摘要
仔猪间的攻击行为被认为是一种有害的社会接触。监测具有强烈攻击行为的断奶仔猪对于生猪育种管理至关重要。本研究引入了一种新颖的混合模型 PAB-Mamba-YOLO,该模型集成了 Mamba 和 YOLO 的原理,用于高效视觉检测断奶仔猪的攻击行为,包括爬跨身体、鼻部撞击、咬尾和咬耳。在所提出的模型中,开发了一个新颖的 CSPVSS 模块,该模块将跨阶段部分(CSP)结构与视觉状态空间模型(VSSM)集成在一起。该模块被巧妙地集成到网络的 Neck 部分,它利用卷积能力进行局部特征提取,并利用视觉状态空间来揭示长距离依赖关系。该模型在检测攻击行为方面表现出良好的性能,爬跨身体的平均精度(AP)为 0.976,鼻部撞击为 0.994,咬尾为 0.977,咬耳为 0.994。所有攻击行为类别的平均精度均值(mAP)为 0.985,反映了模型在检测所有类别攻击行为方面的整体有效性。该模型的检测速度 FPS 达到 69 帧/秒,模型复杂度以 7.2 G 浮点运算次数(GFLOPs)和 263 万个参数(Params)衡量。与现有主流模型的对比实验证实了所提出模型的优越性。这项工作有望为精准育种和动物行为分析研究领域贡献一丝新的思路和启发。
1. 引言
猪的选育和保留是育种过程中最关键的方面。优秀的种猪是重要的基因载体,能够通过选育加速群体内的遗传进展。这些种猪直接影响整个育种系统的遗传进展和经济可行性 (Hellbrügge et al., 2008)。仔猪表现出的社会行为可以反映社会遗传效应对生长性能的影响,基于这些社会遗传效应的遗传选择可以增强杂交后代的生长性能 (Schef er et al., 2016)。断奶仔猪间的攻击行为被认为是有害的社会接触,成为一个日益突出的问题 (Buettner et al., 2015; Yang et al., 2024)。在断奶仔猪中观察到的典型攻击行为包括爬跨身体、鼻部撞击、咬尾和咬耳。此类行为不仅会导致仔猪身体受伤和皮肤感染,还可能损害其生长和生产力,严重时甚至导致死亡。因此,监测和分析断奶仔猪的攻击行为对于识别和淘汰具有强烈攻击性的仔猪在生猪育种中至关重要 (Yang and Xiao, 2020)。
随着信息技术的飞速发展,包括三轴加速度传感器 (Ringgenberg et al., 2010)、压力传感器 (Oliviero et al., 2008) 和 RFID 标签 (Martinez-Aviles et al., 2017) 在内的一系列传感器技术正逐渐应用于动物行为监测。尽管取得了进展,但基于传感器的系统的一个显著限制是它们通常需要外部附着。这种外在定位可能由于设备的物理强加而导致动物应激。此外,在猪只互动和运动过程中存在传感器脱落的风险 (Maselyne et al., 2014)。非接触式计算机视觉技术正成为精准育种领域的一个突出替代方案 (Borges Oliveira et al., 2021; Lao et al., 2016)。这些技术利用复杂的算法来识别和分析猪的行为特征,实现攻击行为的自动化监测和评估。这一技术进步最大限度地减少了与可穿戴传感器相关的应激,并增强了动态监测的精确性和效率 (Li et al., 2021)。
关于猪攻击行为监测已进行了多项研究。Viazzi 等人 (2014) 使用运动历史图像提取运动信息,如平均强度和占用指数,然后应用线性判别分析 (LDA) 来识别猪的攻击行为。Lee 等人 (2016) 利用深度传感器捕获猪的活动特征,并应用支持向量机 (SVM) 识别猪栏内的攻击行为。Oczak 等人 (2014) 引入了群体活动指数,并采用多层前馈神经网络来检测猪只间的攻击事件。为了解决使用帧间差分法时由变化的背景和养殖设施引起的干扰问题,Dong 等人 (2021) 计算了活动指数来辨别攻击行为的发生。Chen 等人 (2017) 利用加速度特征进行层次聚类,以对猪攻击行为的强度进行分类。在此基础上,Chen 等人 (2018) 开发了一个识别模型,该模型基于相邻视频帧之间动能差导出的特征进行训练。
上述方法主要依赖于传统的图像处理技术,手动定义和提取一个或几个特征用于猪攻击行为的识别。然而,这些策略的有效性可能会受到猪只间遮挡、设施内光照变化以及猪行为模式复杂性等因素的影响。这些挑战可能导致模型在实际场景中应用时稳定性和鲁棒性下降。
