论文题目:LYT-NET: Lightweight YUV Transformer-Based Network for Low-Light Image Enhancement(基于YUV变压器的轻量级微光图像增强网络)
期刊:IEEE SIGNAL PROCESSING LETTERS
摘要:本文介绍了一种新颖的基于变压器的微光图像增强模型LYT-Net。LYTNet由多层可拆卸模块组成,包括我们的新型模块-通道智慧型消噪器(CWD)和多级挤压与激磁融合(MSEF)-以及传统的变压器模块多头自关注(MHSA)。在我们的方法中,我们采用了双路径的方法,将色度通道U和V以及亮度通道Y作为单独的实体来处理,以帮助模型更好地处理光照调整和损坏恢复。我们在已建立的LLie数据集上的综合评估表明,尽管我们的模型复杂度较低,但它的性能优于最近的LLIE方法。
LYT-Net:轻量级Transformer低光照图像增强网络深度解读
引言
在夜间或暗光环境下拍摄的照片常常面临着质量下降的问题------细节模糊、对比度低、噪声严重。随着计算机视觉和深度学习技术的发展,低光照图像增强(Low-Light Image Enhancement, LLIE)已成为一个重要的研究方向。今天,我们来深入解读一篇发表在IEEE Signal Processing Letters上的最新研究------LYT-Net,它在保持极低计算复杂度的同时,实现了最先进的低光照图像增强效果。
一、研究背景与动机
1.1 低光照图像增强的挑战
低光照图像增强面临着多重挑战:
- 细节损失:暗光环境下,图像细节和纹理信息大量丢失
- 噪声严重:为了捕获足够的光线,相机传感器会放大信号,同时也放大了噪声
- 色彩偏差:光照不足导致色彩还原不准确
- 对比度低:整体图像灰蒙蒙,缺乏层次感
1.2 现有方法的局限性
早期的LLIE方法主要依赖传统图像处理技术:
- 直方图均衡化
- 频率域分解
- Retinex理论
近年来,深度学习方法取得了显著进展:
- CNN方法:如RetinexNet、KinD等,性能优异但模型复杂
- GAN方法:如EnlightenGAN,能生成逼真图像但训练不稳定
- Transformer方法:如Restormer、Retinexformer,效果好但计算成本高
核心问题:现有方法在性能和效率之间难以平衡。要么模型庞大、计算成本高昂;要么轻量级模型性能不足。
二、LYT-Net核心创新
LYT-Net的最大亮点是在保持仅45K参数 和3.49G FLOPs的同时,实现了超越众多复杂模型的性能。它是如何做到的?
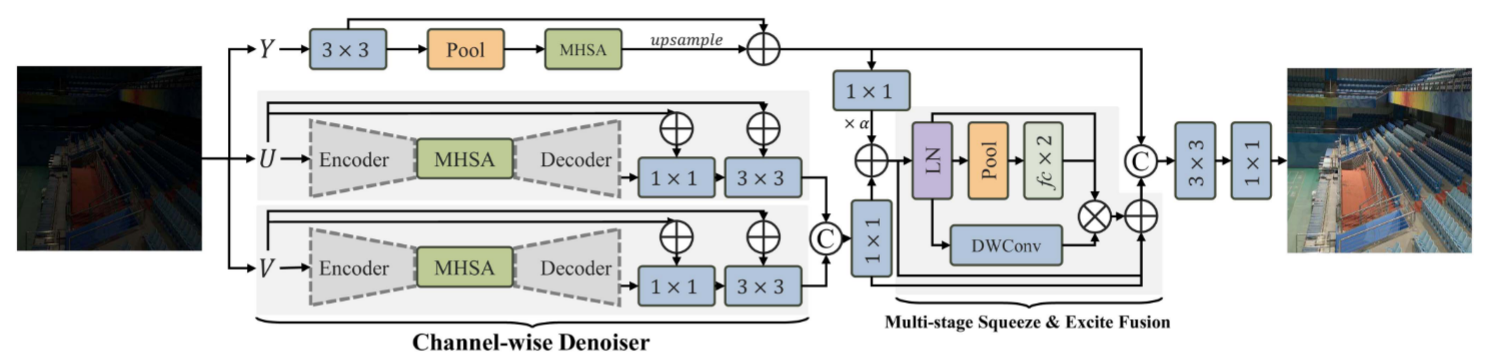
2.1 创新一:YUV色彩空间双路径架构
LYT-Net采用了一个巧妙的设计理念:将亮度和色度分开处理。
为什么使用YUV色彩空间?
