目录
- [1 Anaconda on Linux](#1 Anaconda on Linux)
- [2 Spark Local模式部署](#2 Spark Local模式部署)
- [3 StandAlone环境](#3 StandAlone环境)
-
- [3.1 Standalone架构](#3.1 Standalone架构)
- [3.2 StandAlone部署](#3.2 StandAlone部署)
- [3.3 StandAlone测试](#3.3 StandAlone测试)
- [3.4 Spark程序运行层次结构](#3.4 Spark程序运行层次结构)
- [3.5 StandAlone的原理](#3.5 StandAlone的原理)
- [3.6 Spark角色在StandAlone中的分布](#3.6 Spark角色在StandAlone中的分布)
- [3.7 StandAlone如何提交Spark应用](#3.7 StandAlone如何提交Spark应用)
- [4 StandAlone HA](#4 StandAlone HA)
1 Anaconda on Linux
上传到linux

sh执行
回车
空格跳过
输入yes接收
输入Anaconda安装目录
等待安装
安装完成后输入yes进行初始化
退出当前终端

再进入终端
看到这个base开头表明安装好了
base是默认的虚拟环境
创建虚拟环境
conda create -n pyspark python=3.8切换环境
2 Spark Local模式部署
上传Spark安装包

解压缩
配置环境变量
配置Spark有如下五个环境变量需要设置
SPARK_HOME:表示Spark安装路径在哪里
PYSPARK_PYTHON:表示Spark想运行Python程序,那么去哪里找python执行器
JAVA_HOME:告知Spark Java在哪里
HADOOP_CONF_DIR:告知Spark Hadoop的配置文件在哪里
HADOOP_HOME:告知Spark Hadoop安装在哪里这几个环境变量都需要配置在/etc/profile中
