdn上已经有博客记录了,但是案例实现却没有写,同时这次实验老师的文档里面并没有记录清楚最后的效果是什么样,以及也没有给pom环境,导致实现起来会有点迷茫,本篇博客就是旨在带领大家实现案例。
pom文件
这里我给出我的maven的环境文件,大家可以根据这个文件进行修改自己的pom
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>storm_project</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- ========== 添加 Storm 相关依赖 ========== -->
<!-- Apache Storm Core -->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>2.8.2</version>
<!-- 本地测试时注释掉 provided,集群部署时取消注释 -->
<!-- <scope>provided</scope> -->
</dependency>
<!-- Storm Kafka Integration -->
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka-client</artifactId>
<version>2.8.2</version>
</dependency>
<!-- Kafka Clients (确保版本兼容) -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.4.0</version>
</dependency>
<!-- 添加SLF4J日志实现,解决SLF4J警告 -->
<!-- <dependency>-->
<!-- <groupId>org.slf4j</groupId>-->
<!-- <artifactId>slf4j-simple</artifactId>-->
<!-- <version>1.7.36</version>-->
<!-- </dependency>-->
<!-- 添加Apache Commons依赖 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
</dependencies>
</project>DataSourceSpout2类
这个类的目的是从csv中读取数据,需要修改的地方就是文件的路径文件的目录,以及文件的编码格式,编码格式错误可能导致乱码。
this.fileNames = Arrays.asList("E:\Real-time\experiment\two\lab2-data\stock-part1.utf8.csv",
"E:\Real-time\experiment\two\lab2-data\stock-part2.utf8.csv");#文件路径
this.directoryPath = "E:\Real-time\experiment\two\lab2-data";#文件目录
InputStreamReader isr = new InputStreamReader(fis, "UTF-8");#文件编码格式
java
package org.example;
//import org.apache.storm.shade.org.apache.commons.lang.StringUtils;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.io.*;
import java.util.*;
/**
* 从产生的股票文件中读取数据
*/
public class DataSourceSpout2 extends BaseRichSpout {
private SpoutOutputCollector spoutOutputCollector;
private Set<String> processedData; // 用于存储已处理的数据
private BufferedReader reader; // 文件读取器
private List<String> fileNames;
private String directoryPath;
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector
spoutOutputCollector) {
this.spoutOutputCollector = spoutOutputCollector;
this.processedData = new HashSet<>();
this.fileNames = Arrays.asList("E:\\Real-time\\experiment\\two\\lab2-data\\stock-part1.utf8.csv",
"E:\\Real-time\\experiment\\two\\lab2-data\\stock-part2.utf8.csv");
this.directoryPath = "E:\\Real-time\\experiment\\two\\lab2-data";
}
@Override
public void nextTuple() {
File directory = new File(directoryPath);
File[] files = directory.listFiles((dir, name) -> name.toLowerCase().endsWith(".csv"));
if (files != null) {
for (File file : files) {
try {
FileInputStream fis = new FileInputStream(file);
InputStreamReader isr = new InputStreamReader(fis, "UTF-8");
BufferedReader reader = new BufferedReader(isr);
// 跳过第一行
reader.readLine();
String line;
while ((line = reader.readLine()) != null) {
if (!processedData.contains(file.getName() + ":" + line)) {
spoutOutputCollector.emit(new Values(file.getName(),
line));
processedData.add(file.getName() + ":" + line);
}
}
reader.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
// 添加适当的延迟,以避免循环过快
Utils.sleep(1000);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("key", "message"));
}
}WriteTopology类
这个类是实现将刚刚得到的数据发送给kafka的
修改kafka地址
private static final String BOOTSTRAP_SERVERS = "192.168.43.219:19092"; //kafka 地址,这个地址跟flink实验里面填写的相同就可以。
修改话题名
private static final String TOPIC_NAME = "foo";#这里要注意本实验需要一个唯一的话题名,在这里以及后面的文件和kafka中填写相同的话题名
添加nimbus地址
config.put("nimbus.seeds", Arrays.asList("192.168.43.219")); // 这里是我自己添加的,由于我的代码会报错找不到nimbus在这里添加之后写上自己的ip就可以找到了
