前言
此问题是最近碰到的一个问题
最近的一个项目, 单条记录的大小 超过了 1M, 然后 使用 kafka 存储数据出现了各种问题
一些问题很容易发现问题, 但是一些问题 很隐蔽
这里 特此记录一下, 篇幅不会很长
测试用例
测试用例如下, 问题主要分为两个地方, 其一是客户端这边的限制, 其二是服务器那边的限制
其中 服务器那边的限制 出现的问题较为隐蔽
package com.hx.test14;
/**
* Test10KafkaProducer
*
* @author Jerry.X.He
* @version 1.0
* @date 2023-03-12 10:15
*/
public class Test10KafkaProducer {
// Test06KafkaProducer
public static void main(String[] args) throws Exception {
Properties properties = new Properties();
properties.put("bootstrap.servers", "192.168.0.116:9092");
properties.put("acks", "all");
properties.put("retries", 0);
properties.put("batch.size", 16384);
properties.put("linger.ms", 1);
properties.put("buffer.memory", 33554432);
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// properties.put("max.request.size", 10485760);
String topic = "test20230312";
String path = "/Users/jerry/Jobs/14_lzxm/xx/realdata.json";
String content = Tools.getContent(path);
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
long start = System.currentTimeMillis();
for (int i = 1; i <= 10; i++) {
