
🔥草莓熊Lotso: 个人主页
❄️个人专栏: 《C++知识分享》 《Linux 入门到实践:零基础也能懂》
✨生活是默默的坚持,毅力是永久的享受!
🎬 博主简介:

文章目录
- 前言:
- [一. 核心认知:unordered 系列容器是什么?](#一. 核心认知:unordered 系列容器是什么?)
- [二. 模板参数与基础接口](#二. 模板参数与基础接口)
-
- [2.1 模板参数](#2.1 模板参数)
- [2.2 核心接口(与 map/set 高度一致)](#2.2 核心接口(与 map/set 高度一致))
- [2.3 支持冗余的版本:unordered_multiset/unordered_multimap](#2.3 支持冗余的版本:unordered_multiset/unordered_multimap)
- [三. 关键差异:unordered 系列 vs map/set](#三. 关键差异:unordered 系列 vs map/set)
- [四. 性能实测:谁更快](#四. 性能实测:谁更快)
- 结尾:
前言:
在 C++ 开发中,
map/set与unordered_map/unordered_set是高频使用的关联式容器,前者基于红黑树实现,后者基于哈希表实现。很多开发者纠结于 "该选哪一个"------ 其实核心在于理解两者的底层差异:红黑树保证有序但效率是 O (logN),哈希表追求 O (1) 平均效率但无序。本文聚焦unordered_map/unordered_set 的使用方法、与 map/set 的核心差异、性能对比,用代码示例和场景分析帮你快速掌握其用法,精准选择适合自己的容器。
一. 核心认知:unordered 系列容器是什么?
unordered_map 和 unordered_set 是 C++11 引入的关联式容器,底层基于 哈希表(哈希桶) 实现,核心特点如下:
- 存储特性:unordered_set 存储单个 key(去重 + 无序),unordered_map 存储 key-value 对(key 去重 + 无序);
- 效率:增删查改平均时间复杂度 O (1),最坏情况 O (N)(哈希冲突严重时);
- 迭代器:单向迭代器(不支持 -- 操作),遍历结果无序;
- 对 key 的要求:需支持 "转换为整形"(哈希函数需求)和 "相等比较"(冲突判断需求)。
二. 模板参数与基础接口
2.1 模板参数


一般来说,后面三个参数我们都不需要传。
2.2 核心接口(与 map/set 高度一致)
无论是 unordered_map 还是 unordered_set,核心接口与 map/set 完全兼容,上手零成本:(这里仅展示部分接口,剩下的可以看看文档,还有些和map/set不一样的后续讲实现的时候还会再进行补充的)
unordered_set 核心接口:
cpp
#include <unordered_set>
using namespace std;
int main()
{
unordered_set<int> us;
// 插入(返回pair<iterator, bool>,bool标记是否插入成功)
us.insert(10);
us.insert({ 20, 30, 40 });
// 查找(返回迭代器,未找到返回end())
auto it = us.find(20);
if (it != us.end())
{
// 找到处理
}
// 删除(按key删除,返回删除个数)
us.erase(30);
// 其他常用接口
us.size(); // 元素个数
us.empty(); // 是否为空
us.clear(); // 清空容器
}unordered_map 核心接口:
cpp
#include <unordered_map>
using namespace std;
int main()
{
