是否曾为录音中的背景噪音而烦恼?上次介绍过使用ffmpeg一行命令进行降噪,虽然非常简单,但效果可能不尽如人意。
今天,再介绍一种更专业、更强大的降噪方案------利用阿里达摩院的AI大模型 speech_zipenhancer_ans_multiloss_16k_base。别担心复杂的环境配置和编程知识!你只需要准备两个小工具和一份py文件,就能通过一个简单的命令,自动完成所有降噪工作。
下面,让我们一步步开始吧!
准备工作(若已存在uv和ffmepg可跳过该步)
在开始之前,我们需要获取两个小工具:uv 和 ffmpeg。它们是实现自动配置和音视频处理的关键。
步骤 1:获取 uv
uv 是一个轻量级的 Python 包管理工具,它能帮助我们自动下载和配置阿里降噪模型所需的各种库,省去手动安装的麻烦。
-
下载地址: Windows 版
uv.exe请从这里下载:https://github.com/astral-sh/uv/releases/download/0.9.8/uv-x86_64-pc-windows-msvc.zip -
操作步骤:
-
点击上述链接下载压缩包。
-
解压下载的
uv-x86_64-pc-windows-msvc.zip文件,你会看到uv.exe以及同目录下的另外两个.exe文件。 -
在电脑的任意文件夹 的地址栏(就是显示文件路径的地方,如下图所示)中,输入
%userprofile%\.local\bin后按回车键。
-
将刚才解压出来的
uv.exe等三个文件,全部复制粘贴到这个新打开的文件夹中。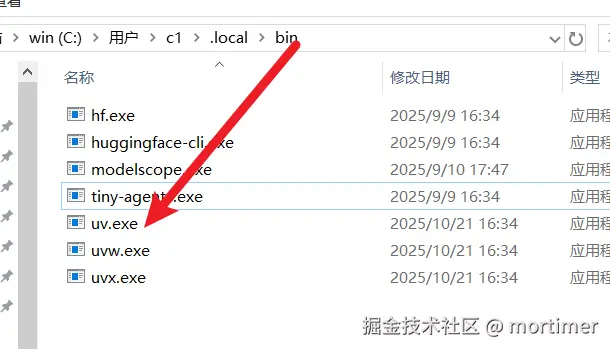
-
-
小贴士: 这样做是为了让你的电脑能够在任何地方直接识别并运行
uv命令,而无需每次都指定它的完整路径,非常方便! -
MacOS上直接执行
wget -qO- https://astral.sh/uv/install.sh | sh一步完成安装
步骤 2:获取 ffmpeg
ffmpeg 是一个功能强大的音视频处理工具,使用它来将视频转为降噪模型所需的固定音频格式。
-
下载地址: Windows请从这里下载
ffmpeg的完整版本:https://www.gyan.dev/ffmpeg/builds/ffmpeg-release-full.7zMacOS上直接执行
brew install ffmpeg一步安装 -
操作步骤:
- 点击上述链接下载
ffmpeg-release-full.7z压缩包。 - 解压下载的文件。解压后,你会看到一个名为
ffmpeg-x.x.x-full_build的文件夹(x.x.x代表版本号)。 - 进入这个文件夹,找到
bin子文件夹,里面有一个ffmpeg.exe文件。 - 将这个
ffmpeg.exe文件复制 到你刚才放置uv.exe的同一个目录中 (即%userprofile%\.local\bin文件夹)。
- 点击上述链接下载
-
恭喜! 最麻烦的准备工作已经完成。这两个工具只需这样设置一次,以后就能永久使用了。
保存降噪代码到 ans.py 文件
降噪的全部逻辑都包含在下面这段代码中,按下面方式复制粘贴代码。
- 在你的电脑上,选择一个你喜欢的文件夹来存放这个降噪程序(例如,你可以在
D盘下新建一个aitools文件夹)。 - 在这个文件夹中,新建一个文本文件,并将其命名为
ans.py。 * 特别注意: 确保文件后缀是.py而不是.txt!如果你不确定,可以在文件管理器中点击"查看"选项卡,然后勾选"文件扩展名",这样你就能清楚地看到和修改文件后缀了。 - 将下面的所有代码完整复制,然后粘贴到你刚刚创建的
ans.py文件中。 - 保存
ans.py文件。
python
# /// script
# requires-python = "==3.10.*"
# dependencies = [
# "modelscope",
# "datasets==3.0.*",
# "torch",
# "pillow",
# "addict",
# "simplejson",
# "librosa",
# "soundfile",
# "sortedcontainers",
# ]
# [[tool.uv.index]]
# url = "https://pypi.tuna.tsinghua.edu.cn/simple"
# ///
print('Loading....')