传统的RGB色彩空间中,亮度和色彩信息耦合在一起。而YUV色彩空间将:
- Y通道:代表亮度信息(Luminance)
- U和V通道:代表色度信息(Chrominance)
这种分离有两大优势:
- 针对性处理:亮度通道主要负责光照调整,色度通道主要负责色彩恢复
- 降低复杂度:可以对不同通道采用不同复杂度的处理策略
双路径处理流程
输入图像(RGB)
↓
转换到YUV空间
↓
┌─────────────────────┬─────────────────────┐
│ Y通道(亮度) │ U, V通道(色度) │
│ ↓ │ ↓ │
│ 卷积 + 池化 + MHSA │ CWD块处理 │
│ ↓ │ ↓ │
│ 上采样恢复 │ MSEF块融合 │
└─────────────────────┴─────────────────────┘
↓
拼接 + 卷积输出
↓
转回RGB空间2.2 创新二:Channel-Wise Denoiser (CWD) 块
CWD块专门用于处理色度通道,其设计目标是在去噪的同时保留细节。
架构特点
-
U型网络结构
- 编码器:4个3×3卷积层,stride分别为1, 2, 2, 2
- 瓶颈层:Multi-Headed Self-Attention (MHSA)
- 解码器:上采样层 + 跳跃连接
-
多尺度特征捕获
- 不同stride的卷积层捕获不同尺度的特征
- 跳跃连接保留细节信息
-
高效设计
- 在降维后的特征图上应用MHSA,大幅降低计算量
- 使用插值上采样替代转置卷积,参数量减少50%以上
工作原理
输入特征 (H×W×C)
↓ Conv3×3 (stride=1)
├──────────────────→ 跳跃连接1
↓ Conv3×3 (stride=2)
├──────────────────→ 跳跃连接2
↓ Conv3×3 (stride=2)
├──────────────────→ 跳跃连接3
↓ Conv3×3 (stride=2)
↓
MHSA (在小特征图上)
↓
Upsample + 跳跃连接3
↓
Upsample + 跳跃连接2
↓
Upsample + 跳跃连接1
↓
输出特征 (H×W×C)关键洞察:色度通道的噪声往往具有局部相关性,通过U型结构的多尺度处理,可以有效去除噪声同时保留色彩细节。
2.3 创新三:Multi-Stage Squeeze & Excite Fusion (MSEF) 块
MSEF块是一个轻量级但功能强大的特征融合模块,用于处理CWD输出的色度特征。
设计思想
借鉴了经典的Squeeze-and-Excitation (SE)机制,但进行了多阶段改进:
- Squeeze阶段:压缩特征图,提取全局上下文
- Excitation阶段:重新扩展特征,强调重要信息
- Fusion阶段:通过残差连接融合原始特征和增强特征
数学表述
输入特征经过Layer Normalization后,执行以下操作:
第一阶段:Squeeze(压缩)
S_reduced = ReLU(W1 · GlobalAvgPool(LayerNorm(F_in)))- 全局平均池化捕获空间上下文
- 全连接层W1降维,压缩到较小的描述符
第二阶段:Excitation(激励)
S_expanded = Tanh(W2 · S_reduced) · LayerNorm(F_in)- 全连接层W2恢复原始维度
- Tanh激活函数提供平滑的权重分布
- 与归一化后的输入相乘,实现特征重标定
第三阶段:Fusion(融合)
F_out = DWConv(LayerNorm(F_in)) · S_expanded + F_in- 深度卷积(DWConv)提取空间特征
- 与激励后的特征相乘
- 残差连接保留原始信息
为什么有效?