Future<RecordMetadata> respFuture = kafkaProducer.send(new ProducerRecord<>(topic, content));
System.out.println("message" + i);
}
long spent = System.currentTimeMillis() - start;
System.out.println(" spent " + spent + " ms ");
kafkaProducer.close();
//
}
}客户端这边的限制
客户端这边报错如下
java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.RecordTooLargeException: The message is 1880363 bytes when serialized which is larger than the maximum request size you have configured with the max.request.size configuration.主要是客户端这边 本地对于消息大小的校验 使用的配置是 max.request.size
然后 默认值是 1M, 我们这里没有手动配置, 因此是 默认值 1M
但是实际消息大小在 1.7M 左右, 因此 抛出了异常
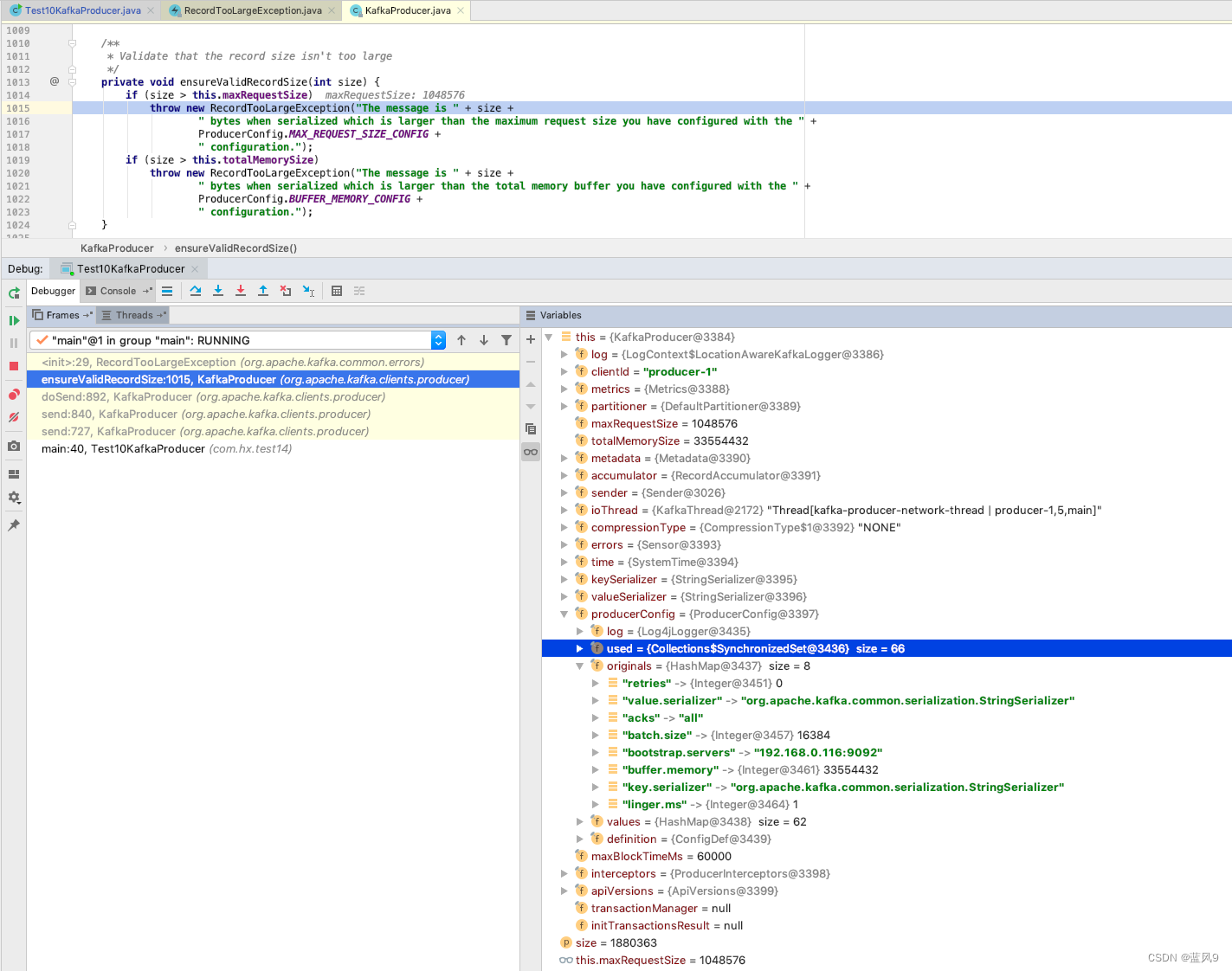
解决方式, ProducerConfig 增加 max.request.size 的配置

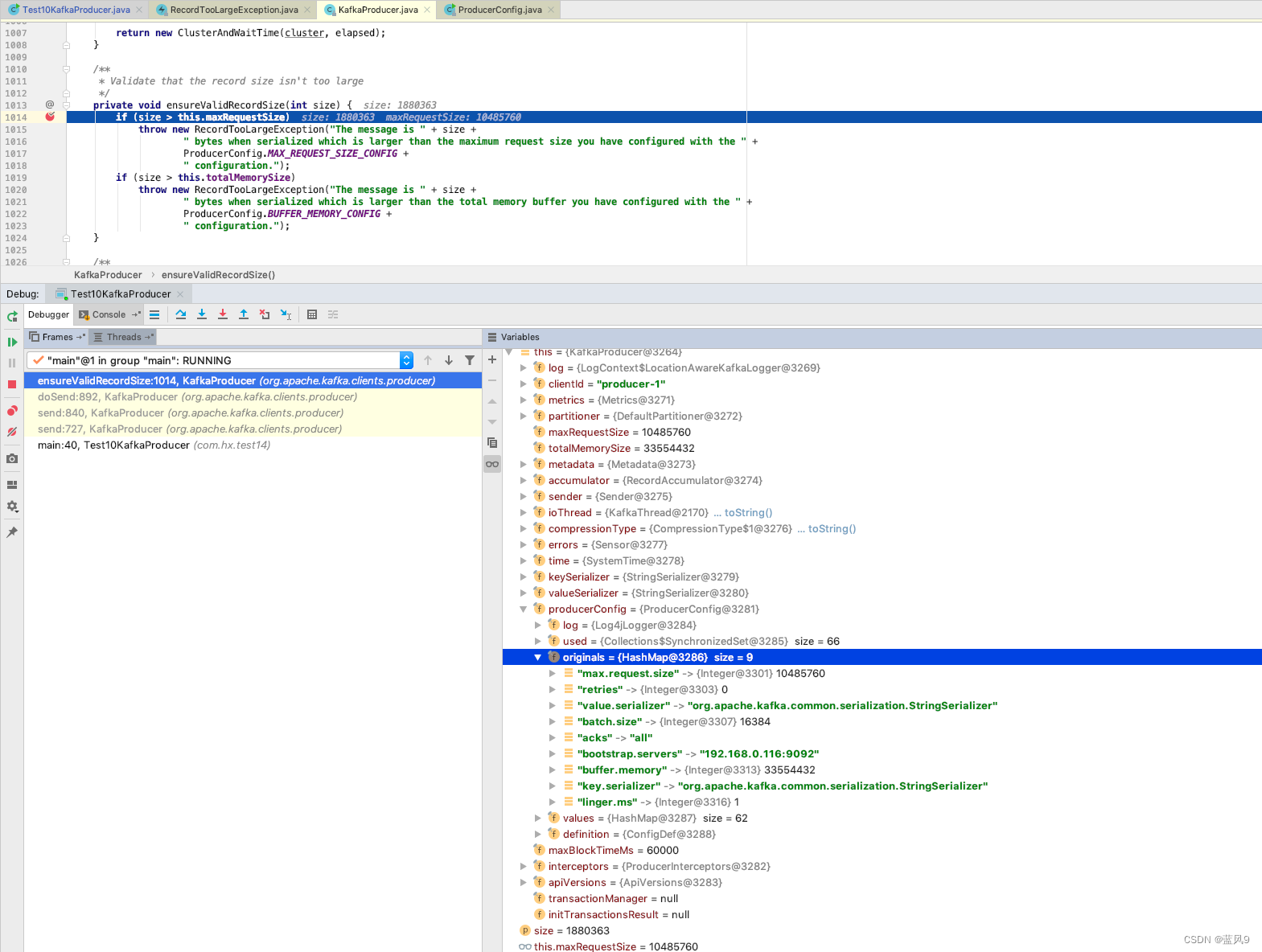
服务器那边的限制
客户端这边生产线消息之后, 同步获取服务器的反馈, 得到信息如下
但是 服务器那边 没有报错消息, 因此 较为隐蔽
Exception in thread "main" java.util.concurrent.ExecutionException: org.apache.kafka.common.errors.RecordTooLargeException: The request included a message larger than the max message size the server will accept.