export SPARK_HOME=/usr/local/soft/spark-3.2.0-bin-hadoop3.2
export PYSPARK_PYTHON=/usr/local/soft/anaconda3/envs/pyspark/bin/python3.8
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
export HADOOP_CONF_DIR=/usr/local/soft/hadoop-3.3.1/etc/hadoop
export HADOOP_HOME=/usr/local/soft/hadoop-3.3.1PYSPARK_PYTHON和JAVA_HOME需要同样配置在/root/.bashrc中
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
export PYSPARK_PYTHON=/usr/local/soft/anaconda3/envs/pyspark/bin/python3.8测试
到Spark的安装目录
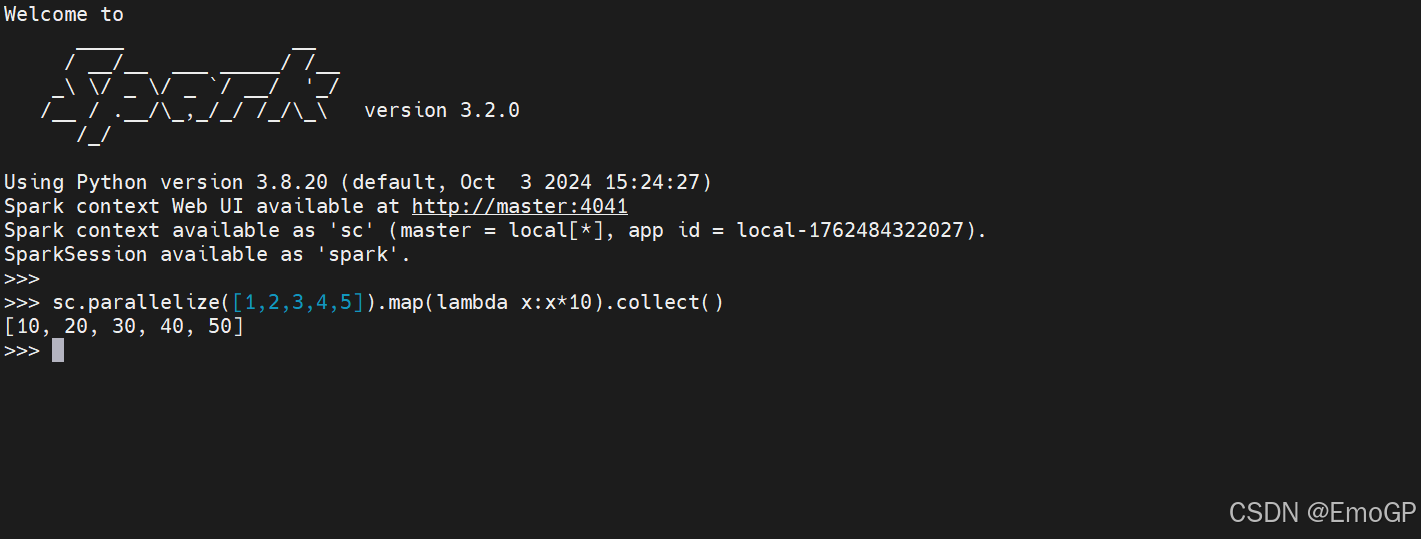
bin/pyspark程序,可以提供一个交互式的Python解释器环境,在这里面可以写普通python代码,以及spark代码

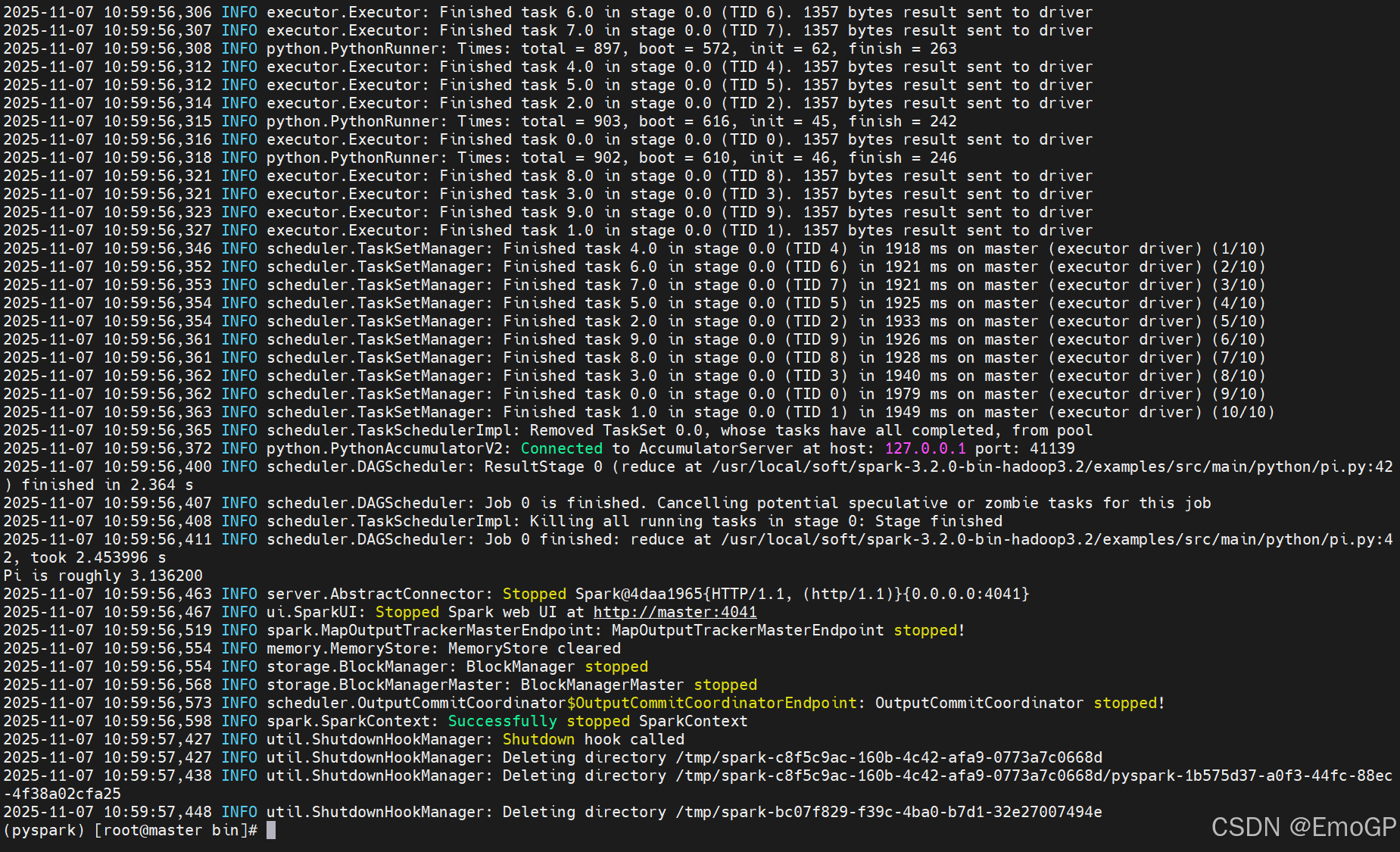
Local模式的运行原理?
Local模式就是以一个独立进程配合其内部线程来提供完成Spark运行时环境,Local模式可以通过spark-shell/pyspark/spark-submit等来开启
bin/pyspark是什么程序?
是一个交互式的解释器执行环境,环境启动后就得到了一个Local Spark环境,可以运行Python代码去进行Spark计算,类似Python自带解释器
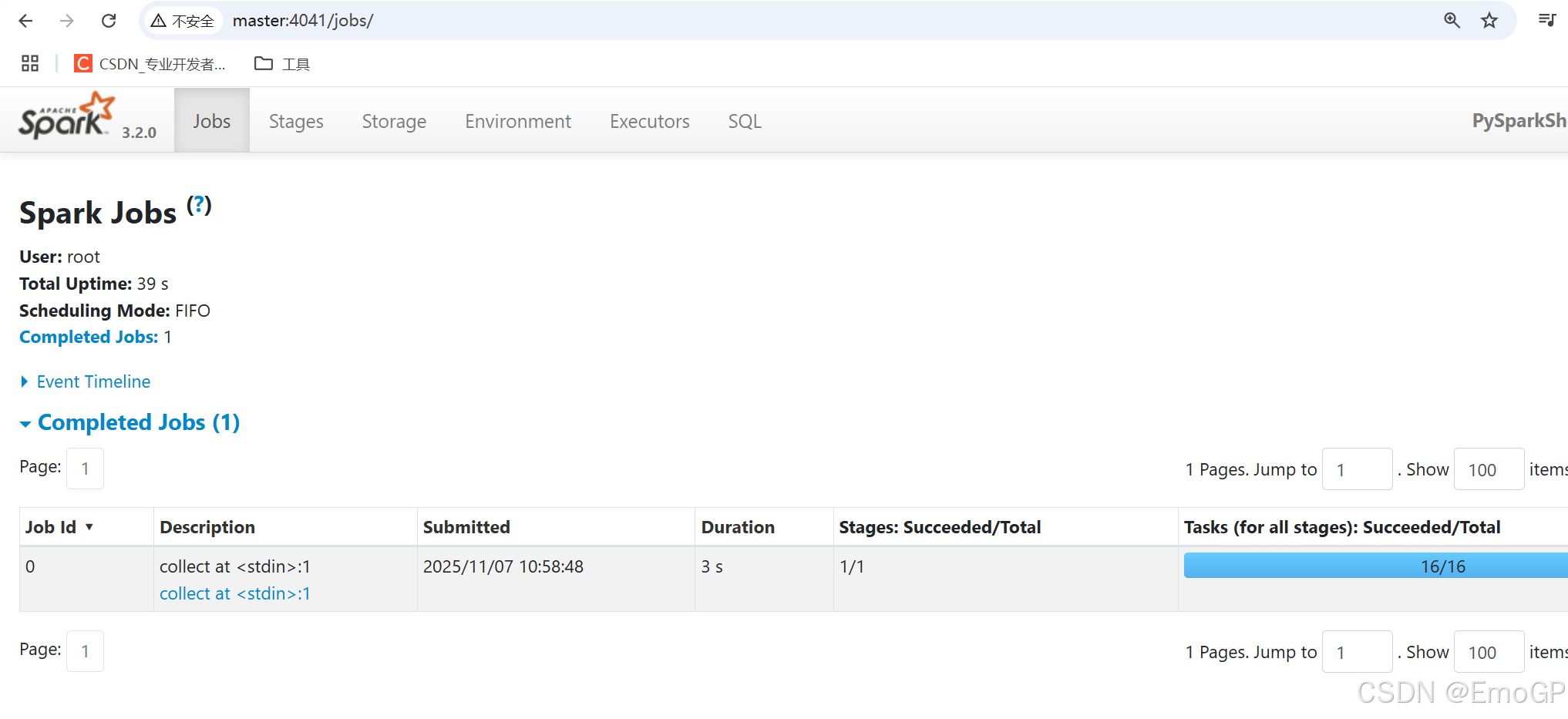
Spark的4040端口是什么?