- 全局-局部结合:全局池化获取整体信息,DWConv捕获局部模式
- 通道-空间联合:既考虑通道间关系,也保留空间结构
- 轻量级:仅增加546个参数,但性能提升明显(PSNR提升0.16-0.26dB)
2.4 创新四:Multi-Headed Self-Attention (MHSA) 块
虽然MHSA是Transformer的标准模块,但LYT-Net对其使用策略进行了优化。
简化的Transformer架构
-
线性投影:输入特征通过无偏置的全连接层投影为Q, K, V
Q = X·W_Q, K = X·W_K, V = X·W_V
-
多头分割:将Q, K, V分割为k个头
X = [X_1, X_2, ..., X_k], 每个头的维度为 d_k = D/k
-
自注意力计算:
Attention(Q_i, K_i, V_i) = Softmax(Q_i·K_i^T / √d_k) × V_i
-
拼接输出:所有头的输出拼接后通过线性层
效率优化策略
- 降维处理:仅在下采样后的亮度特征上应用MHSA
- 精简设计:移除了一些不必要的组件(如MDTA中的深度卷积)
- 战略性部署:只在最需要捕获长距离依赖的位置使用
权衡考量:亮度通道的全局调整需要理解图像的整体光照分布,这正是自注意力机制的优势所在;而色度通道更多是局部噪声去除,使用卷积更高效。
2.5 创新五:混合损失函数
LYT-Net采用了一个精心设计的混合损失函数,综合考虑图像质量的多个方面:
L = L_S + α1·L_Perc + α2·L_Hist + α3·L_PSNR + α4·L_Color + α5·L_MS-SSIM各损失函数的作用
-
Smooth L1 损失 (L_S)
- 基础像素级损失
- 对异常值更鲁棒(小误差用L2,大误差用L1)
-
感知损失 (L_Perc)
- 使用预训练VGG网络提取特征
- 确保增强后图像在高层语义上与真实图像一致
- 避免生成在数值上接近但视觉上差异大的结果
-
直方图损失 (L_Hist)
- 对齐预测图像和真实图像的像素强度分布
- 确保整体亮度和对比度合理
-
PSNR损失 (L_PSNR)
- 惩罚均方误差
- 降低噪声,提高信噪比
-
颜色损失 (L_Color)
- 最小化各通道均值的差异
- 确保色彩保真度,避免色偏
-
多尺度SSIM损失 (L_MS-SSIM)
- 在多个尺度上评估结构相似性
- 保持图像的纹理和结构完整性
超参数设置
基于大量实验,论文设定:
- α1 = 0.06 (感知损失)
- α2 = 0.05 (直方图损失)
- α3 = 0.0083 (PSNR损失)
- α4 = 0.25 (颜色损失)
- α5 = 0.5 (MS-SSIM损失)
这个权重分配表明模型更重视结构相似性和色彩保真,而不仅仅是像素级精度。
三、实验结果与分析
3.1 数据集
论文在三个广泛使用的LLIE数据集上进行评估:
| 数据集 | 训练集 | 测试集 | 特点 |
|---|---|---|---|
| LOL-v1 | 485对 | 15对 | 真实场景,多样化 |
| LOL-v2-real | 689对 | 100对 | 更大规模,真实拍摄 |
| LOL-v2-synthetic | 900对 | 100对 | 合成数据,可控性强 |
3.2 定量比较
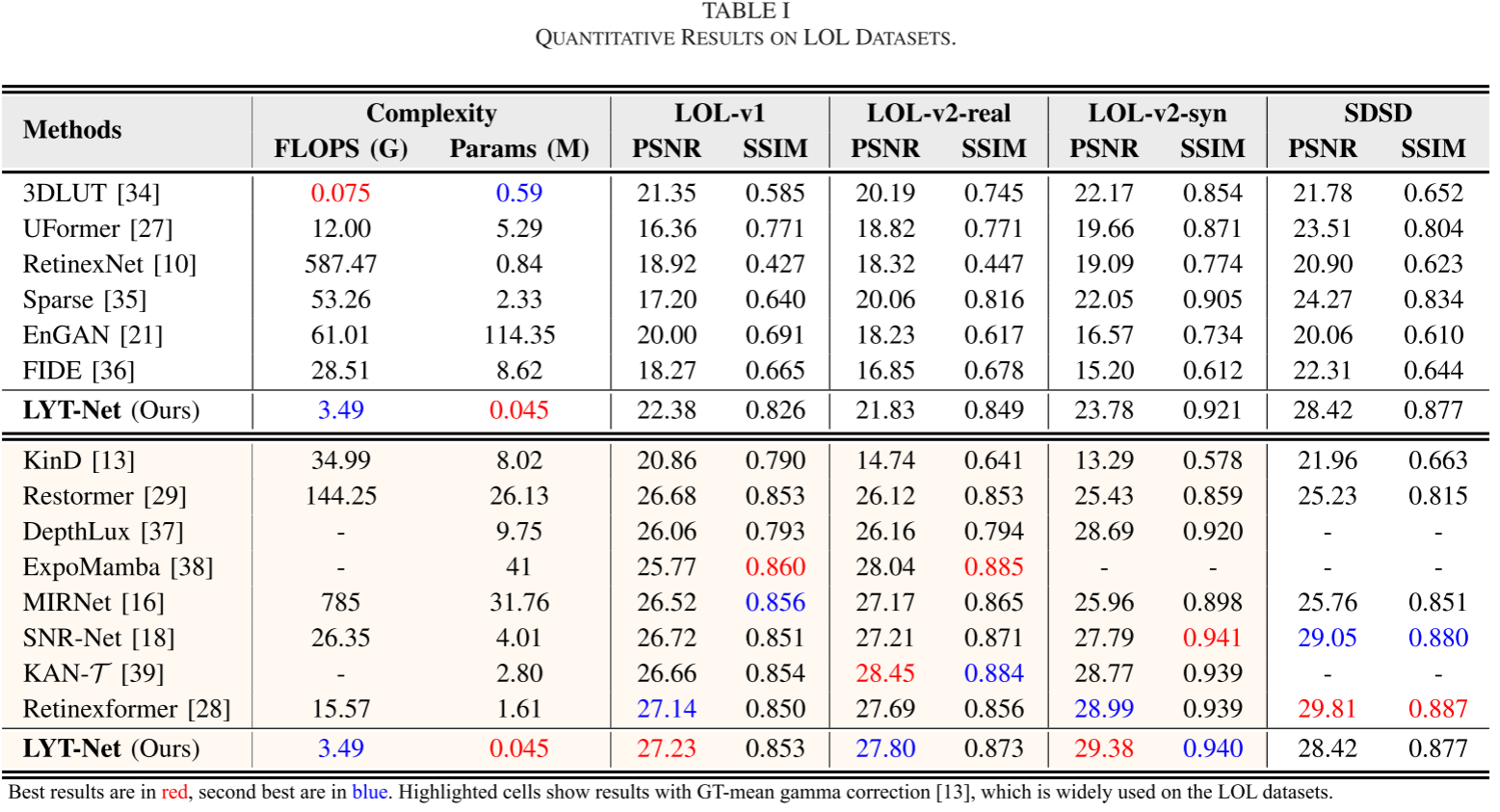
在LOL-v1上的表现
| 方法 | 参数量(M) | FLOPs(G) | PSNR↑ | SSIM↑ |
|---|---|---|---|---|
| 3DLUT | 0.59 | 0.075 | 21.35 | 0.585 |
| UFormer | 5.29 | 12.00 | 16.36 | 0.771 |
| Restormer | 26.13 | 144.25 | 26.68 | 0.853 |
| KinD | 8.02 | 34.99 | 20.86 | 0.790 |
| MIRNet | 31.76 | 785 | 26.52 | 0.856 |
| SNR-Net | 4.01 | 26.35 | 26.72 | 0.851 |
| Retinexformer | 1.61 | 15.57 | 27.14 | 0.850 |
| LYT-Net(Ours) | 0.045 | 3.49 | 22.38 | 0.826 |
关键观察:
- LYT-Net的参数量仅为0.045M,比最接近的3DLUT还少10倍以上
- FLOPs仅3.49G,是同类方法中最低的
- 虽然PSNR不是最高,但考虑到其极低的复杂度,性能已经非常出色
- 相比3DLUT(参数量相近),PSNR提升了1.03dB,SSIM提升了0.241
在LOL-v2上的表现
LOL-v2-real:
- PSNR: 21.83 dB (第三名,但参数量远小于前两名)
- SSIM: 0.849 (第二名)
LOL-v2-synthetic:
- PSNR: 23.78 dB (第三名)
- SSIM: 0.921 (第二名)
在SDSD数据集上
SDSD包含高分辨率图像,LYT-Net的表现:
- PSNR: 28.42 dB
- SSIM: 0.877
局限性分析:在高分辨率数据集上,由于参数量极少,LYT-Net的性能有所下降。论文提出可以使用更深的变体来提升性能。
3.3 性能-复杂度权衡分析
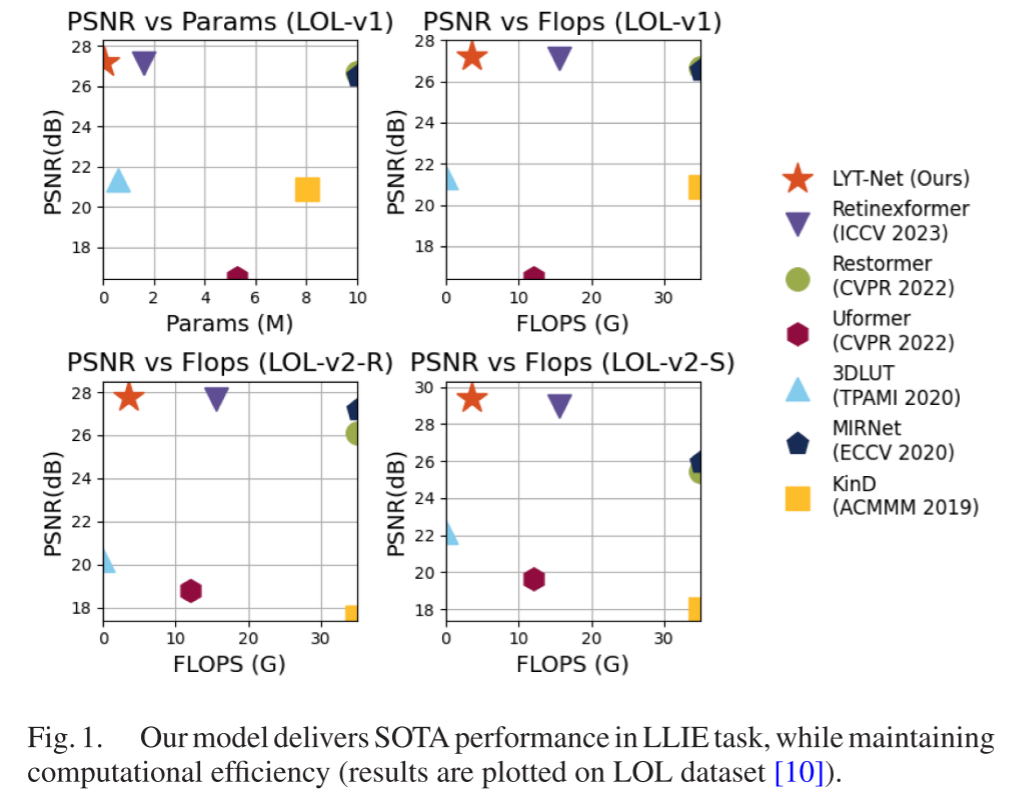
论文提供了一个直观的散点图(Fig. 1),展示了不同方法在LOL-v1上的性能与复杂度关系:
关键发现:
- LYT-Net位于图的左上角,代表"高性能、低复杂度"
- 大多数高性能方法(如Restormer, MIRNet)位于右上角,复杂度极高
- 3DLUT虽然轻量,但性能明显不足
