一. 内存回收
1.1 内存过期处理
Redis并不会在KEY过期时立刻删除KEY,因为要实现这样的效果就必须给每一个过期的KEY设置时钟,并监控这些KEY的过期状态。无论对CPU还是内存都会带来极大的负担。
Redis的过期KEY删除策略有两种:
- 惰性删除:Redis会在每次访问KEY的时候判断当前KEY有没有设置过期时间,如果有,过期时间是否已经到期。(Redis如果不访问就一直不会删除)
- 周期删除:通过一个定时任务,周期性的抽样部分过期的key,然后执行删除。
执行周期有两种:
- SLOW模式:Redis会设置一个定时任务serverCron(),按照server.hz的频率来执行过期key清理
- FAST模式:Redis的每个事件循环前执行过期key清理(事件循环就是NIO事件处理的循环)。
SLOW模式规则:
- ① 执行频率受server.hz影响,默认为10,即每秒执行10次,每个执行周期100ms。
- ② 执行清理耗时不超过一次执行周期的25%,即25ms.
- ③ 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
- ④ 如果没达到时间上限(25ms)并且过期key比例大于10%,再进行一次抽样,否则结束
FAST模式规则(过期key比例小于10%不执行):
- ① 执行频率受beforeSleep()调用频率影响,但两次FAST模式间隔不低于2ms
- ② 执行清理耗时不超过1ms
- ③ 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
- ④ 如果没达到时间上限(1ms)并且过期key比例大于10%,再进行一次抽样,否则结束
Redis如何判断KEY是否过期呢?
答:在Redis中会有两个Dict,也就是HashTable,其中一个记录KEY-VALUE键值对,另一个记录KEY和过期时间。要判断一个KEY是否过期,只需要到记录过期时间的Dict中根据KEY查询即可。
1.2 内存淘汰策略
当内存使用达到阈值 时就会主动挑选部分KEY删除以释放更多内存。这叫做内存淘汰机制。
Redis支持8种不同的内存淘汰策略:
- noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。
- volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
- allkeys-random:对全体key ,随机进行淘汰。也就是直接从db->dict中随机挑选
- volatile-random:对设置了TTL的key ,随机进行淘汰。也就是从db->expires中随机挑选。
- allkeys-lru: 对全体key,基于LRU算法进行淘汰
- volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰
- allkeys-lfu: 对全体key,基于LFU算法进行淘汰
- volatile-lfu: 对设置了TTL的key,基于LFI算法进行淘汰
LRU,LFU算法:
- LRU(Least Recently Used),最近最久未使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
- LFU(Least Frequently Used),最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。
二. 缓存问题
2.1 缓存穿透
缓存穿透 是指查询一个数据库中根本不存在的数据 。由于这个数据在缓存中肯定也不存在,导致这个查询请求会绕过缓存 ,直接去查询数据库。
如果这类请求非常多,或者有人恶意攻击,频繁地请求这些不存在的数据,就会给数据库造成巨大的压力,甚至可能导致数据库宕机。
解决方案:
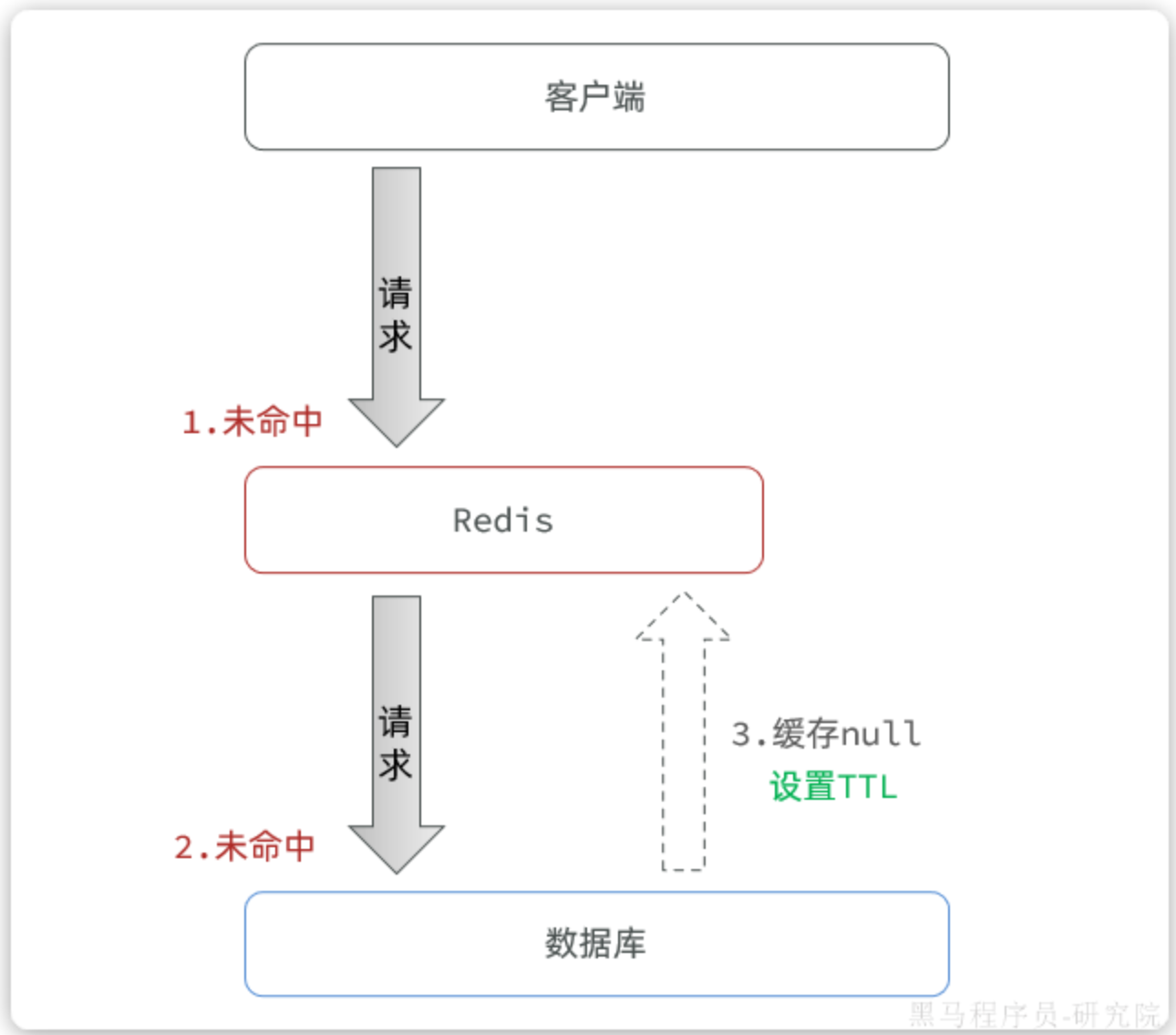
- 缓存空对象(Bloom Filter 的一种简单实现)
做法:当从数据库查询不到数据时,我们仍然将这个"空结果"进行缓存,但会设置一个较短的过期时间(比如2-5分钟)。