Spark的任务在运行后,会在Driver所在机器绑定到4040端口,提供当前任务的监控页面供查看
3 StandAlone环境
3.1 Standalone架构
Standalone模式是Spark自带的一种集群模式,不同于前面本地模式启动多个进程来模拟集群的环境,该模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用改模式搭建多机器集群,用于实际的大数据处理
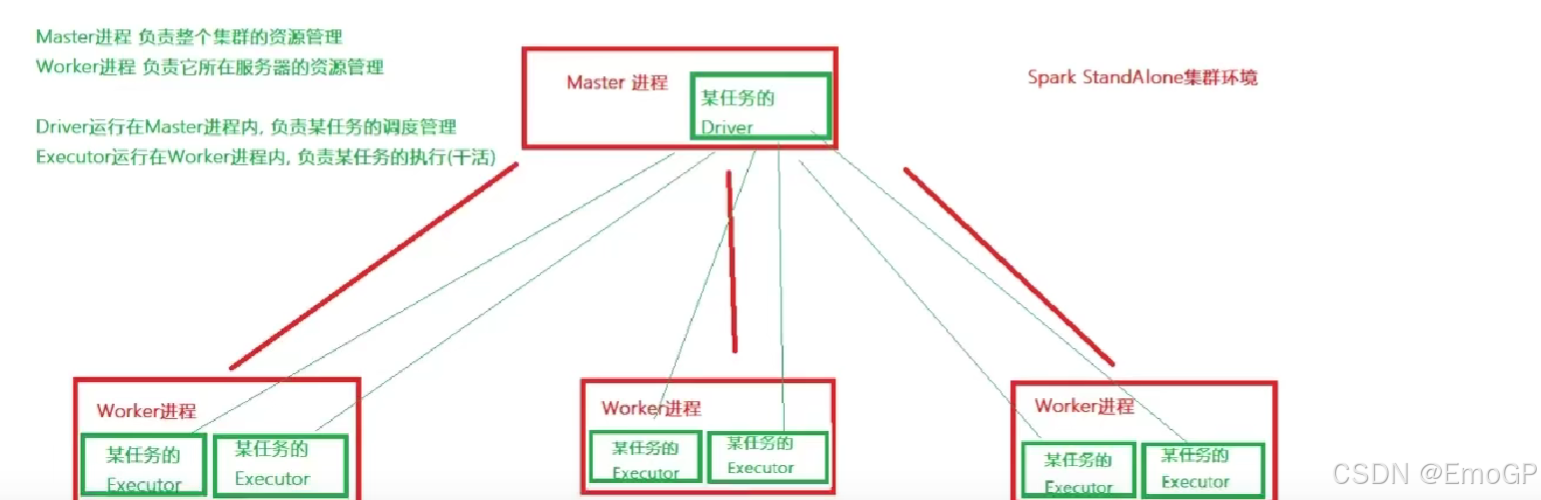
StandAlone是完整的Spark运行环境,其中
Master角色以Master进程存在,Worker角色以Worker进程存在
Driver角色在运行时存在于Master进程内,Executor运行于Worker进程内
StandAlone集群在进程上主要有三类进程:
主节点Master进程
Master角色,管理整个集群资源,并托管运行各个任务的Driver
从节点Workers
Worker角色,管理每个机器的资源,分配对应的资源来运行Executor(Task)
每个从节点分配资源信息给Worker管理,资源信息包含内存和CPU Cores核数
历史服务器HistoryServer
SparkApplication运行完成以后,保存事件日志数据至HDFS,启动HistoryServer可以查看应用运行相关信息
3.2 StandAlone部署
在所有机器上面安装Python(Anaconda)
在所有机器上创建虚拟环境pyspark
在所有机器上配置环境变量

使用source生效

修改Spark配置文件
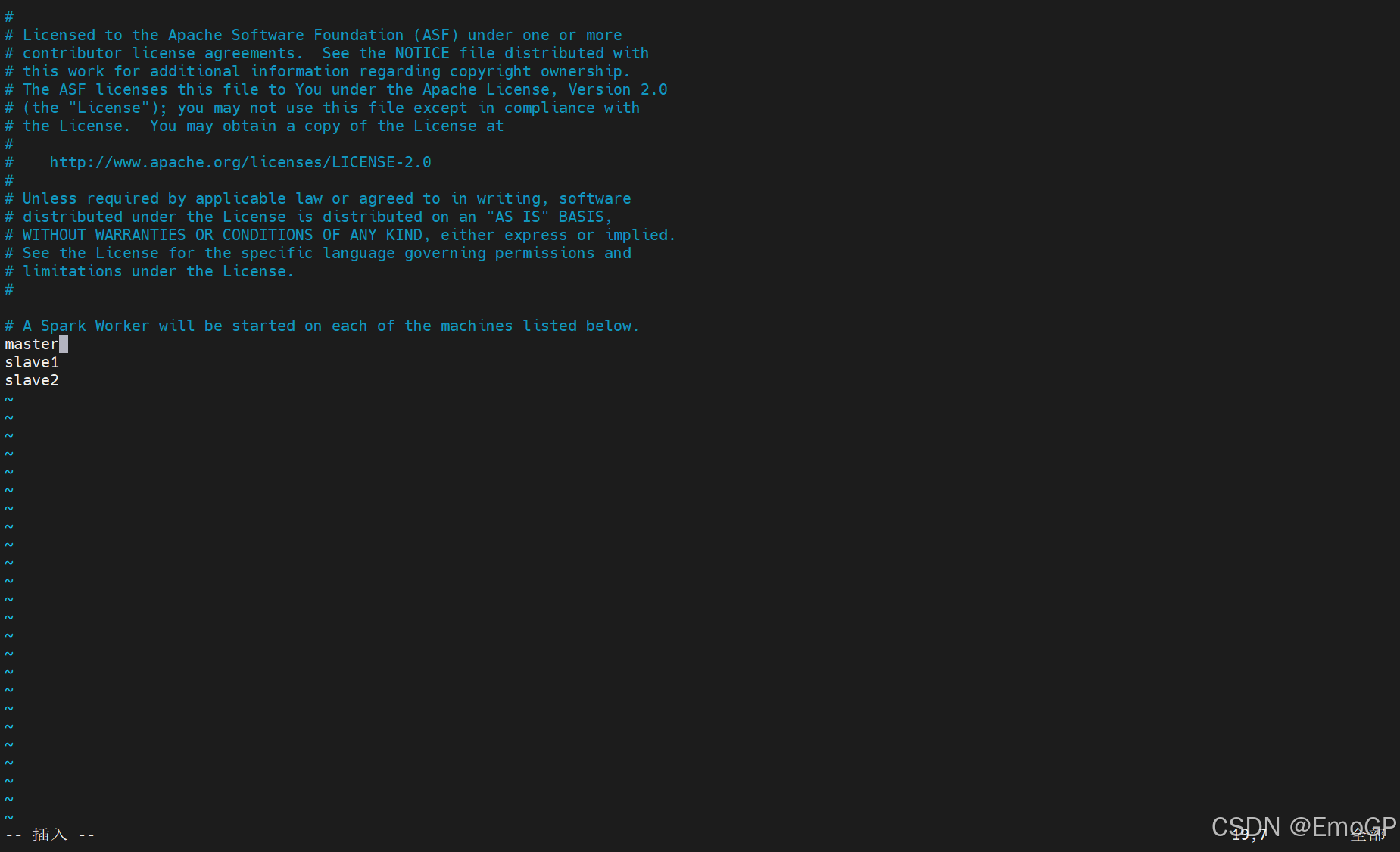
修改spark-env.sh
## 设置JAVA安装目录
JAVA_HOME=/usr/local/soft/jdk1.8.0_171
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群
HADOOP_CONF_DIR=/usr/local/soft/hadoop-3.3.1/etc/hadoop
YARN_CONF_DIR=/usr/local/soft/hadoop-3.3.1/etc/hadoop
## 指定spark老大Master的IP和提交任务的通信端口
# 告知Spark的master运行在哪个机器上
export SPARK_MASTER_HOST=master
# 告知sparkmaster的通讯端口
export SPARK_MASTER_PORT=7077
# 告知spark master的 webui端口
SPARK_MASTER_WEBUI_PORT=8080
# worker cpu可用核数
SPARK_WORKER_CORES=1
# worker可用内存
SPARK_WORKER_MEMORY=1g
# worker的工作通讯地址
SPARK_WORKER_PORT=7078
# worker的 webui地址
SPARK_WORKER_WEBUI_PORT=8081
## 设置历史服务器
# 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparkLog文件夹中
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://master:9000/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
hadoop fs -mkdir /sparklog
hadoop fs -chmod 777 /sparklog配置spark-defaults.conf

# 开启spark的日志记录功能
spark.eventLog.enabled true
# 设置spark日志记录的路径
spark.eventLog.dir hdfs://master:9000/sparklog/
# 设置spark日志是否启动压缩
spark.eventLog.compress true
配置log4j.properties

修改log4j.rootCategory=INFO, console
为log4j.rootCategory=WARN, console
即可
分发Spark到其他节点
启动历史服务器
sbin/start-history-server.sh
启动Spark的Master和Worker进程
启动全部的master和worker
sbin/start-all.sh
或者可以一个一个启动
启动当前机器的master
sbin/start-master.sh
启动当前机器的worker
sbin/start-worker.sh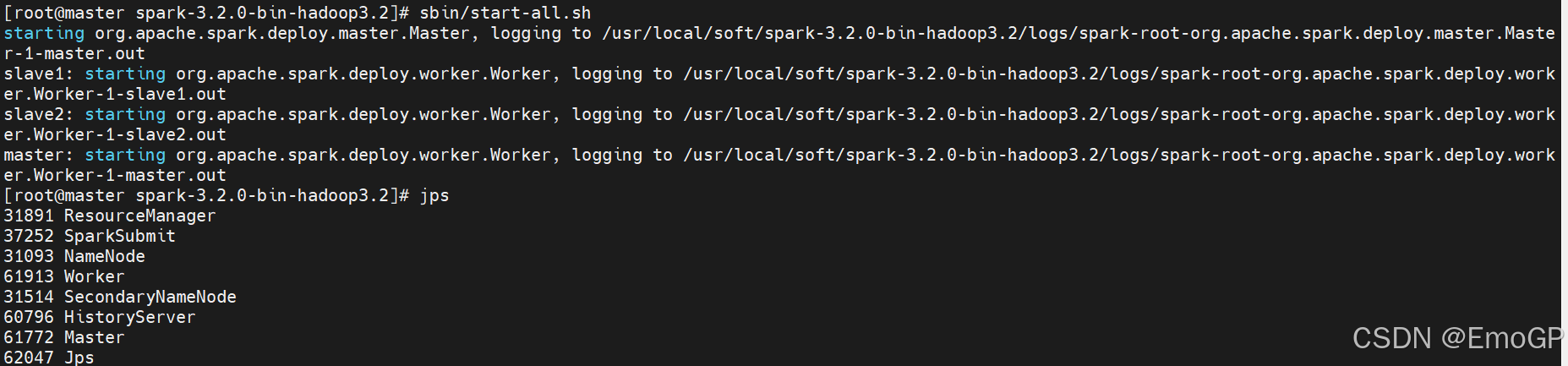
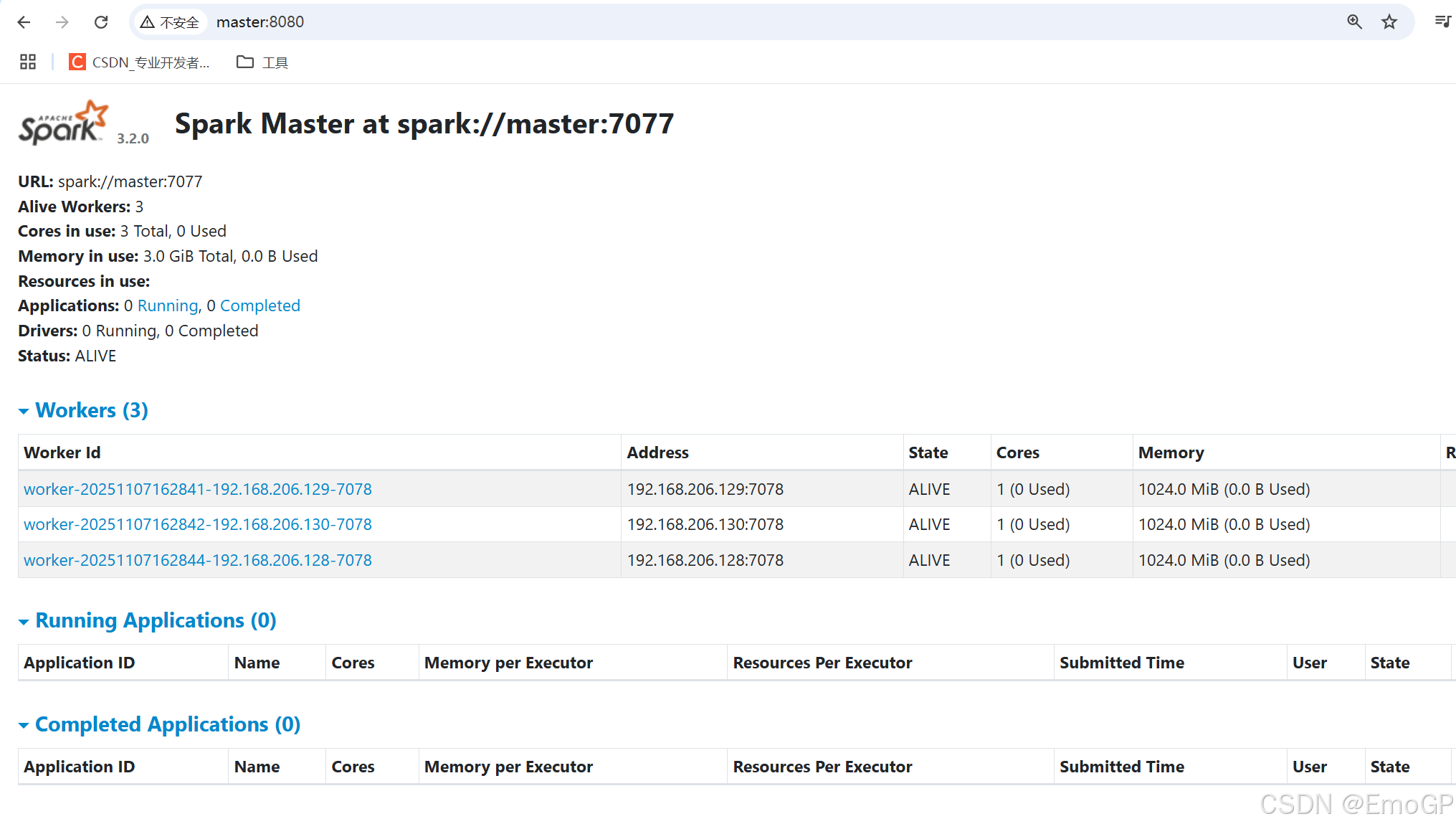
查看master的webui
默认端口设置的是8080,如果端口被占用,会顺延到8081...
3.3 StandAlone测试
连接到StandAlone集群
./pyspark --master spark://master:7077

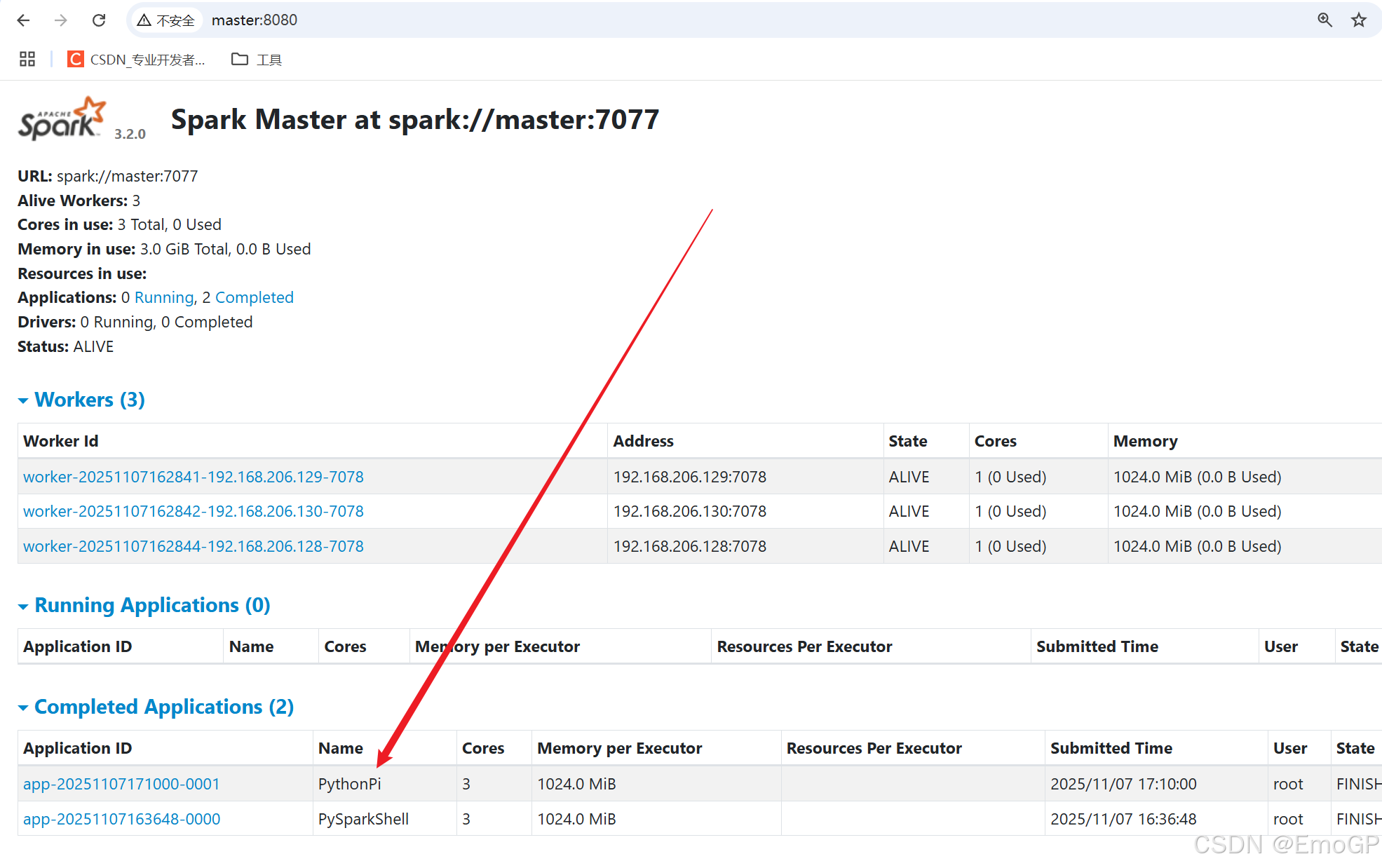
查看历史服务器 webui
历史服务器的默认端口是:18080
3.4 Spark程序运行层次结构
4040:是一个运行的Application在运行的过程中临时绑定的端口,用以查看当前任务的状态,如果被占用,会顺延到4041,4042等,4040是一个临时端口,当前程序运行完成后,4040就会被注销
8080:默认是StandAlone下,Master角色(进程)的Web端口,用以查看当前Master(集群)的状态
18080:默认是历史服务器的端口,由于每个程序运行完成后,4040端口就被注销了,在以后想回看某个程序的运行状态就可以通过历史服务器查看,历史服务器长期稳定运行,可供随时查看被纪录的程序的运行过程
执行如下代码
./pyspark --master spark://master:7077

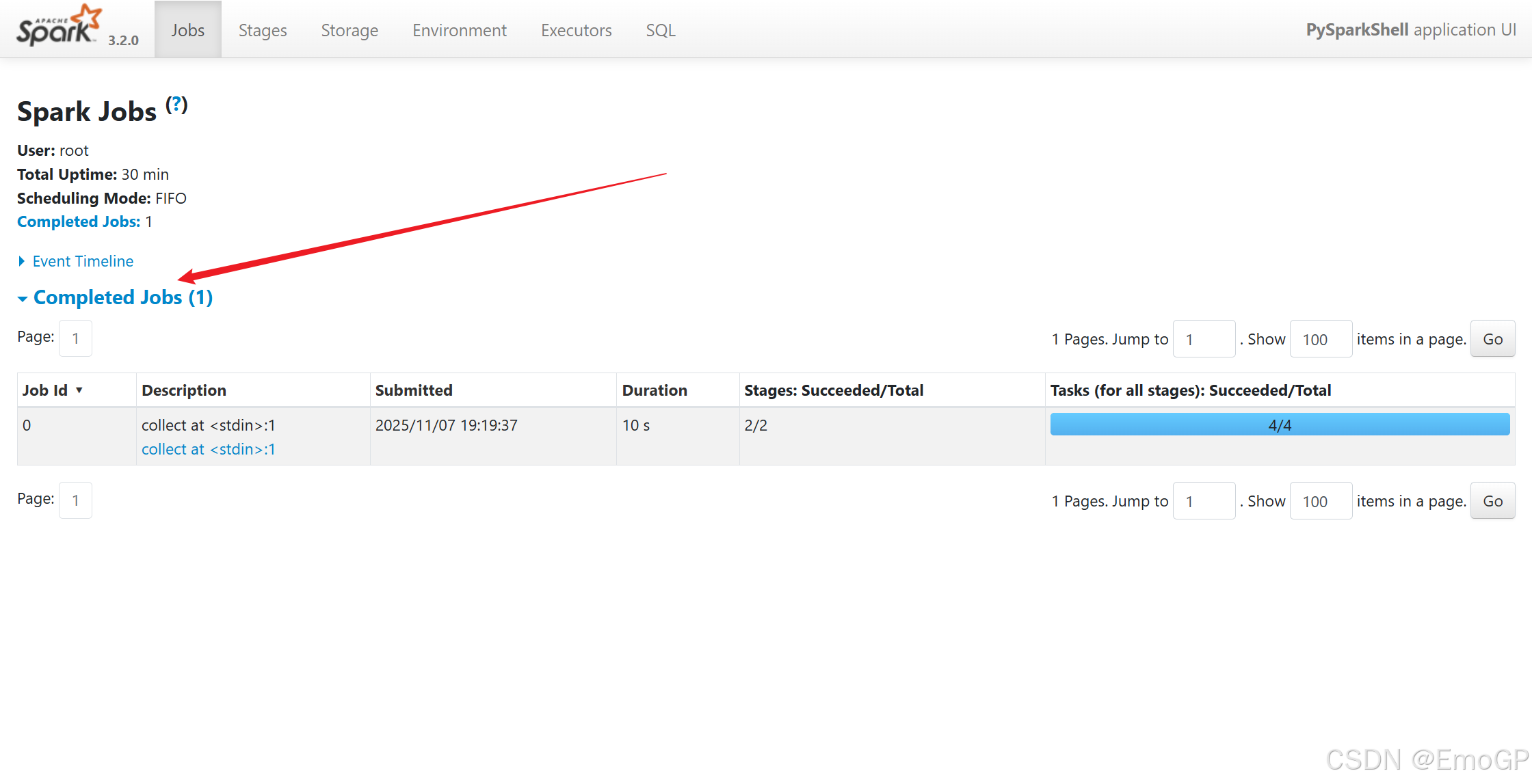
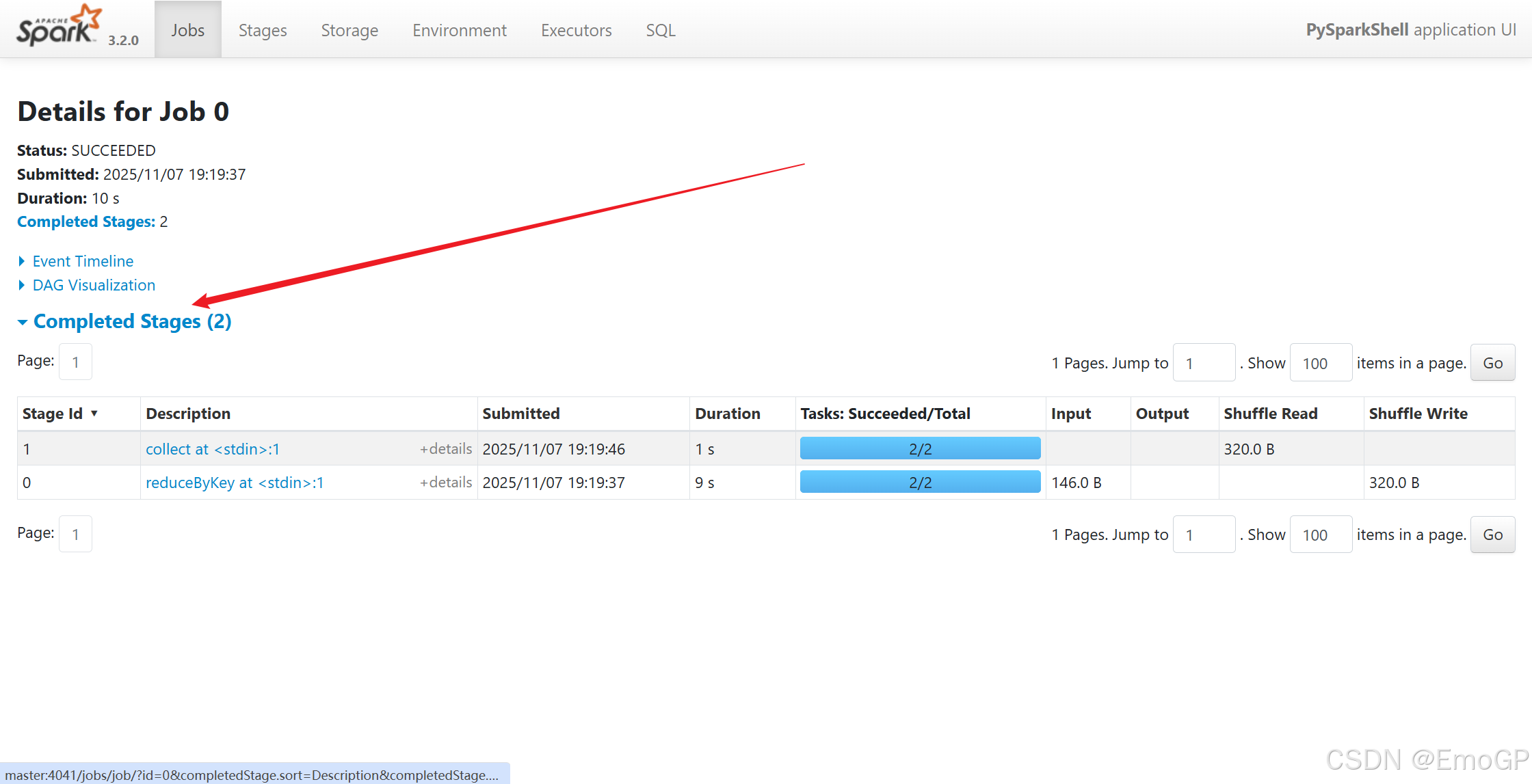
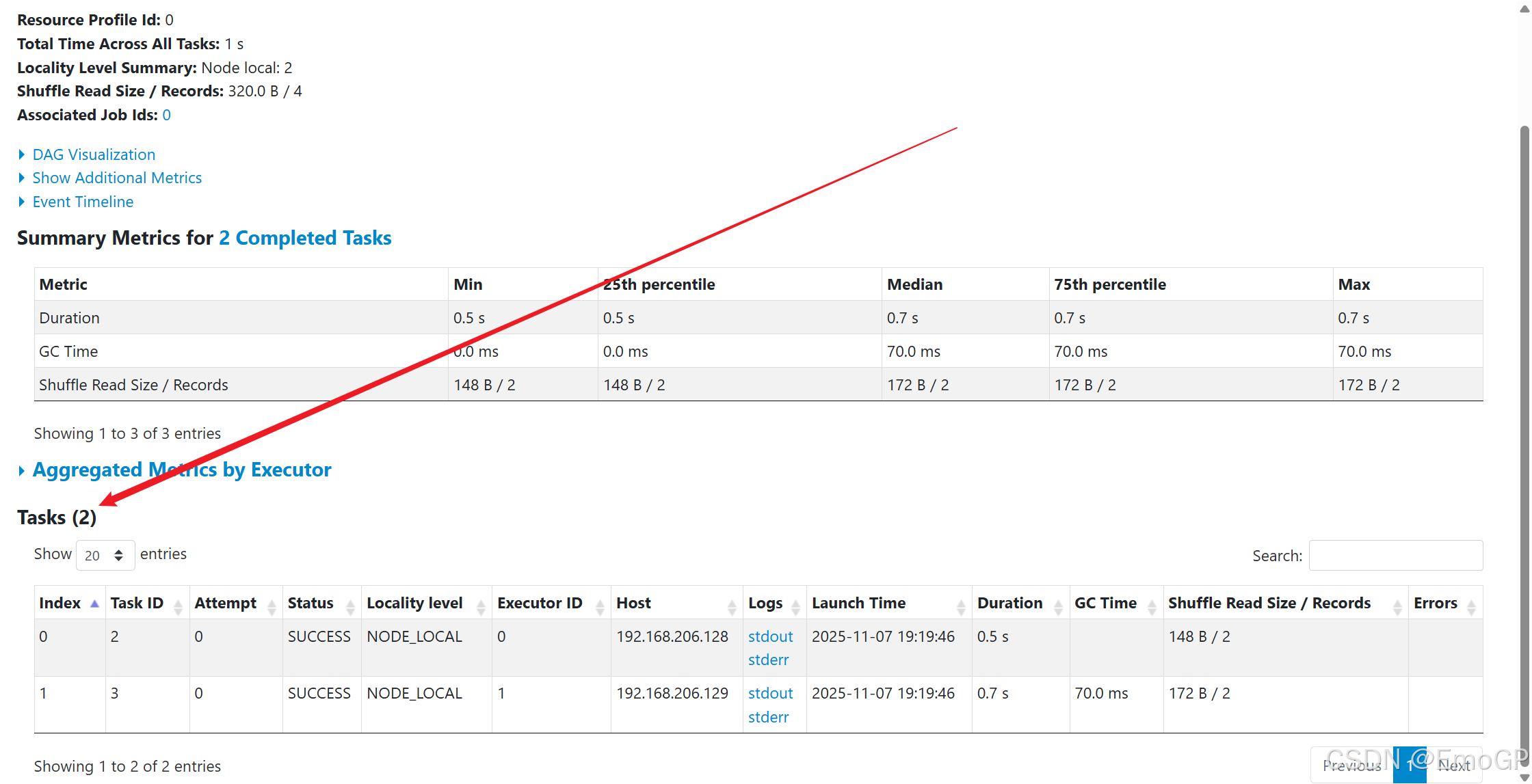
一个Spark程序会被分成多个子任务(Job)运行,每一个Job会分成多个State(阶段)来运行,每一个State内会分出来多个Task(线程)来执行具体任务
3.5 StandAlone的原理