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.valueOrError(FutureRecordMetadata.java:98)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:67)
at org.apache.kafka.clients.producer.internals.FutureRecordMetadata.get(FutureRecordMetadata.java:30)
at com.hx.test14.Test10KafkaProducer.main(Test10KafkaProducer.java:41)
Caused by: org.apache.kafka.common.errors.RecordTooLargeException: The request included a message larger than the max message size the server will accept.服务器这边处理如下, 有一个 消息大小的限制
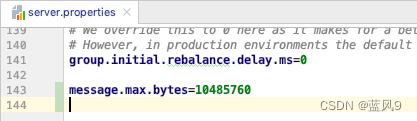
读取的配置是服务器的 message.max.bytes 的配置
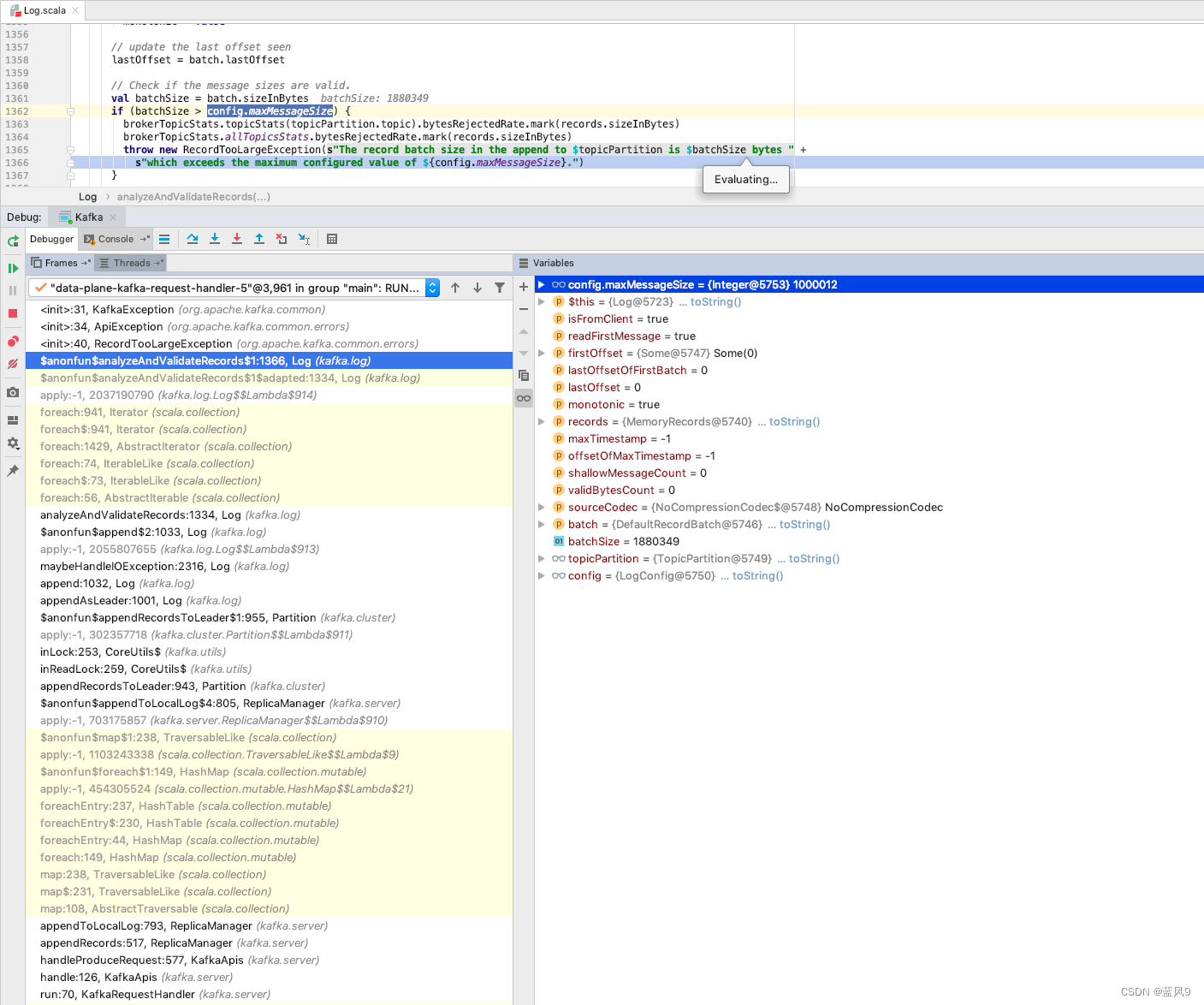
调整了了这个配置之后, 服务器这边的校验就过了
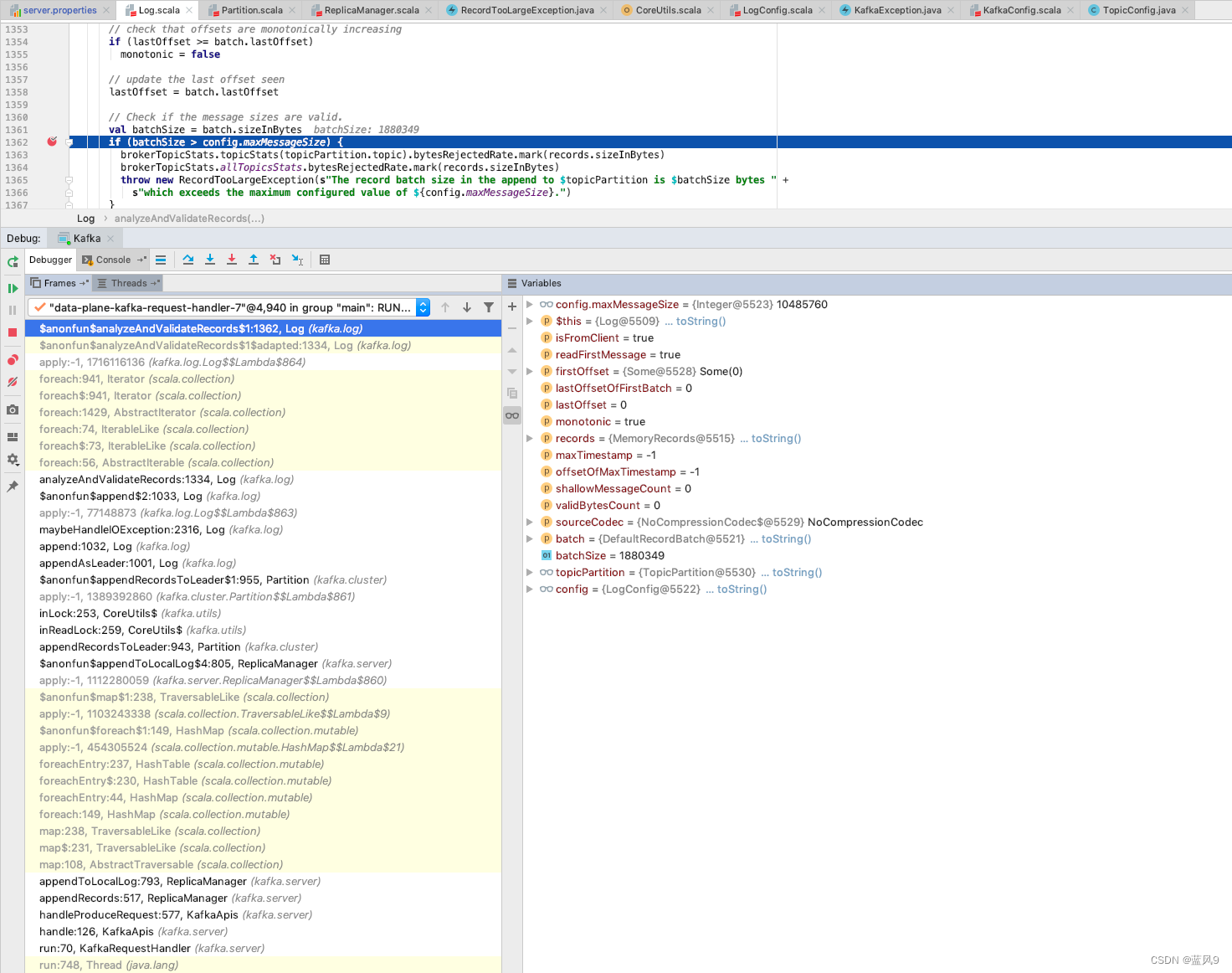
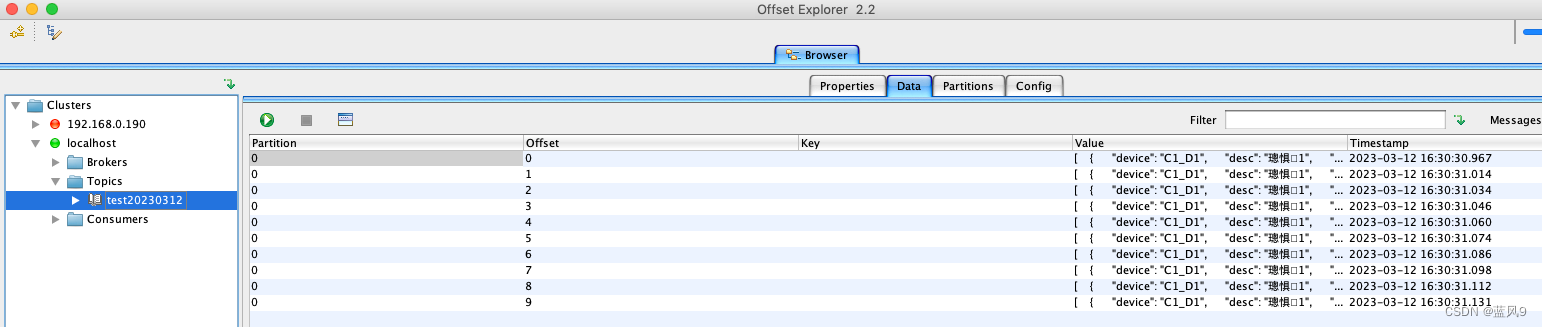
客户端这边拿到存储的记录如下
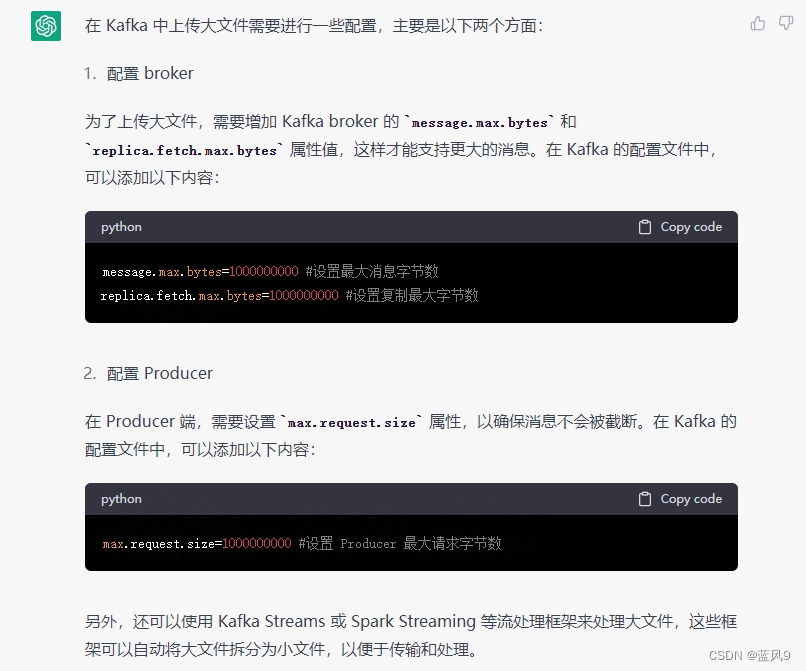
问了一下 chatgpt
和本文的梳理出来的东西一致, 但是 开销却比 人类 大脑快多了
完