import sys,subprocess,os,logging,warnings
warnings.filterwarnings("ignore", category=UserWarning)
os.environ['MODELSCOPE_LOG_LEVEL']=str(logging.ERROR)
from pathlib import Path
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
if len(sys.argv) < 2:
print("\n 错误:请在命令后面提供要处理的音频或视频文件路径!\n正确用法:uv run ans.py \"你的文件路径\"\n技巧:可以直接将文件拖拽到命令行窗口中。");sys.exit(1)
ROOT = Path(os.getcwd());TMP_DIR = ROOT / "tmp";TMP_DIR.mkdir(exist_ok=True)
filepath = Path(sys.argv[1])
file_wav = TMP_DIR/f"{filepath.stem}.wav"
out_wav = ROOT/f"{filepath.stem}-ans.wav"
print(f'======开始降噪=======')
try:
subprocess.run( ["ffmpeg", "-y", "-i", str(filepath), "-c:a", "pcm_s16le", "-ac", "1", "-ar", "16000", str(file_wav)], check=True, capture_output=True, text=True )
except subprocess.CalledProcessError as e:
print(f"\n 错误:FFmpeg 转换失败!请检查文件路径是否正确,或文件本身是否损坏。\nFFmpeg 错误信息: {e.stderr}");sys.exit(1)
ans = pipeline(Tasks.acoustic_noise_suppression, model='iic/speech_zipenhancer_ans_multiloss_16k_base', disable_update=True, disable_log=True)
ans( str(file_wav), output_path=str(out_wav))
Path(file_wav).unlink(missing_ok=True)
print(f'======降噪完毕,降噪后文件是: {out_wav}')运行降噪程序
现在,是时候让我们的降噪程序大显身手了!
- 打开命令行窗口: 找到你存放
ans.py文件的文件夹(例如D:\aitools)。在文件夹的地址栏中(显示文件路径的地方),清空 现有内容,输入cmd,然后按回车键。
这会在当前文件夹中快速打开一个命令行窗口。
-
输入命令: 在打开的命令行窗口中,输入以下命令:
uv run ans.py(ans.py后面有一个空格!) -
指定要降噪的文件: 在
uv run ans.py后面,你需要告诉程序哪个文件需要降噪。你可以选择以下两种方式:- 方式一(推荐):直接拖拽。 将你想要降噪的音频或视频文件(例如
我的噪音录音.mp4)直接拖拽到命令行窗口中。文件的完整路径会自动显示在命令后面。 - 方式二:手动输入路径。 手动输入文件的完整路径。如果文件路径中包含空格,请务必用双引号把整个路径括起来 ,例如:
uv run ans.py "D:\我的视频\吵闹的录音.mp4"。
- 方式一(推荐):直接拖拽。 将你想要降噪的音频或视频文件(例如
-
执行命令: 输入或拖拽完成后,按下回车键,程序就开始执行了!
查看降噪结果
程序运行完毕后,你会在 ans.py 文件所在的同一个文件夹中,找到一个名为 [你的原文件名]-ans.wav 的新文件。这个文件就是降噪后的音频了!
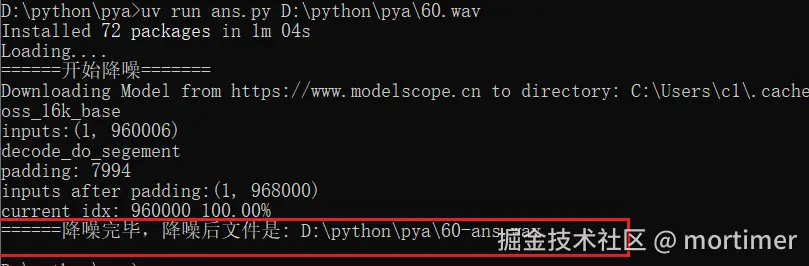
第一次运行程序时,
uv会自动下载并配置阿里降噪模型所需的各种库和模型文件。这可能需要一些时间(根据你的网络速度而定),请耐心等待。下载完成后,后续再次运行就会快很多了!