效果:后续相同的请求在缓存过期前,都会命中这个"空结果",从而保护数据库。
缺点:如果恶意攻击者每次请求的Key都不同,会导致缓存大量无意义的空键,占用内存。
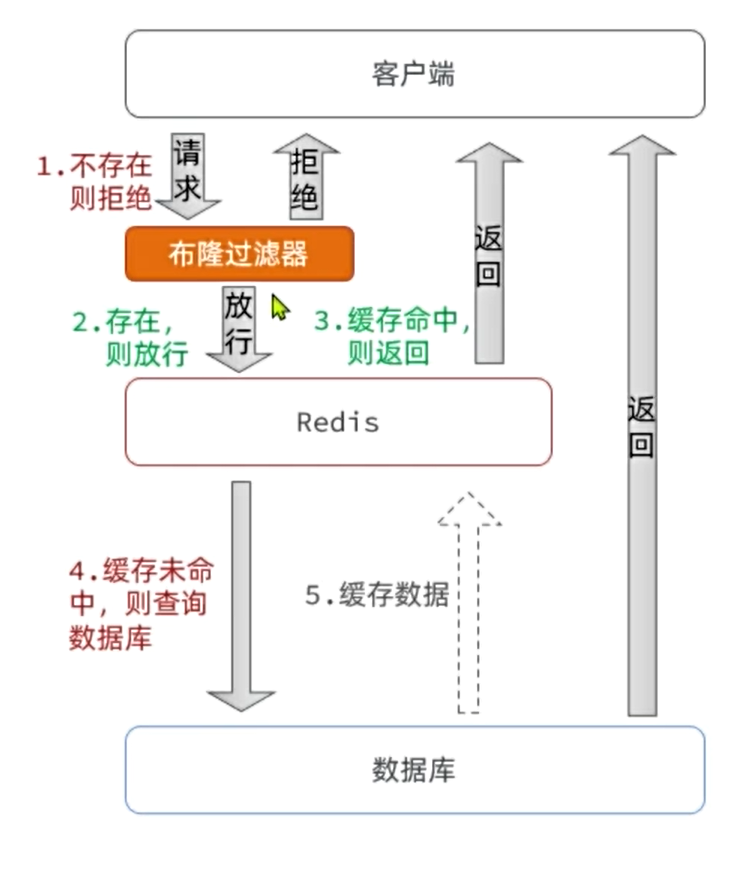
- 布隆过滤器(Bloom Filter)
做法:在缓存之前,加一个布隆过滤器。布隆过滤器是一个高效的数据结构,它可以告诉你"某个数据一定不存在"或者"可能存在"。
工作流程:
所有合法的、可能存在的数据Key都预先存入布隆过滤器。
当一个查询请求过来时,先让布隆过滤器检查这个Key。
如果过滤器说"一定不存在",则直接返回空,无需查询缓存和数据库。
如果过滤器说"可能存在",再继续后面的缓存和数据库查询流程。
效果:可以从根本上拦截掉绝大部分不存在的Key的查询,是解决缓存穿透最有效的方法之一。
- 接口层增加校验
做法:在API接口层对请求参数进行合法性校验。比如,根据规则判断请求的ID是否合法(是否是正数、是否符合格式等)。
效果:可以直接拦截掉一些明显非法的请求(如ID为负数、非数字等)。
2.2 缓存雪崩
缓存雪崩 是指在同一时间段内,大量的缓存数据同时失效(过期),或者缓存服务直接宕机,导致所有原本应该访问缓存的请求,瞬间都涌向了数据库。
数据库无法承受这突如其来的巨大压力,从而导致数据库响应变慢甚至崩溃。应用系统因为无法从数据库获取数据,继而引发整个系统的连锁性故障,就像雪崩一样,一发不可收拾。