近年来,深度学习已成为计算机视觉领域的关键技术,特别是在表示高层抽象特征和实现自动特征学习方面 (Lecun et al., 2015)。该技术已广泛应用于识别猪的各种基本行为。例如,研究重点在于识别猪的采食和哺乳行为 (Alameer et al., 2020; Yang et al., 2018a; Zheng et al., 2018),以及识别不同的猪姿势及其变化 (Yang et al., 2021; Zhu et al., 2020a)。Riekert 等人 (2021) 开发了一种改进的 Faster R-CNN 来检测猪的位置并对躺卧和非躺卧姿势进行分类。Nasirahmadi 等人 (2019) 融合了 R-FCN 和 ResNet101 网络来识别猪的站立和躺卧姿势。Shao 等人 (2021) 使用 DeepLab v3+ 分割个体猪轮廓,并使用深度可分离卷积网络对猪姿势进行分类。Ji 等人 (2022) 开发了一种改进的 YOLOX 来识别各种猪姿势,如站立、躺卧和坐立。Kim 等人 (2021) 在 YOLOv3 和 YOLOv4 中引入了角度优化策略来识别猪的采食行为。Tu 等人 (2022) 比较了 YOLOv5s 和 YOLOXs 在检测猪的躺卧、站立和采食方面的性能。Yang 等人 (2018b) 利用全卷积神经网络获取猪的几何特征来对母猪哺乳行为进行分类。Yang 等人 (2018c) 报道了一种基于 Fast R-CNN 的方法,用于群养猪的采食行为检测。Xu 等人 (2022) 提出了 TransFree 模型,该模型将 Vision Transformer 与无锚点头部相结合,用于仔猪的检测和姿势分类。Tu 等人 (2024) 将 YOLOv5 与 ByteTrack 算法融合,用于跟踪群养猪并对其站立、躺卧和采食进行分类。
尽管其重要性,但在生猪育种中关于监测断奶仔猪攻击行为的研究却很少。Wutke 等人 (2021) 讨论了群养猪的社会接触,并提出了一个自动检测社会接触的框架,开创了使用基于关键点的 CNN 进行动物身体部位检测和社会接触识别的先河。Liu 等人 (2020) 设计了一种两阶段策略来识别猪咬尾行为,涉及跟踪检测方法,然后使用 CNN + LSTM 模型进行分类。Hakansson 和 Jensen (2023) 以及 Chen 等人 (2020) 报道了一种多阶段方法,采用预训练的 CNN 进行空间特征提取,并使用 LSTM 进行时间特征处理来识别咬尾行为。Gao 等人 (2019) 开发了一种改进的 C3D 模型来学习时间和活动信息,用于对猪图像中的攻击和非攻击行为进行分类。出于相同目的,Gao 等人 (2023) 设计了一个 CNN-GRU 融合模型来区分猪的攻击行为和非攻击行为。Ji 等人 (2023) 利用基于时间移位模块的方法对视频片段中的猪攻击行为进行分类。Gan 等人 (2022) 采用了一种由自适应空间亲和核函数和时空图节点组成的多阶段方法来表征仔猪的攻击和玩耍行为。
总之,基于深度学习的方法在识别单个猪攻击实例方面已展现出令人印象深刻的性能。然而,大多数现有方法侧重于粗粒度识别,仅确定是否发生了攻击事件。此外,这些方法由于在空间和时间域处理特征,可能会引入大量冗余信息,导致过度的计算负担,从而影响实时能力。对于实际场景中断奶仔猪攻击行为监测,需要更多地关注几个关键问题:1) 攻击行为发生在图像中的哪个位置?2) 图像中表现出的具体攻击行为类别是什么?3) 监测到的攻击行为能否及时反馈?解决这些问题可以使养殖者或 AI 辅助机器人能够发现仔猪的攻击行为,并根据攻击行为的类型及时进行干预。
当前基于深度学习的目标检测模型,包括基于 CNN 和基于 Transformer 的模型,都存在一些局限性。基于 CNN 的模型受限于局部感受野,限制了它们捕获长距离依赖关系的能力。相比之下,基于 Transformer 的模型虽然擅长建模长程关系,但其二次计算复杂度带来了沉重的计算负载 (Vaswani et al., 2017)。以 Mamba (Wang et al., 2023; Liu et al., 2024) 为代表的状态空间模型 (SSM) 因其在建模长距离依赖关系方面的熟练度及其线性时间复杂度 (Zhu et al., 2024) 而成为有前景的解决方案。Mamba 自 NLP 领域引入以来,其应用已迅速扩展到各种任务 (Gu and Dao, 2023)。受此启发,将 Mamba 集成到目标检测框架中可以利用其优势对断奶仔猪的攻击行为进行鲁棒监测。
本文提出了一种新颖的混合模型,该模型集成了 Mamba 和 YOLO 的原理,用于高效视觉检测断奶仔猪的攻击行为,包括爬跨身体、鼻部撞击、咬尾和咬耳。该模型具有一个专门设计的 CSPVSS 模块,该模块利用卷积能力进行局部特征提取,并利用视觉状态空间来揭示长距离依赖关系。这种方法在猪攻击行为监测和育种分析中具有应用潜力。
这项工作的主要贡献如下:
-
- 通过创新性地开发 PAB-Mamba-YOLO 模型,建立了一个有效的基准检测器,用于检测实际场景中断奶仔猪的多种攻击行为,开创了在该领域集成 Mamba 驱动架构的先河。
-
- 在所提出的模型中设计了 CSPVSS 模块,这是一个新颖的组件,它结合了跨阶段部分 (CSP) 结构和由 Mamba 构建的视觉状态空间模型 (VSSM),从而增强了模型在断奶仔猪攻击行为检测方面的性能。
本文的其余部分安排如下:第 2 节详细介绍了数据收集和数据集构建标准。第 3 节概述了所提出模型的设计。第 4 节展示了实验结果以及与其他方法的性能比较分析。第 5 节从多个角度讨论了所提出的方法,最后在第 6 节给出结论。
2. 材料
2.1. 数据来源
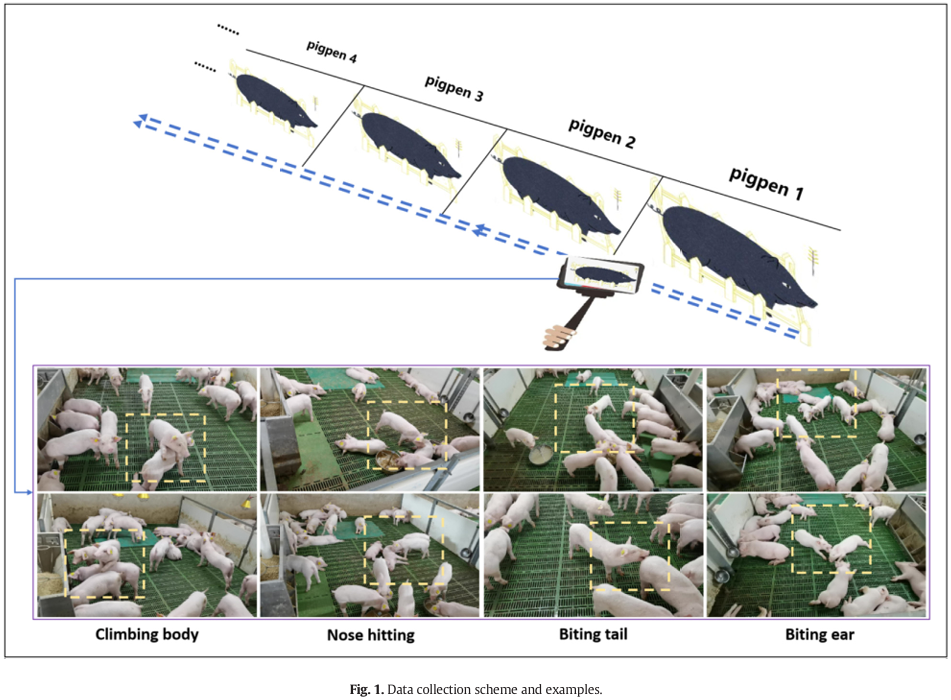
本研究的实验数据收集自位于中国贵州省施秉县(东经 108°14′,北纬 27°01′)的一个商业生猪育种场。实验数据采集自猪场的两个饲养舍。在饲养舍中,每个猪栏的尺寸标准化为约 2.77 米 × 3.72 米。约克夏品种的断奶仔猪饲养在饲养栏中,密度为每栏 12 至 25 头仔猪。饲养舍中仔猪的年龄分布多样,包含断奶后早期阶段(35-50 日龄)和断奶后后期阶段(50-70 日龄)。图 1 说明了数据收集的示意图以及本研究中使用的攻击行为示例。如图 1 中蓝色带箭头的虚线所示,实验者沿着猪栏周边进行巡查,使用智能手机捕捉断奶猪攻击行为的视频片段。智能手机的内置摄像头距离地面高度约 150 至 160 厘米。数据收集时间为 2023 年 5 月至 2023 年 6 月,在白天时间(上午 7 点至下午 5 点)记录断奶仔猪行为的 RGB 视频数据。断奶仔猪在栏舍内从不同视角表现出攻击行为,样本从不同视角捕捉以增加数据多样性。视频录制分辨率为 1920 × 1080 像素,MP4 格式,帧率为每秒 30 帧。
2.2. 数据集构建
本研究的数据集根据断奶仔猪的表现定义,主要关注典型的攻击行为,包括爬跨身体、鼻部撞击、咬尾和咬耳。表 1 详细描述了这些行为。为了缓解重复采样问题,从 519 个视频片段中精心提取了 15,705 张图像,然后系统地分配到训练集和测试集中。具体来说,随机选择 12,805 张图像(约占数据集的 80%)用于模型训练。随后,剩余的 2900 张图像(约占 20%)保留用于性能评估。数据集的分配详见表 2。为了精确识别和标注图像中的攻击行为,使用了一个基于开源脚本 BBox-Label-Tool (https://gitee.com/alexleft/BBox-Label-Tool/) 的自开发标注软件来标记图像中猪攻击行为的区域。图 2 提供了数据集的视觉分布图,包括标注目标的边界框位置和大小。
3. 方法
3.1. 整体架构
在高密度养殖场景中,断奶仔猪表现出的多样化攻击行为给监测系统带来了持续的挑战。发现断奶仔猪的攻击行为需要精确定位这些行为在图像中的位置以及攻击行为的具体分类。
因此,一个有效的检测算法对于监测断奶仔猪间的攻击行为是必不可少的。本研究提出了 PAB-Mamba-YOLO,一种将视觉 Mamba 集成到单阶段检测框架中的混合模型,能够高效检测断奶仔猪表现出的攻击行为。图 3 描绘了所提出的 PAB-Mamba-YOLO 模型的整体架构。
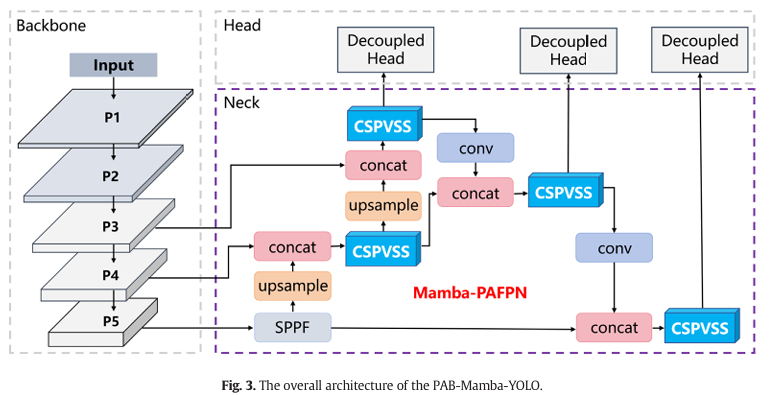
PAB-Mamba-YOLO 模型包含三个组成部分:Backbone、Neck 和 Head,它继承了 YOLOv8 (Jocher et al., 2023) 的主要结构。Backbone 使用 CSPDarknet 作为特征提取网络,处理输入图像以产生初始特征。在 Backbone 之后,模型生成五个不同尺度的特征图 { C 1 , C 2 , C 3 , C 4 , C 5 } \{\mathsf{C}{1},\mathsf{C}{2},\mathsf{C}{3},\mathsf{C}{4},\mathsf{C}_{5}\} {C1,C2,C3,C4,C5},每个特征图包含从粗到细的多层次特征信息。这些特征随后被送入 Neck,其中开发并采用了一种新颖的渐进聚合特征传播网络 (PAFPN) 变体,称为 Mamba-PAFPN。Mamba-PAFPN 作为 Neck,通过复杂的聚合过程集成多级特征来增强特征表示。其核心原理在于有效融合跨尺度特征,使其能够捕获更丰富的信息流梯度和不同层级间的长程关系,同时保持可控的计算负载。聚合后的多尺度特征图随后传递给 Head 进行进一步处理。Head 在定位和分类方面承担双重责任。它采用解耦头机制,分析来自 Mamba-PAFPN 不同输出层的各种尺度特征。该部分分为两个任务:用于估计目标位置的边界框回归和用于确定对象类别的类别预测。解耦策略允许每个任务处理一组专用参数,便于在定位和分类方面进行独立专门化。
PAB-Mamba-YOLO 模型代表了一种新颖的网络,它融合了 Mamba 和 CNN 的优势,以准确定位和分类图像中仔猪的攻击行为。通过将 CSPVSS 模块集成到模型的 Mamba-PAFPN 中,该架构有效地捕获了全局依赖关系并无缝集成了局部信息。这一增强提高了模型对复杂养殖场景中仔猪攻击行为的理解,同时保持了线性计算复杂度。这种混合架构为检测断奶仔猪攻击行为提供了一个鲁棒且适应性强的基于视觉的解决方案。