java
package org.example;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.kafka.bolt.KafkaBolt;
import org.apache.storm.kafka.bolt.mapper.FieldNameBasedTupleToKafkaMapper;
import org.apache.storm.kafka.bolt.selector.DefaultTopicSelector;
import org.apache.storm.topology.TopologyBuilder;
import java.util.Arrays;
import java.util.Properties;
/**
* 将读取到的数据分发到 Kafka 中
*/
public class WriteTopology {
// private static final String BOOTSTRAP_SERVERS = "192.168.43.219:9092"; //kafka 地址
private static final String BOOTSTRAP_SERVERS = "192.168.43.219:19092"; //kafka 地址
private static final String TOPIC_NAME = "foo";
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
// 定义 Kafka 生产者属性
Properties props = new Properties();
/*
* 指定 broker 的地址清单,清单里不需要包含所有的 broker 地址,生产者会从
给定的 broker 里查找其他 broker 的信息。
* 不过建议至少要提供两个 broker 的信息作为容错。
*/
props.put("bootstrap.servers", BOOTSTRAP_SERVERS);
/*
* acks 参数指定了必须要有多少个分区副本收到消息,生产者才会认为消息写
入是成功的。
* acks=0 : 生产者在成功写入消息之前不会等待任何来自服务器的响应。
* acks=1 : 只要集群的首领节点收到消息,生产者就会收到一个来自服务器成
功响应。
* acks=all : 只有当所有参与复制的节点全部收到消息时,生产者才会收到一个
来自服务器的成功响应。
*/
props.put("acks", "all");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
KafkaBolt bolt = new KafkaBolt<String, String>()
.withProducerProperties(props)
.withTopicSelector(new DefaultTopicSelector(TOPIC_NAME))
.withTupleToKafkaMapper(new
FieldNameBasedTupleToKafkaMapper<>());
builder.setSpout("sourceSpout", new DataSourceSpout2(), 2).setNumTasks(3);
builder.setBolt("kafkaBolt", bolt,
2).shuffleGrouping("sourceSpout").setNumTasks(3);
Config config = new Config();
config.setNumWorkers(2);
config.setDebug(true);
config.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1000);//允许 Spout 在处
// 理数据时保持更多的未处理数据,确保持续地从数据源中读取数据
// 添加 Nimbus 配置
config.put("nimbus.seeds", Arrays.asList("192.168.43.219")); // 根据实际情况调整
if (args.length > 0 && args[0].equals("cluster")) {
try {
StormSubmitter.submitTopology("StormClusterWritingToKafkaClusterApp", config,
builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException |
AuthorizationException e) {
e.printStackTrace();
}
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LocalWritingToKafkaApp",
config, builder.createTopology());
}
}
}阶段性验收
在编写好这两个文件之后就可以进行阶段性验收运行WriteTopology类,在kafka里面打开一个kafka,创建一个消费者,查看是否有收到消息,如果成功就可以继续下一步。
bash
docker exec -it kafka2 /bin/bash
bash
kafka-console-consumer.sh --bootstrap-server 172.23.0.11:9092,172.23.0.12:9092,172.23.0.13:9092 --topic foo这里的话题要跟代码中的一致
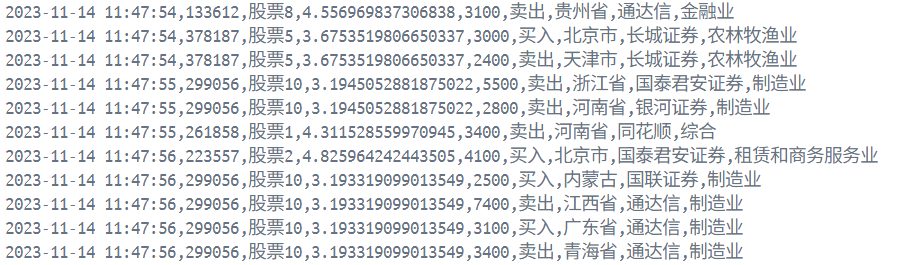
如果有这样的输出就意味着连接成功了。
KafkaSpout类
这个类是从kafka中拿取数据,同上面的WriteTopology类要修改的内容是相同的
修改kafka地址
private static final String BOOTSTRAP_SERVERS = "192.168.43.219:19092"; //kafka 地址,这个地址跟flink实验里面填写的相同就可以。
修改话题名
private static final String TOPIC_NAME = "foo";#这里要注意本实验需要一个唯一的话题名,在这里以及后面的文件和kafka中填写相同的话题名
添加nimbus地址
config.put("nimbus.seeds", Arrays.asList("192.168.43.219")); // 这里是我自己添加的,由于我的代码会报错找不到nimbus在这里添加之后写上自己的ip就可以找到了
报错
这个文件会出现两个类没有的报错以及<>的报错,两个类是需要自己定义的(后续会写),老师并没有给,<>的报错老师给的文件会有,如果用我下面的文件就不会有,已经解决了。
java
package org.example;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.kafka.spout.*;
import org.apache.storm.kafka.spout.KafkaSpoutRetryExponentialBackoff.TimeInterval;
import org.apache.storm.topology.TopologyBuilder;
import java.util.Arrays;
import java.util.logging.Logger;
/**new-topic
* 从 Kafka 中读取数据
*/
public class KafkaSpout {
private static final String BOOTSTRAP_SERVERS = "192.168.43.219:19092";
// private static final String TOPIC_NAME = "kafkatopic0";
private static final String TOPIC_NAME = "foo";
private static final Logger logger =
Logger.getLogger(ReadingFromKafkaApp.class.getName());
static {
//获取父级日志记录器
Logger parentLogger = logger.getParent();
//设置日志记录器的級别为 0FF
parentLogger.setLevel(java.util.logging.Level.OFF);
}
public static void main(String[] args) throws Exception {
final TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka_spout", new
org.apache.storm.kafka.spout.KafkaSpout<>(getKafkaSpoutConfig(BOOTSTRAP_SERVERS, TOPIC_NAME)), 1);
builder.setBolt("split_bolt", new SplitBolt(),
2).shuffleGrouping("kafka_spout").setNumTasks(2);
builder.setBolt("stat_store_bolt", new StatAndStoreBolt(),
1).shuffleGrouping("split_bolt").setNumTasks(1);
// 配置 Storm 工作线程数
Config config = new Config();
config.setNumWorkers(2); // 设置工作线程数为4
// 如果外部传参 cluster 则代表线上环境启动,否则代表本地启动
if (args.length > 0 && args[0].equals("cluster")) {
config.put("nimbus.seeds", Arrays.asList("192.168.43.219")); // 根据实际部署修改
try {
StormSubmitter.submitTopology("ClusterReadingFromKafkaApp", config,
builder.createTopology());
} catch (AlreadyAliveException | InvalidTopologyException |
AuthorizationException e) {
e.printStackTrace();
}
} else {
// 本地模式
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("ClusterReadingFromKafkaApp", config,
builder.createTopology());
// 保持本地集群运行一段时间或直到手动停止
Thread.sleep(60000); // 运行1分钟
cluster.shutdown();
}
}
private static KafkaSpoutConfig<String, String> getKafkaSpoutConfig(String bootstrapServers, String topic) {
return KafkaSpoutConfig.builder(bootstrapServers, topic)
// 除了分组 ID,以下配置都是可选的。分组 ID 必须指定,否则会抛InvalidGroupIdException
.setProp(ConsumerConfig.GROUP_ID_CONFIG, "testGroup")
// 定义重试策略
.setRetry(getRetryService())
// 定时提交偏移量的时间间隔,默认是 15s
.setOffsetCommitPeriodMs(10_000)
.build();
}
// 定义重试策略
private static KafkaSpoutRetryService getRetryService() {
return new KafkaSpoutRetryExponentialBackoff(TimeInterval.microSeconds(500),
TimeInterval.milliSeconds(2), Integer.MAX_VALUE,
TimeInterval.seconds(10));
}
}SplitBolt类
这个类是将拿到的数据进行切分的,无需修改
java
package org.example;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
/**
* 切分并统计从 Kafka 获取的数据
*/
public class SplitBolt extends BaseRichBolt {
private OutputCollector collector;
private int count;
private List<Tuple> tuples;
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector)
{
this.collector = collector;
this.count = 0;
this.tuples = new ArrayList<>();
}
public void execute(Tuple tuple) {
try {
String[] words = processAndEmitData(tuple);
// 使用逗号作为分隔符
int volume = Integer.parseInt(words[4]);
double amount = Double.parseDouble(words[3]);
String time = words[0];
String tradeType = words[5];
String stockCode = words[1];
String stockName = words[2];
String tradePlace = words[6];
String tradePlatform = words[7];
String industryType = words[8];
collector.emit(new Values(volume, amount, time, tradeType, stockCode,
stockName, tradePlace, tradePlatform, industryType));
// 必须 ack,否则会重复消费 kafka 中的消息
collector.ack(tuple);
} catch (Exception e) {
e.printStackTrace();
collector.fail(tuple);
}
}
public String[] processAndEmitData(Tuple tuple){
String[] words;
String line = tuple.getStringByField("value");
System.out.println("received from kafka : " + line);
words = line.split(",");
return words;
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("volume", "amount", "time", "tradeType", "stockCode",
"stockName", "tradePlace", "tradePlatform", "industryType")); // 切分成字段,后续进行统计
}