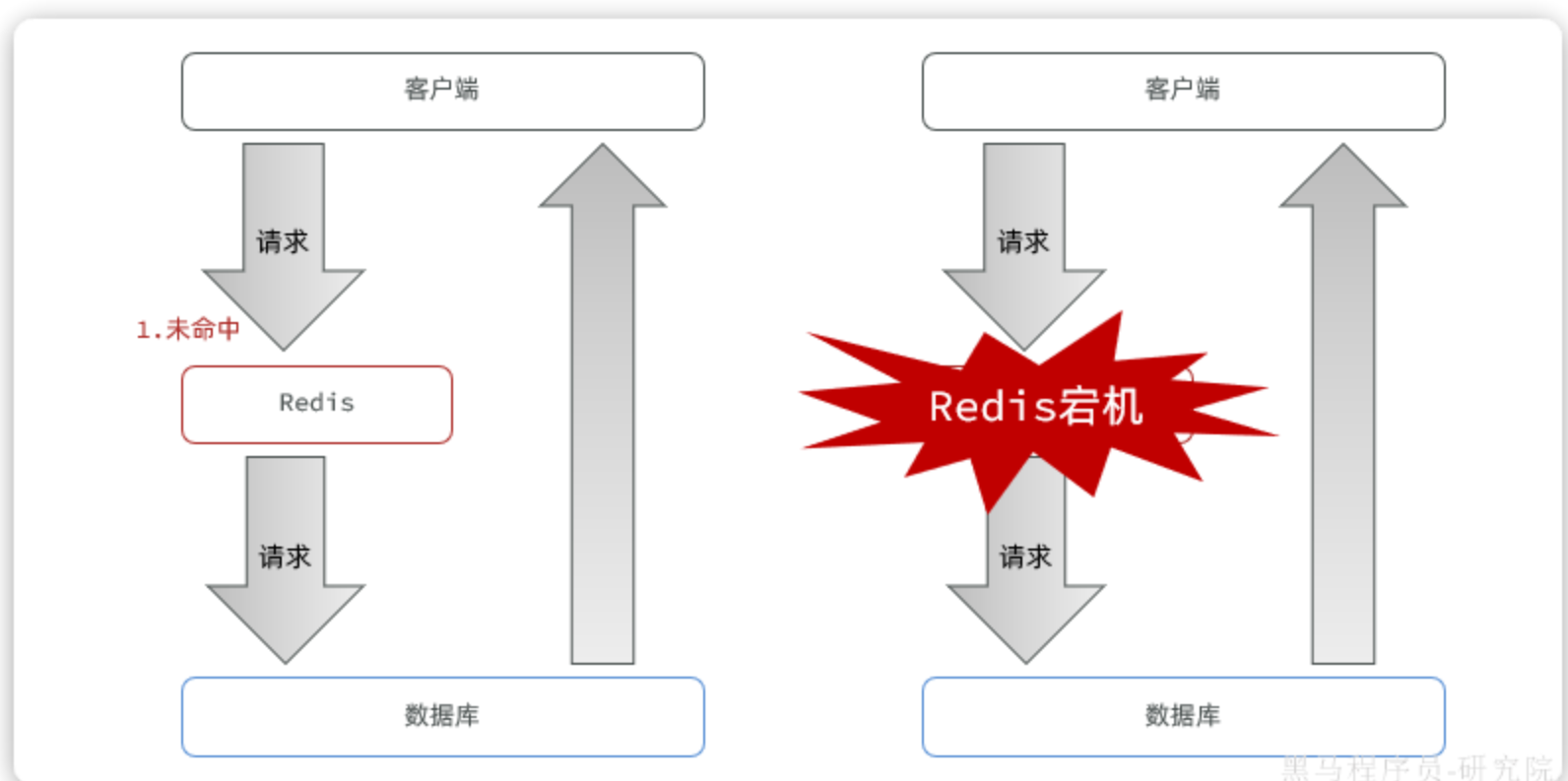
解决方案:
- 设置差异化的过期时间
做法:这是最核心、最简单的方案。在为缓存数据设置过期时间时,在基础值上加上一个随机值。
例如:原本都设置1小时过期,现在可以改成:1小时 + 随机(0~300)秒。这样就能保证缓存不会在同一个时间点大面积失效。
效果:将请求的压力均匀地分摊到不同的时间点上。
- 构建高可用的缓存集群
做法:通过Redis的哨兵(Sentinel)模式或集群(Cluster)模式,实现缓存服务的高可用。
效果:即使某个Redis节点宕机,集群也可以自动进行主从切换,保证服务整体不会完全不可用,从而防止因缓存服务宕机引发的雪崩。
- 服务降级与熔断
做法:在应用系统中引入熔断降级机制(如Hystrix、Sentinel)。当检测到数据库压力巨大,响应过慢或大量报错时,系统会自动熔断,暂时停止访问数据库,并返回一个预设的默认值(如"系统繁忙,请稍后重试")。
效果:牺牲部分非核心功能或用户体验,保护数据库不被拖垮,保证核心服务的可用性。
- 依赖隔离组件为后端限流
做法:使用线程池、信号量等机制,对数据库的访问进行限流。严格控制能够同时访问数据库的线程数量。
效果:即使缓存失效,涌向数据库的并发请求也是可控的,数据库不会被打垮。