unordered_map<string, int> um;
// 插入
um.insert({ "sort", 1 });
um.insert(make_pair("left", 2));
// []运算符(插入+访问/修改,最常用)
um["right"] = 3; // 插入
um["left"] = 22; // 修改
// 查找
auto it = um.find("sort");
if (it != um.end()) { cout << it->first << ":" << it->second << endl; }
// 删除
um.erase("right");
}2.3 支持冗余的版本:unordered_multiset/unordered_multimap
与 multiset/multimap 类似,支持 key 重复:
- unordered_multiset:允许相同 key 重复插入,遍历无序;
- unordered_multimap:允许相同 key 重复插入,不支持 \[\] 运算符(key 不唯一);
- 核心差异:无去重机制,其他接口与 unordered_map/unordered_set 一致。
三. 关键差异:unordered 系列 vs map/set
| 对比维度 | unordered_map / unordered_set |
map / set |
|---|---|---|
| 底层结构 | 哈希表(数组 + 链表/红黑树) | 红黑树(自平衡二叉搜索树) |
| 元素顺序 | 无序(取决于哈希函数) | 有序(按 key 默认升序排列) |
| 时间复杂度 | 平均 O(1) ,最差 O(n) | 稳定 O(logN) |
| 迭代器特性 | 单向迭代器(仅支持向前遍历) | 双向迭代器(支持向前/向后遍历) |
| 对 Key 的要求 | 1. 支持 == 比较 2. 可计算哈希值 |
支持 < 比较(或自定义严格弱序) |
| 内存占用 | 较高(需预留桶空间减少冲突) | 较低(树结构紧凑,无预留开销) |
| 数据分布 | 数据分散在桶中 | 数据在树结构中平衡分布 |
| 主要优势 | 极速查找(常数级平均时间) | 有序遍历、稳定性能 |
| 典型场景 | 高频查询、缓存系统、去重操作 | 需要有序数据、范围查询、顺序相关操作 |
选择建议:
- 要极致速度 → 选
unordered_xxx - 要顺序访问 → 选
map/set
四. 性能实测:谁更快
测试代码(核心逻辑):
cpp
// (测试环境:VS2022,Release 模式):
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<unordered_set>
#include<unordered_map>
#include<set>
using namespace std;
void test_unset1()
{
const size_t N = 1000000;
unordered_set<int> us;
set<int> s;
vector<int> v;
v.reserve(N);
srand(time(0));
for (size_t i = 0; i < N; ++i)
{
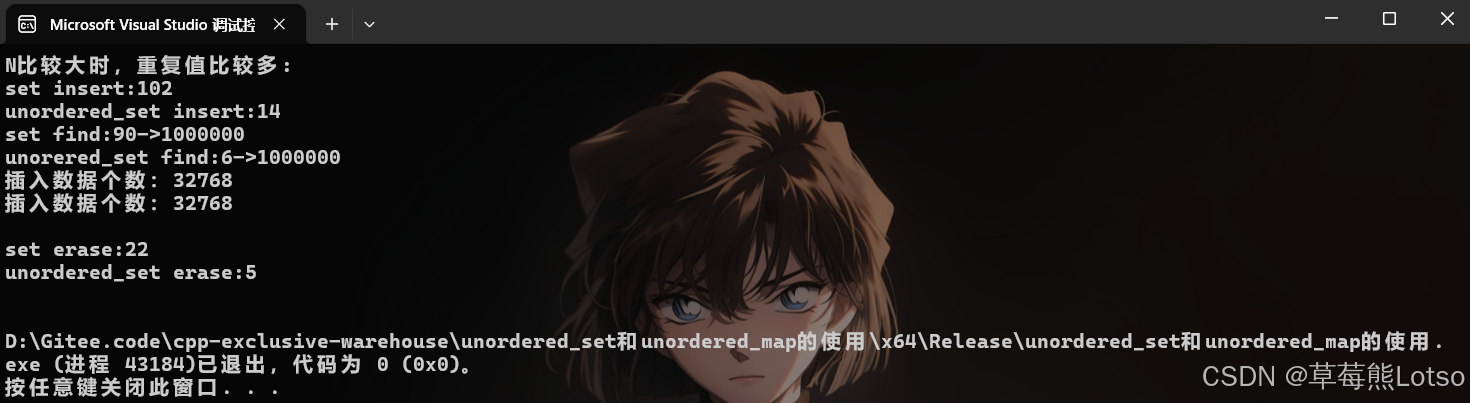
v.push_back(rand()); // N比较大时,重复值比较多
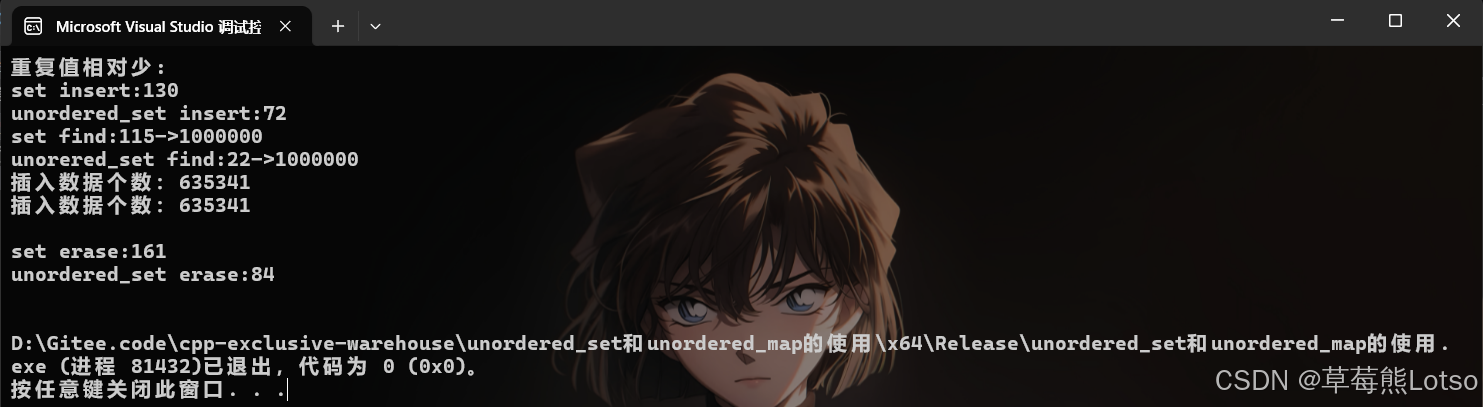
//v.push_back(rand() + i); // 重复值相对少
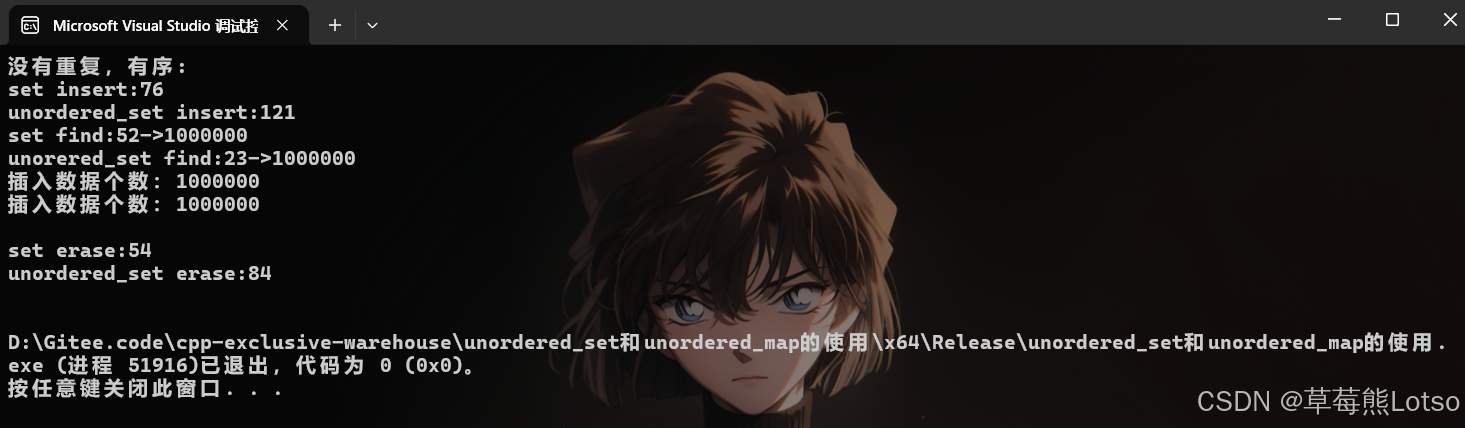
//v.push_back(i); // 没有重复,有序
}
size_t begin1 = clock();
for (auto e : v)
