案例一
调优前任务
任务拓扑:
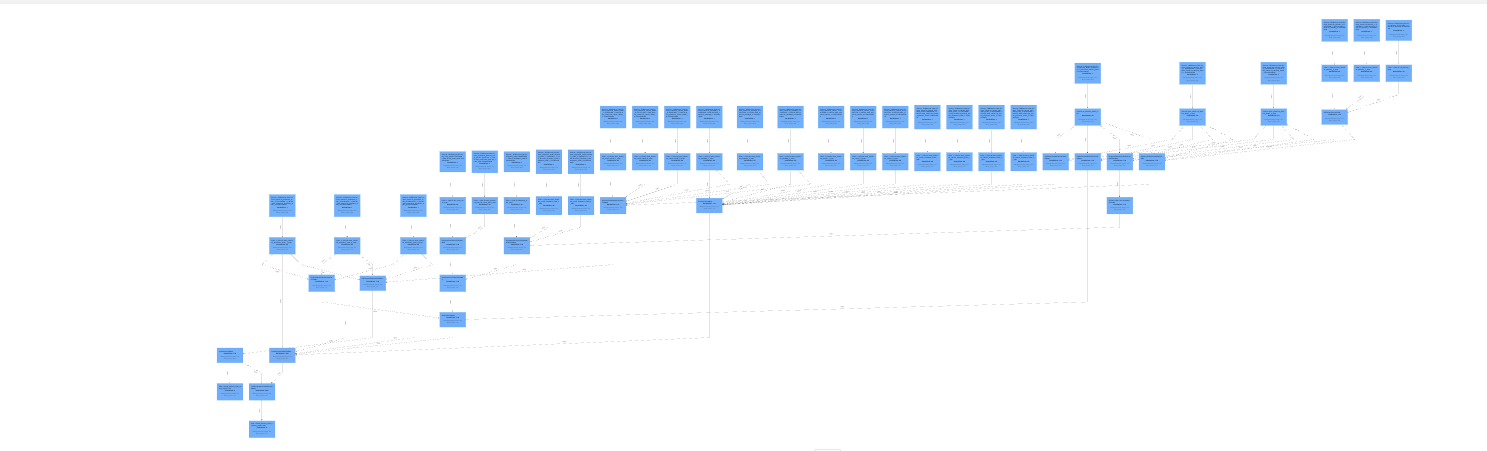
数据倾斜的算子:
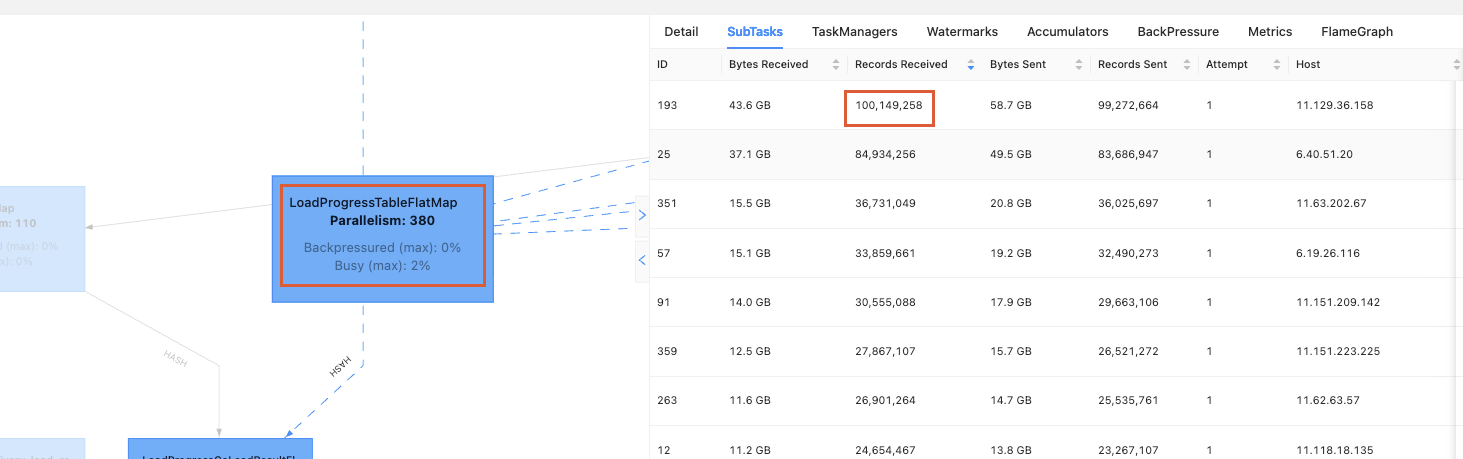
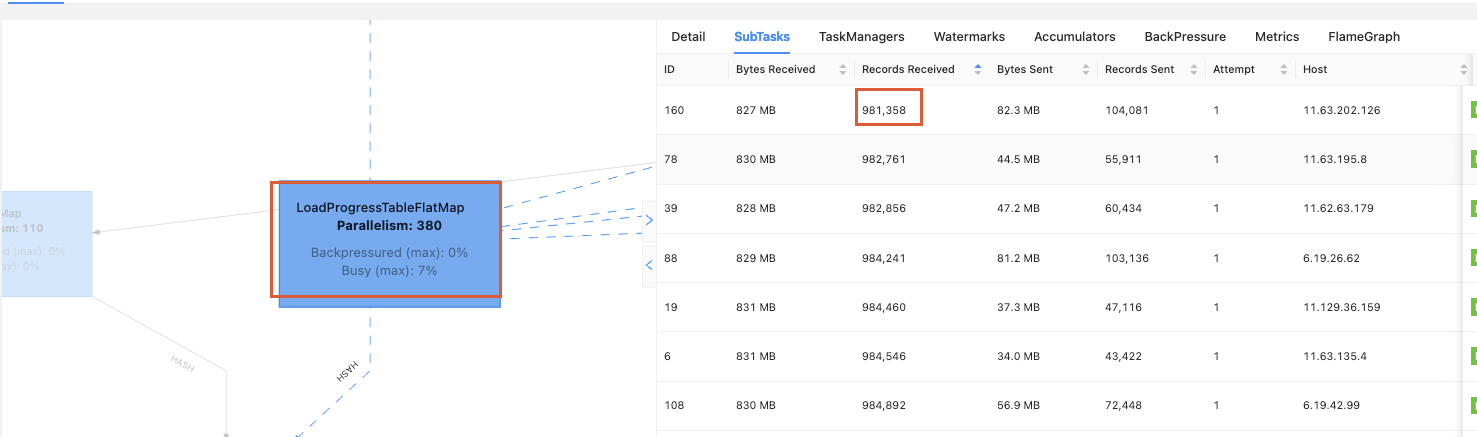
数据并行度为380,独享槽,最大数据量为1亿,最小数据量为98万,数据倾斜达到100倍以上
调优后任务
任务拓扑:

数据倾斜算子调优后:
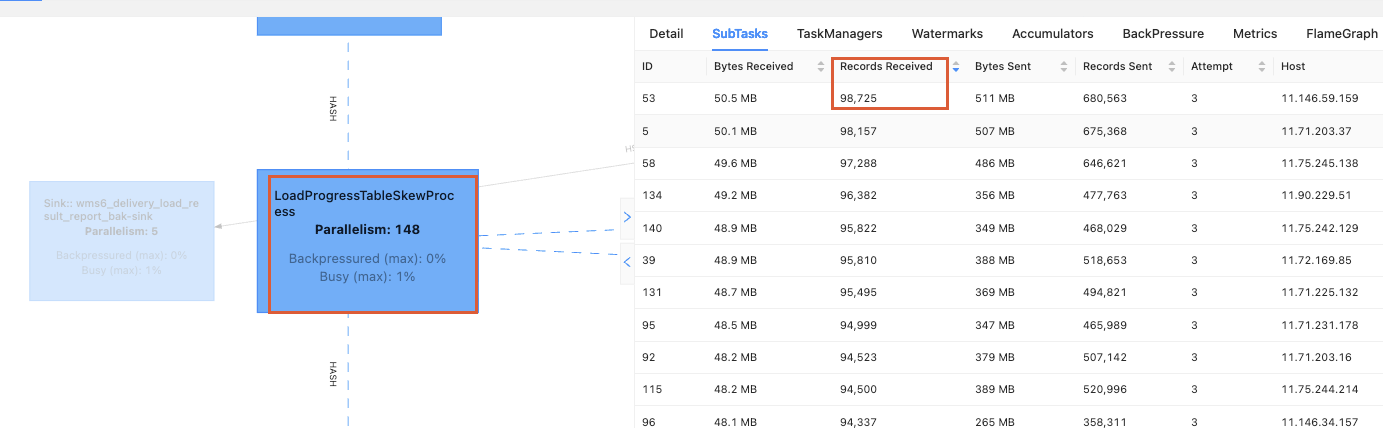
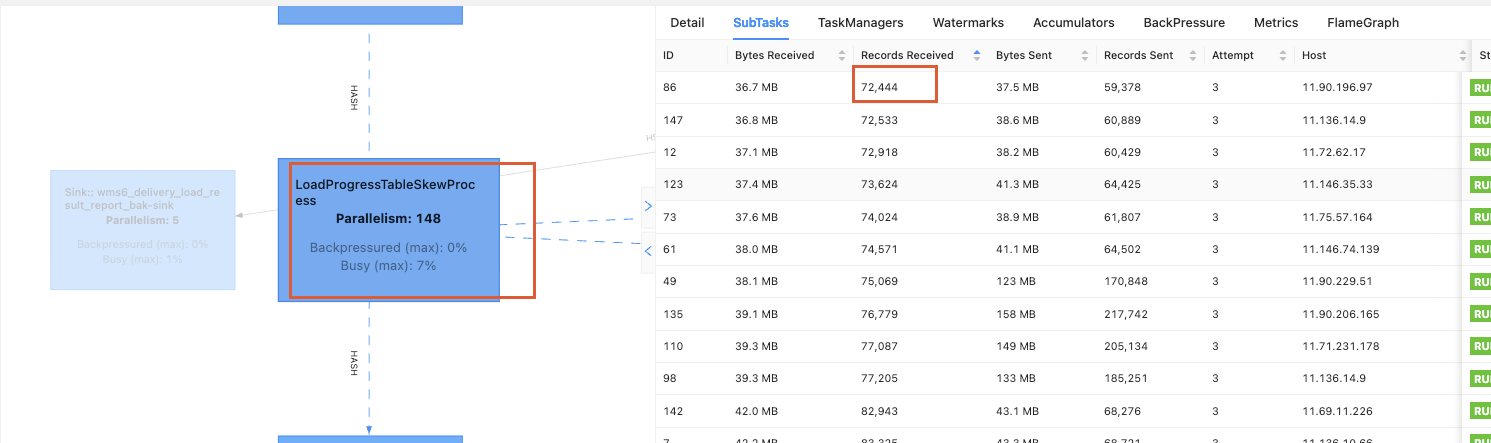
数据并行度为148,最大数据量为98万,最小数据量为72万,数据倾斜度不到1倍,几乎不存在。并行度降为原来的38%,并且为共享槽。