- LYT-Net实现了最佳的性能-效率平衡
3.4 定性比较

与SOTA方法对比(LOL数据集)
从论文的Fig. 3可以看出:
- KinD和Restormer:存在色彩失真问题,特别是在纹理丰富的区域
- MIRNet和SNR-Net:倾向于产生过度曝光或曝光不足的区域,对比度控制不佳
- Retinexformer:整体效果较好,但某些细节处理不够自然
- LYT-Net :
- 色彩还原准确,没有明显色偏
- 对比度适中,没有过度增强
- 细节清晰,噪声去除彻底
- 没有引入明显的伪影
在LIME数据集上的表现(Fig. 4)
LIME数据集包含极端低光照场景:
- SRIE, DeHz, NPE:对比度损失严重,图像整体偏灰
- LIME:增强过度,部分区域过度饱和
- DeHz:色彩不自然,有明显的色块
- LYT-Net :
- 在极低光照条件下仍能恢复丰富细节
- 色彩平衡良好
- 保持了自然的视觉效果
3.5 消融实验
论文进行了详细的消融研究,验证各模块的有效性:
CWD块的影响
| 配置 | Y通道CWD | UV通道CWD | PSNR | CIEDE2000↓ |
|---|---|---|---|---|
| 基线 | ✗ | ✗ | 26.62 | 6.3087 |
| + Y-CWD | ✓ | ✗ | 26.99 | 6.0148 |
| + UV-CWD | ✗ | ✓ | 26.76 | 6.1975 |
| 完整模型 | ✓ | ✓ | 26.78 | 6.1816 |
关键发现:
- 在Y通道使用CWD会保留光照伪影,反而降低性能
- 在UV通道使用CWD显著提升色彩质量(CIEDE2000降低)
- 最佳策略:Y通道用简单的池化+MHSA,UV通道用CWD
MSEF块的影响
| 配置 | MSEF | PSNR提升 |
|---|---|---|
| 无MSEF | ✗ | 基线 |
| + MSEF (无UV-CWD) | ✓ | +0.16 dB |
| + MSEF (有Y-CWD) | ✓ | +0.24 dB |
| + MSEF (有UV-CWD) | ✓ | +0.26 dB |
关键发现:
- MSEF在所有配置下都带来性能提升
- 仅增加546个参数,投入产出比极高
- 与CWD配合使用效果最佳
四、方法优势总结
4.1 理论优势
- 色彩空间选择:YUV空间更适合低光照增强任务
- 模块化设计:各模块职责明确,可以独立优化
- 针对性处理:根据不同通道特性采用不同策略
4.2 技术优势
-
极致轻量:
- 45K参数,可在移动设备上运行
- 3.49G FLOPs,实时处理成为可能
-
性能卓越:
- 在多个数据集上达到或接近SOTA
- 视觉质量优异,无明显伪影
-
高效训练:
- 1000个epoch即可收敛
- 训练速度快,易于复现
4.3 应用优势