}ReadingFromKafkaApp类
这个类说实话我感觉并没有起作用,但是为了不报错,我还是写上了(我看有些人没有这个文件都能直接跑),修不修改都是能跑的
java
package org.example;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.kafka.spout.KafkaSpoutConfig;
import org.apache.storm.topology.TopologyBuilder;
public class ReadingFromKafkaApp {
private static final String BOOTSTRAP_SERVERS = "192.168.193.108:9092";
private static final String TOPIC_NAME = "kafkatopic0";
public static void main(String[] args) throws Exception {
// Kafka 配置
KafkaSpoutConfig<String, String> spoutConfig = KafkaSpoutConfig
.builder(BOOTSTRAP_SERVERS, TOPIC_NAME)
.setGroupId("storm-consumer-group") // 指定消费者组
.setMaxUncommittedOffsets(100) // Kafka 消费者的最大未提交偏移量数
.build();
// 创建拓扑
TopologyBuilder builder = new TopologyBuilder();
// 添加 Kafka Spout
builder.setSpout("kafka_spout", new org.apache.storm.kafka.spout.KafkaSpout<>(spoutConfig), 1);
// 添加 SplitBolt 进行数据处理
builder.setBolt("split_bolt", new SplitBolt(), 2).shuffleGrouping("kafka_spout");
// Storm 配置
Config config = new Config();
config.setDebug(true);
config.setNumWorkers(2);
// 提交拓扑到本地集群
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("ReadingFromKafkaApp", config, builder.createTopology());
}
}StatAndStoreBolt类
这个类是将切分后的数据进行统计,得到我们比较关心的数据,无需修改
java
package org.example;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.topology.IRichBolt;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.HashMap;
import java.util.Map;
/**
* 统计和存储数据的 Bolt 类
*/
public class StatAndStoreBolt implements IRichBolt {
private static final Logger LOG = LoggerFactory.getLogger(StatAndStoreBolt.class); // 使用 SLF4J 记录日志
private OutputCollector collector;
// 用来存储统计数据的变量
private Map<String, Integer> stockCountMap;
private Map<String, Double> totalAmountMap;
@Override
public void prepare(Map stormConf, org.apache.storm.task.TopologyContext context, OutputCollector collector) {
this.collector = collector;
// 初始化统计数据存储结构
this.stockCountMap = new HashMap<>();
this.totalAmountMap = new HashMap<>();
}
@Override
public void execute(Tuple input) {
long startTime = System.nanoTime(); // 记录开始时间
// 从输入的 tuple 中获取字段数据
String stockCode = input.getStringByField("stockCode");
int volume = input.getIntegerByField("volume");
double amount = input.getDoubleByField("amount");
// 统计每个股票的交易数量
stockCountMap.put(stockCode, stockCountMap.getOrDefault(stockCode, 0) + volume);
// 计算每个股票的总交易金额
totalAmountMap.put(stockCode, totalAmountMap.getOrDefault(stockCode, 0.0) + amount);
// 每次处理完数据后进行 ack 操作,确认处理成功
collector.ack(input);
// 记录当前统计数据到日志
long endTime = System.nanoTime(); // 记录结束时间
long elapsedTime = endTime - startTime; // 计算耗时
// 使用 SLF4J 记录日志,避免使用 System.out.println
LOG.info("Processing Stock Code: {}", stockCode);
LOG.info("Total Volume: {}", stockCountMap.get(stockCode));
LOG.info("Total Amount: {}", totalAmountMap.get(stockCode));
LOG.info("Processing Time for this Tuple: {} nanoseconds", elapsedTime);
// 示例: 发射处理后的数据到下游(如果需要的话)
collector.emit(new Values(stockCode, stockCountMap.get(stockCode), totalAmountMap.get(stockCode)));
}
@Override
public void cleanup() {
// 进行任何必要的清理操作
LOG.info("StatAndStoreBolt cleanup");
}
@Override
public void declareOutputFields(org.apache.storm.topology.OutputFieldsDeclarer declarer) {
// 声明输出字段
declarer.declare(new org.apache.storm.tuple.Fields("stockCode", "totalVolume", "totalAmount"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}最终验收
先运行WriteTopology类,并且确定kafka接收到数据后,运行KafkaSpout类,这个类会处理数据得到统计数据,如图结果就算成功了。

集群测试
本博客记录的实现是在本地的,集群测试请移步这篇博客