调优前资源使用量: 2002cpu,5016g内存,250TM,500slots;
调优后资源使用量: 400cpu,656g内存,80TM,160slots;
资源使用基本降为原来的1/5。
由于之前的数据倾斜严重导致checkpoint迟迟过不去,只能通过加资源和配置【Tolerable Failed Checkpoints 】来缓解数据倾斜的情况;调优以后数据倾斜的情况不存在了,checkpoint更容易对齐和成功,所以资源使用量大大降低。
调优手段
主要用到的调优手段
- 加盐,由于当前数据倾斜的算子存在一对多的情况(A:B=1:n)。所以通过在A stream 加盐前缀并扩大n倍的数据量下发数据到下游,比如:1#100,2#100,...,n#100;在B stream 加随机盐值下发数据到下游,比如:1#100,2#101,5#102,8#103,...,n#123。
- 通过测流来减少不必要数据量的计算
- 通过滚动窗口去重,减少数据下发,减轻下游的压力,例如:
java
DataStream<Tuple2<String, String>> tumblingProcessingTimeWindows = loadProgressTableSkewStream
.keyBy(v -> v.f0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5))) // 5秒钟滚动窗口
.reduce((v1, v2) -> v2)
.uid("tumblingProcessingTimeWindows")
.name("tumblingProcessingTimeWindows");