3.2. 视觉状态空间模型
3.2.1. 状态空间模型
Mamba 是基于状态空间模型 (SSM) 构建的。与新兴的基于 Transformer 的方法相比,Mamba 在长序列建模方面展现出卓越的表征能力,同时保持线性时间复杂度,这在数据处理效率方面提供了显著优势 (Chen et al., 2024)。
SSM 通常用于表示线性时不变系统 (Zhao et al., 2024a)。它通过一个潜在的隐状态 h ( t ) ∈ R N h(t)\in R^{N} h(t)∈RN 将一维输入序列 x ( t ) ∈ R L x(t)\in R^{L} x(t)∈RL 映射到输出序列 y ( t ) ∈ R L y(t)\in R^{L} y(t)∈RL,有效地桥接了输入和输出之间的关系,并封装了时间动态。数学上,SSM 可以表述为线性常微分方程 (ODE),如下所示:
h ′ ( t ) = A h ( t ) + B x ( t ) h^{\prime}(t)=A h(t)+B x(t) h′(t)=Ah(t)+Bx(t)
y ( t ) = C h ( t ) + D x ( t ) y(t)=C h(t)+D x(t) y(t)=Ch(t)+Dx(t)
其中 A ∈ R N × N A\in R^{N\times N} A∈RN×N 表示状态转移矩阵, B , C ∈ R N B,C\in R^{N} B,C∈RN 分别表示输入矩阵和输出矩阵, D ∈ R L D\in R^{L} D∈RL 表示前馈矩阵, h ( t ) h(t) h(t) 表示时刻 t t t 的隐状态向量。
SSM 中的矩阵有不同的职责。状态转移矩阵 A 控制隐状态向量 h ( t ) h(t) h(t) 随时间的演化。输入矩阵 B、输出矩阵 C 和前馈矩阵 D 各自在定义输入信号 x ( t ) x(t) x(t)、状态 h ( t ) h(t) h(t) 和输出响应 y ( t ) y(t) y(t) 之间的内在关系方面起着关键作用。在深度学习应用中,通常采用离散时间框架来对 ODE 进行离散化 (Wang et al., 2024a)。这种方法对于使模型与输入信号的采样频率同步至关重要,从而确保模型在离散时间间隔内准确捕获系统过程。在离散化过程中,封装线性时不变系统动态特性的连续方程被转换为等效的离散时间表示。这种转换对于使模型与信号的采样率同步至关重要 (Wang et al., 2023)。可以通过对输入信号应用零阶保持原理来获得等效的离散时间表示。因此,方程 (1) 和方程 (2) 可以离散化如下:
A ˉ = e Δ A \bar{A}=e^{\Delta A} Aˉ=eΔA
B ˉ = ( e Δ A − I ) A − 1 B \bar{\boldsymbol{B}}=\Big(e^{\Delta A}-I\Big)\boldsymbol{A}^{-1}\boldsymbol{B} Bˉ=(eΔA−I)A−1B
C ˉ = C \bar{C}=C Cˉ=C
h k = A ‾ h k − 1 + B ‾ x k h_{k}=\overline{{A}}h_{k-1}+\overline{{B}}x_{k} hk=Ahk−1+Bxk
y k = C ‾ h k + D ‾ x k y_{k}=\overline{{C}}h_{k}+\overline{{D}}x_{k} yk=Chk+Dxk
其中 Δ \Delta Δ 是离散化步长, I I I 是单位矩阵。
这些固定的离散化规则作为 SSM 应用的基础,促进了 Mamba 无缝集成到深度学习框架中。
3.2.2. 二维选择性扫描机制
二维 (2D) 视觉数据和一维 (1D) 序列数据之间固有的不兼容性使得 Mamba 直接应用于视觉任务不切实际。这主要是因为 2D 空间信息对于视觉相关任务至关重要,而它在 1D 序列建模中的作用不那么突出。这种基本差异导致有限的感受野,无法捕获与未探索区域的潜在相关性 (Dong et al., 2024)。
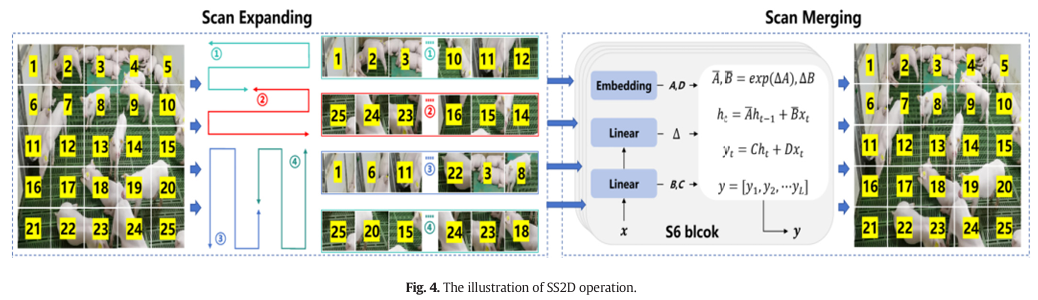
为了应对这一挑战,视觉状态空间模型 (VSSM) 引入了二维选择性扫描机制 (SS2D),它作为该框架内 VSSM 的基石 (Liu et al., 2024)。SS2D 操作示意图如图 4 所示。最初,SS2D 在四个不同方向上扩展性地扫描和排列图像块,创建四个独立的序列。这种创新的四向扫描策略确保特征图中的每个元素都能整合来自各个方向所有其他位置的信息,生成全局感受野,而不会线性地加剧计算复杂度。最后,每个特征序列通过选择性扫描状态空间序列模型 (S6) 进行处理,最终通过扫描合并操作重建 2D 特征图。给定输入特征 z z z,SS2D 的输出特征 z ˉ \bar{z} zˉ 可以表述如下:
z i = e x p a n d ( z , i ) z_{i}=expand(z,i) zi=expand(z,i)
z ˉ i = S 6 ( z i ) \bar{z}{i}=S6(z{i}) zˉi=S6(zi)
z ˉ = m e r g e ( z ˉ 1 , z ˉ 2 , z ˉ 3 , z ˉ 4 ) \bar{z}=m e r g e(\bar{z}{1},\bar{z}{2},\bar{z}{3},\bar{z}{4}) zˉ=merge(zˉ1,zˉ2,zˉ3,zˉ4)
其中 i ∈ { 1 , 2 , 3 , 4 } i\in\{1,2,3,4\} i∈{1,2,3,4} 表示四个扫描方向之一。函数 e x p a n d ( ) expand() expand() 和 m e r g e ( ) merge() merge() 分别对应于扫描扩展和扫描合并操作。S6 块是 SS2D 内的核心 VSSM 算子。该算子通过简洁的隐状态促进一维数组内每个元素与任何先前扫描样本之间的交互。
3.3. 提出的 CSPVSS 模块
在其选择性扫描机制下,VSSM 专注于输入数据中的关键区域,以有效提取与目标相关的特征。然而,直接将 VSSM 作为组件集成到检测框架中可能不是最优解决方案,因为仅从 VSSM 组件导出的特征表示在模型学习期间可能不足。受跨阶段部分 (CSP) 结构 (Wang et al., 2020) 的启发,该结构通过策略性地省略特定连接来提高信息流效率并减少计算负载,CSP 结构已被采用并与 VSSM 组件集成,以创建一个新颖的模块 CSPVSS。CSPVSS 模块的结构如图 5 所示。
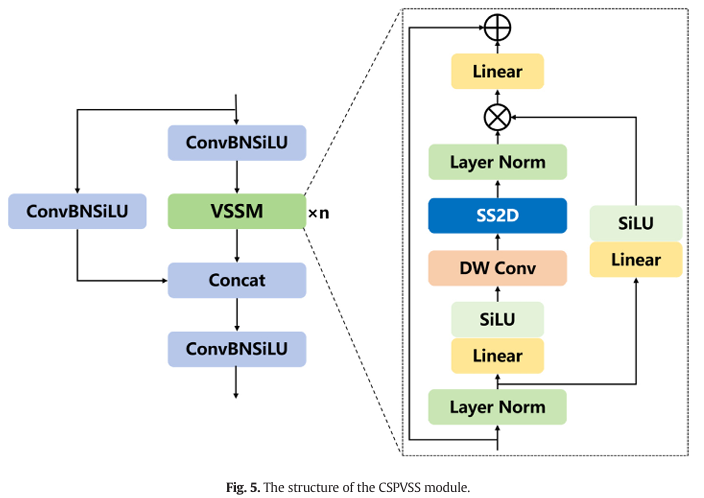
如图 5 所示,CSPVSS 模块采用双分支设计,通过并行处理更有效地从图像中捕获关键且丰富的特征信息。模块的输入被分成两个相等的子输入,每个子输入在其各自的分支内进行独立的特征提取和处理。具体来说,左分支配备了一个标准的卷积模块,包含卷积、批量归一化和 SiLU 激活操作,专注于通过卷积操作直接处理输入特征图以保持局部信息完整性。右分支将一系列标准卷积模块与 VSSM 组件集成在一起,使 2D 选择性扫描机制能够捕获长程依赖关系。两个分支的输出通过沿通道维度连接它们的特征图进行合并,然后通过一个标准卷积组件进行进一步的信息集成,最终输出最终的特征表示。CSPVSS 模块的设计充分利用了不同组件的优势,从而确保了特征信息的完整性。
在 CSPVSS 模块内,VSSM 组件通过对输入特征应用层归一化来启动,作为标准化的预处理步骤。归一化后,特征被分成两个并行的子路径,每个子路径设计用于以不同方式处理特征。第一个子路径促进了特征的简化变换,包括线性变换层和激活函数。同时,第二个子路径更为复杂,使特征经历分层处理过程。这个进展包括线性层、深度可分离卷积和激活函数,最终启动 SS2D 以捕获全局空间特征信息。两个子路径的输出通过逐元素乘法深度合并,然后采用残差连接策略以促进信息流内更深层次的交互,从而增强特征表示的鲁棒性。
3.4. 评估指标
为了严格评估所提出方法的性能,本研究采用了一套评估指标,包括模型参数 (Params)、十亿次浮点运算次数 (GFLOPs)、每秒帧数 (FPS)、平均精度 ( A P , IoU= 0.5 ) (\mathrm{AP},\text{IoU=}0.5) (AP,IoU=0.5) 和平均精度均值 (mAP)。具体来说,参数指标量化了模型的存储需求,提供了对其内存占用的洞察。GFLOPs 衡量计算操作量,反映了模型的处理强度。FPS 间接评估模型的运行速度,表明其是否适合实时应用。AP 是目标检测中的关键性能指标,通过计算精确率-召回率曲线下的面积来捕获模型的精确度。该指标提供了在不同置信度阈值下检测性能的视图。mAP 计算为所有行为类别的 AP 值的算术平均值,提供了模型平均检测精度的整体度量。计算 AP 和 mAP 的公式如下:
P = T P T P + F P \mathrm{P}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FP}} P=TP+FPTP
R = T P T P + F N \mathrm{R}=\frac{\mathrm{TP}}{\mathrm{TP}+\mathrm{FN}} R=TP+FNTP
A P = ∫ 0 1 P ( R ) d R \mathrm{AP}=\int\limits_{0}^{1}\mathrm{P}(\mathrm{R})\mathrm{dR} AP=0∫1P(R)dR
m A P = ∑ c = 1 C A P ( c ) C \mathrm{mAP}=\frac{\sum_{\mathrm{c}=1}^{\mathrm{C}}\mathrm{AP}(\mathrm{c})}{\mathrm{C}} mAP=C∑c=1CAP(c)
在给出的公式中,P 和 R 分别对应精确率和召回率。TP 表示真正例样本的数量,FP 表示假正例样本的数量,FN 表示假负例样本的数量。此外,C 表示被分类的不同攻击行为类别的总数。
4. 实现细节与结果分析
4.1. 实验设置
所提出的 PAB-Mamba-YOLO 模型在配备 Intel i7 CPU (2.90 GHz)、NVIDIA GeForce RTX 3080 GPU (12 GB) 和 32 GB RAM 的桌面工作站计算机上实现。软件环境包括 Ubuntu 20.04 LTS 操作系统、CUDA 11.6、Python 3.8 和 Pytorch 1.12 深度学习框架。表 3 详细说明了模型训练的参数设置。

4.2. 实验结果
使用猪攻击行为的训练集对 PAB-Mamba-YOLO 模型进行训练。所提出的模型中应用了三种类型的损失函数:CloU 损失 ( L l o c ) (\mathrm{L}{\mathrm{l o c}}) (Lloc) 和分布焦点损失 (Ldfl) 用于边界框回归,而 BCE 损失是分类损失 ( L c l s ) (\mathrm{L}{\mathrm{c l}s}) (Lcls) 。训练损失曲线如图 6 所示。可以看
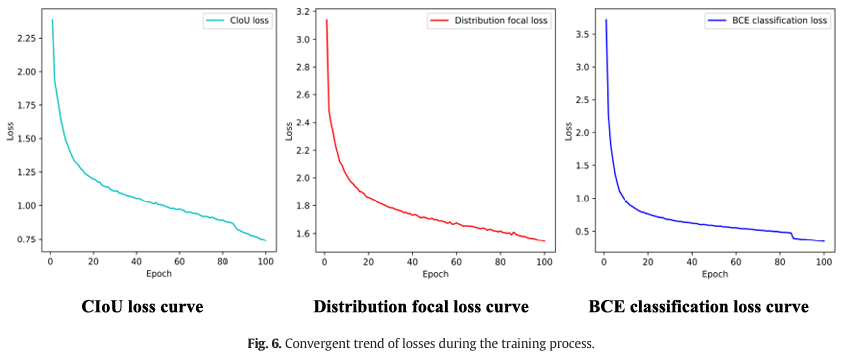
出,所有损失曲线随着训练周期数的增加都呈现出收敛趋势,然后在训练后期逐渐变得稳定。 L l o c , L d f l \mathrm{L}{\mathrm{l o c}},~\mathrm{L}{\mathrm{d f l}} Lloc, Ldfl 和 L c l s \mathrm{L}_{\mathrm{c l}s} Lcls 最终分别收敛到大约 0.693、1.544 和 0.348。
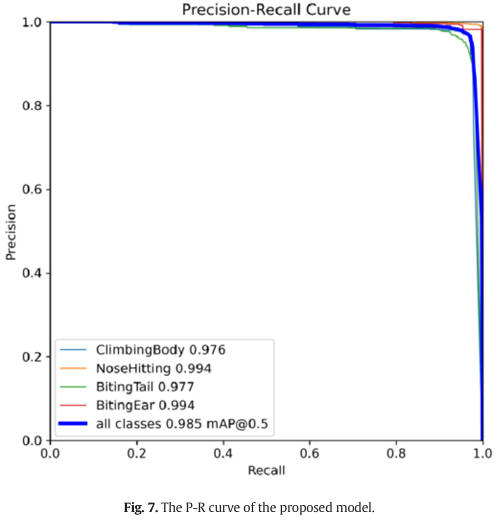
图 7 说明了所提出模型在测试集上的 P-R 曲线。如图 7 所示,PAB-Mamba-YOLO 模型的训练达到了良好的拟合,从 P-R 曲线的平衡点接近 1 可以明显看出,这强调了模型执行有效检测任务的能力。所提出模型的实验结果表明,爬跨身体行为、鼻部撞击行为、咬尾行为和咬耳行为的 AP 分别为 0.976、0.994、0.977 和 0.994。作为所有四种攻击行为类别的综合评估,mAP 达到了 0.985。

断奶仔猪在不同时期攻击行为检测的可视化结果如图 8 所示。可以观察到,断奶仔猪间的攻击行为在断奶后早期和后期阶段都存在,并且所提出的模型能够正确检测不同时期断奶仔猪的不同攻击行为。

图 9 展示了在远景和近景视图中的检测结果可视化,而图 10 显示了在密集场景中的检测结果。从这些图示可以明显看出,所提出的模型在一系列具有挑战性的场景中表现出值得称赞的性能,在密集场景中对于变化的视图和部分遮挡等干扰因素展示了强大的鲁棒性。

4.3. 消融研究
为了验证优化组件对所提出的 PAB-Mamba-YOLO 模型的效率,在相同的测试集下进行了消融实验。在实验中,原始的 YOLOv8n 作为比较的基线。将 CSP、VSSM 和 CSPVSS 分别集成到基线模型中以评估其性能。消融实验的比较结果如表 4 所示。

很明显,所采用的优化组件会影响模型的检测性能。当 PAB-Mamba-YOLO 模型采用 CSP 组件时,其 mAP 与基线模型保持相当,但 Params 和 GFLOPs 得到了显著优化。虽然将 VSSM 组件集成到 PAB-Mamba-YOLO 模型中确实导致 mAP 提高了 0.41%,但这种改进伴随着参数数量的不良增加以及 FPS 的同步下降。相比之下,通过结合 CSP 和 VSSM 的优势而开发的 CSPVSS 组件,在集成到 PAB-Mamba-YOLO 模型中时,通过显著提高检测精度和优化模型复杂度,展示了更优越的性能。具体来说,mAP 和 FPS 分别达到 0.985 和 69,分别优于基线模型 0.51% 的 mAP 和 1.47% 的 FPS。同时,Params 和 GFLOPs 指标分别优化到 2.63 和 7.2,与基线模型相比,分别 favorable 减少了 12.62% 和 11.11%。因此,CSPVSS 组件成为增强 PAB-Mamba-YOLO 模型性能的更实用选择。
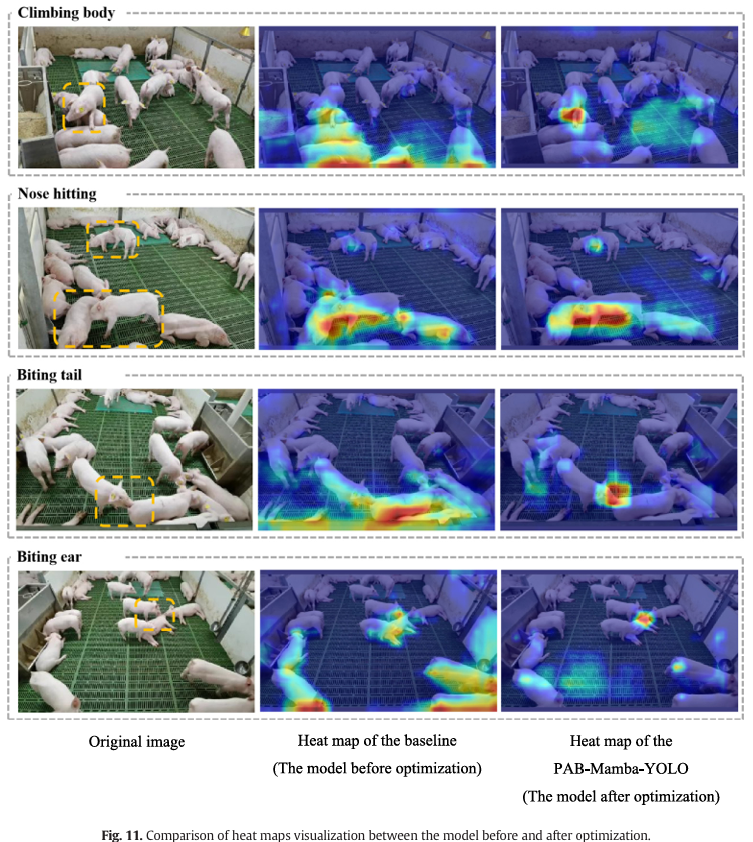
为了直观展示优化前后模型的对比,使用 Grad-CAM (Selvaraju et al., 2017) 创建了热力图来检查基线模型和提出的 PAB-Mamba-YOLO 模型关注的感兴趣区域。图 11 展示了两者模型的可视化热力图。如图 11 所示,经过增强的 PAB-Mamba-YOLO 模型更关注攻击行为的关键区域,从而为该部分分配了更高的权重。相比之下,基线模型似乎更受其他非关键仔猪的影响,并且未能充分抑制图像中的无关信息。
消融实验结果证实了所提出的优化对增强模型性能的积极影响。利用基于 Mamba 框架的设计,PAB-Mamba-YOLO模型有效地捕获了位置信息的局部和全局融合特征,显著提升了其在检测断奶仔猪攻击行为方面的整体性能。
4.4. 与其他模型的比较
将几种主流模型与 PAB-Mamba-YOLO 进行比较,以评估所提出模型的优越性。比较模型包括基于 CNN 的模型和基于 Transformer 的模型。选择 Faster R-CNN (Ren et al., 2016)、VFnet (Zhang et al., 2021)、Ddod (Chen et al., 2021)、YOLOXs (Ge et al., 2021)、RTMDet (Lyu et al., 2022)、YOLOv8n (Jocher et al., 2023) 和 YOLOv10n (Wang et al., 2024b) 作为比较的基于 CNN 的模型。选择的基于 Transformer 的比较模型包括 Swin Transformer (Liu et al., 2021)、Deformable DETR (Zhu et al., 2020b)、DINO (Zhang et al., 2022) 和 RTDETR (Zhao et al., 2024b)。此外,最近报道的基于 Mamba 的模型 Mamba-YOLO (Wang et al., 2024c) 也被添加到实验中以进行全面的比较。比较实验中的所有模型都在相同的测试集上进行评估。
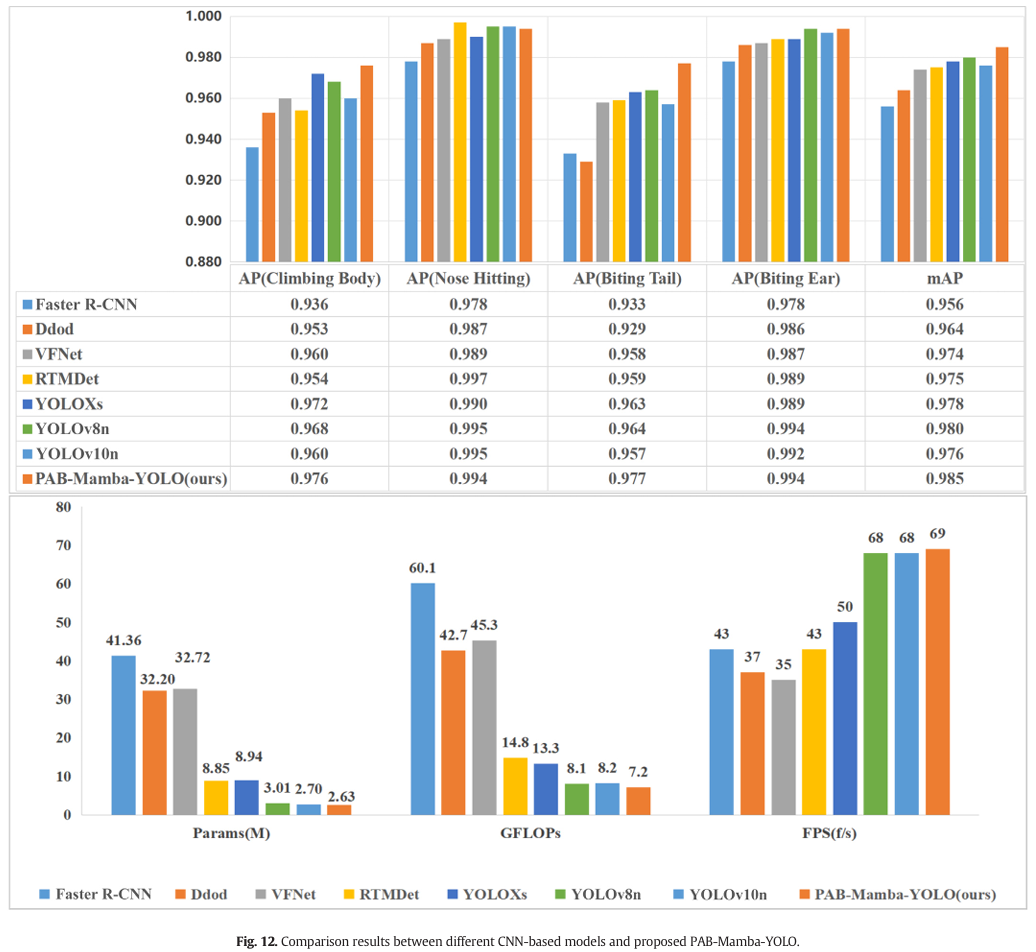
图 12 说明了不同基于 CNN 的模型与所提出的 PAB-Mamba-YOLO 在断奶仔猪攻击行为检测方面的比较结果。如图 12 所示,先进的 YOLO 系列,包括 YOLOX、YOLOv8n 和 YOLOv10n,分别表现出令人印象深刻的 mAP,分别为 0.978、0.980 和 0.976。然而,它们仍然低于所提出的 PAB-Mamba-YOLO,后者实现了更高的 mAP 0.985。值得注意的是,所提出的模型在 mAP 上分别超过了 Faster R-CNN、Ddod 和 VFNet 3.0%、2.2% 和 1.1%。同时,它们的 Params 和 GFLOPs 意外地比 PAB-Mamba-YOLO 模型高出数倍。YOLOv8n、YOLOv10n 和 PAB-Mamba-YOLO 在 FPS 上表现相当,但 PAB-Mamba-YOLO 在 mAP、Params 和 GFLOPs 方面展现出更大的优势。
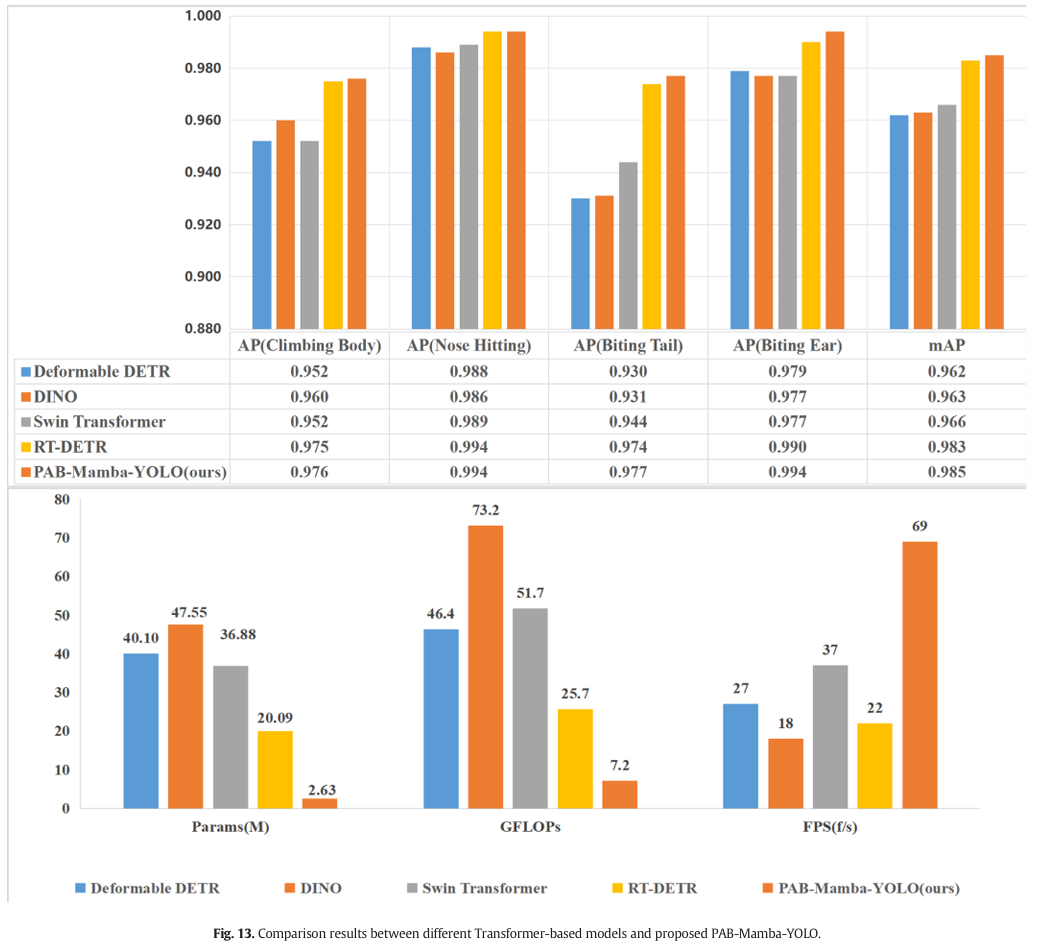
图 13 展示了不同基于 Transformer 的模型与所提出的 PAB-Mamba-YOLO 在断奶仔猪攻击行为检测方面的比较结果。如图 13 所示,RT-DETR 脱颖而出,在 mAP、Params 和 GFLOPs 方面超过了 DINO、Deformable DETR 和 Swin Transformer。尽管如此,RT-DETR 在 mAP 上仍落后于所提出的模型 0.2%,同时与所提出的模型相比,其 Params 和 GFLOPs 水平也处于不利的升高状态。此外,实验中的基于 Transformer 的模型消耗的 Params 和 GFLOPs 比所提出模型所需的多出数倍。在检测速度方面,以 FPS 衡量,所提出的 PAB-Mamba-YOLO 显著超过了 Swin Transformer、Deformable DETR、DINO 和 RT-DETR。
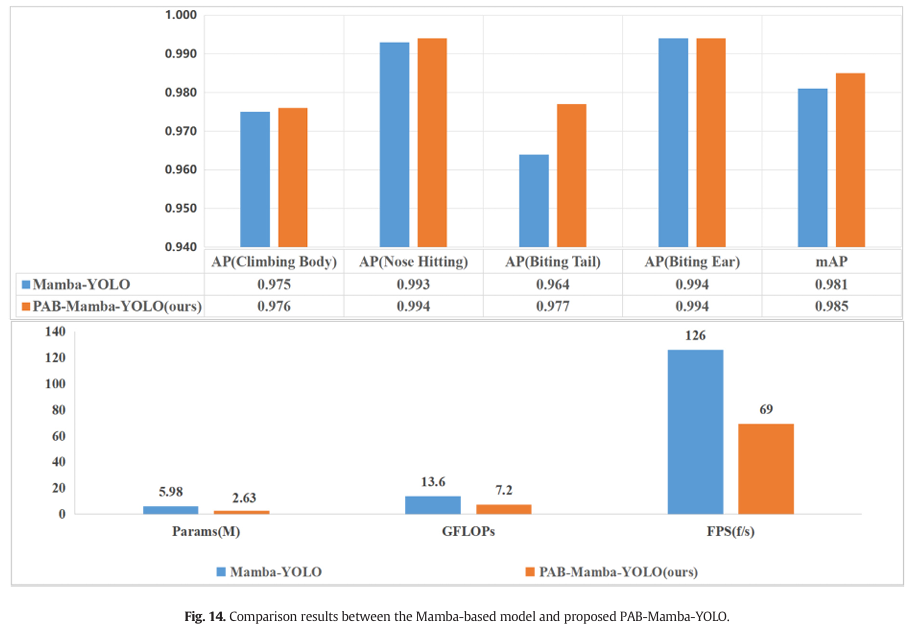
图 14 显示了基于 Mamba 的模型与所提出的 PAB-Mamba-YOLO 模型在断奶仔猪攻击行为检测方面的比较结果。可以看出,所提出的模型表现出 superior 的性能,与 Mamba-YOLO 模型相比,mAP 高出 0.4%。同时,所提出的 PAB-Mamba-YOLO 在模型复杂度上大幅降低,与 Mamba-YOLO 模型相比,Params 减少了 56.0%,GFLOPs 减少了 47.1%。尽管 Mamba-YOLO 模型具有更快的 FPS,但 PAB-Mamba-YOLO 模型达到的 69 FPS 足以满足检测断奶仔猪攻击行为的实时检测要求。
比较实验表明,所提出的模型在性能和效率方面提供了竞争优势,使其成为检测断奶仔猪攻击行为的合适选择。
5. 讨论
近年来,深度学习在智能畜牧业中展现出强大的能力。大多数现有工作往往更侧重于监测猪的基本行为,如站立、躺卧、坐立、采食和饮水。然而,很少有研究深入调查猪的攻击行为,特别是生猪育种中断奶仔猪的攻击行为。先前相关工作中报道的方法将猪的攻击识别纯粹视为分类任务 (Liu et al., 2020; Chen et al., 2020; Ji et al., 2023),这仅能确定图像中是否存在攻击事件。然而,这些工作无法确定攻击行为发生在图像中的哪个位置以及图像内行为的具体类别,因此无法有效指导后续对这些异常仔猪的育种管理。与先前研究相反,本研究开发了 PAB-Mamba-YOLO 模型用于断奶仔猪攻击行为检测。该模型不仅能够定位并记录攻击行为在图像中发生的位置坐标,还能基于这些坐标勾勒出攻击行为。同时,该模型能够对勾勒区域内仔猪攻击行为的具体类别进行分类。图像中检测到的位置和仔猪攻击行为的详细类别信息将有助于指导生猪育种筛选和管理。
由于模型内置的机制,当前的一些方法 (Gao et al., 2023; Ji et al., 2023) 可能由于在空间和时间通道处理特征而引入大量冗余信息,导致过度的计算负担,从而影响实时能力。所提出的模型应用了一个有效的基于 Mamba 的框架来检测仔猪的攻击行为。最优的模型复杂度和实时检测速度(FPS)表明其适合实际应用。
这项工作是率先探索将新兴技术 Mamba 集成到 AI 辅助育种中用于断奶仔猪攻击行为监测的开创性研究。作为所提出模型的关键部分,CSPVSS 模块无缝融合了局部信息和长程关系信息。这种集成设计策略性地旨在促进这两种不同类型信息的协同融合,通过其选择性扫描机制增强了模型熟练处理关键信息的能力。这种信息处理能力的增强反过来又转化为模型整体性能的提高。
最近的工作 (Wang et al., 2024c) 也尝试应用基于 Mamba 的方法来解决通用目标检测的问题。Wang 等人 (2024c) 的发现与本研究的结果一致,这进一步证明了 Mamba 融合解决方案对于目标检测任务的可行性。与上述工作不同,所提出的方法专门定制了一个 CSPVSS 模块,其中采用了 CSP 结构来增强信息流的效率,并集成了 VSSM 组件以实现 2D 选择性扫描机制来捕获长程依赖关系。CSPVSS 模块结构简单但高效,使其在保持较低模型复杂度的同时具有更高的检测性能。这对于在边缘设备上部署模型并使其在实际猪场场景中应用具有重要意义。
虽然 PAB-Mamba-YOLO 模型能够初步检测断奶仔猪的攻击行为,但仍然存在某些干扰因素,例如遮挡、图像模糊和异常姿势,导致少数检测失败,如图 15 所示。应注意并分析这些导致检测失败的因素。首先,在商业生猪育种场,仔猪通常彼此靠近放置,通常采用每栏近二十头仔猪的高密度饲养模式。在这种场景下,很容易发生漏检,因为仔猪的关键部位,包括头部、尾巴、脚和身体,可能被其他仔猪或自身遮挡。因此,无法充分提取可用特征,导致模型无法成功检测图像中的攻击行为。其次,由于拍摄过程中仔猪移动或相机抖动,捕获的图像可能过度模糊。这导致用于检测攻击行为的判别性特征有限,可能导致漏检。第三,在仔猪表现出攻击行为期间,它们的身体可能会发生扭曲,偶尔导致异常姿势,这反过来又导致漏检实例增加。后续研究应通过优化模型的鲁棒性和丰富各种条件下的样本来应对这些挑战。

从更广泛的猪品种和不同的养殖环境获取样本将增加数据集的多样性,从而增强模型的泛化性能。然而,由于猪瘟影响导致的严格准入限制,本研究的数据覆盖范围不够广泛。在研究的下一阶段,将记录来自不同品种和饲养场景的更广泛数据,以丰富数据集并进一步增强模型的泛化能力。
6. 结论
检测断奶仔猪的攻击行为对于监测生猪育种中具有有害社会接触的仔猪至关重要。通过结合 Mamba 和 YOLO,本工作提出了一种混合模型 PAB-Mamba-YOLO,用于高效检测断奶仔猪的攻击行为。从本研究中可以得出以下结论。
(1) 所设计的 CSPVSS 模块在检测断奶仔猪攻击行为方面被证明是有效的。
(2) PAB-Mamba-YOLO 模型不仅能够准确定位断奶仔猪攻击行为在图像中发生的区域,还能区分其具体类别。

图 11. 优化前后模型热力图可视化对比。

图 12. 不同基于 CNN 的模型与提出的 PAB-Mamba-YOLO 的比较结果。
(3) 与其他实验方法相比,PAB-Mamba-YOLO 模型实现了良好的检测性能和合理的模型复杂度,从而证明了所提出模型在有效监测断奶仔猪攻击行为方面的优越性和适用性。
未来,所提出的模型将被移植到边缘设备上,指导猪场 AI 系统随时随地自动监测断奶仔猪的攻击行为。此外,将收集来自不同品种仔猪和不同养殖环境的更多样本,以增强模型的鲁棒性和泛化能力。希望这项研究能够推动精准畜牧业育种领域的发展,并为该领域未来的研究和应用提供一个有前景的基础。