Master和Worker角色以独立进程的形式存在,并组成Spark运行时环境(集群)
3.6 Spark角色在StandAlone中的分布
Master角色:Master进程,Worker角色:Worker进程,Driver角色:以线程运行运行在Master中,Executor角色:以线程运行在Worker中
3.7 StandAlone如何提交Spark应用
bin/spark-submit --master spark://master:70774 StandAlone HA
Spark Standalone集群式Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master单点故障(SPOF Single Point of Failure)的问题
HA搭建
编辑spark-env.sh配置文件
注释export SPARK_MASTER_HOST=master
添加如下内容
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"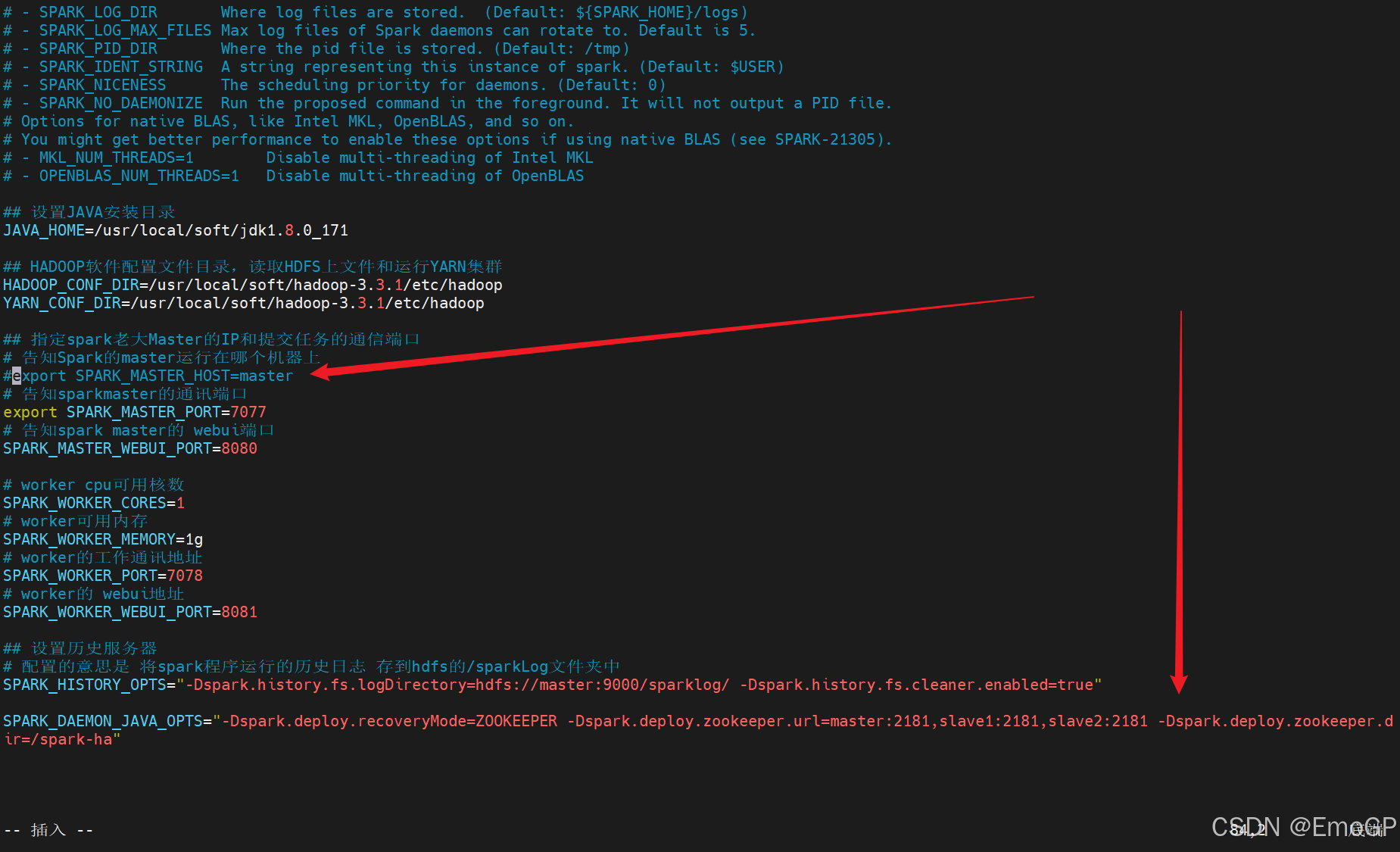
分发

启动集群(先启动hadoop和zookeeper)

再在slave1上启动一个master,即可实现高可用