2.3 缓存击穿
缓存击穿 是指某一个非常热点的数据 (比如明星八卦、秒杀商品)在缓存过期的瞬间,同时有大量的请求涌来。
由于这个热点数据刚好失效,这些并发的请求会同时发现缓存为空,于是它们会同时去访问数据库,瞬间给数据库带来巨大的压力,就像在缓存屏障上击穿了一个洞,所有流量都从这个洞涌向了数据库。
解决方案:
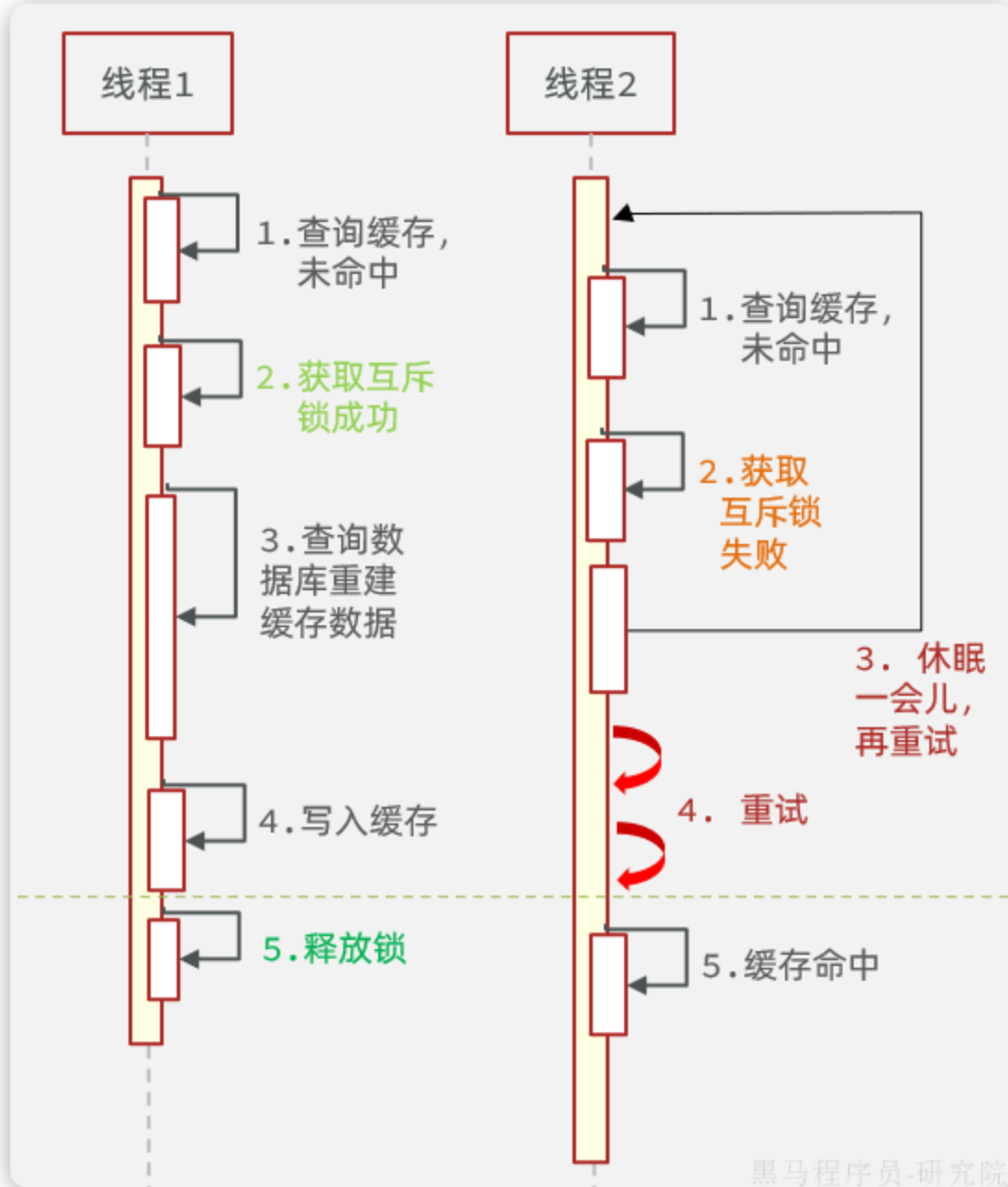
- 互斥锁(Mutex Lock)------ 最经典的方案
做法:当第一个请求发现缓存失效时,它并不立即去查询数据库。
它先去获取一个分布式锁(比如用Redis的SETNX命令)。
获取到锁的线程,负责去数据库查询数据并重建缓存 。
其他未能获取锁的线程则等待、重试或直接返回默认值,等待缓存被重建好。
效果:保证在同一时间,只有一个线程可以去查询数据库,从而将巨大的并发流量挡在外面,保护数据库。
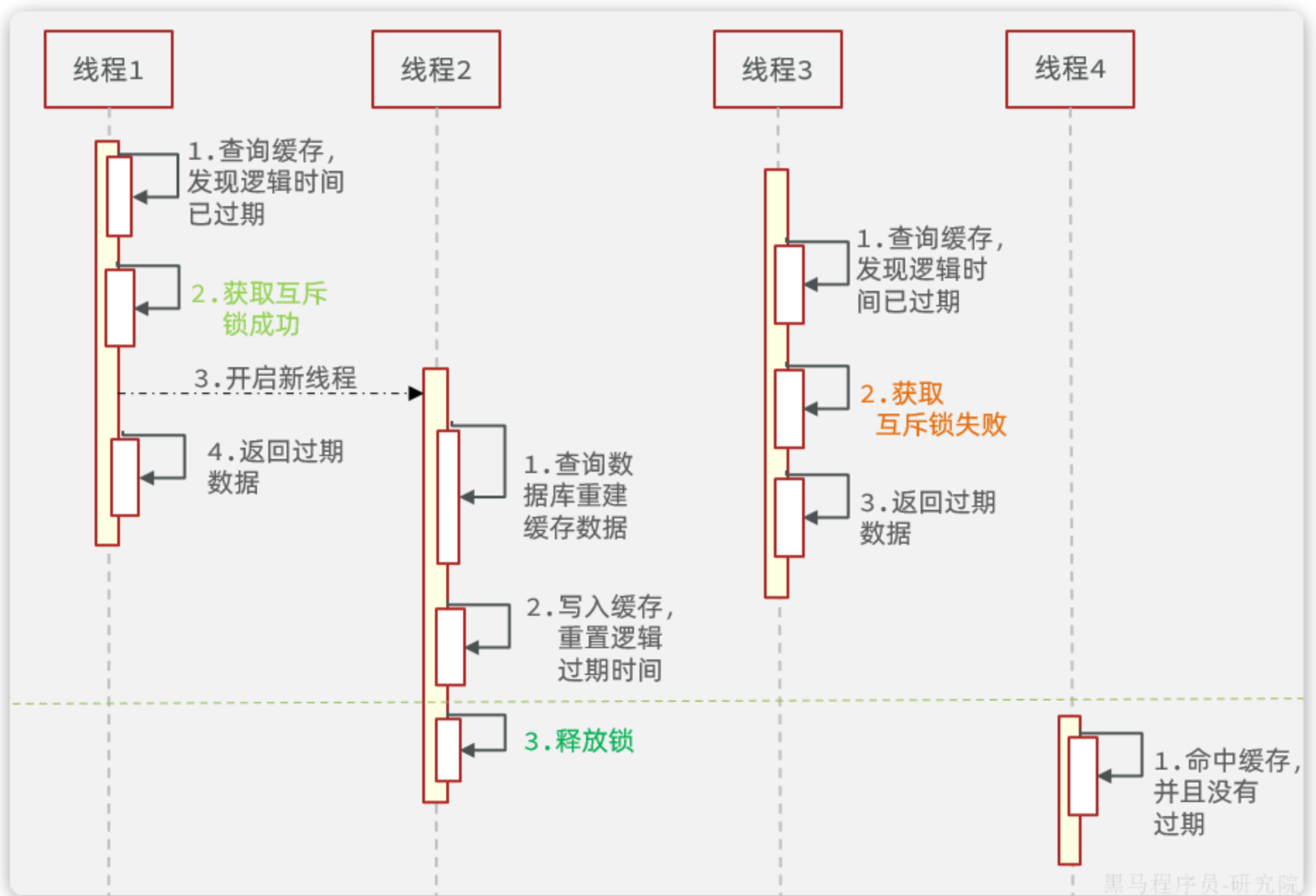
- 逻辑过期(逻辑上永不过期)
做法:缓存值本身不设置过期时间,但在缓存数据中额外加入一个"逻辑过期时间"字段。当应用发现数据逻辑上已过期时,就发起一个异步任务去更新缓存 ,而在更新期间,应用继续使用旧的缓存数据。
效果:用户不会遇到缓存失效的瞬间,体验平滑。它用"暂时性的数据不一致"换取了"系统的高可用性"。