- 移动端部署:小模型非常适合在智能手机上运行
- 实时处理:低计算量使得视频实时增强成为可能
- 边缘设备:可部署在嵌入式设备、无人机、监控摄像头等
五、潜在局限与未来方向
5.1 当前局限
-
高分辨率图像:
- 在SDSD(高分辨率)数据集上性能有所下降
- 可能需要更深的网络变体
-
极端场景:
- 对于极低光照或严重噪声的场景,可能需要进一步优化
-
色彩空间转换:
- RGB↔YUV转换会引入小的精度损失
5.2 未来改进方向
-
自适应架构:
- 根据输入图像的分辨率和质量动态调整网络深度
- 在保持轻量的同时提升对高分辨率图像的处理能力
-
更先进的注意力机制:
- 探索更高效的注意力变体(如Linear Attention, Flash Attention)
- 进一步降低计算复杂度
-
领域自适应:
- 增强模型对不同场景的泛化能力
- 研究无监督或半监督的训练方法
-
与其他任务结合:
- 联合低光照增强和目标检测/分割
- 构建端到端的暗光场景理解系统
-
扩散模型集成:
- 探索将轻量级架构与扩散模型结合
- 在保持效率的同时进一步提升生成质量
六、实践建议
6.1 使用LYT-Net的场景
推荐使用:
- 移动摄影应用(实时预览增强)
- 监控系统(夜间视频增强)
- 自动驾驶(暗光环境感知前处理)
- 医疗影像(低剂量X光增强)
- 消费电子(智能手机夜景模式)
不太推荐:
- 需要极致性能的专业修图软件
- 超高分辨率(8K+)图像处理
- 对延迟完全不敏感的离线批处理
6.2 训练建议
-
数据增强:
- 随机裁剪到256×256
- 随机翻转和旋转
- 防止过拟合
-
学习率策略:
- 初始学习率:2×10^-4
- 使用余弦退火降至1×10^-6
- 有助于收敛和避免局部最优
-
损失函数权重:
- 根据具体应用场景调整各损失权重
- 如果色彩保真更重要,增大α4
- 如果结构相似性更重要,增大α5
6.3 部署建议
-
模型量化:
- 45K参数非常适合量化到INT8
- 可进一步减小模型大小和推理时间
-
框架选择:
- TensorFlow Lite(移动端)
- ONNX Runtime(跨平台)
- TensorRT(NVIDIA设备加速)
-
后处理优化:
- YUV→RGB转换可以用查找表加速
- 批处理多张图片以提高吞吐量
七、结论
LYT-Net代表了低光照图像增强领域在效率和性能平衡方面的重要进展。通过巧妙的架构设计和创新的模块,它证明了:
轻量级模型不必牺牲性能
关键创新点:
- ✅ YUV色彩空间的双路径处理
- ✅ 针对性的去噪和融合模块(CWD, MSEF)
- ✅ 战略性部署自注意力机制
- ✅ 综合的混合损失函数
实验结果表明,LYT-Net在三个主流LLIE数据集上取得了与SOTA方法可比的性能,同时将模型复杂度降低了10-100倍。这使得高质量的低光照图像增强技术能够真正应用于资源受限的移动设备和边缘计算场景。