{
s.insert(e);
}
size_t end1 = clock();
cout << "set insert:" << end1 - begin1 << endl;
size_t begin2 = clock();
us.reserve(N);
for (auto e : v)
{
us.insert(e);
}
size_t end2 = clock();
cout << "unordered_set insert:" << end2 - begin2 << endl;
int m1 = 0;
size_t begin3 = clock();
for (auto e : v)
{
auto ret = s.find(e);
if (ret != s.end())
{
++m1;
}
}
size_t end3 = clock();
cout << "set find:" << end3 - begin3 << "->" << m1 << endl;
int m2 = 0;
size_t begin4 = clock();
for (auto e : v)
{
auto ret = us.find(e);
if (ret != us.end())
{
++m2;
}
}
size_t end4 = clock();
cout << "unorered_set find:" << end4 - begin4 << "->" << m2 << endl;
cout << "插入数据个数:" << s.size() << endl;
cout << "插入数据个数:" << us.size() << endl << endl;
size_t begin5 = clock();
for (auto e : v)
{
s.erase(e);
}
size_t end5 = clock();
cout << "set erase:" << end5 - begin5 << endl;
size_t begin6 = clock();
for (auto e : v)
{
us.erase(e);
}
size_t end6 = clock();
cout << "unordered_set erase:" << end6 - begin6 << endl << endl;
}
int main()
{
test_unset1();
return 0;
}- 三组测试结果 :
关键结论:
- unordered 系列在插入、查找、删除场景下均显著快于 map/set,尤其是高频查询场景;
- unordered 系列使用时建议先用reserve(N)预分配空间,避免频繁扩容导致性能下降;
- 数据量越小,性能差距越不明显;数据量越大,unordered 系列的优势越突出;数据有序时,unoredered系列的插入效率没set高。
unordered_xxx的哈希相关接口:
Buckets和Hash policy系列的接口分别是跟哈希桶和负载因子相关的接口,日常使用的角度我们不需
要太关注,后面学习了哈希表底层,我们再来看这个系列的接口,一目了然。
结尾:
html
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:unordered_map/unordered_set 的核心价值是 "以空间换时间",用哈希表的结构实现 O (1) 平均效率,完美适配高频查询场景;而 map/set 则以 "有序 + 稳定" 为核心优势,适合需要排序或空间敏感的场景。两者的接口高度兼容,切换成本极低,实际开发中可根据 "是否需要有序" 和 "查询频率" 快速决策。建议在性能瓶颈时优先尝试 unordered 系列,若需有序则切换到 map/set。
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど
